列式数据库管理系统——ClickHouse实战演练
一、前言
ClickHouse的基础概念和环境部署,可以参考我之前的文章:列式数据库管理系统——ClickHouse(version:22.7.1 环境部署)
二、SQL语法讲解与实战操作
ClickHouse有2类解析器:完整SQL解析器(递归式解析器),以及数据格式解析器(快速流式解析器) 除了 INSERT 查询,其它情况下仅使用完整SQL解析器。 官方文档:https://clickhouse.com/docs/zh/sql-reference/syntax
1)数据库
1、创建数据库
【语法】
`CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster] [ENGINE = engine(...)]`
IF NOT EXISTS:如果db_name数据库已经存在,则ClickHouse不会创建新数据库并且:- 如果指定了子句,则不会引发异常。
- 如果未指定子句,则抛出异常。
ON CLUSTER:ClickHouse在指定集群的所有服务器上创建db_name数据库。ENGINE:指定数据库引擎,默认情况下,ClickHouse使用Atomic,还有其它引擎:数据库引擎
【示例1】单点操作
# 登录
clickhouse-client -h local-168-182-111 -d default -m -u default --password 123456
# 不指定数据库引擎,默认使用Atomic引擎,不指定集群,则只在当前击节点有效,其它节点是不会有这个库的
create database if not exists ck_test;

默认的数据库是磁盘上的一个文件目录,执行创建之后可以在数据目录下创建文件:
ls -l /var/lib/clickhouse/data/
# 可以看相关的元数据
ls -l /var/lib/clickhouse/metadata
# 查看数据库引擎
cat /var/lib/clickhouse/metadata/ck_test.sql

# 登录
clickhouse-client -h local-168-182-111 -d default -m -u default --password 123456
# 查看
show databases;
# 查看创建数据库的语句
show create database ck_test\G;
# 删除数据库
drop database ck_test;
# 检查
show databases;

【示例2】集群操作
# 登录
clickhouse-client -h local-168-182-111 -d default -m -u default --password 123456
# 查看集群
select * from system.clusters;
# 先查看
show databases;
# 不指定数据库引擎,默认使用Atomic引擎,指定集群
create database if not exists ck_test ON CLUSTER ck_cluster_2022;
# 检查
show databases;

【示例3】集群操作切换MYSQL引擎
【语法】
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
引擎参数
- host:port — MySQL服务地址
- database — MySQL数据库名称
- user — MySQL用户名
- password — MySQL用户密码
【示例】MySQL操作
mysql -uroot -p -h local-168-182-113
密码:123456
# 创建数据库
create database ck_test001;
USE ck_test001;
CREATE TABLE `ck_test001`.`mysql_table` (
`int_id` INT NOT NULL AUTO_INCREMENT,
`float` FLOAT NOT NULL,
PRIMARY KEY (`int_id`));
show tabels;
# 添加数据
insert into mysql_table (`int_id`, `float`) VALUES (1,2);
# 查看数据
select * from mysql_table;

ClickHouse操作
# 登录
clickhouse-client -h local-168-182-111 -d default -m -u default --password 123456
# 创建数据库使用mysql引擎
create database if not exists mysql_db ON CLUSTER ck_cluster_2022 ENGINE = MySQL('local-168-182-113:3306', 'ck_test001', 'root', '123456');
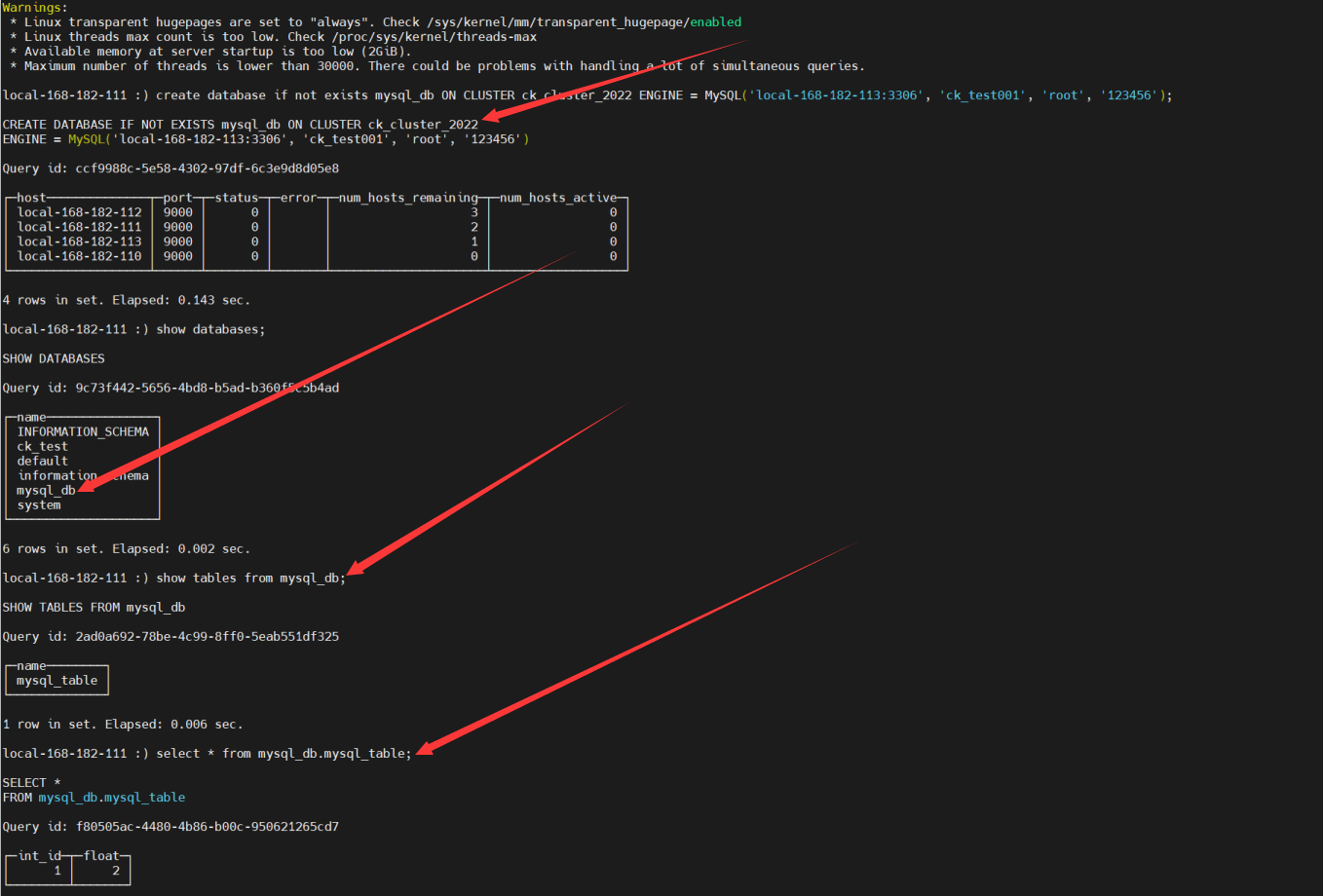
2)数据表
ClickHouse默认的表引擎是MergeTree,更多表引擎,可以参考官方文档,这里会讲主要的几种:MergeTree、MYSQL、HDFS、Hive、KAFKA。
1、MergeTree
【语法】
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
参数解释
-
ENGINE——引擎名和参数。 ENGINE = MergeTree(). MergeTree 引擎没有参数。 -
ORDER BY—— 排序键。- 可以是一组列的元组或任意的表达式。 例如: ORDER BY (CounterID, EventDate) 。
- 如果没有使用 PRIMARY KEY 显式指定的主键,ClickHouse 会使用排序键作为主键。
- 如果不需要排序,可以使用 ORDER BY tuple(). 参考 选择主键
-
PARTITION BY——分区键 ,可选项。
要按月分区,可以使用表达式 toYYYYMM(date_column) ,这里的 date_column 是一个 Date 类型的列。分区名的格式会是 "YYYYMM" 。
PRIMARY KEY——如果要 选择与排序键不同的主键,在这里指定,可选项。
默认情况下主键跟排序键(由 ORDER BY 子句指定)相同。 因此,大部分情况下不需要再专门指定一个 PRIMARY KEY 子句。
SAMPLE BY- 用于抽样的表达式,可选项。
如果要用抽样表达式,主键中必须包含这个表达式。例如: SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID)) 。
TTL——指定行存储的持续时间并定义数据片段在硬盘和卷上的移动逻辑的规则列表,可选项。
# 表达式中必须存在至少一个 Date 或 DateTime 类型的列,比如:
TTL date + INTERVAl 1 DAY
-
