大数据Hadoop之——数据仓库Hive
一、概述
Hive是基于Hadoop的一个数据仓库(Data Aarehouse,简称数仓、DW),可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。是用于存储、分析、报告的数据系统。
在Hadoop生态系统中,HDFS用于存储数据,Yarn用于资源管理,MapReduce用于数据处理,而Hive是构建在Hadoop之上的数据仓库,包括以下方面:
- 使用HQL作为查询接口;
- 使用HDFS存储;
- 使用MapReduce或其它计算框架计算;
- 执行程序运行在Yarn上。
Hive的本质是:将Hive SQL转化成MapReduce程序,其灵活性和扩展性比较好,支持UDF,自定义存储格式等;适合离线数据处理。
Hive相关网站
官网:http://hive.apache.org
文档:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
https://cwiki.apache.org/confluence/display/Hive/Home
下载:http://archive.apache.org/dist/hive
Github地址:https://github.com/apache/hive
二、Hive优点与使用场景
1)优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手);
- 避免了去写MapReduce,减少开发人员的学习成本;
- 统一的元数据管理,可与impala/spark等共享元数据;
- 易扩展(HDFS+MapReduce:可以扩展集群规模;支持自定义函数);
- 数据的离线处理;比如:日志分析,海量结构化数据离线分析。
2)使用场景
- Hive的执行延迟比较高,因此hive常用于数据分析的,对实时性要求 不高的场合;
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执 行延迟比较高。
三、Hive架构
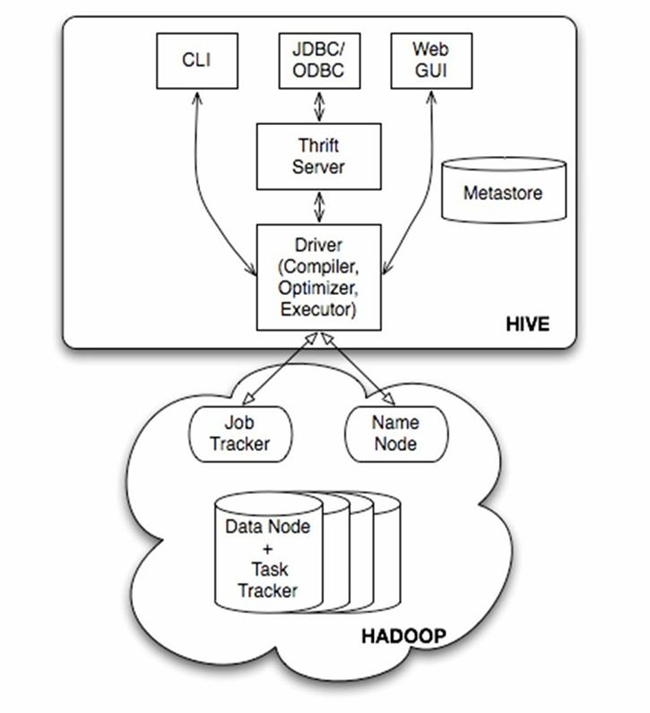
由上图可知,hadoop和mapreduce是hive架构的根基。Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor),这些组件我可以分为两大类:服务端组件和客户端组件。
1)服务端组件
1、Driver组件
该组件包括Complier、Optimizer和Executor,它的作用是将我们写的HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架。
2、Metastore组件
Metastore是元数据服务组件,这个组件存储hive的元数据,hive的元数据存储在关系数据库里,hive支持的关系数据库有derby、mysql。元数据对于hive十分重要,因此hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性。
3、Thrift服务
Thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
2)客户端组件
1、CLI
command line interface,命令行接口。
2、Thrift客户端
上面的架构图里没有写上Thrift客户端,但是hive架构的许多客户端接口是建立在Thrift客户端之上,包括JDBC和ODBC接口。
3、WEBGUI
hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应hive的hwi组件(hive web interface),使用前要启动hwi服务。
3)Metastore详解
- Hive的metastore组件是hive元数据集中存放地。
- Metastore组件包括两个部分:metastore服务和后台数据的存储。
- 后台数据存储的介质就是关系数据库,例如hive默认的嵌入式磁盘数据库derby,还有mysql数据库。
- Metastore服务是建立在后台数据存储介质之上,并且可以和hive服务进行交互的服务组件,默认情况下,metastore服务和hive服务是安装在一起的,运行在同一个进程当中。
