

linux 中 awk命令中数组的应用
001、基本用法
[root@pc1 test4]# ls a.txt [root@pc1 test4]# cat a.txt a b c d b e a d e z b c a d e [root@pc1 test4]# awk '{print ay[$2]++}' a.txt 0 1 0 2 1 [root@pc1 test4]# awk '{print ++ay[$2]}' a.txt ## 记录指定列的元素重复的次数 1 2 1 3 2
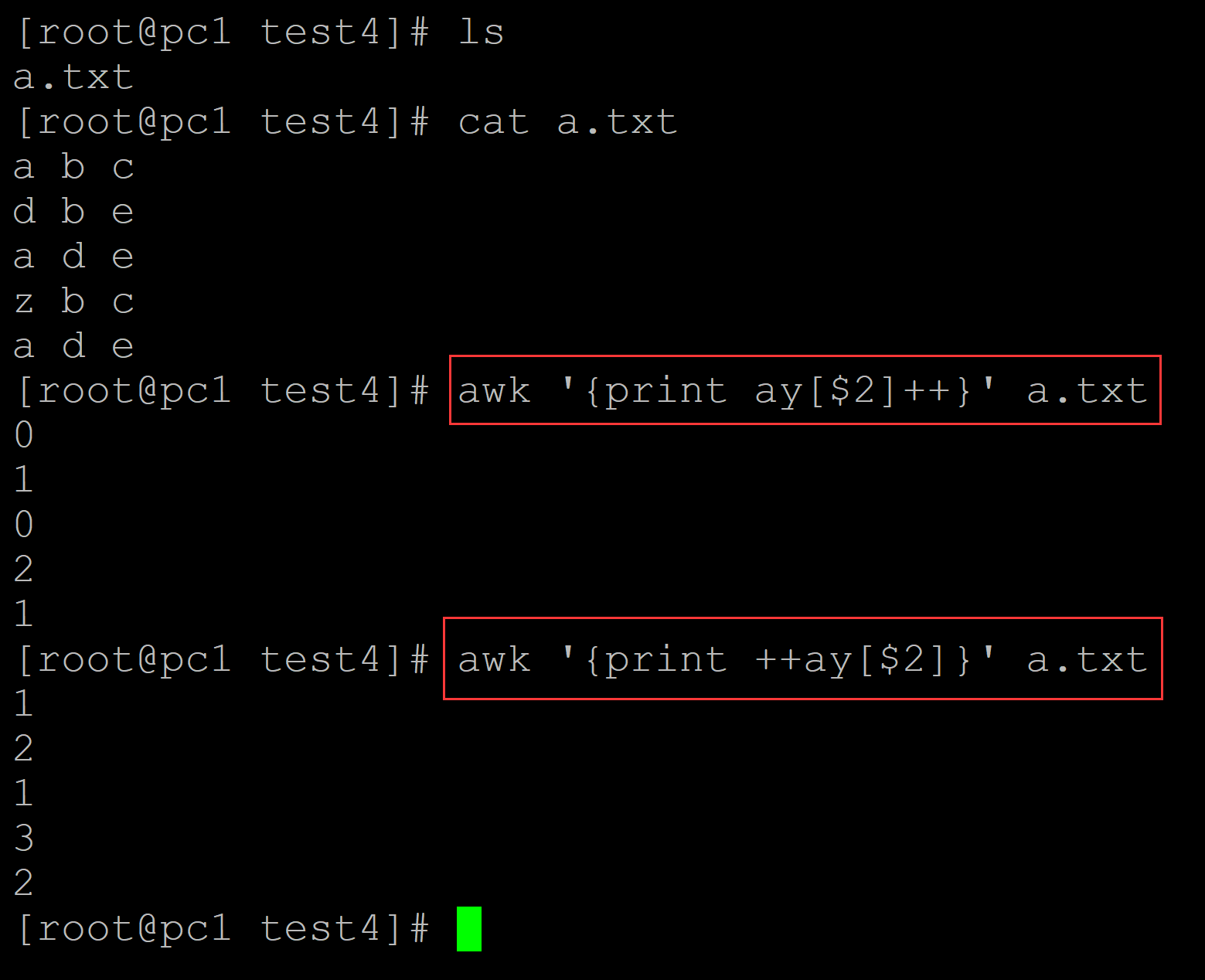