SETTINGS—— 控制 MergeTree 行为的额外参数,可选项:index_granularity——索引粒度。索引中相邻的『标记』间的数据行数。默认值8192 。参考数据存储。index_granularity_bytes——索引粒度,以字节为单位,默认值:10Mb。如果想要仅按数据行数限制索引粒度, 请设置为0(不建议)。min_index_granularity_bytes——允许的最小数据粒度,默认值:1024b。该选项用于防止误操作,添加了一个非常低索引粒度的表。enable_mixed_granularity_parts——是否启用通过 index_granularity_bytes 控制索引粒度的大小。在19.11版本之前, 只有 index_granularity 配置能够用于限制索引粒度的大小。当从具有很大的行(几十上百兆字节)的表中查询数据时候,index_granularity_bytes 配置能够提升ClickHouse的性能。如果您的表里有很大的行,可以开启这项配置来提升SELECT 查询的性能。use_minimalistic_part_header_in_zookeeper——ZooKeeper中数据片段存储方式 。如果use_minimalistic_part_header_in_zookeeper=1 ,ZooKeeper 会存储更少的数据。min_merge_bytes_to_use_direct_io——使用直接 I/O 来操作磁盘的合并操作时要求的最小数据量。合并数据片段时,ClickHouse 会计算要被合并的所有数据的总存储空间。如果大小超过了 min_merge_bytes_to_use_direct_io 设置的字节数,则 ClickHouse 将使用直接 I/O 接口(O_DIRECT 选项)对磁盘读写。如果设置 min_merge_bytes_to_use_direct_io = 0 ,则会禁用直接 I/O。默认值:10 * 1024 * 1024 * 1024字节。merge_with_ttl_timeout——TTL合并频率的最小间隔时间,单位:秒。默认值:86400(1 天)。write_final_mark——是否启用在数据片段尾部写入最终索引标记。默认值: 1(不要关闭)。merge_max_block_size——在块中进行合并操作时的最大行数限制。默认值:8192storage_policy——存储策略min_bytes_for_wide_part,min_rows_for_wide_part——在数据片段中可以使用Wide格式进行存储的最小字节数/行数。您可以不设置、只设置一个,或全都设置。max_parts_in_total- 所有分区中最大块的数量(意义不明)max_compress_block_size——在数据压缩写入表前,未压缩数据块的最大大小。您可以在全局设置中设置该值(参见max_compress_block_size)。建表时指定该值会覆盖全局设置。min_compress_block_size——在数据压缩写入表前,未压缩数据块的最小大小。建表时指定该值会覆盖全局设置。max_partitions_to_read——一次查询中可访问的分区最大数。。
示例配置
ENGINE MergeTree() PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate, intHash32(UserID)) SAMPLE BY intHash32(UserID) SETTINGS index_granularity=8192
同时我们设置了一个按用户 ID 哈希的抽样表达式。这使得您可以对该表中每个 CounterID 和 EventDate 的数据伪随机分布。如果您在查询时指定了 SAMPLE 子句。 ClickHouse会返回对于用户子集的一个均匀的伪随机数据采样。
index_granularity可省略因为 8192 是默认设置 。
【示例1】简单使用
-- 创建本地数据库
create database if not exists ck_test002;
-- 创建本地表
CREATE TABLE ck_test002.example_table
(
d DateTime,
a Int TTL d + INTERVAL 1 MONTH,
b Int TTL d + INTERVAL 1 MONTH,
c String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d;
show tables from ck_test002;
【示例2】使用多个块设备进行数据存储
MergeTree 系列表引擎可以将数据存储在多个块设备上。这对某些可以潜在被划分为“冷”“热”的表来说是很有用的。为了应用存储策略,可以在建表时使用storage_policy设置。
【配置】磁盘、卷和存储策略应当在主配置文件 /etc/clickhouse-server/config.xml 或 /etc/clickhouse-server/config.d 目录中的独立文件中的 <storage_configuration> 标签内定义。
示例配置如下:
# 创建存储路径
mkdir -p /var/lib/clickhouse/storage001/data{1..3}
# 授权
chown -R clickhouse:clickhouse /var/lib/clickhouse/storage001
存储配置如下:
<storage_configuration>
<disks>
<disk1> <!-- disk name -->
<path>/var/lib/clickhouse/storage001/data1/</path>
</disk1>
<disk2>
<path>/var/lib/clickhouse/storage001/data2/</path>
<keep_free_space_bytes>10485760</keep_free_space_bytes>
</disk2>
<disk3>
<path>/var/lib/clickhouse/storage001/data3/</path>
<keep_free_space_bytes>10485760</keep_free_space_bytes>
</disk3>
</disks>
</storage_configuration>
<disk_name_N>— 磁盘名,名称必须与其他磁盘不同.path— 服务器将用来存储数据 (data 和 shadow 目录) 的路径, 应当以 ‘/’ 结尾.keep_free_space_bytes— 需要保留的剩余磁盘空间。
存储策略配置:
<storage_configuration>
<policies>
<hdd_in_order> <!-- policy name -->
<volumes>
<single> <!-- volume name -->
<disk>disk1</disk>
</single>
</volumes>
</hdd_in_order>
<moving_from_ssd_to_hdd> <!-- policy name -->
<volumes>
<hot> <!-- volume name -->
<disk>disk2</disk>
<max_data_part_size_bytes>1073741824</max_data_part_size_bytes>
</hot>
<cold> <!-- volume name -->
<disk>disk3</disk>
</cold>
</volumes>
<move_factor>0.2</move_factor>
</moving_from_ssd_to_hdd>
</policies>
</storage_configuration>
标签:
disk— 卷中的磁盘。max_data_part_size_bytes— 卷中的磁盘可以存储的数据片段的最大大小。move_factor— 当可用空间少于这个因子时,数据将自动的向下一个卷(如果有的话)移动 (默认值为 0.1)。prefer_not_to_merge- 禁止在这个卷中进行数据合并。该选项启用时,对该卷的数据不能进行合并。这个选项主要用于慢速磁盘。
完整配置(/etc/clickhouse-server/config.d/storage001.xml):
<yandex>
<storage_configuration>
<!-- 存储配置 -->
<disks>
<disk1> <!-- disk name -->
<path>/var/lib/clickhouse/storage001/data1/</path>
</disk1>
<disk2>
<path>/var/lib/clickhouse/storage001/data2/</path>
<keep_free_space_bytes>10485760</keep_free_space_bytes>
</disk2>
<disk3>
<path>/var/lib/clickhouse/storage001/data3/</path>
<keep_free_space_bytes>10485760</keep_free_space_bytes>
</disk3>
</disks>
<!-- 存储策略配置 -->
<policies>
<hdd_in_order> <!-- policy name -->
<volumes>