- 我也可以把metastore服务从hive服务里剥离出来,metastore独立安装在一个集群里,hive远程调用metastore服务,这样我们可以把元数据这一层放到防火墙之后,客户端访问hive服务,就可以连接到元数据这一层,从而提供了更好的管理性和安全保障。
- 使用远程的metastore服务,可以让metastore服务和hive服务运行在不同的进程里,这样也保证了hive的稳定性,提升了hive服务的效率。
四、Hive的工作原理
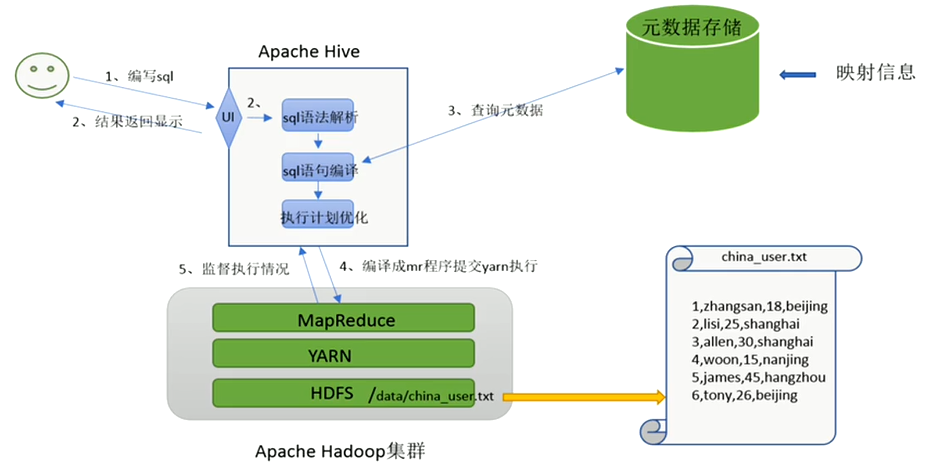
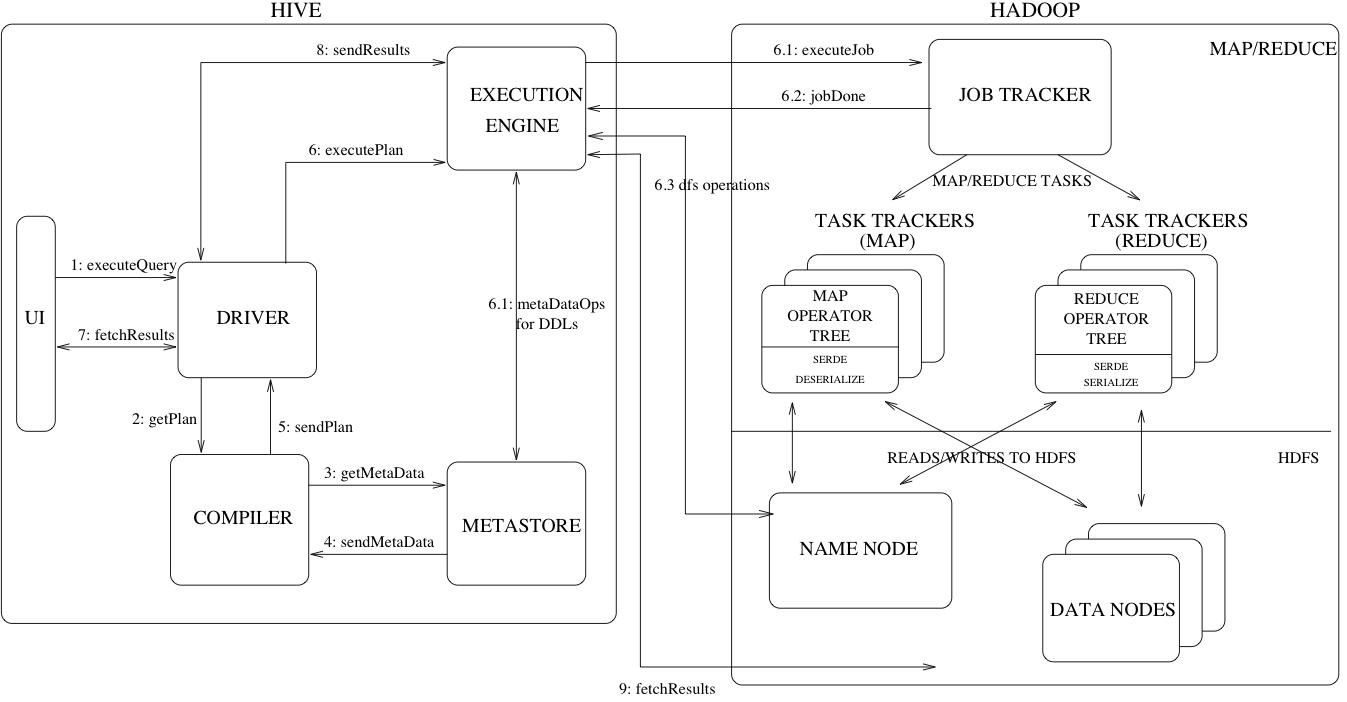
简单的将就是说sql或者HQL(Hive SQL)会被Hive解释,编译,优化并生成查询计划,一般情况而言查询计划会被转化为MapReduce任务进而执行。
具体工作过程如下:
- 词法分析/语法分析
使用antlr将SQL语句解析成抽象语法树(AST)
- 语义分析
从Megastore获取模式信息,验证SQL语句中队表名,列名,以及数据类型的检查和隐式转换,以及Hive提供的函数和用户自定义的函数(UDF/UAF)
- 逻辑计划生成
生成逻辑计划--算子树
- 逻辑计划优化
对算子树进行优化,包括列剪枝,分区剪枝,谓词下推等
- 物理计划生成
将生成包含由MapReduce任务组成的DAG(Directed acyclic graph:有向无环图)的物理计划
- 物理计划执行
将DAG发送到Hadoop集群进行执行
- 最后把查询结果返回
【温馨提示】新版本的Hive也支持使用Tez或Spark等作为执行引擎。
五、安装
1)local模式(内嵌derby)
内嵌derby数据库(一个会话连接,常用于简单测试)derby是个in-memory的数据库。
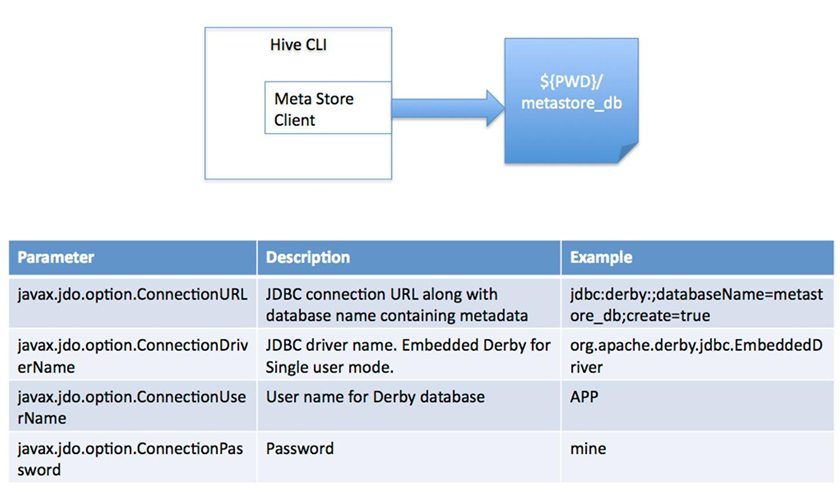
安装方法如下:
1、下载hive

$ cd /opt/bigdata/hadoop/software
# 下载
$ wget http://archive.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
# 解压
$ tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/bigdata/hadoop/server/
2、配置环境变量
$ cd /opt/bigdata/hadoop/server/apache-hive-3.1.2-bin/conf/
# 把模板文件复制一份
$ cp hive-env.sh.template hive-env.sh
- 在/etc/profile文件中追加如下内容:
export HIVE_HOME=/opt/bigdata/hadoop/server/apache-hive-3.1.2-bin
export PATH=$HIVE_HOME/bin:$PATH
source 加载生效
$ source /etc/profile
- hive-site.xml,这个文件不存在,创建文件,内容如下:
# 创建在hdfs存储目录,下面配置文件会用到
$ hadoop fs -mkdir -p /user/hive/warehouse
# 切到hive conf目录
$ cd /opt/bigdata/hadoop/server/apache-hive-3.1.2-bin/conf
hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 数据在hdfs中的存储位置 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>
- hive-env.sh #底部追加两行
export HADOOP_HOME=/opt/bigdata/hadoop/server/hadoop-3.3.1
export HIVE_CONF_DIR=/opt/bigdata/hadoop/server/apache-hive-3.1.2-bin/conf
