

linux 中根据指定列的重复或者唯一输出文本
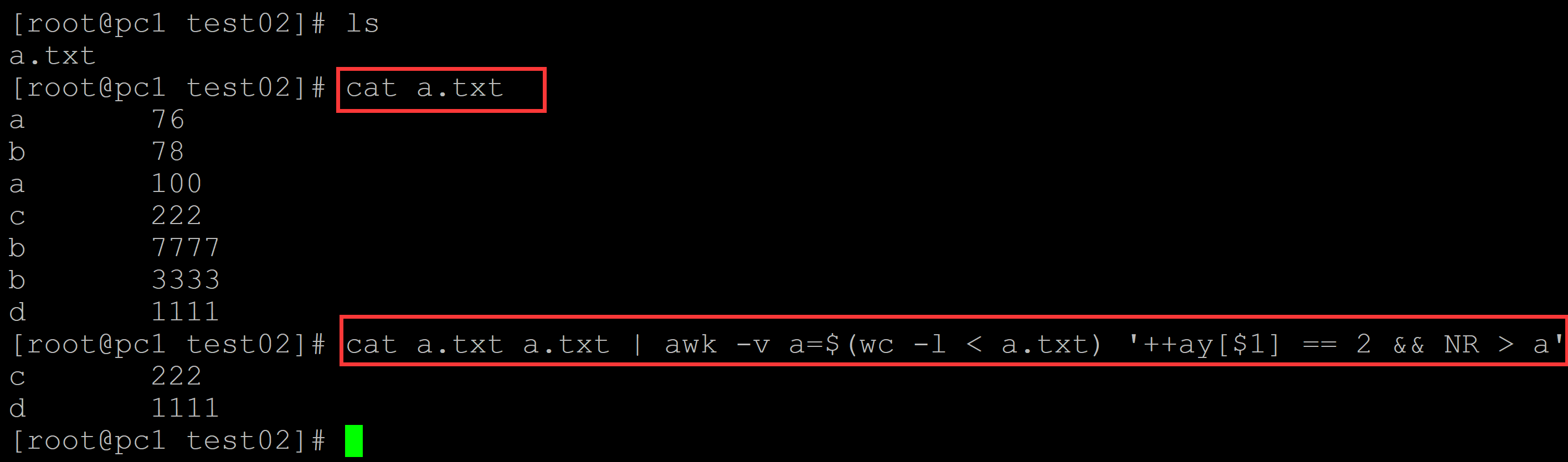
001、 输出第一列中没有重复的文本
[root@pc1 test02]# ls a.txt [root@pc1 test02]# cat a.txt ## 测试数据 a 76 b 78 a 100 c 222 b 7777 b 3333 d 1111 ## 先把文本叠加一次, 然后引入文本行数变量; 如果重复多次,在叠加后的文本的后半部分,计数最少是3开始,依据此进行过滤 [root@pc1 test02]# cat a.txt a.txt | awk -v a=$(wc -l < a.txt) '++ay[$1] == 2 && NR > a' c 222 d 1111
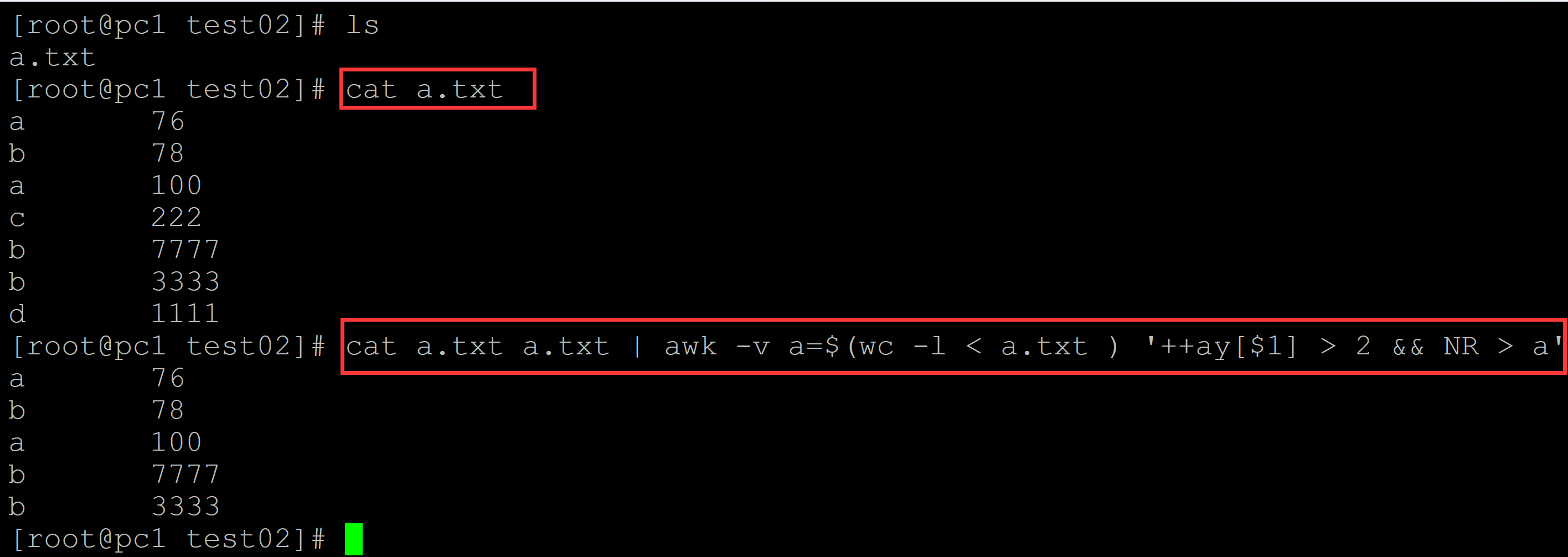
002、输出指定列有重复的文本
[root@pc1 test02]# ls a.txt [root@pc1 test02]# cat a.txt ## 测试数据 a 76 b 78 a 100 c 222 b 7777 b 3333 d 1111 ## 先把文本叠加一次; 然后记录文本行数; 在叠加后的文本的后半部分,最低的计数是3,据此提取重复 [root@pc1 test02]# cat a.txt a.txt | awk -v a=$(wc -l < a.txt ) '++ay[$1] > 2 && NR > a' a 76 b 78 a 100 b 7777 b 3333
。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号