<single> <!-- volume name -->
<disk>disk1</disk>
</single>
</volumes>
</hdd_in_order>
<moving_from_ssd_to_hdd> <!-- policy name -->
<volumes>
<hot> <!-- volume name -->
<disk>disk2</disk>
<max_data_part_size_bytes>1073741824</max_data_part_size_bytes>
</hot>
<cold> <!-- volume name -->
<disk>disk3</disk>
</cold>
</volumes>
<move_factor>0.2</move_factor>
</moving_from_ssd_to_hdd>
</policies>
</storage_configuration>
</yandex>
授权
chown -R clickhouse.clickhouse /etc/clickhouse-server/config.d
查看(配置自动加载,不需要重启服务)
# 登录
clickhouse-client -u default --password 123456 --port 9000 -h local-168-182-110 --multiquery
# 检查
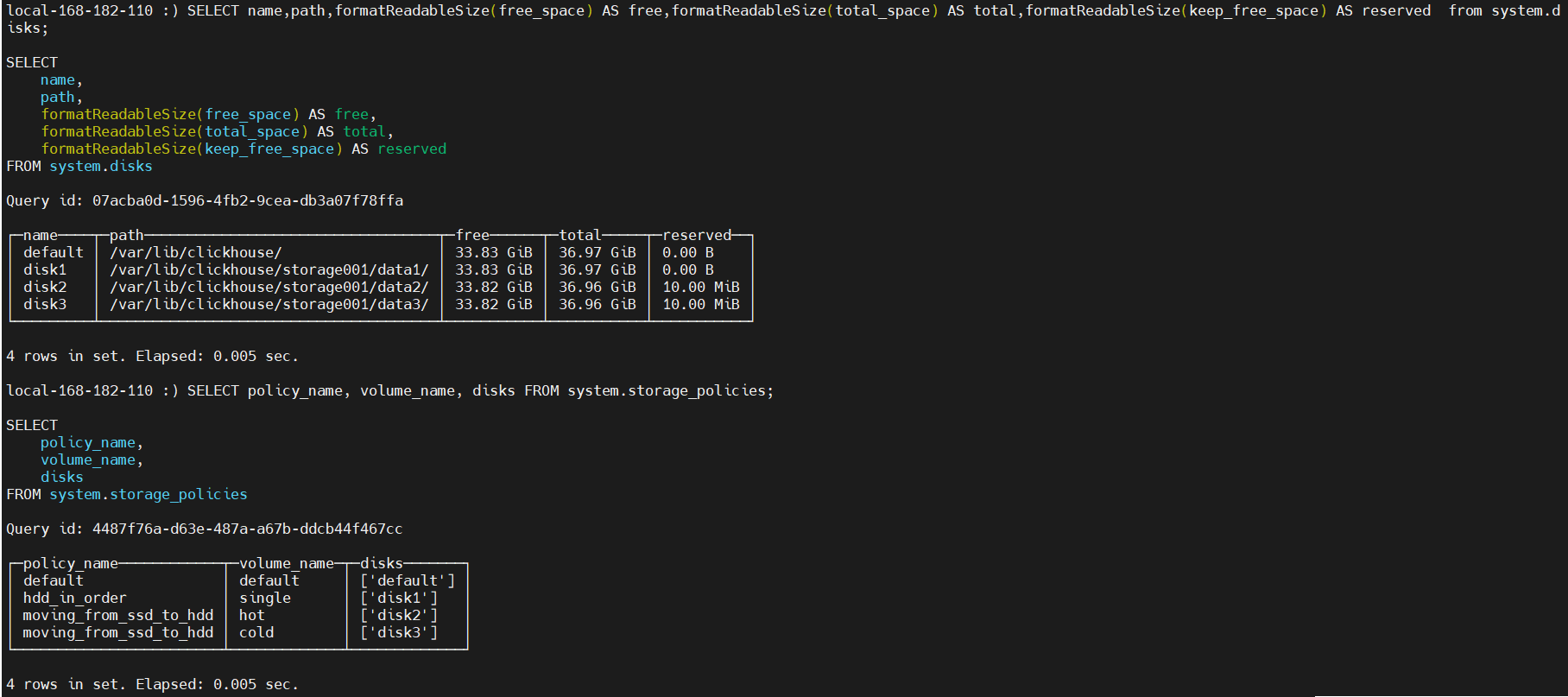
SELECT name,path,formatReadableSize(free_space) AS free,formatReadableSize(total_space) AS total,formatReadableSize(keep_free_space) AS reserved from system.disks;
SELECT policy_name, volume_name, disks FROM system.storage_policies;
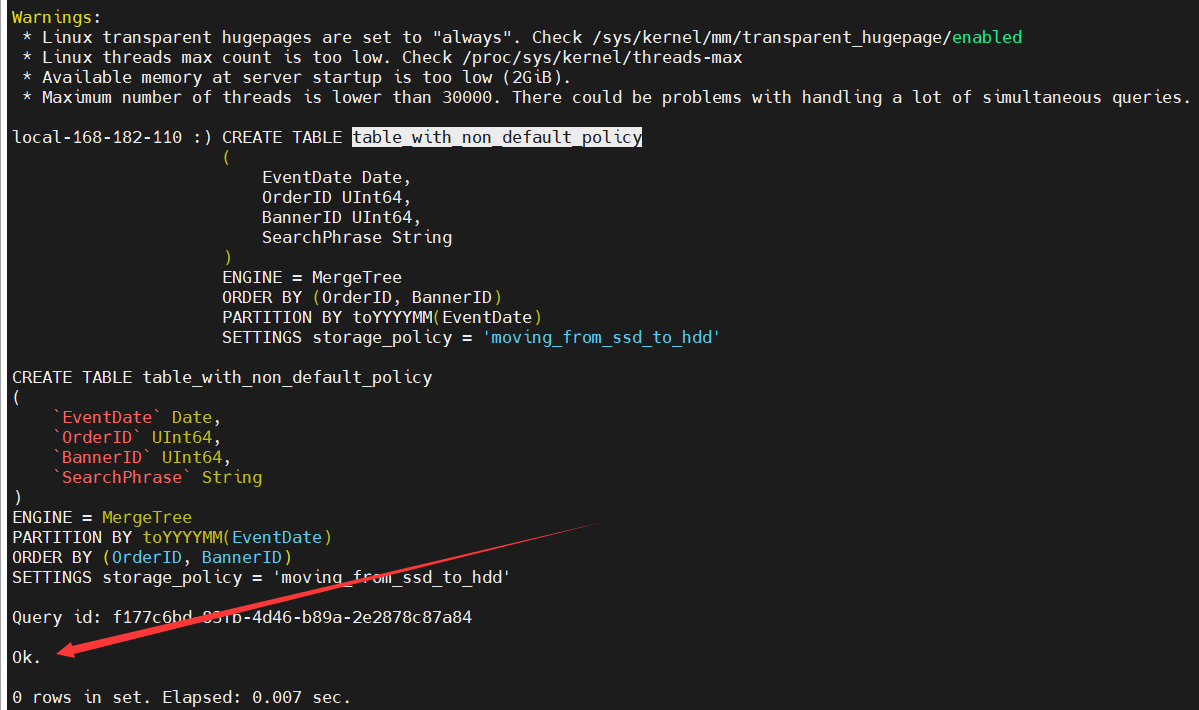
在创建表时,指定存储策略(默认default):
CREATE TABLE table_with_non_default_policy
(
EventDate Date,
OrderID UInt64,
BannerID UInt64,
SearchPhrase String
)
ENGINE = MergeTree
ORDER BY (OrderID, BannerID)
PARTITION BY toYYYYMM(EventDate)
SETTINGS storage_policy = 'moving_from_ssd_to_hdd'
2、MYSQL
MySQL 引擎可以对存储在远程 MySQL 服务器上的数据执行 SELECT 查询。
【语法】
MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);
参数详解:
host:port— MySQL 服务器地址。database— 数据库的名称。table— 表名称。user— 数据库用户。password— 用户密码。replace_query— 将 INSERT INTO 查询是否替换为 REPLACE INTO 的标志。如果replace_query=1,则替换查询。【可选】on_duplicate_clause— 将 ON DUPLICATE KEY UPDATE - 'on_duplicate_clause' 表达式添加到 INSERT 查询语句中。例如:impression = VALUES(impression) + impression。如果需要指定 'on_duplicate_clause',则需要设置 replace_query=0。如果同时设置 replace_query = 1 和 'on_duplicate_clause',则会抛出异常。【可选】
【示例】
MySQL操作
mysql -uroot -p -h local-168-182-113
密码:123456
# 创建数据库
create database if not exists ck_test003;
USE ck_test003;
CREATE TABLE `ck_test003`.`user` (
`id` bigint NOT NULL AUTO_INCREMENT,
`account_no` bigint DEFAULT NULL,
`phone` varchar(128) COMMENT '手机号',
`username` varchar(255) COMMENT '用户名',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
# 添加数据
INSERT INTO `ck_test003`.`user`(`id`, `account_no`, `phone`, `username`, `create_time`)
VALUES (1, 35, '00719526', 'zhangsan', '2022-07-24 16:02:15');
# 查看数据
select * from `ck_test003`.`user`;
在clickhouse中创建user表,设置引擎为mysql
# 登录
clickhouse-client -h local-168-182-111 -d default -m -u default --password 123456
create database if not exists ck_mysql_test003;
# 创建表,字段得跟mysql表一一对应
CREATE TABLE `ck_mysql_test003`.`user`(
id UInt32 ,
account_no UInt32 ,
username String ,
phone String ,
create_time Datetime
)
ENGINE = MySQL(
'local-168-182-113:3306',
'ck_test003',
'user',
'root',
'123456');
# 在clickhouse查询mysql数据
select * from `ck_mysql_test003`.`user`;

在clickhouse中添加数据
# 登录
clickhouse-client -h local-168-182-111 -d default -m -u default --password 123456
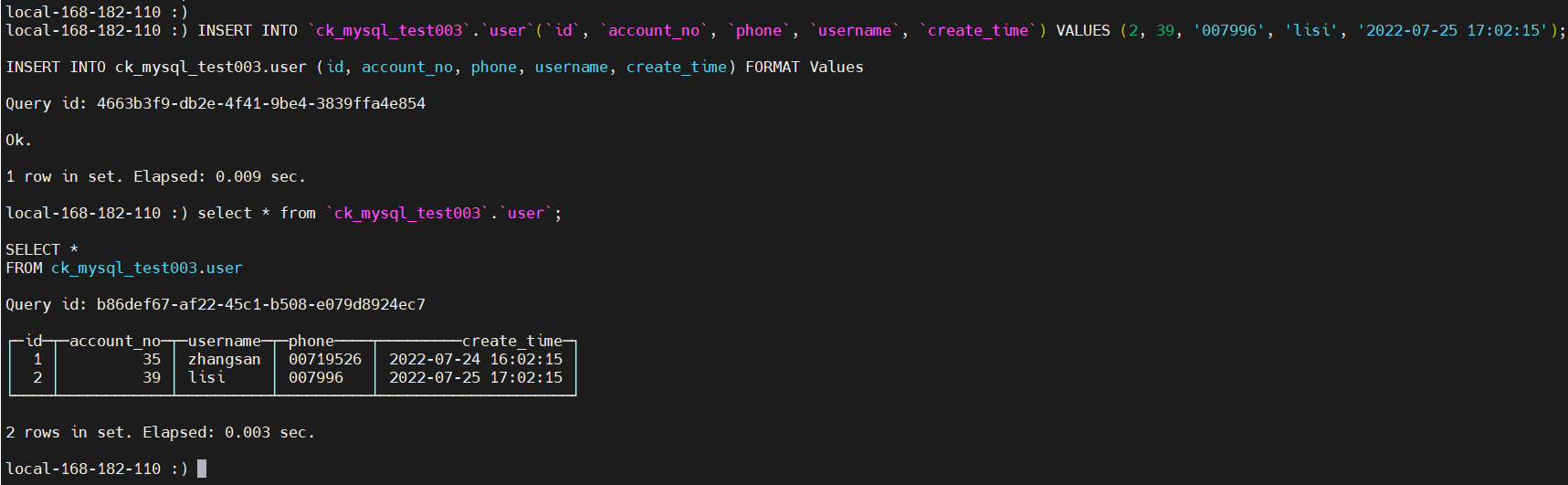
# 添加数据
INSERT INTO `ck_mysql_test003`.`user`(`id`, `account_no`, `phone`, `username`, `create_time`) VALUES (2, 39, '007996', 'lisi', '2022-07-25 17:02:15');
# 查询
select * from `ck_mysql_test003`.`user`;
在mysql中查询
mysql -uroot -p -h local-168-182-113
密码:123456
select * from `ck_test003`.`user`;

3、HDFS(hadoop-3.3.3)
首选需要安装HDFS,可以参考我之前的文章:大数据Hadoop原理介绍+安装+实战操作(HDFS+YARN+MapReduce)
环境准备
| hostname | ip | 运行角色 |
|---|---|---|
| local-168-182-110 | local-168-182-110 | namenode,datanode ,resourcemanager,nodemanager |
| local-168-182-111 | local-168-182-111 | secondarynamedata,datanode,nodemanager |
| local-168-182-112 | local-168-182-112 | datanode,nodemanager |
这里不在讲部署的具体过程了,有不清楚的,可以看我上面的文章哦!!!