export HIV_AUX_JARS_PATH=/opt/bigdata/hadoop/server/apache-hive-3.1.2-bin/lib
3、启动验证
$ hive
# 查看数据库
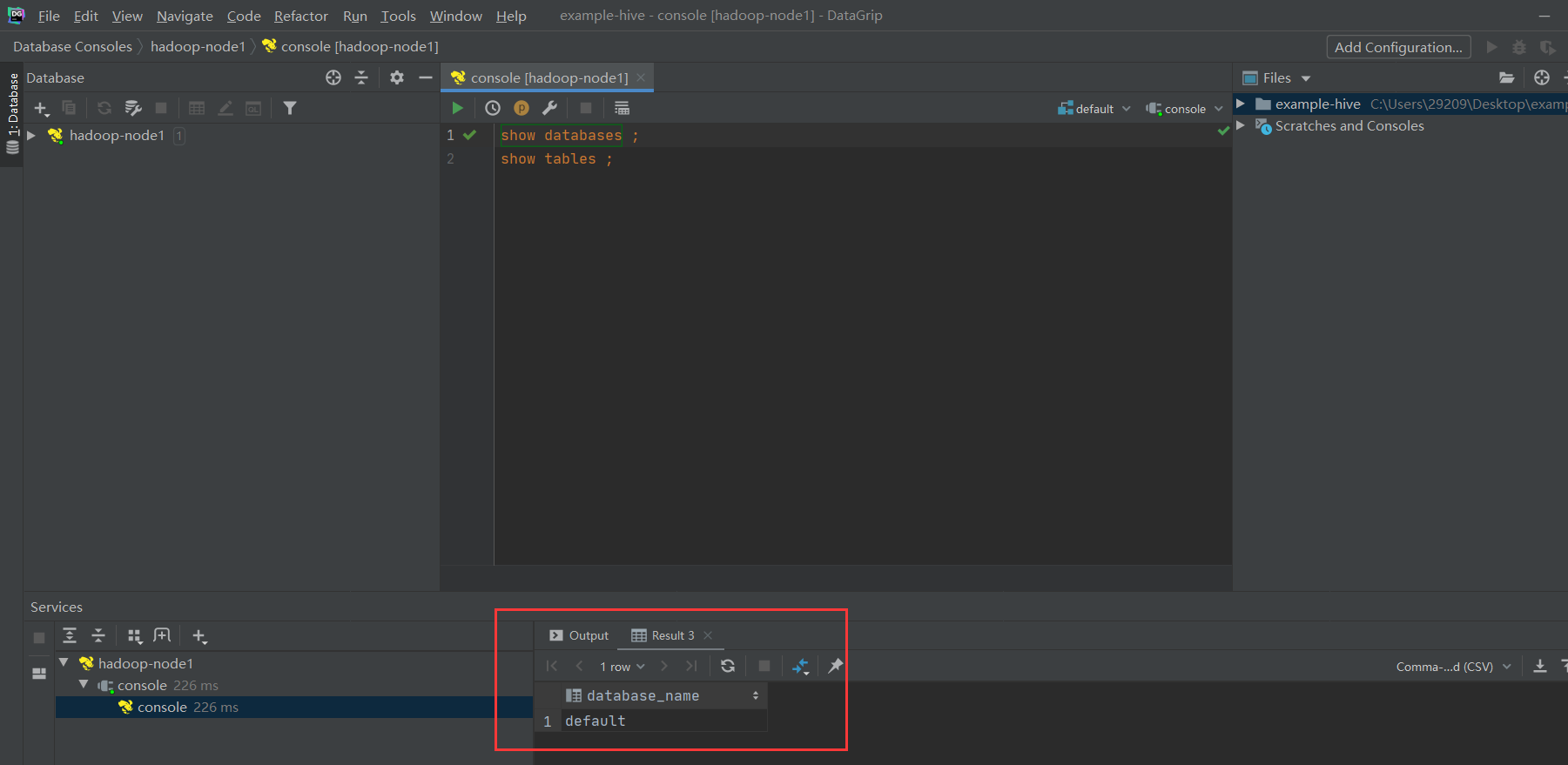
hive> show databases;
# 查看当前库(默认是default库)的表
hive> show tables;
# 查看当前库
hive> select current_database();
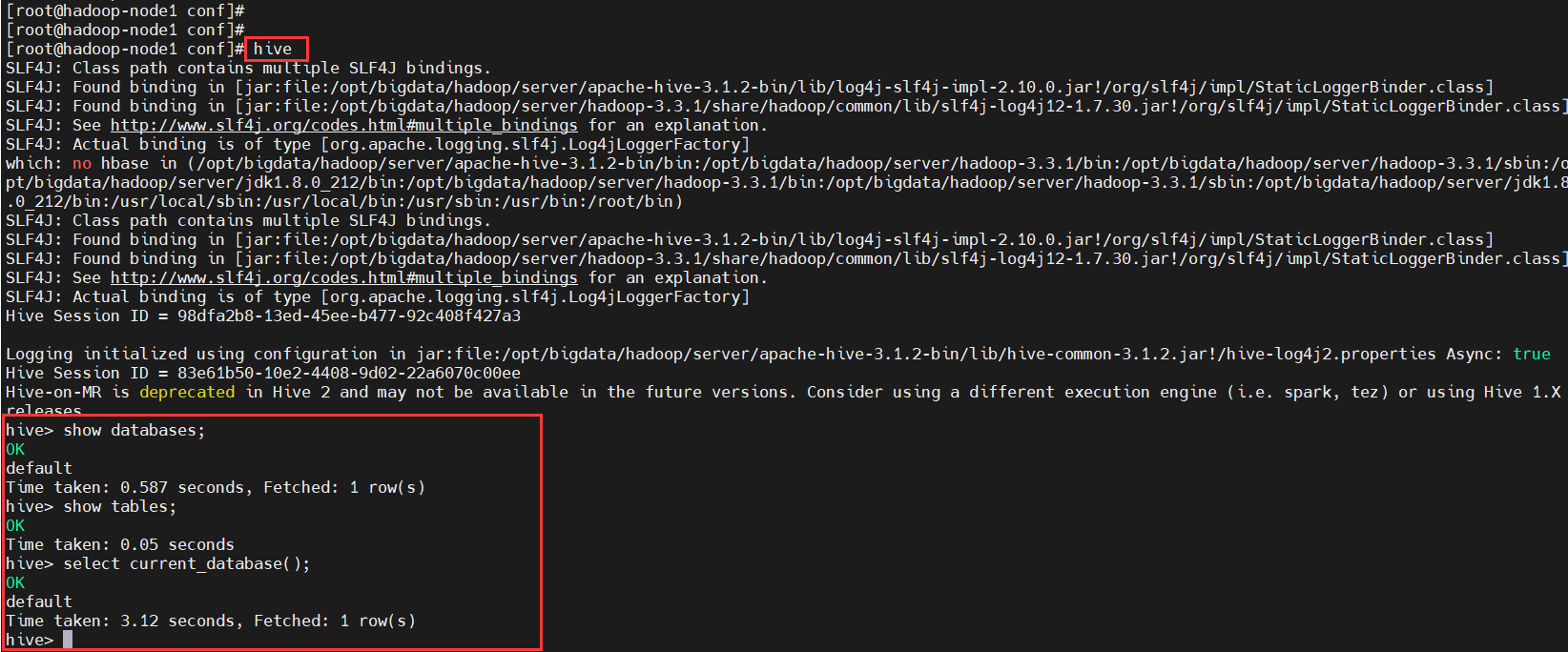
查看当前目录,发现多了derby文件和一个metastore_db目录
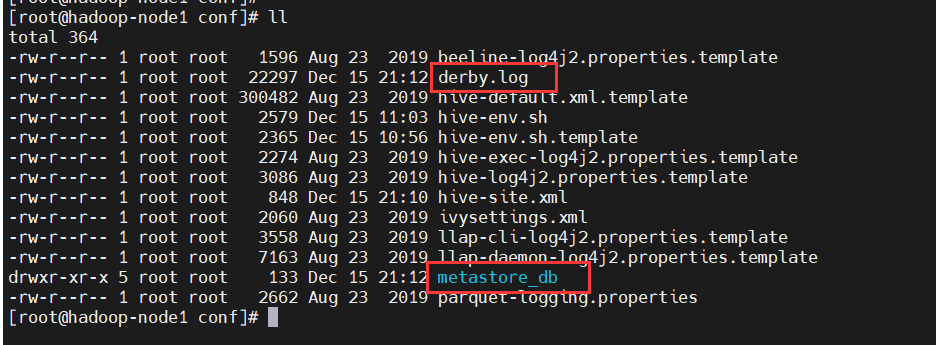
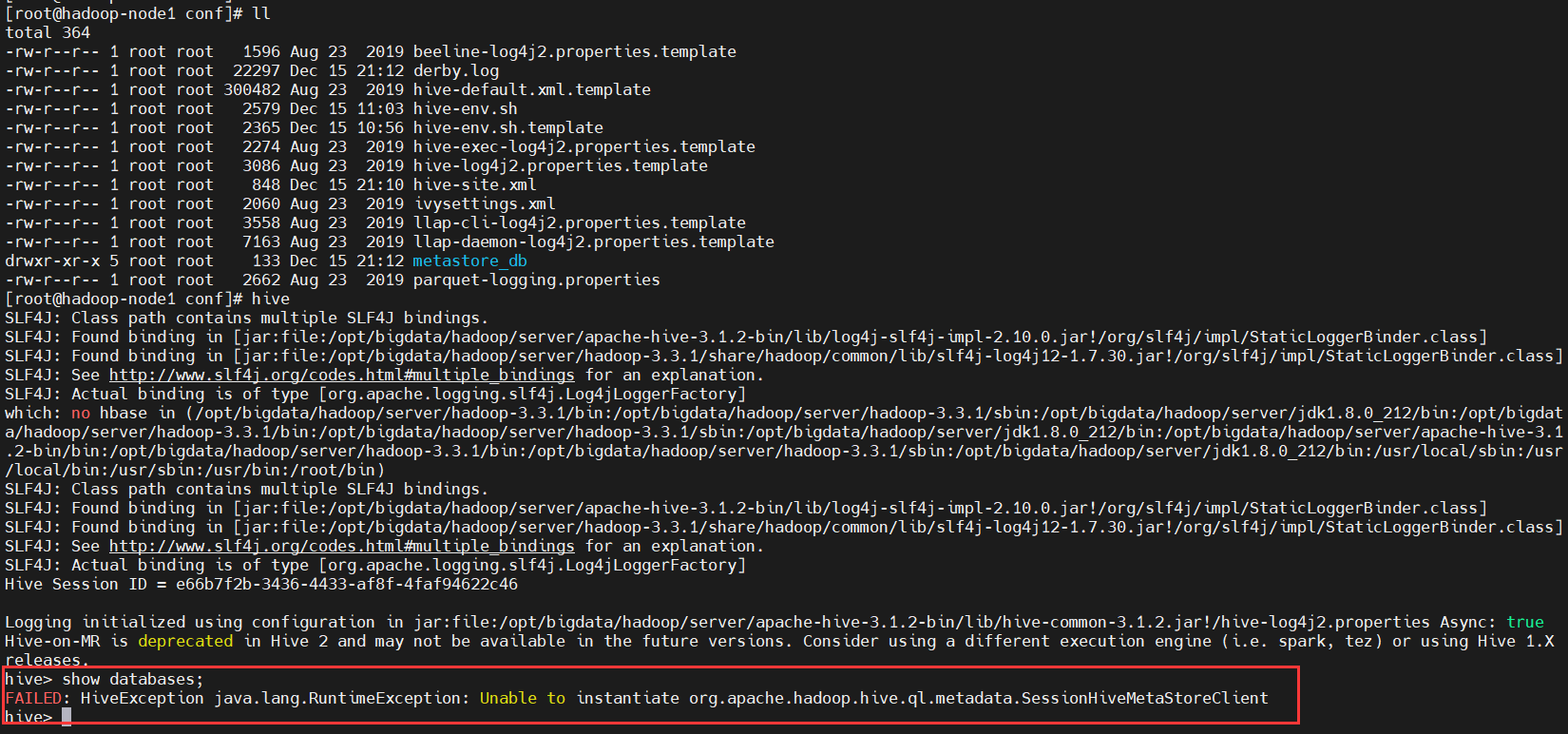
【注意】使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,否则会提示如下错误:
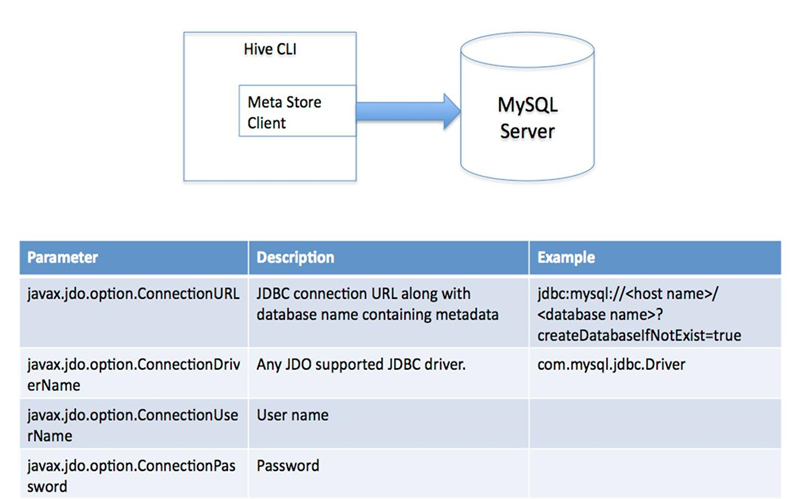
2)单用户模式(mysql)
该模式下就是客户端和服务端在一个节点上,使用关系型数据库(mysql、oracle等带jdbc驱动的数据库)来对元数据进行存储。这里使用mysql,mysql可以在安装同一台机器上,也可以在远程机器上。
hive包上面已经下载了,这里就不重复了。
1、安装mysql数据库
- yum源安装
$ yum -y install mysql-server
# 启动数据库
$ systemctl start mysqld
$ systemctl status mysqld
# 开机自启动
$ systemctl enable mysqld
- 连接mysql8.x授权(无密码,直接进入)
$ mysql
# 创建可远程连接用户
CREATE USER 'root'@'%' IDENTIFIED BY '123456';
# 修改用户密码
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
# 授权给用户
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
# 查看
select user,host from mysql.user;
show grants for 'root'@'%';
# 权限撤回,这里不执行,了解即可
revoke all privileges on *.* from 'root'@'%';
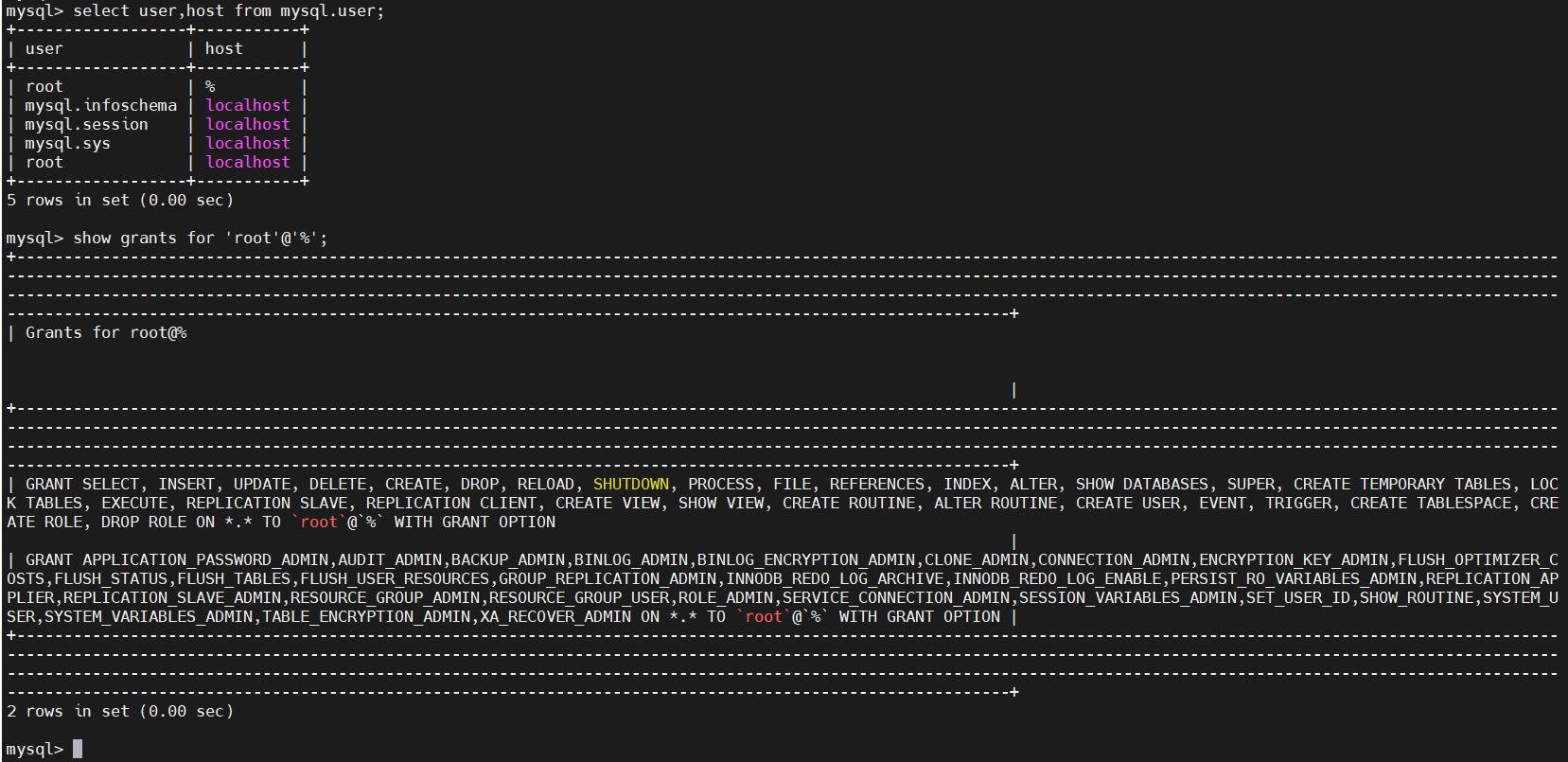
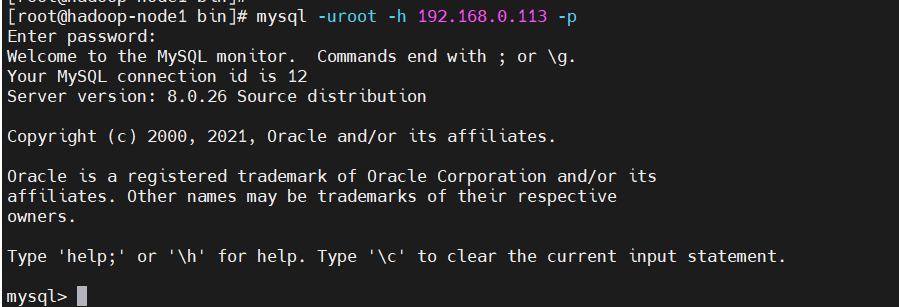
通过密码登录mysql
$ mysql -uroot -h 192.168.0.113 -p
输入密码:123456
2、解决Hive与Hadoop之间guava版本的差异
$ cd /opt/bigdata/hadoop/server
$ ls -l apache-hive-3.1.2-bin/lib/guava-*.jar
$ ls -l hadoop-3.3.1/share/hadoop/common/lib/guava-*.jar
# 删除hive中guava低版本
$ rm -f apache-hive-3.1.2-bin/lib/guava-*.jar
# copy hadoop中的guava到hive
$ cp hadoop-3.3.1/share/hadoop/common/lib/guava-*.jar apache-hive-3.1.2-bin/lib/
$ ls -l apache-hive-3.1.2-bin/lib/guava-*.jar

3、下载对应版本的mysql驱动包
# 查看mysql版本
$ mysql --version

这里的mysql版本是8.0.26,所以就得下载对应版本的驱动包
官网下载地址:https://dev.mysql.com/downloads/
如果小伙伴的mysql版本(8.0.26)跟我的一样,也可以使用百度的地址下载:
链接:https://pan.baidu.com/s/1uczpnH0PHxbq258vMoYlgA