002、统计指定列中元素的频次
[root@pc1 test4]# ls a.txt [root@pc1 test4]# cat a.txt a b c d b e a d e z b c a d e [root@pc1 test4]# awk '{ay[$2]++} END {for(i in ay) print i, ay[i]}' a.txt b 3 d 2
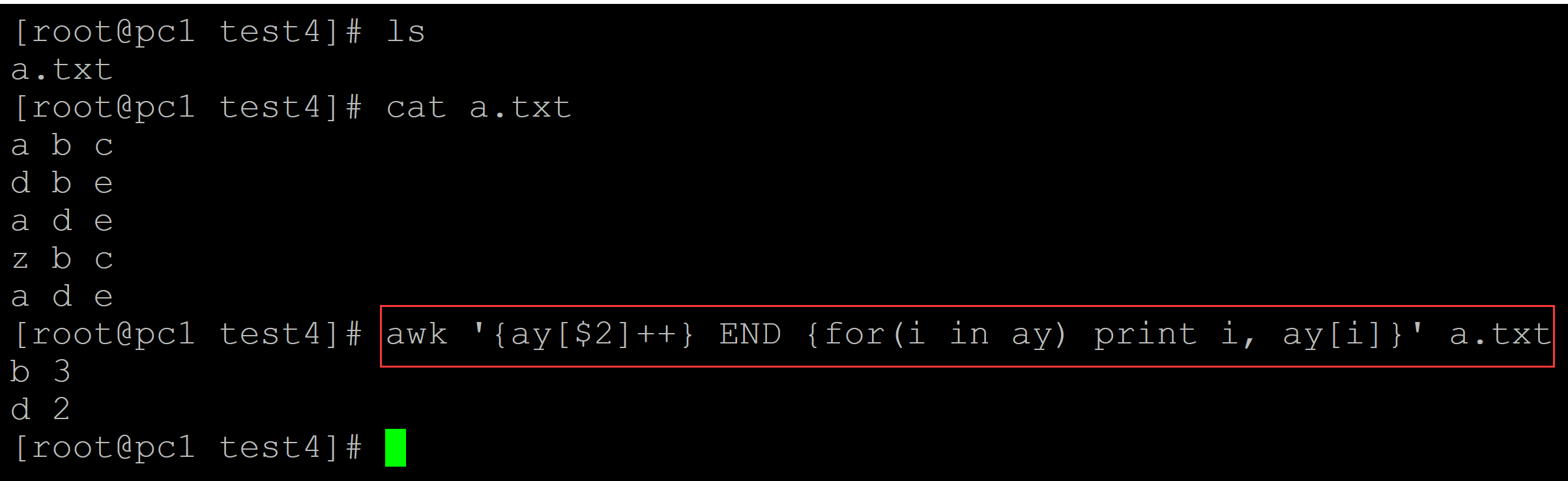
003、
[root@pc1 test4]# ls a.txt [root@pc1 test4]# cat a.txt