启动HDFS服务
start-dfs.sh
web访问:http://local-168-182-110:9870

创建ClickHouse存储目录
hdfs dfs -mkdir hdfs://local-168-182-110:8082/clickhouse
# 给目录授权
hdfs dfs -chown clickhouse:clickhouse hdfs://local-168-182-110:8082/clickhouse
继续说ClickHouse的HDFS引擎
这个引擎提供了与 Apache Hadoop 生态系统的集成,允许通过 ClickHouse 管理 HDFS 上的数据。这个引擎类似于 文件 和 URL 引擎,但提供了 Hadoop 的特定功能。
【语法】
ENGINE = HDFS(URI, format)
URI参数是 HDFS 中整个文件的 URI。format参数指定一种可用的文件格式。 执行 SELECT 查询时,格式必须支持输入,以及执行 INSERT 查询时,格式必须支持输出. 你可以在 格式 章节查看可用的格式。 路径部分 URI 可能包含 glob 通配符。 在这种情况下,表将是只读的。
【示例】创建 hdfs_engine_table 表
# 登录
clickhouse-client -h local-168-182-111 -d default -m -u default --password 123456
# 创建表,hdfs_engine_table这个目录是不能提前创建的
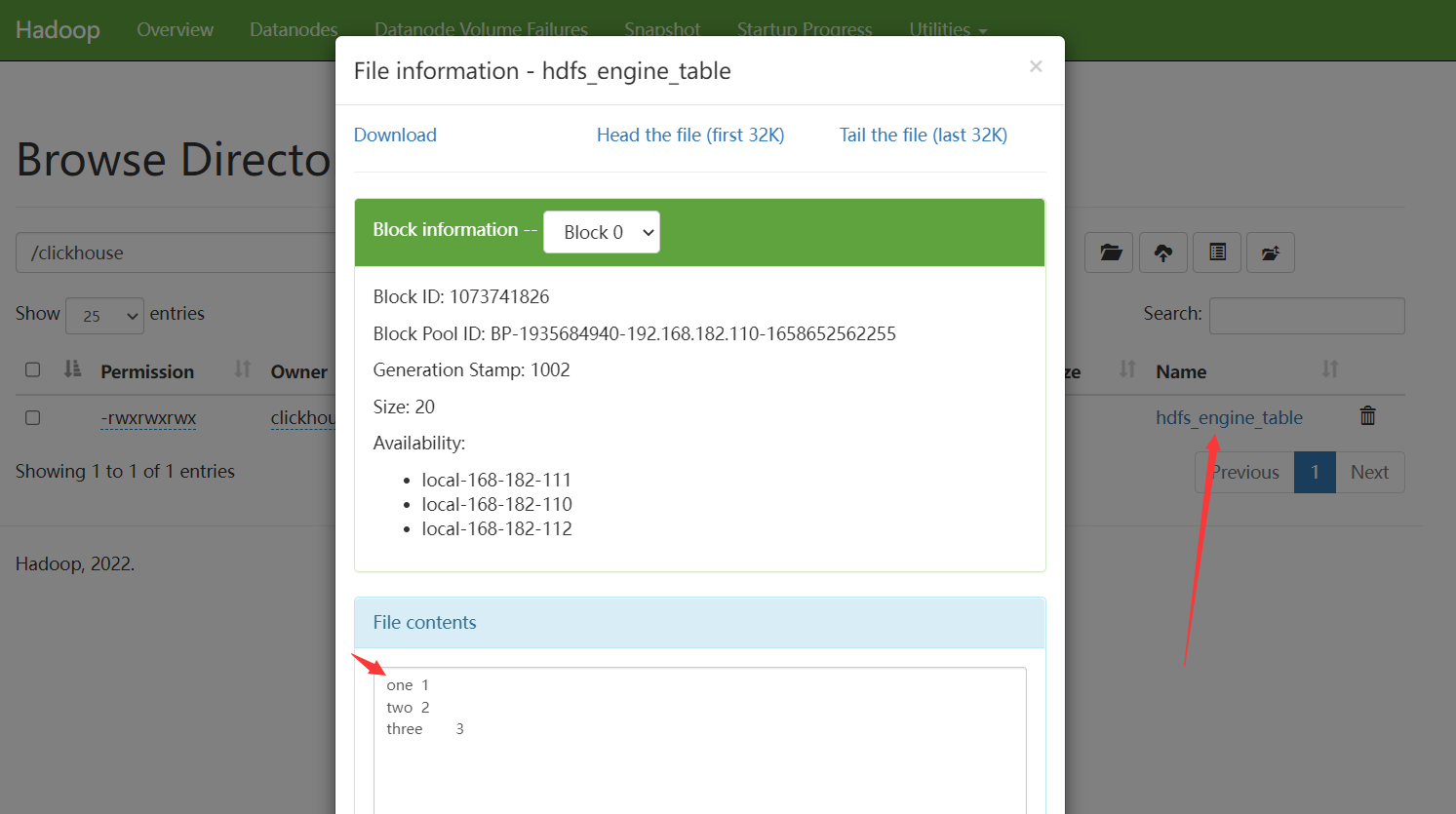
CREATE TABLE hdfs_engine_table (name String, value UInt32) ENGINE=HDFS('hdfs://local-168-182-110:8082/clickhouse/hdfs_engine_table', 'TSV');
# 添加数据
INSERT INTO hdfs_engine_table VALUES ('one', 1), ('two', 2), ('three', 3);

在HDFS上查看:http://local-168-182-110:9870
4、Hive(hive-3.1.3)
首选需要安装Hive,可以参考我之前的文章:大数据Hadoop之——数据仓库Hive
启动metastore服务
nohup hive --service metastore &
ss -atnlp|grep 9083
【语法】ClickHouse使用Hive引擎建表语法如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [ALIAS expr1],
name2 [type2] [ALIAS expr2],
...
) ENGINE = Hive('thrift://host:port', 'database', 'table');
PARTITION BY expr
参数:
-
thrift://host:port— Hive Metastore 地址 -
database— 远程数据库名. -
table— 远程数据表名.