提取码:8888
# 包放在这个目录下
$ cd /opt/bigdata/hadoop/software
# 解压
$ unzip mysql-connector-java-8.0.26.zip
把对应的驱动包copy到hive lib目录下
$ cp mysql-connector-java-8.0.26/mysql-connector-java-8.0.26.jar ../server/apache-hive-3.1.2-bin/lib/
4、配置
$ cd /opt/bigdata/hadoop/server/apache-hive-3.1.2-bin/conf
# 先备份一下
$ mv hive-site.xml local-derby-hive-site.xml
# 复制一份
$ cp hive-default.xml.template hive-site.xml
hive-site.xml内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 配置hdfs存储目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<!-- 本地模式 -->
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<!-- 所连接的 MySQL 数据库的地址,hive_local是数据库,程序会自动创建,自定义就行 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop-node1:3306/hive_local?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=Asia/Shanghai</value>
</property>
<!-- MySQL 驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- mysql连接用户 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- mysql连接密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!--元数据是否校验-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>system:user.name</name>
<value>root</value>
<description>user name</description>
</property>
</configuration>
5、初始化元数据
# 初始化,--verbose:查询详情,可以不加
$ schematool -initSchema -dbType mysql --verbose
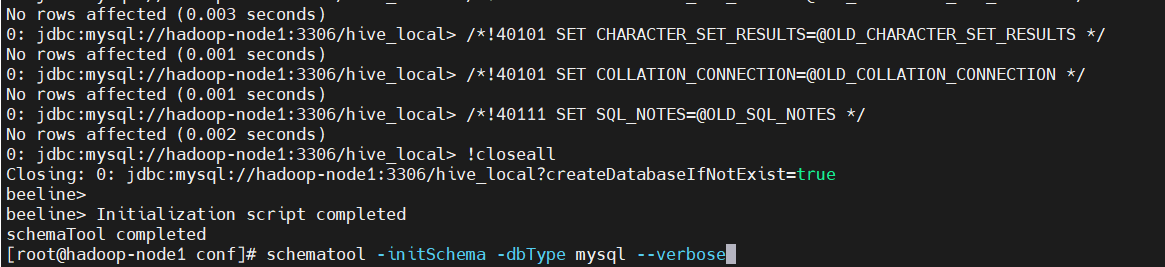
出现上图Initialization script completed和schemaTool completed,就初始化完成了。
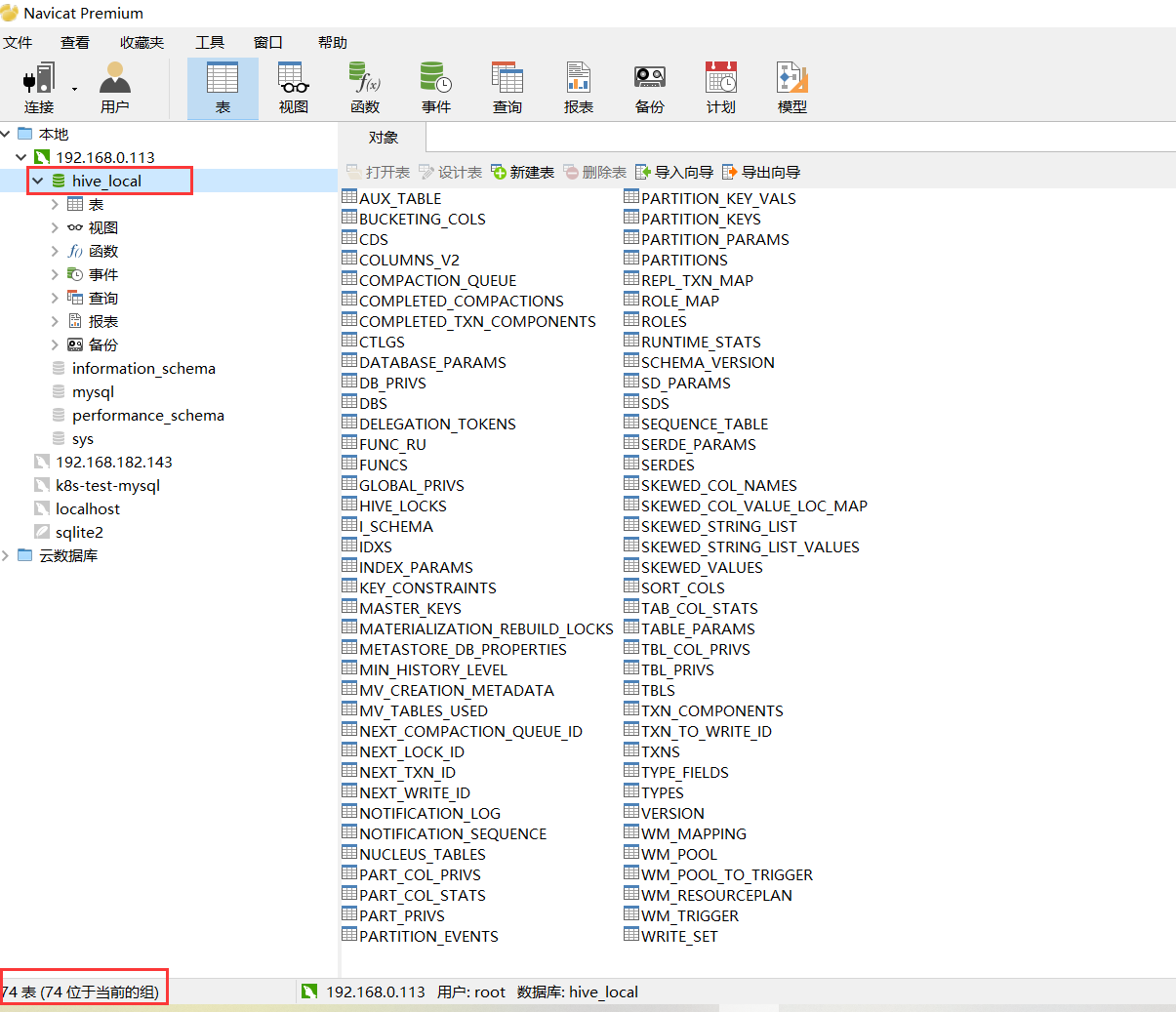
通过mysql 客户端工具取连接数据,发现新增量了hive_local,这个库里有74张表。
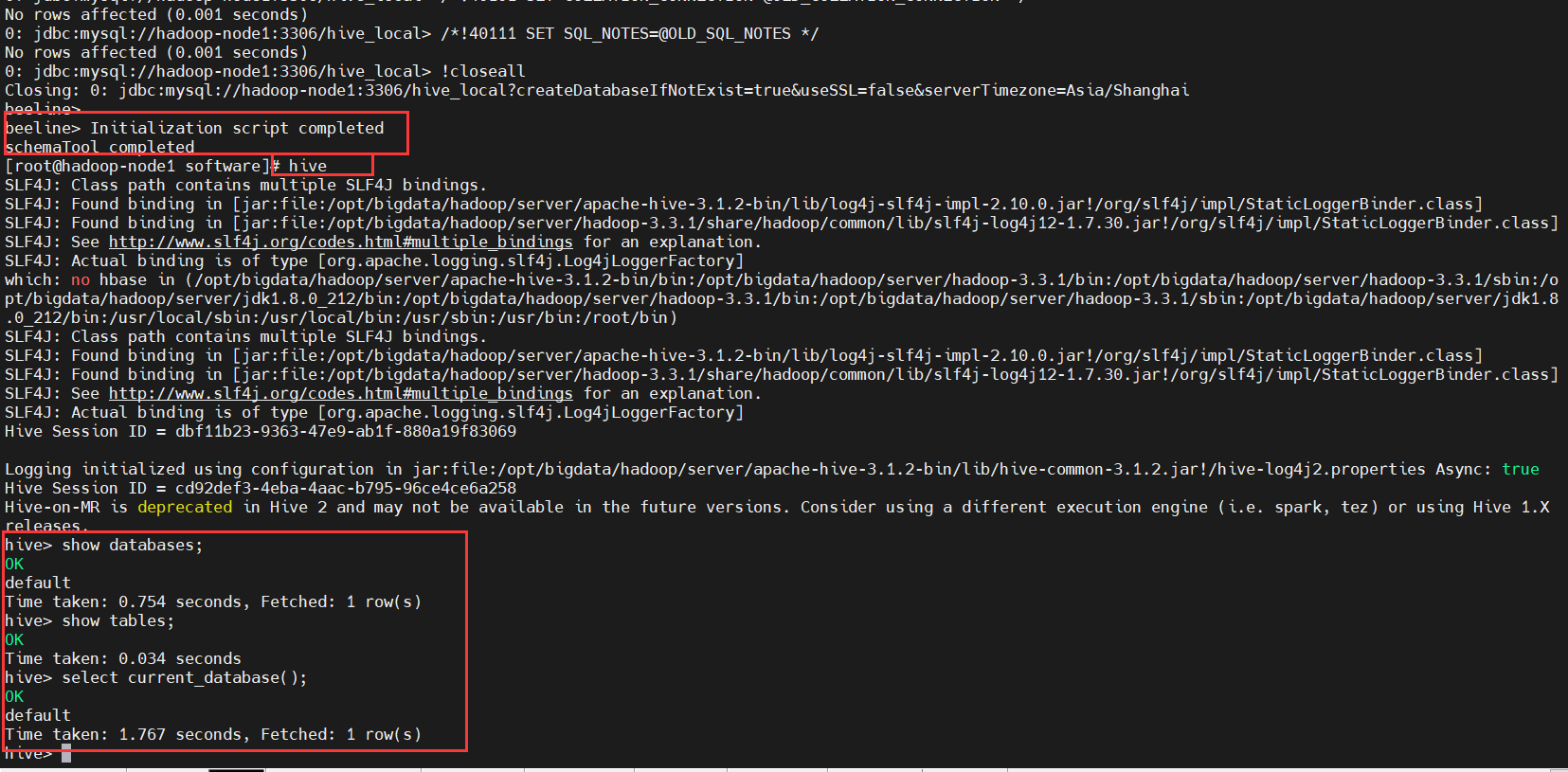
6、启动验证
# 进入hive
$ hive
# 查看数据库
hive> show databases;
# 查看当前库(默认是default库)的表
hive> show tables;
# 查看当前库
hive> select current_database();
3)多用户模式(mysql)
该模式下就是客户端和服务端在不同的节点上,因此需要单独启动metastore服务。该模式需要hive.metastore.local设置为false,并将hive.metastore.uris设置为metastore服务器URI,如有多个metastore服务器,URI之间用逗号分隔。
- 客户端hadoop-node2和服务端hadoop-node1分布在不同的节点上,客户端通过远程的方式连接。
