

linux 中实现指定列进行去重复
001、 awk
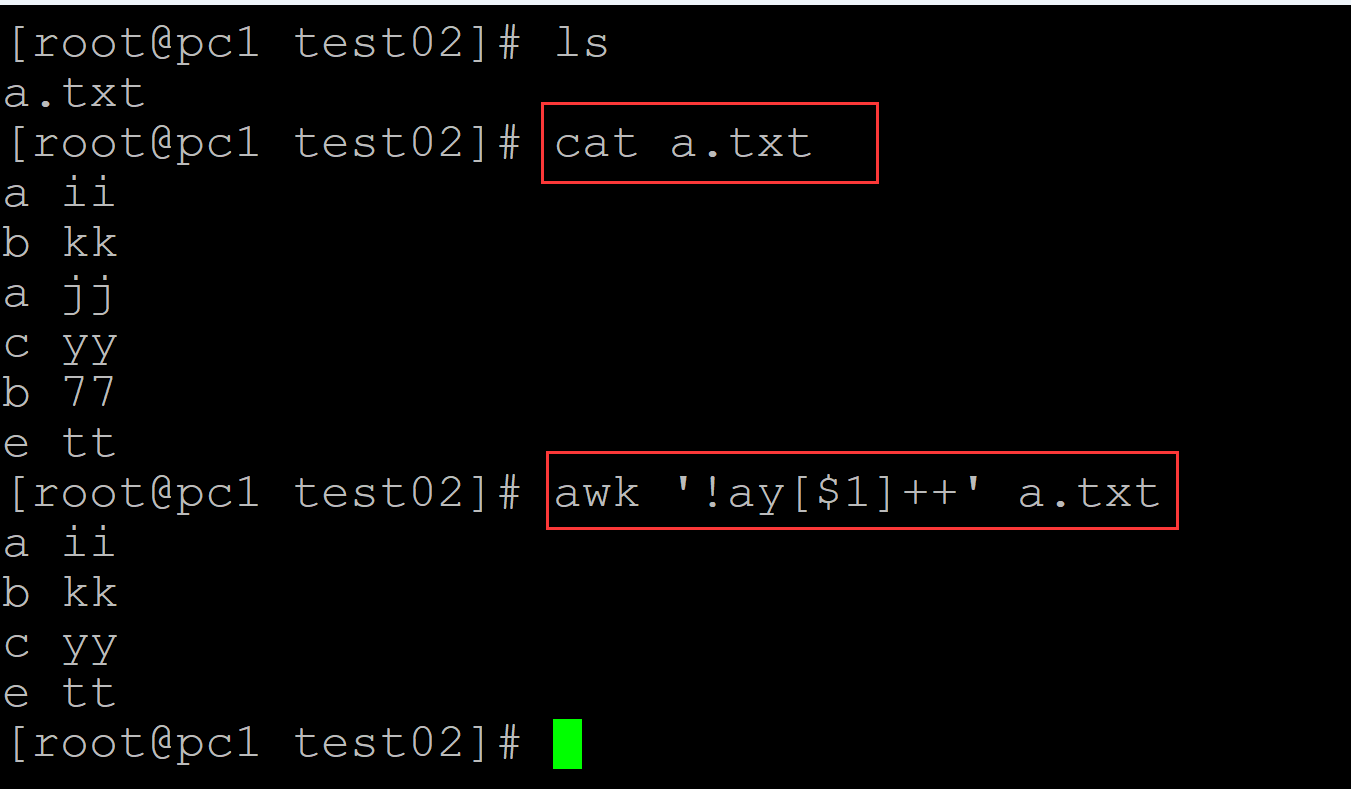
[root@pc1 test02]# ls a.txt [root@pc1 test02]# cat a.txt a ii b kk a jj c yy b 77 e tt [root@pc1 test02]# awk '!ay[$1]++' a.txt a ii b kk c yy e tt
002、 sort -u
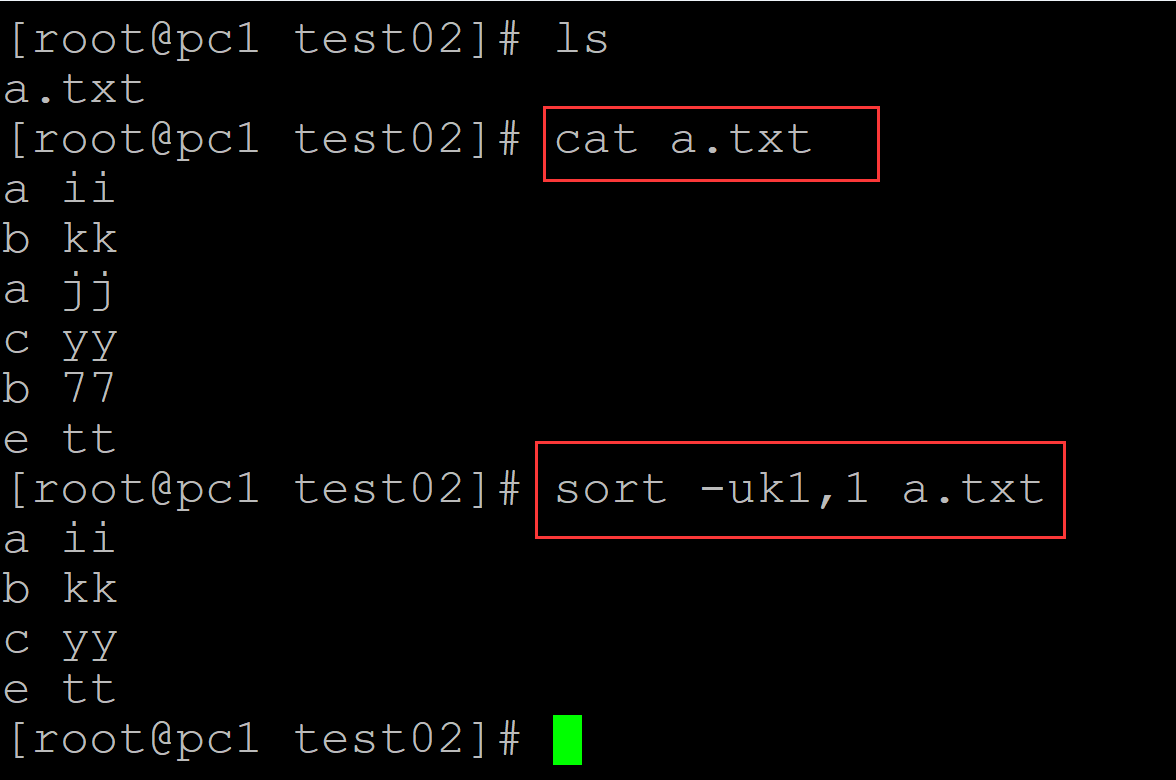
[root@pc1 test02]# ls a.txt [root@pc1 test02]# cat a.txt a ii b kk a jj c yy b 77 e tt ## 1,1 表示从第一个域开始,到第一个域结束 [root@pc1 test02]# sort -uk1,1 a.txt ## sort保留唯一的顺序是原始文件中最早出现的顺序 a ii b kk c yy e tt
。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号