使用HDFS文件系统的本地缓存,配置(/etc/clickhouse-server/config.xml)如下:
<local_cache_for_remote_fs>
<enable>true</enable>
<root_dir>local_cache</root_dir>
<limit_size>559096952</limit_size>
<bytes_read_before_flush>1048576</bytes_read_before_flush>
</local_cache_for_remote_fs>
enable: 开启后,ClickHouse将为HDFS (远程文件系统)维护本地缓存。root_dir: 必需的。用于存储远程文件系统的本地缓存文件的根目录。limit_size: 必需的。本地缓存文件的最大大小(单位为字节)。bytes_read_before_flush: 从远程文件系统下载文件时,刷新到本地文件系统前的控制字节数。缺省值为1MB。
【温馨提示】当ClickHouse为远程文件系统启用了本地缓存时,用户仍然可以选择不使用缓存,并在查询中设置
use_local_cache_for_remote_fs = 0, use_local_cache_for_remote_fs 默认为 false。
在 Hive 中建表:
hive > CREATE TABLE `test`.`test_orc`(
`f_tinyint` tinyint,
`f_smallint` smallint,
`f_int` int,
`f_integer` int,
`f_bigint` bigint,
`f_float` float,
`f_double` double,
`f_decimal` decimal(10,0),
`f_timestamp` timestamp,
`f_date` date,
`f_string` string,
`f_varchar` varchar(100),
`f_bool` boolean,
`f_binary` binary,
`f_array_int` array<int>,
`f_array_string` array<string>,
`f_array_float` array<float>,
`f_array_array_int` array<array<int>>,
`f_array_array_string` array<array<string>>,
`f_array_array_float` array<array<float>>)
PARTITIONED BY (
`day` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
'hdfs://testcluster/data/hive/test.db/test_orc'
OK
Time taken: 0.51 seconds
hive > insert into test.test_orc partition(day='2021-09-18') select 1, 2, 3, 4, 5, 6.11, 7.22, 8.333, current_timestamp(), current_date(), 'hello world', 'hello world', 'hello world', true, 'hello world', array(1, 2, 3), array('hello world', 'hello world'), array(float(1.1), float(1.2)), array(array(1, 2), array(3, 4)), array(array('a', 'b'), array('c', 'd')), array(array(float(1.11), float(2.22)), array(float(3.33), float(4.44)));
OK
Time taken: 36.025 seconds
hive > select * from test.test_orc;
OK
1 2 3 4 5 6.11 7.22 8 2021-11-05 12:38:16.314 2021-11-05 hello world hello world hello world true hello world [1,2,3] ["hello world","hello world"] [1.1,1.2] [[1,2],[3,4]] [["a","b"],["c","d"]] [[1.11,2.22],[3.33,4.44]] 2021-09-18
Time taken: 0.295 seconds, Fetched: 1 row(s)
在 ClickHouse 中建表,ClickHouse中的表,从上面创建的Hive表中获取数据:
CREATE TABLE test.test_orc
(
`f_tinyint` Int8,
`f_smallint` Int16,
`f_int` Int32,
`f_integer` Int32,
`f_bigint` Int64,
`f_float` Float32,
`f_double` Float64,
`f_decimal` Float64,
`f_timestamp` DateTime,
`f_date` Date,
`f_string` String,
`f_varchar` String,
`f_bool` Bool,
`f_binary` String,
`f_array_int` Array(Int32),
`f_array_string` Array(String),
`f_array_float` Array(Float32),
`f_array_array_int` Array(Array(Int32)),
`f_array_array_string` Array(Array(String)),
`f_array_array_float` Array(Array(Float32)),
`day` String
)
ENGINE = Hive('thrift://localhost:9083', 'test', 'test_orc')
PARTITION BY day;
# 查询
SELECT * FROM test.test_orc settings input_format_orc_allow_missing_columns = 1\G
5、KAFKA
首选需要安装KAFKA,可以参考我之前的文章:大数据Hadoop之——Kafka 图形化工具 EFAK(EFAK环境部署)
# 启动服务
cd $KAFKA_HOME
./bin/kafka-server-start.sh -daemon ./config/server.properties