- 客户端hadoop-node2节点操作,基本和服务端差不多操作,区别是他不需要初始化。
在hadoop-node2部署客户端
1、copy hive包到客户端hadoop-node2(在hadoop-node1服务端执行)
$ cd /opt/bigdata/hadoop/server
$ scp -r apache-hive-3.1.2-bin hadoop-node2:/opt/bigdata/hadoop/server/
2、在客户端添加环境变量(hadoop-node2)
- 在/etc/profile文件中追加如下内容:
export HIVE_HOME=/opt/bigdata/hadoop/server/apache-hive-3.1.2-bin
export PATH=$HIVE_HOME/bin:$PATH
source 加载生效
$ source /etc/profile
3、配置hive-site.xml(hadoop-node2)
$ cd /opt/bigdata/hadoop/server/apache-hive-3.1.2-bin/conf/
hive-site.xml内容如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop-node1:9083</value>
</property>
</configuration>
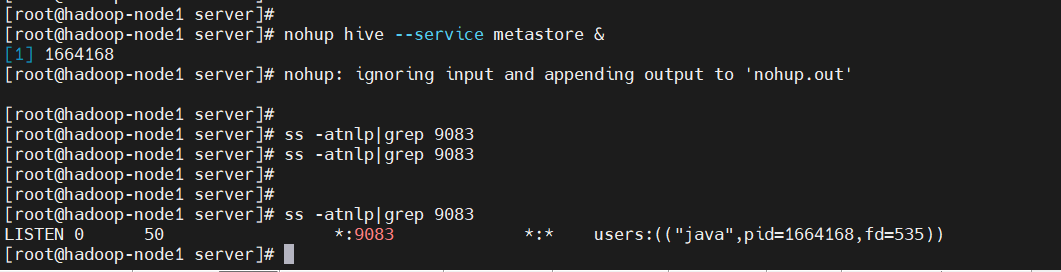
4、服务端后台开启metastore(hadoop-node1)
$ nohup hive --service metastore &
$ ss -atnlp|grep 9083
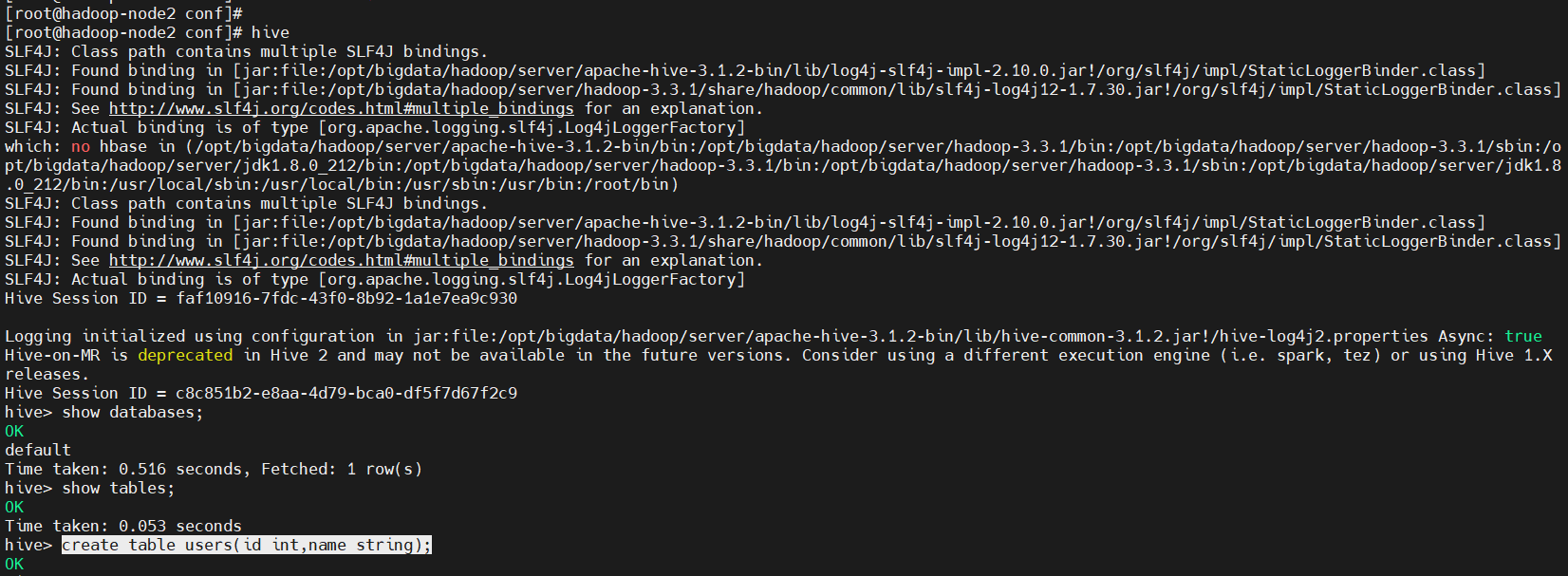
5、在客户端执行hive操作(hadoop-node2)
# 这里使用新命令beeline,跟hive命令差不多
$ hive
$ show databases;
$ show tables;
$ create table users(id int,name string);
$ insert into users values(1,'zhangsan');
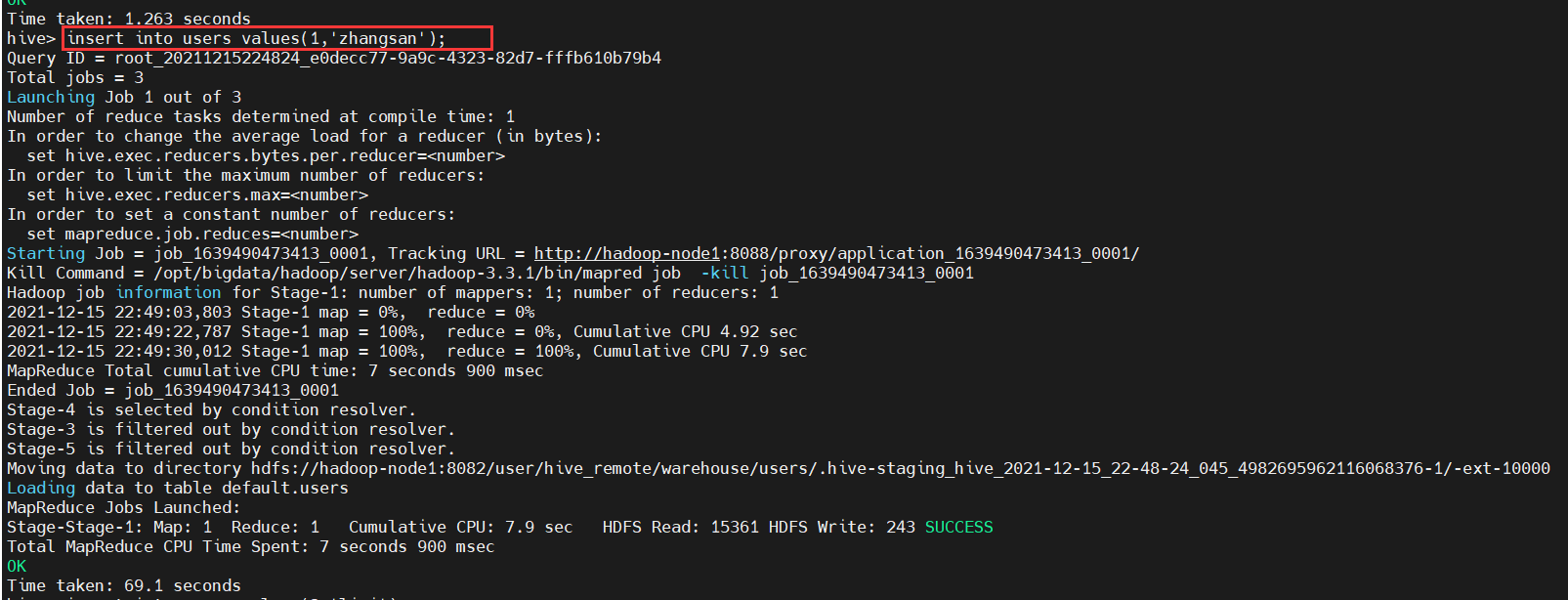
通过上面数据的插入操作,发现hive的操作最终会变成一个mapreduce任务在运行,也正验证了之前所述。

五、Hive客户端
Hive发展至今,总共历经了两代客户端工具:
- 第一代客户端(deprecated不推荐使用):$HIVE_HOME/bin/hive,是一个shellUtil。主要功能:一是可用于以交互或批处理运行Hive查询;二是用于Hive相关服务的启动,比如metastore服务。
- 第二代客户端(recommend 推荐使用):$HIVE_HOME/bin/beeline,是一个JDBC客户端,是官方强烈推荐使用的Hive命令行工具,和第一代客户端相比,性能加强安全性提高。

1)Hive CLI
1、查看帮助
使用 hive -H 或者 hive --help 命令可以查看所有命令的帮助,显示如下:
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B --定义用户自定义变量
--database <databasename> Specify the database to use -- 指定使用的数据库
-e <quoted-query-string> SQL from command line -- 执行指定的 SQL
-f <filename> SQL from files --执行 SQL 脚本
-H,--help Print help information -- 打印帮助信息
--hiveconf <property=value> Use value for given property --自定义配置
--hivevar <key=value> Variable subsitution to apply to hive --自定义变量
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file --在进入交互模式之前运行初始化脚本
