

Linux 中awk命令中实现以某一列为分类输出数据
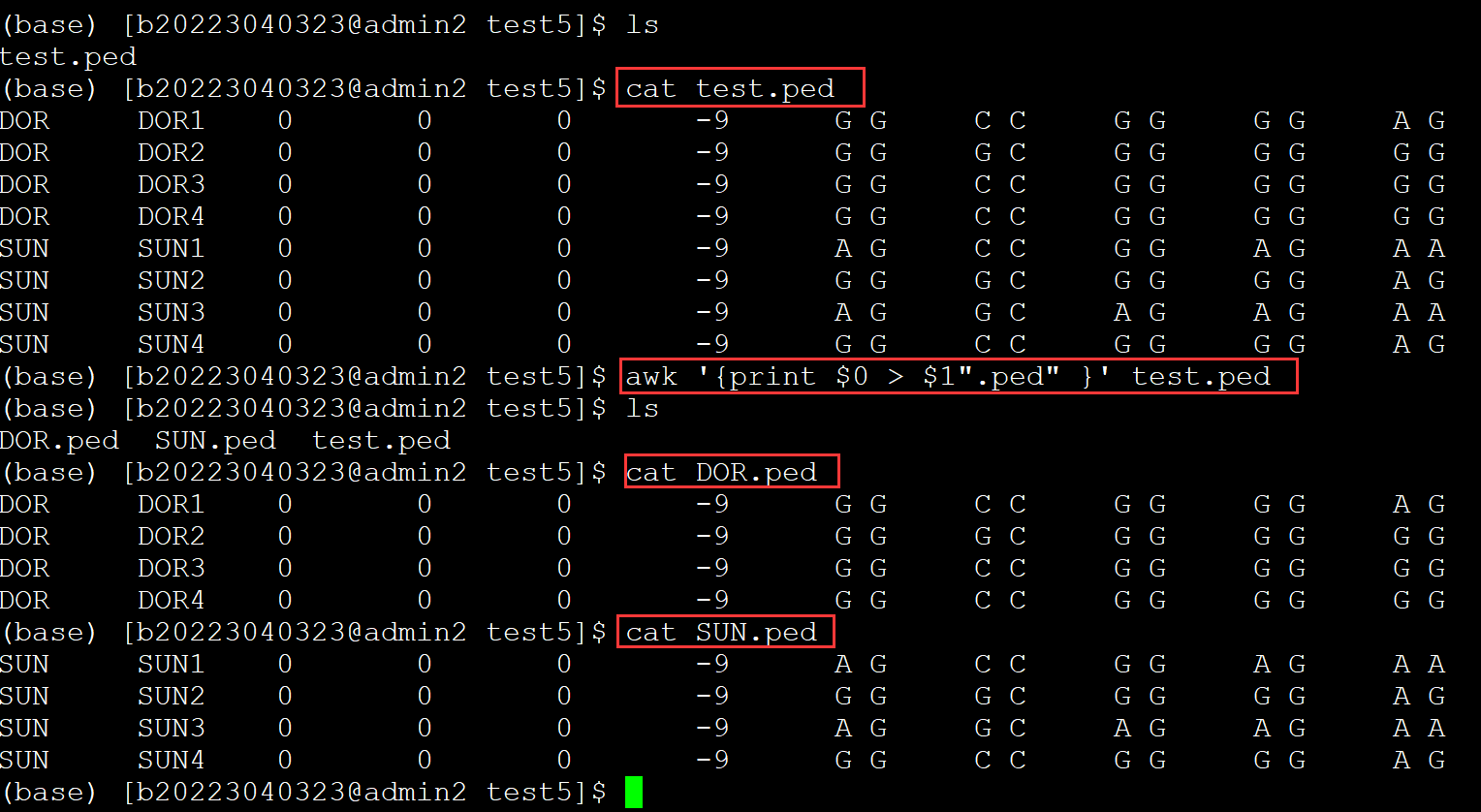
001、
(base) [b20223040323@admin2 test5]$ ls test.ped (base) [b20223040323@admin2 test5]$ cat test.ped ## 测试ped文件 DOR DOR1 0 0 0 -9 G G C C G G G G A G DOR DOR2 0 0 0 -9 G G G C G G G G G G DOR DOR3 0 0 0 -9 G G C C G G G G G G DOR DOR4 0 0 0 -9 G G C C G G G G G G SUN SUN1 0 0 0 -9 A G C C G G A G A A SUN SUN2 0 0 0 -9 G G G C G G G G A G SUN SUN3 0 0 0 -9 A G G C A G A G A A SUN SUN4 0 0 0 -9 G G C C G G G G A G (base) [b20223040323@admin2 test5]$ awk '{print $0 > $1".ped" }' test.ped ## 输出每行所有字段, 导入到以第一字段+".ped"的文件名称中 (base) [b20223040323@admin2 test5]$ ls ## 检查结果 DOR.ped SUN.ped test.ped (base) [b20223040323@admin2 test5]$ cat DOR.ped ## 查看 DOR DOR1 0 0 0 -9 G G C C G G G G A G DOR DOR2 0 0 0 -9 G G G C G G G G G G DOR DOR3 0 0 0 -9 G G C C G G G G G G DOR DOR4 0 0 0 -9 G G C C G G G G G G (base) [b20223040323@admin2 test5]$ cat SUN.ped SUN SUN1 0 0 0 -9 A G C C G G A G A A SUN SUN2 0 0 0 -9 G G G C G G G G A G SUN SUN3 0 0 0 -9 A G G C A G A G A A SUN SUN4 0 0 0 -9 G G C C G G G G A G