# 创建topic
# 创建topic,1副本,1分区,设置数据过期时间72小时(-1表示不过期),单位ms,72*3600*1000=259200000
kafka-topics.sh --create --topic clickhouse --bootstrap-server local-168-182-110:9092,local-168-182-111:9092,local-168-182-112:9092 --partitions 1 --replication-factor 1 --config retention.ms=259200000
# 查看topic 列表
kafka-topics.sh --bootstrap-server local-168-182-110:9092,local-168-182-111:9092,local-168-182-112:9092 --list
继续回到ClickHouse的KAFKA引擎
【语法】
Kafka SETTINGS
kafka_broker_list = 'local-168-182-110:9092,local-168-182-111:9092,local-168-182-112:9092',
kafka_topic_list = 'clickhouse',
kafka_group_name = 'group1',
kafka_format = 'JSONEachRow',
kafka_row_delimiter = '\n',
kafka_schema = '',
kafka_num_consumers = 2
必要参数:
kafka_broker_list– 以逗号分隔的 brokers 列表 (localhost:9092)。kafka_topic_list– topic 列表 (clickhouse)。kafka_group_name– Kafka 消费组名称 (group1)。如果不希望消息在集群中重复,请在每个分片中使用相同的组名。kafka_format– 消息体格式。使用与 SQL 部分的 FORMAT 函数相同表示方法,例如 JSONEachRow。了解详细信息,请参考 Formats 部分。
可选参数:
kafka_row_delimiter- 每个消息体(记录)之间的分隔符。kafka_schema– 如果解析格式需要一个 schema 时,此参数必填。kafka_num_consumers– 单个表的消费者数量。默认值是:1,如果一个消费者的吞吐量不足,则指定更多的消费者。消费者的总数不应该超过 topic 中分区的数量,因为每个分区只能分配一个消费者。
【示例】
在kafka中添加数据
# 删除topic
kafka-topics.sh --delete --topic clickhouse --bootstrap-server local-168-182-110:9092,local-168-182-111:9092,local-168-182-112:9092
# 新建topic
kafka-topics.sh --create --topic clickhouse --bootstrap-server local-168-182-110:9092,local-168-182-111:9092,local-168-182-112:9092 --partitions 1 --replication-factor 1 --config retention.ms=259200000
# 添加数据(生产者),添加的数据字段要跟CH的字段对应
kafka-console-producer.sh --broker-list local-168-182-110:9092 --topic clickhouse
{"id":1,"createDate":"2022-08-01","message":"cliclhouse test1"}
{"id":2,"createDate":"2022-08-02","message":"cliclhouse test2"}
{"id":3,"createDate":"2022-08-03","message":"cliclhouse test3"}
# 消费
kafka-console-consumer.sh --bootstrap-server local-168-182-110:9092 --topic clickhouse --from-beginning

在ClickHouse中添加表
# 登录,需要加上--stream_like_engine_allow_direct_select 1
clickhouse-client -h local-168-182-111 -d default -m -u default --password 123456 --stream_like_engine_allow_direct_select 1
CREATE TABLE queue (
id Int16,
createDate Date,
message String
) ENGINE = Kafka('local-168-182-110:9092', 'clickhouse', 'group1', 'JSONEachRow');
SELECT * FROM queue LIMIT 3;
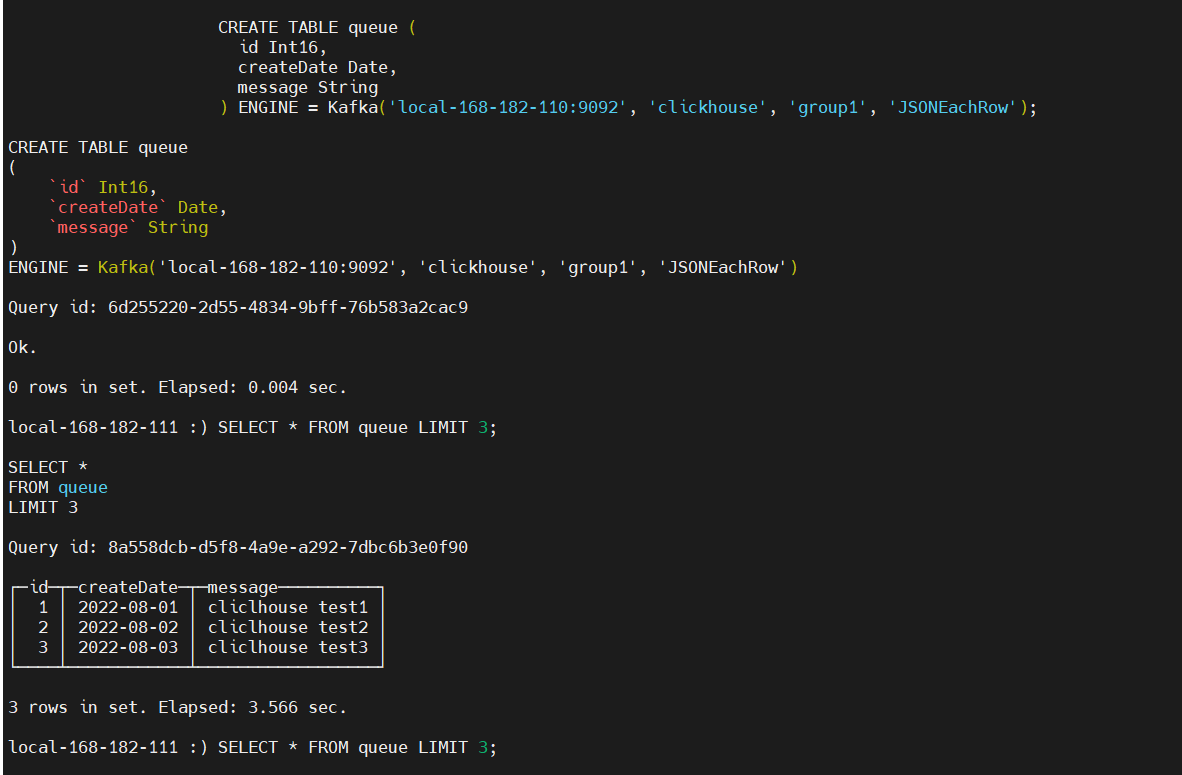
成功读取到了数据,并且是从earlast读取,而不是lartest,再执行一次查询,发现数据消失了,这是因为Kafka引擎只能读取消费的数据,读取完了以后就会删除数据,那么用这个引擎就没有意义了,数据只能查询一次,其实Kafka引擎是需要结合物化视图一起使用的,物化视图不断将从kafka接收的消息数据写入到其他表引擎。
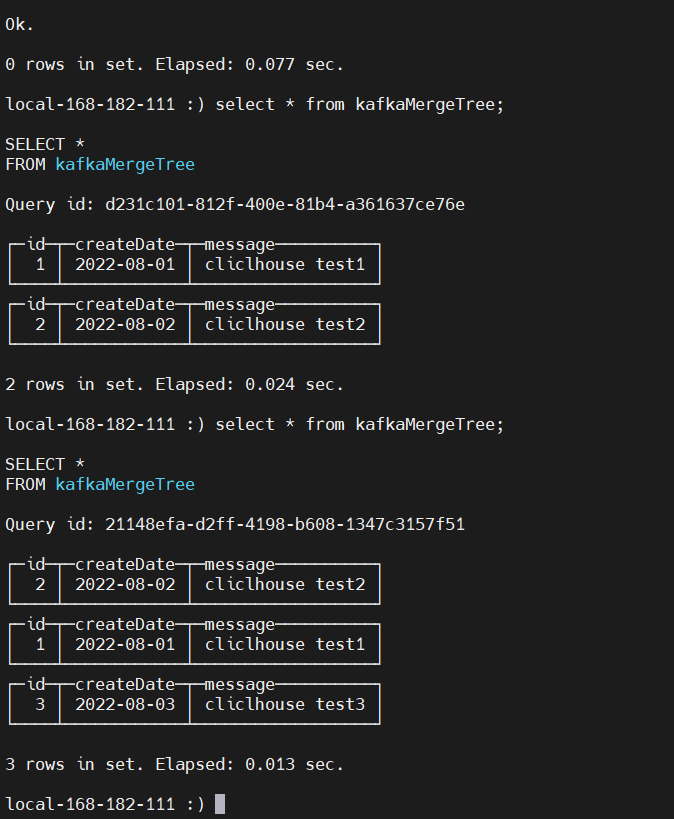
CREATE TABLE kafkaMergeTree
(
id Int16,
createDate Date,
message String
)
ENGINE = MergeTree
ORDER BY id;
CREATE MATERIALIZED VIEW kafkaview TO kafkaMergeTree AS SELECT * FROM queue ;
创建好后,继续向kafka生产数据几条数据,之后查询
select * from kafkaMergeTree;
【示例2】演示一下查询Kafka引擎隐藏列
CREATE TABLE queue2 (
id Int16,
createDate Date,
message String
) ENGINE = Kafka('local-168-182-110:9092', 'clickhouse2', 'group1', 'JSONEachRow');
生产数据
# 新建topic
kafka-topics.sh --create --topic clickhouse2 --bootstrap-server local-168-182-110:9092,local-168-182-111:9092,local-168-182-112:9092 --partitions 1 --replication-factor 1 --config retention.ms=259200000