a b c d b e a d e z b c a d e [root@pc1 test4]# awk 'ay[$1]++ {print $0}' a.txt ## 依据第一列取出重复数据 a d e a d e [root@pc1 test4]# awk 'ay[$2]++ {print $0}' a.txt ## 依据第二列取出重复数据 d b e z b c a d e
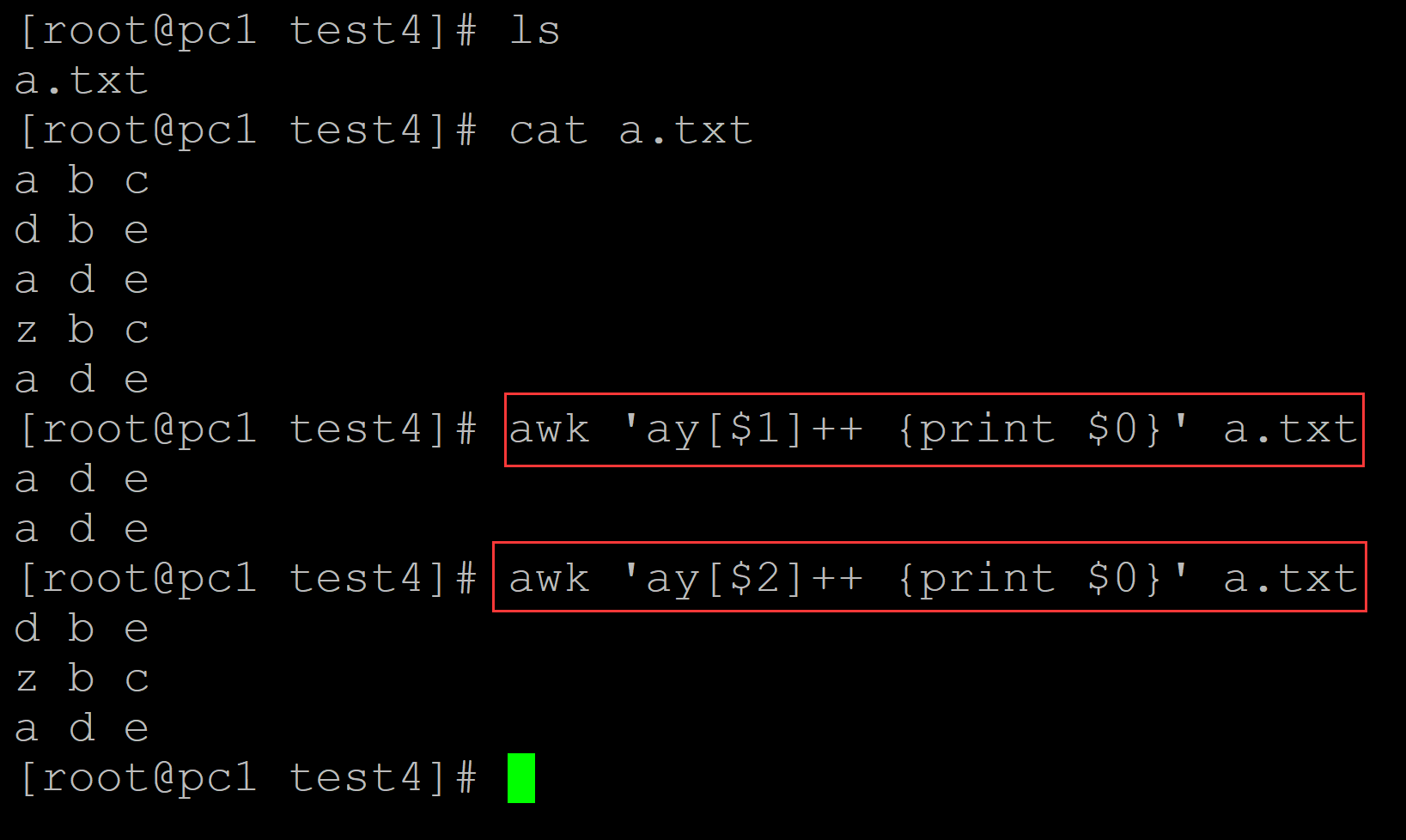
004、根据指定列剔除重复
