
redis底层数据结构
1 SDS(动态数组结构)
struct sdshdr{ int len; int free; char buf[]; }
(1) len 保存了SDS保存字符串的长度
(2) buf[] 数组用来保存字符串的每个元素
(3) free j记录了 buf 数组中未使用的字节数量
使用sds的好处:
(1)常数复杂度获取字符串长度(2)杜绝缓冲溢出 (3)减少字符串的内存重新分配次数。
2 链表结构
typedef struct list{ //表头节点 listNode *head; //表尾节点 listNode *tail; //链表所包含的节点数量 unsigned long len; //节点值复制函数 void (*free) (void *ptr); //节点值释放函数 void (*free) (void *ptr); //节点值对比函数 int (*match) (void *ptr,void *key); }list;
redis链表特性:双端、无环、带链表长度计数器、多态。
3 字典
使用哈希表结构实现,c语言没有自带的字典结构,redis自己实现了这一数据结构。其中字典中的数组table组成,每个dictEntry由键值对和指向下一个dictEntry实现。用以解决hash冲突。
hash数组每次扩容是根据已经使用的元素个数的两倍进行扩展的。当正在执行时。负载因子大于等于5,进行扩容。当不执行时,负载因子大于等于1时就会进行扩容。
渐进式rehash,当hashtable保存的数据过多时,不能一次性rehash,所以会在查找时如果第一个hash表找不到,会去第二个hash表进行查找。Redis的字典底层使用哈希表实现,每个字典通常有两个哈希表,一个平时使用,另一个用于rehash时使用,使用链地址法解决哈希冲突。
4 跳跃表
通过在每个节点维持多个指向其他节点的指针,从而达到快速访问。
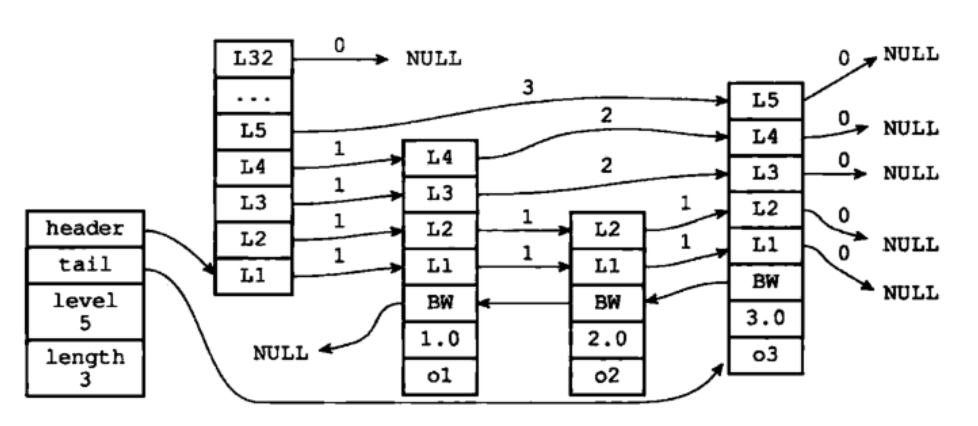
原图参考:https://www.cnblogs.com/ysocean/p/9080942.html#_label0
①、搜索:从最高层的链表节点开始,如果比当前节点要大和比当前层的下一个节点要小,那么则往下找,也就是和当前层的下一层的节点的下一个节点进行比较,以此类推,一直找到最底层的最后一个节点,如果找到则返回,反之则返回空。
②、插入:首先确定插入的层数,有一种方法是假设抛一枚硬币,如果是正面就累加,直到遇见反面为止,最后记录正面的次数作为插入的层数。当确定插入的层数k后,则需要将新元素插入到从底层到k层。
③、删除:在各个层中找到包含指定值的节点,然后将节点从链表中删除即可,如果删除以后只剩下头尾两个节点,则删除这一层。
5 整数集合
redis用于保存整数集合的数据结构,并且保证数组中不会出现重复的数据。数组中的数据按照大小排列,length记录了数组的大小。
升级:当新增元素类型长度大于原来元素的长度时,需要进行升级,将底层数组升级、重新分配存储空间后,将所有元素放在正确位置。
6 总结
大多数情况下,Redis使用简单字符串SDS作为字符串的表示,相对于C语言字符串,SDS具有常数复杂度获取字符串长度,杜绝了缓存区的溢出,减少了修改字符串长度时所需的内存重分配次数,以及二进制安全能存储各种类型的文件,并且还兼容部分C函数。
通过为链表设置不同类型的特定函数,Redis链表可以保存各种不同类型的值,除了用作列表键,还在发布与订阅、慢查询、监视器等方面发挥作用(后面会介绍)。
Redis的字典底层使用哈希表实现,每个字典通常有两个哈希表,一个平时使用,另一个用于rehash时使用,使用链地址法解决哈希冲突。
跳跃表通常是有序集合的底层实现之一,表中的节点按照分值大小进行排序。
整数集合是集合键的底层实现之一,底层由数组构成,升级特性能尽可能的节省内存。
压缩列表是Redis为节省内存而开发的顺序型数据结构,通常作为列表键和哈希键的底层实现之一。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号