kafka-console-producer.sh --broker-list local-168-182-110:9092 --topic clickhouse2
{"id":1,"createDate":"2022-08-01","message":"cliclhouse test1"}
{"id":2,"createDate":"2022-08-02","message":"cliclhouse test2"}
{"id":3,"createDate":"2022-08-03","message":"cliclhouse test3"}
查询
select *,_topic,_key,_offset,_timestamp,_partition from queue2;
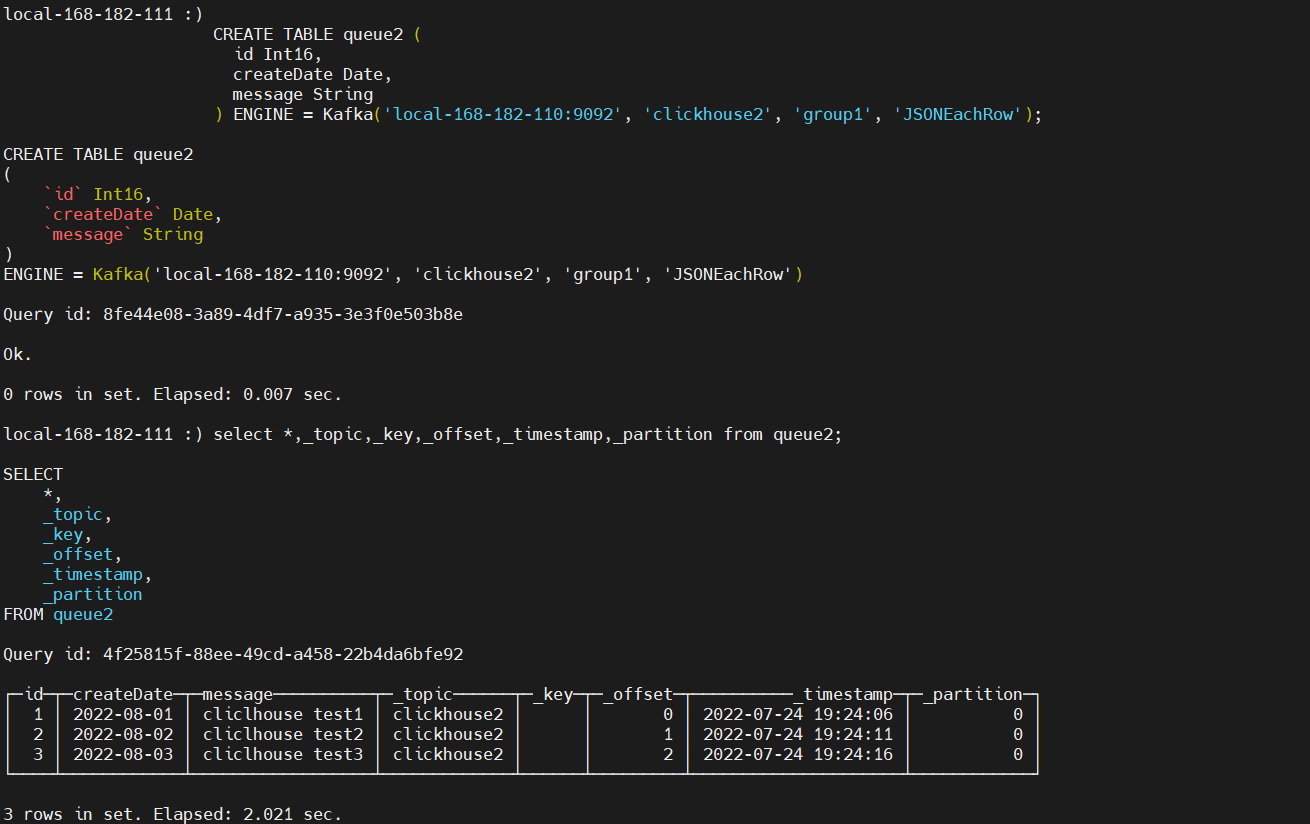
上方以_开头的是隐藏列,不包含在*之中
_topic——kafka主题。_key——消息的key。_offset——消息的偏移量。_timestamp——消息的时间戳。_partition——分区。
三、ClickHouse数据分片复制方案
【方案一】
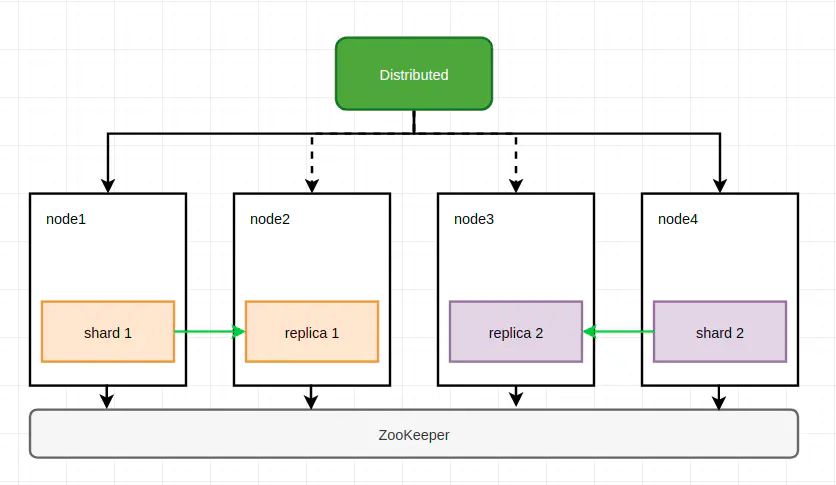
在每个节点创建一个数据表,作为一个数据分片,使用
ReplicatedMergeTree表引擎实现数据副本,而分布表作为数据写入和查询的入口。这是最常见的集群实现方式。ClickHouse 使用 Apache ZooKeeper 存储副本的元信息。
数据副本官方文档:https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/replication
-- 创建复制表
CREATE TABLE table_name
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/table_name', '{replica}')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
-
/clickhouse/tables/是公共前缀,我们推荐使用这个。 -
{layer}-{shard}是分片标识部分。在此示例中,由于Yandex.Metrica集群使用了两级分片,所以它是由两部分组成的。但对于大多数情况来说,你只需保留{shard}占位符即可,它会替换展开为分片标识。 -
table_name是该表在 ZooKeeper 中的名称。使其与 ClickHouse 中的表名相同比较好。 这里它被明确定义,跟 ClickHouse 表名不一样,它并不会被 RENAME 语句修改。 HINT:你也可以在 table_name 前面添加一个数据库名称。例如: db_name.table_name 。 -
两个内置的占位符
{database}和{table}也可使用,它们可以展开成数据表名称和数据库名称(只有当这些宏指令在 macros 部分已经定义时才可以)。因此 ZooKeeper 路径可以指定为 '/clickhouse/tables/{layer}-{shard}/{database}/{table}' 。
你可以在服务器的配置文件中指定 Replicated 数据表引擎的默认参数。例如:
<default_replica_path>/clickhouse/tables/{shard}/{database}/{table}</default_replica_path>
<default_replica_name>{replica}</default_replica_name>
这样,你可以在建表时省略参数:
CREATE TABLE table_name (
x UInt32
) ENGINE = ReplicatedMergeTree
ORDER BY x;
它等价于:
CREATE TABLE table_name (
x UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/{database}/table_name', '{replica}')
ORDER BY x;
【示例】
【温馨提示】{shard}和{replica}会使用macros定义的值,配置文件:
/etc/metrika.xml

# node1登录
clickhouse-client -h local-168-182-110 -d default -m -u default --password 123456
# node2登录
clickhouse-client -h local-168-182-110 -d default -m -u default --password 123456
-- 在所有节点上创建这个表
CREATE TABLE ch_test001
(
`id` Int16,
`createDate` Date,
`message` String
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/ch_test001', '{replica}')
PARTITION BY toYYYYMM(createDate)
ORDER BY id;
-- 只在node1节点上添加数据
insert into ch_test001 values(1, '2020-01-01', 'test1');
-- 在node2上查数据
select * from ch_test001;
-- 分别登录node3和node4节点
-- node3登录
clickhouse-client -h local-168-182-112 -d default -m -u default --password 123456
-- node4登录
clickhouse-client -h local-168-182-113 -d default -m -u default --password 123456
-- 在node4节点上添加数据
insert into ch_test001 values(1, '2020-01-01', 'test2');
-- 在node3上查看副本数据
select * from ch_test001;
node1和node2

node3和node4
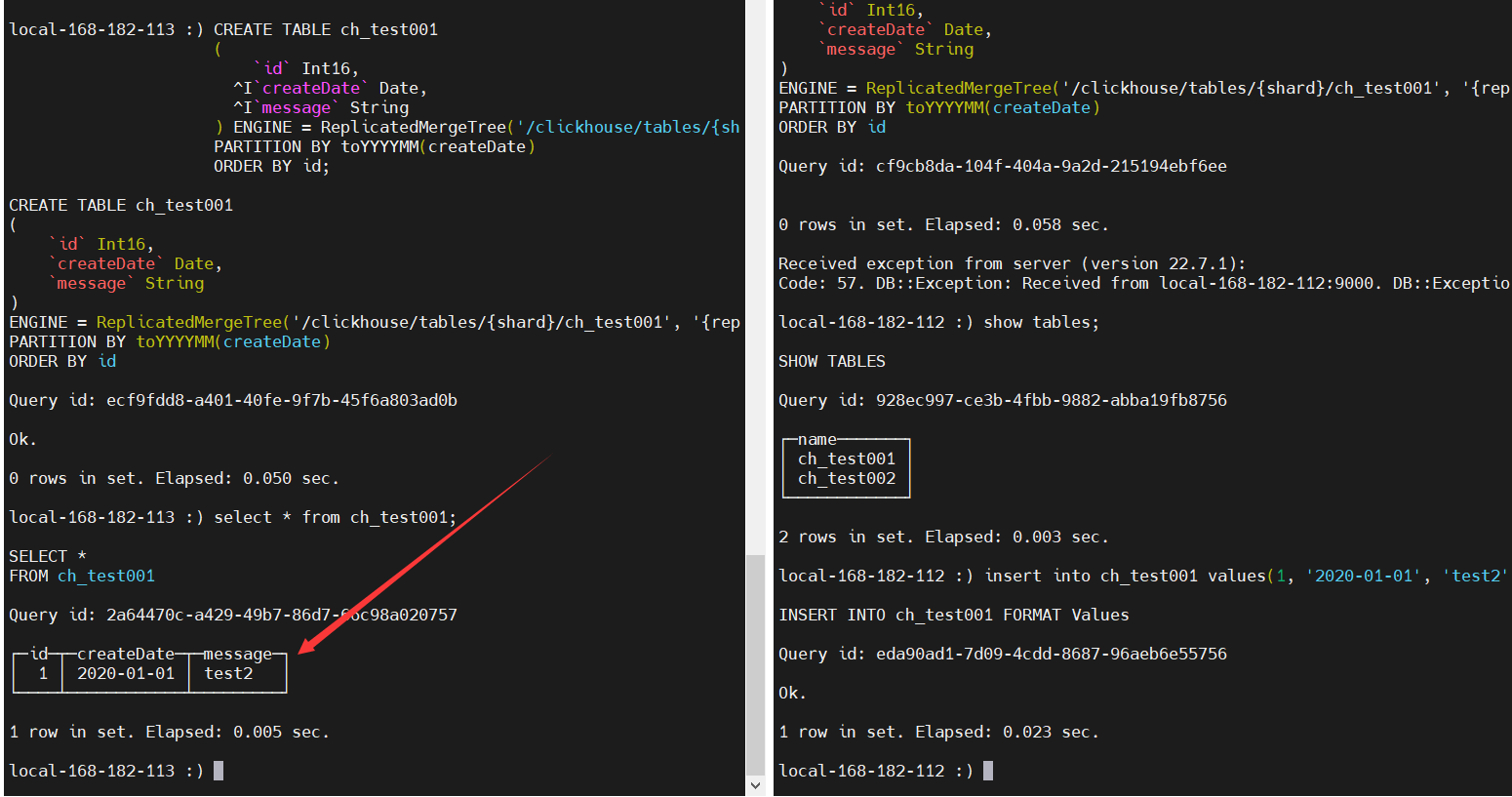
【温馨提示】删除表再重新建表,发现会失败
Code: 253. DB::Exception: Received from local-168-182-111:9000. DB::Exception: Replica /clickhouse/tables/01/ch_test001/replicas/local-168-182-111-01-2 already exists.