-S,--silent Silent mode in interactive shell --静默模式
-v,--verbose Verbose mode (echo executed SQL to the console) --详细模式
2、交互式命令行
直接使用 hive 命令,不加任何参数,即可进入交互式命令行。
3、非交互式
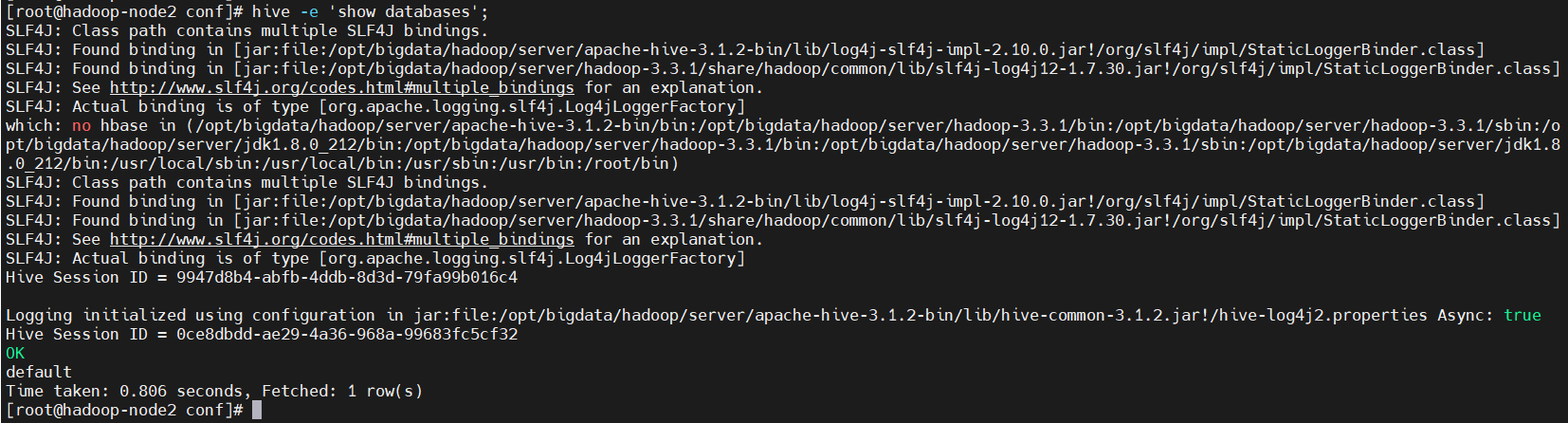
在不进入交互式命令行的情况下,可以使用 hive -e 执行 SQL 命令。
示例:
$ hive -e 'show databases';
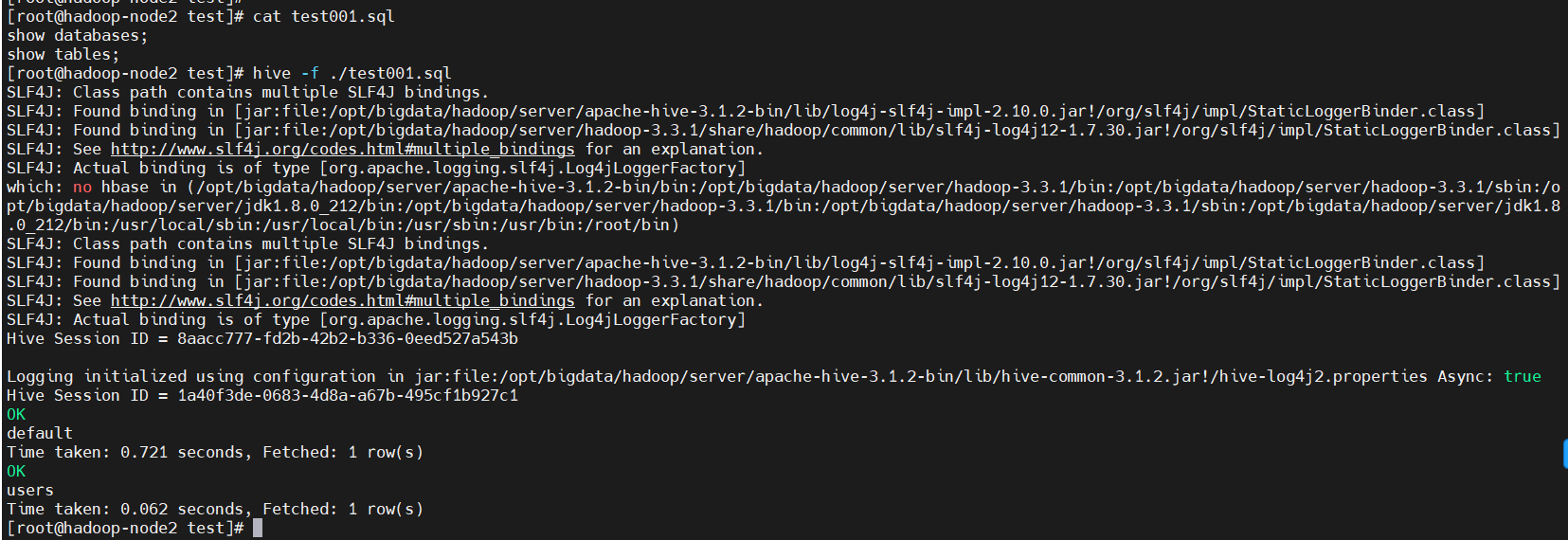
4、接SQL文件非交互式执行SQL脚本
用于执行的 sql 脚本可以在本地文件系统,也可以在 HDFS 上。
准备一个sql文件test001.sql
$ cat test001.sql
show databases;
show tables;
本地文件系统执行
hive -f ./test001.sql
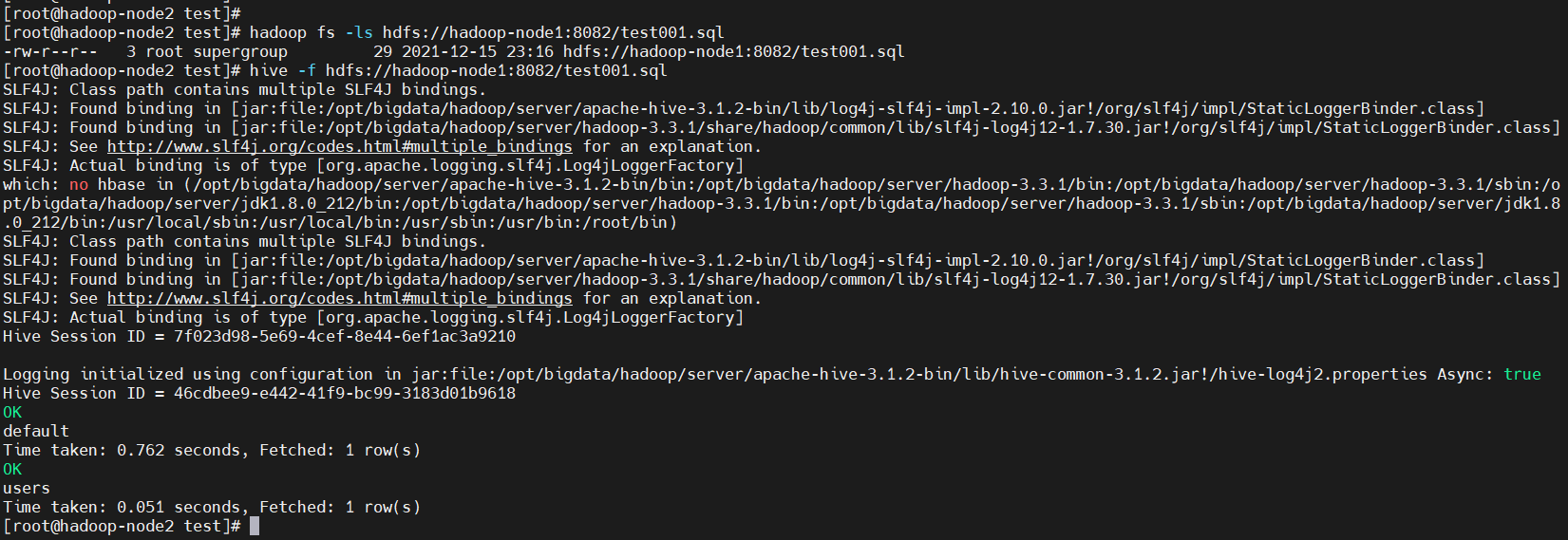
HDFS文件系统执行
# 先把sql文件传到hdfs上
$ hadoop fs -put test001.sql /
$ hadoop fs -ls hdfs://hadoop-node1:8082/test001.sql
$ hive -f hdfs://hadoop-node1:8082/test001.sql
5、配置Hive变量
$ hadoop fs -mkdir -p /user/hive/warehouse/test
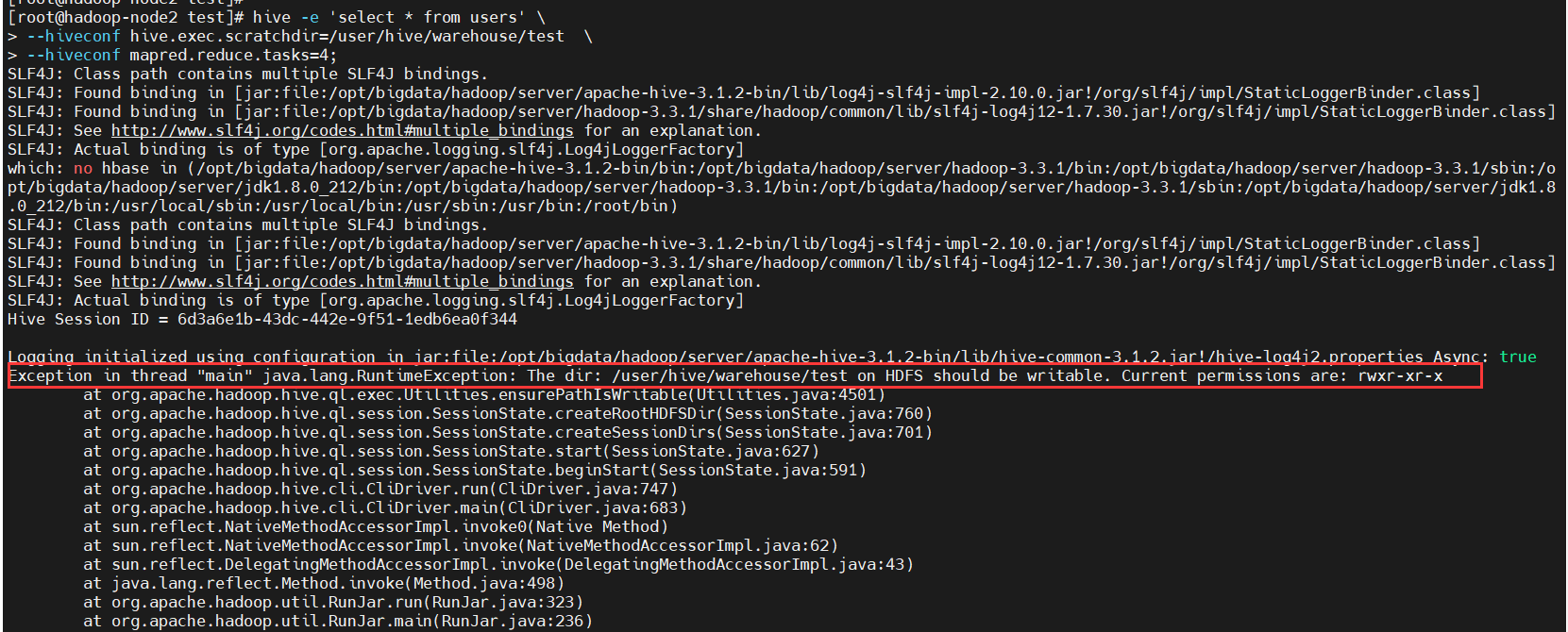
$ hive -e 'select * from users' \
--hiveconf hive.exec.scratchdir=/user/hive/warehouse/test \
--hiveconf mapred.reduce.tasks=4;
发现hdfs的目录没有写权限
添加权限再执行
$ hadoop fs -chmod -R 777 /user/hive/warehouse/test
$ hive -e 'select * from users' \
--hiveconf hive.exec.scratchdir=/user/hive/warehouse/test \
--hiveconf mapred.reduce.tasks=4;
2)Beeline CLI(推荐)
HiveServer2
- Hive 内置了 HiveServer 和 HiveServer2 服务,两者都允许客户端使用多种编程语言进行连接,但是 HiveServer 不能处理多个客户端的并发请求,所以产生了 HiveServer2。
- HiveServer2(HS2)允许远程客户端可以使用各种编程语言向 Hive 提交请求并检索结果,支持多客户端并发访问和身份验证。HS2 是由多个服务组成的单个进程,其包括基于 Thrift 的 Hive 服务(TCP 或 HTTP)和用于 Web UI 的 Jetty Web 服务器。
- HiveServer2 拥有自己的 CLI(Beeline),Beeline 是一个基于 SQLLine 的 JDBC 客户端。由于 HiveServer2 是 Hive 开发维护的重点 (Hive0.15 后就不再支持 hiveserver),所以 Hive CLI 已经不推荐使用了,官方更加推荐使用 Beeline。
1、查看帮助
Beeline 拥有更多可使用参数,可以使用 beeline --help 查看,完整参数如下:
$ beeline --help
Usage: java org.apache.hive.cli.beeline.BeeLine
-u <database url> the JDBC URL to connect to
-r reconnect to last saved connect url (in conjunction with !save)
-n <username> the username to connect as