[root@pc1 test4]# ls a.txt [root@pc1 test4]# cat a.txt a b c d b e a d e z b c a d e [root@pc1 test4]# awk '!ay[$1]++ {print $0}' a.txt ## 根据第一列剔除重复 a b c d b e z b c [root@pc1 test4]# awk '!ay[$2]++ {print $0}' a.txt ## 根据第二列剔除重复 a b c a d e
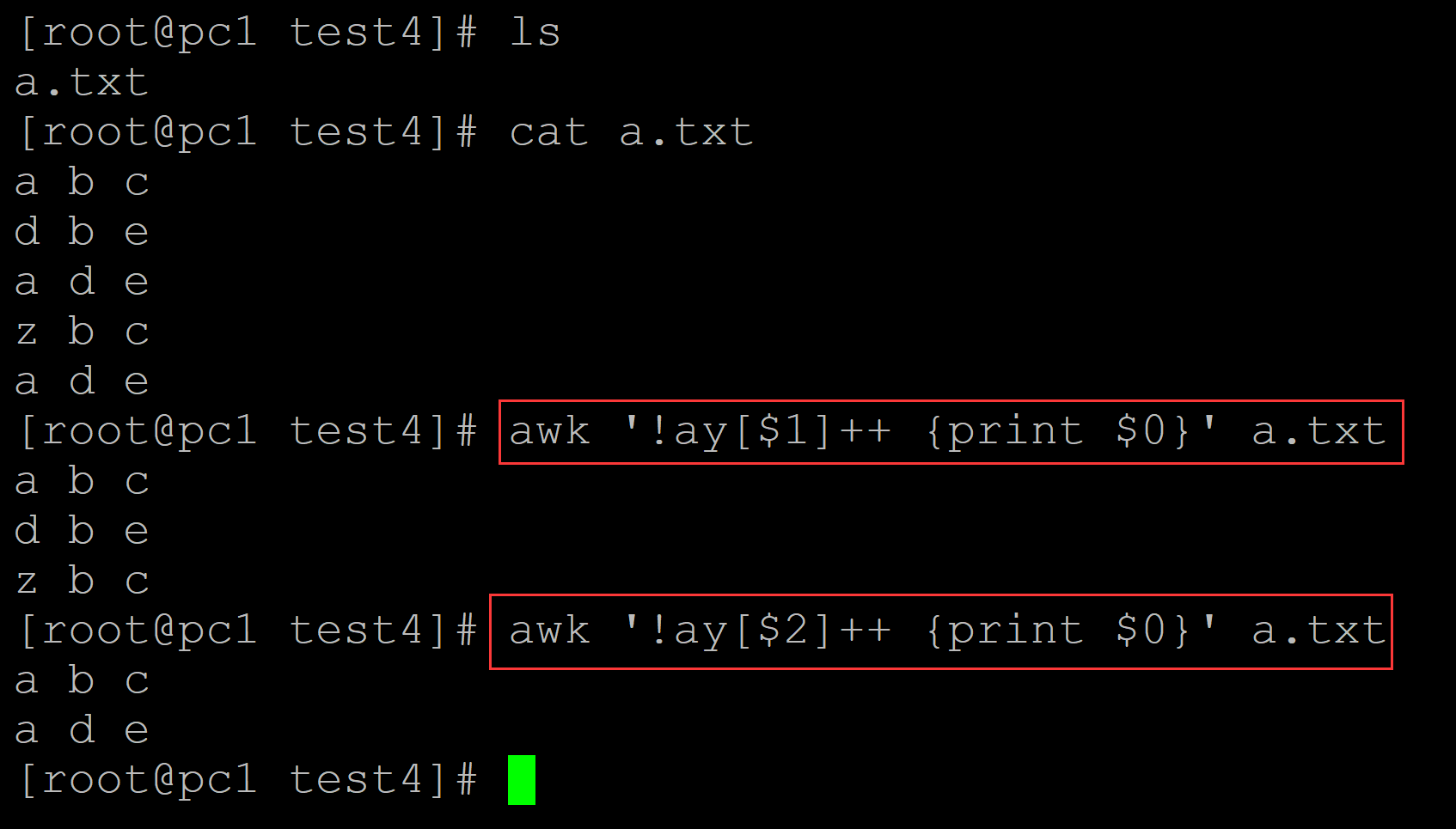

 浙公网安备 33010602011771号
浙公网安备 33010602011771号