解决:
- 修改config.xml的配置database_atomic_delay_before_drop_table_sec为0
- 最原始方法,等待480秒后再重新建表
使用Distributed表引擎创建分布式表:
官方文档:https://clickhouse.com/docs/zh/engines/table-engines/special/distributed/
CREATE TABLE default.ck_distributed on cluster ck_cluster_2022
(
`id` Int16,
`createDate` Date,
`message` String
)
engine = Distributed(ck_cluster_2022,default,ch_test001, rand());
# 添加数据
insert into ck_distributed values(2, '2020-01-02', 'test2001');
# 在哪个节点上添加数据,就是添加到哪个节点的表里。副本会自动同步
【温馨提示】分布式引擎本身不存储数据。
【方案二】
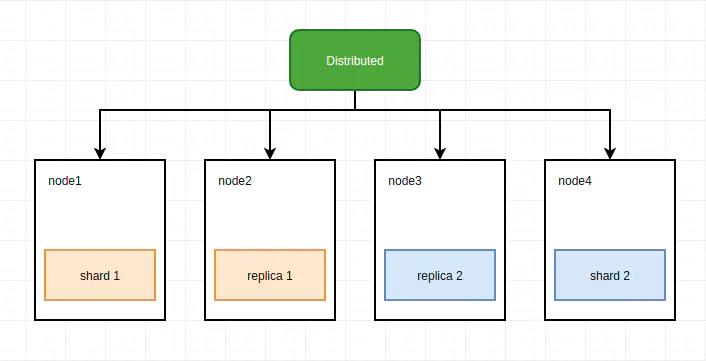
在每个节点创建一个数据表,作为一个数据分片,分布表同时负责分片和副本的数据写入工作。这种实现方案下,不需要使用复制表,但分布表节点需要同时负责分片和副本的数据写入工作,它很有可能称为写入的单点瓶颈。
ZooKeeper不是一个严格的要求:在某些简单的情况下,您可以通过将数据写入应用程序代码中的所有副本来复制数据。 这种方法是不建议的,在这种情况下,ClickHouse将无法保证所有副本上的数据一致性。 因此需要由您的应用来保证这一点。
修改配置即可
<!-- 设置为true ,所有副本同时写-->
<internal_replication>false</internal_replication>
【方案三】
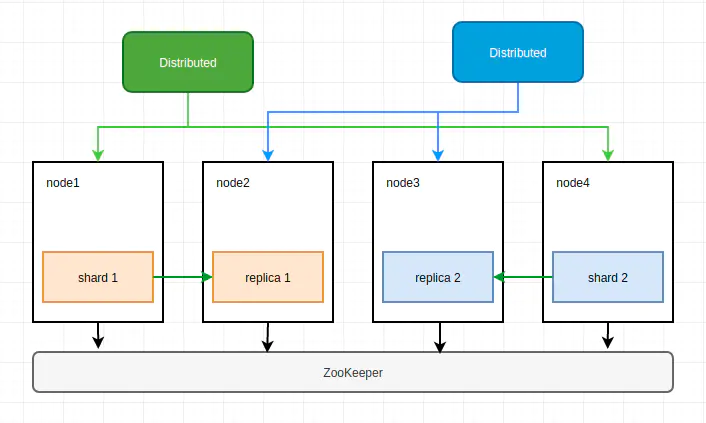
在每个节点创建一个数据表,作为一个数据分片,同时创建两个分布表,每个分布表(Distributed)节点只纳管一半的数据。副本的实现仍需要借助
ReplicatedMergeTree类表引擎。
不同的分片创建不同的表
-- node1登录
clickhouse-client -h local-168-182-110 -d default -m -u default --password 123456
--node2登录
clickhouse-client -h local-168-182-110 -d default -m -u default --password 123456
-- 在node1和node2创建这个表
CREATE TABLE ch_test002
(
`id` Int16,
`createDate` Date,
`message` String
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/ch_test002', '{replica}')
PARTITION BY toYYYYMM(createDate)
ORDER BY id;
# 只在node1节点上添加数据
insert into ch_test002 values(1, '2020-01-01', 'test2');
# 在node2上查数据
select * from ch_test002;
# 分别登录node3和node4节点
# node3登录
clickhouse-client -h local-168-182-112 -d default -m -u default --password 123456
# node4登录
clickhouse-client -h local-168-182-113 -d default -m -u default --password 123456
# 在node3和node4创建这个表
CREATE TABLE ch_test003
(
`id` Int16,
`createDate` Date,
`message` String
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/ch_test003', '{replica}')
PARTITION BY toYYYYMM(createDate)
ORDER BY id;
# 在node4节点上添加数据
insert into ch_test003 values(1, '2020-01-01', 'test3');
# 在node3上查看副本数据
select * from ch_test003;
创建两个分布表
CREATE TABLE default.ck_distributed_test002 on cluster ck_cluster_2022
(
`id` Int16,
`createDate` Date,
`message` String
)
engine = Distributed(ck_cluster_2022,default,ch_test002, rand());
-- 添加数据
insert into ck_distributed_test002 values(2, '2020-01-02', 'test2002');
CREATE TABLE default.ck_distributed_test003 on cluster ck_cluster_2022
(
`id` Int16,
`createDate` Date,
`message` String
)
engine = Distributed(ck_cluster_2022,default,ch_test003, rand());
-- 添加数据
insert into ck_distributed_test003 values(2, '2020-01-02', 'test2003');
【方案四】

在每个节点创建两个数据表,同一数据分片的两个副本位于不同节点上,每个分布式表纳管一般的数据。这种方案可以在更少的节点上实现数据分布与冗余,但是部署上略显繁琐。
第一步:修改配置
<yandex>
<!--ck集群节点-->
<clickhouse_remote_servers>
<!-- 集群名称 -->
<ck_cluster_2022>
<!--shard 1(分片1)-->
<shard>
<weight>1</weight>
<!-- internal_replication这个参数是控制写入数据到分布式表时,分布式表会控制这个写入是否的写入到所有副本中,这里设置false,就是只会写入到第一个replica,其它的通过zookeeper同步 -->
<internal_replication>false</internal_replication>
<replica>
<host>local-168-182-110</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
<!--replicat 2(副本 2)-->
<replica>
<host>local-168-182-111</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
<!--shard 2(分片2)-->
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<host>local-168-182-111</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
<!--replicat 3(副本 3)-->
<replica>
<host>local-168-182-112</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
<!--shard 3(分片3)-->
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<host>local-168-182-112</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
<!--replicat 4(副本 4)-->
<replica>
<host>local-168-182-113</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
<!--shard 4(分片4)-->
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<host>local-168-182-113</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
<!--replicat 1(副本 1)-->
<replica>
<host>local-168-182-110</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
</ck_cluster_2022>
</clickhouse_remote_servers>
<!--zookeeper相关配置-->
<zookeeper>
<node index="1">
<host>local-168-182-110</host>
<port>2181</port>
</node>
<node index="2">
<host>local-168-182-111</host>
<port>2181</port>
</node>
<node index="3">
<host>local-168-182-112</host>
<port>2181</port>
</node>
</zookeeper>
<macros>
<!-- 本节点副本名称,创建复制表时有用,每个节点不同,整个集群唯一,建议使用主机名+副本+分片) ,第一个分片+第一个副本,在当前节点上-->
<shard>01</shard>
<replica>local-168-182-110-01-1</replica>
</macros>
<!-- 监听网络 -->
<networks>
<ip>::/0</ip>
</networks>
<!--压缩相关配置-->
<clickhouse_compression>
<case>
<min_part_size>1073741824</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
<!--压缩算法lz4压缩比zstd快, 更占磁盘-->
</case>
</clickhouse_compression>
</yandex>
上面是node1的配置,其它需要修改配置如下:
<!-- node2 -->
<macros>
<shard>02</shard>
<replica>local-168-182-111-02-1</replica>
</macros>
<!-- node3 -->
<macros>
<shard>03</shard>
<replica>local-168-182-112-03-1</replica>
</macros>
<!-- node4 -->
<macros>
<shard>03</shard>
<replica>local-168-182-113-03-1</replica>
</macros>
接下来就是创建表可以分布表了
-- node1登录
clickhouse-client -h local-168-182-110 -d default -m -u default --password 123456
-- 集群方式创建,每个节点都会创建一张表,这里需要区分的就是分片和副本分别创建
CREATE TABLE ch_shard_test on cluster
(
`id` Int16,
`createDate` Date,
`message` String
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/ch_shard_test', '{replica}')
PARTITION BY toYYYYMM(createDate)
ORDER BY id;
CREATE TABLE ch_replica_test on cluster
(
`id` Int16,
`createDate` Date,
`message` String
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/ch_shard_test', '{replica}')
PARTITION BY toYYYYMM(createDate)
ORDER BY id;
创建两个分布表
CREATE TABLE default.ck_distributed_shard on cluster ck_cluster_2022
(
`id` Int16,
`createDate` Date,
`message` String
)
engine = Distributed(ck_cluster_2022,default,ch_shard_test, rand());
-- 添加数据
insert into ck_distributed_shard values(2, '2020-01-02', 'test2002');
CREATE TABLE default.ck_distributed_replica on cluster ck_cluster_2022
(
`id` Int16,
`createDate` Date,
`message` String
)
engine = Distributed(ck_cluster_2022,default,ch_replica_test, rand());
-- 添加数据
insert into ck_distributed_replica values(2, '2020-01-02', 'test2003');
第二步:
【总结】
CH(ClickHouse)的分片与副本功能完全靠配置文件实现,无法自动管理,所以当集群规模较大时,集群运维成本较高- 数据副本依赖ZooKeeper实现同步,当数据量较大时,ZooKeeper可能会称为瓶颈
- 如果资源充足,建议使用方案一,主副本和副副本位于不同节点,以更好地实现读写分离与负载均衡
- 如果资源不够充足,可以使用方案四,每个节点承载两个副本,但部署方式上略复杂

 浙公网安备 33010602011771号
浙公网安备 33010602011771号