-p <password> the password to connect as
-d <driver class> the driver class to use
-i <init file> script file for initialization
-e <query> query that should be executed
-f <exec file> script file that should be executed
-w (or) --password-file <password file> the password file to read password from
--hiveconf property=value Use value for given property
--hivevar name=value hive variable name and value
This is Hive specific settings in which variables
can be set at session level and referenced in Hive
commands or queries.
--property-file=<property-file> the file to read connection properties (url, driver, user, password) from
--color=[true/false] control whether color is used for display
--showHeader=[true/false] show column names in query results
--headerInterval=ROWS; the interval between which heades are displayed
--fastConnect=[true/false] skip building table/column list for tab-completion
--autoCommit=[true/false] enable/disable automatic transaction commit
--verbose=[true/false] show verbose error messages and debug info
--showWarnings=[true/false] display connection warnings
--showNestedErrs=[true/false] display nested errors
--numberFormat=[pattern] format numbers using DecimalFormat pattern
--force=[true/false] continue running script even after errors
--maxWidth=MAXWIDTH the maximum width of the terminal
--maxColumnWidth=MAXCOLWIDTH the maximum width to use when displaying columns
--silent=[true/false] be more silent
--autosave=[true/false] automatically save preferences
--outputformat=[table/vertical/csv2/tsv2/dsv/csv/tsv] format mode for result display
--incrementalBufferRows=NUMROWS the number of rows to buffer when printing rows on stdout,
defaults to 1000; only applicable if --incremental=true
and --outputformat=table
--truncateTable=[true/false] truncate table column when it exceeds length