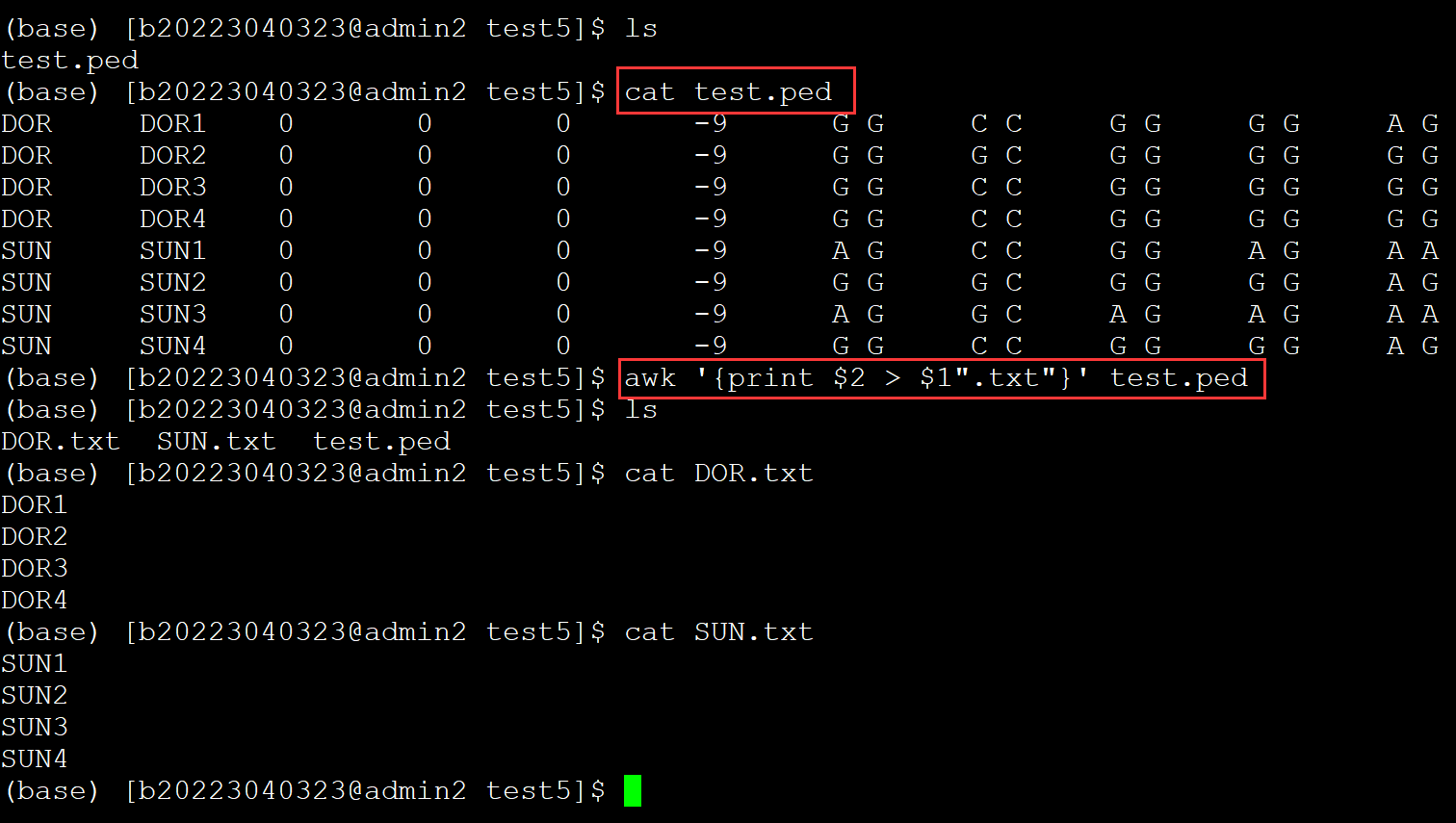
002、同理可以导出指定的字段
(base) [b20223040323@admin2 test5]$ ls test.ped (base) [b20223040323@admin2 test5]$ cat test.ped DOR DOR1 0 0 0 -9 G G C C G G G G A G DOR DOR2 0 0 0 -9 G G G C G G G G G G DOR DOR3 0 0 0 -9 G G C C G G G G G G DOR DOR4 0 0 0 -9 G G C C G G G G G G SUN SUN1 0 0 0 -9 A G C C G G A G A A SUN SUN2 0 0 0 -9 G G G C G G G G A G SUN SUN3 0 0 0 -9 A G G C A G A G A A SUN SUN4 0 0 0 -9 G G C C G G G G A G (base) [b20223040323@admin2 test5]$ awk '{print $2 > $1".txt"}' test.ped ## 这里导出的时第二个字段,输出结果保存到以第一列+".txt" 命名的文件中 (base) [b20223040323@admin2 test5]$ ls DOR.txt SUN.txt test.ped (base) [b20223040323@admin2 test5]$ cat DOR.txt DOR1 DOR2 DOR3 DOR4 (base) [b20223040323@admin2 test5]$ cat SUN.txt SUN1 SUN2 SUN3 SUN4
。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号