--delimiterForDSV=DELIMITER specify the delimiter for delimiter-separated values output format (default: |)
--isolation=LEVEL set the transaction isolation level
--nullemptystring=[true/false] set to true to get historic behavior of printing null as empty string
--maxHistoryRows=MAXHISTORYROWS The maximum number of rows to store beeline history.
--convertBinaryArrayToString=[true/false] display binary column data as string or as byte array
--help display this message
2、常用参数
在 Hive CLI 中支持的参数,Beeline 都支持,常用的参数如下。更多参数说明可以参见官方文档 Beeline Command Options
| 参数 | 说明 |
|---|---|
| -u |
数据库地址 |
| -n |
用户名 |
| -p |
密码 |
| -d |
|
| -e |
执行 SQL 命令 |
| -f |
执行 SQL 脚本 |
| -i (or)–init |
在进入交互模式之前运行初始化脚本 |
| –property-file |
指定配置文件 |
| –hiveconf property=value | 指定配置属性 |
| –hivevar name=value | 用户自定义属性,在会话级别有效 |
3、通过代理用户连接 Hive(不需要配置用户名和密码)
1)在hive服务的安装节点的hive-site.xml配置文件中添加以下配置
<!-- host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop-node1</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
<!-- hs2端口 默认是1000,为了区别,我这里不使用默认端口-->
<property>
<name>hive.server2.thrift.port</name>
<value>11000</value>
</property>
2)修改hadoop配置文件core-site.xml,表示设置可访问的用户及用户组
配置hadoop core-site.xml,再core-site.xml文件中追加如下内容
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
【注意】hadoop.proxyuser.root.hosts和hadoop.proxyuser.root.hosts,其中“root”是连接beeline的用户,将“root”替换成自己的用户名即可。,这个用户是什么不重要,它就是个超级代理。
改完hadoop-node1后,把配置也推送到其它节点上,然后重启hadoop就行
$ /opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop
$ scp core-site.xml hadoop-node2:/opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop/
$ scp core-site.xml hadoop-node2:/opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop/
# 重启hadoop
$ stop-all.sh
$ start-all.sh
3)启动hiveserver2(hs2)
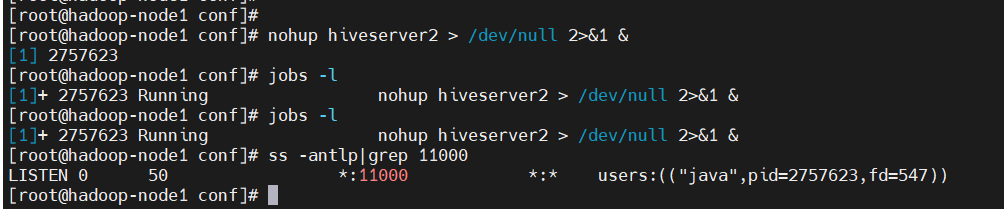
$ nohup hiveserver2 > /dev/null 2>&1 &
$ jobs -l
# 启动有点慢,可以稍等一段时间再查看端口
$ ss -antlp|grep 11000
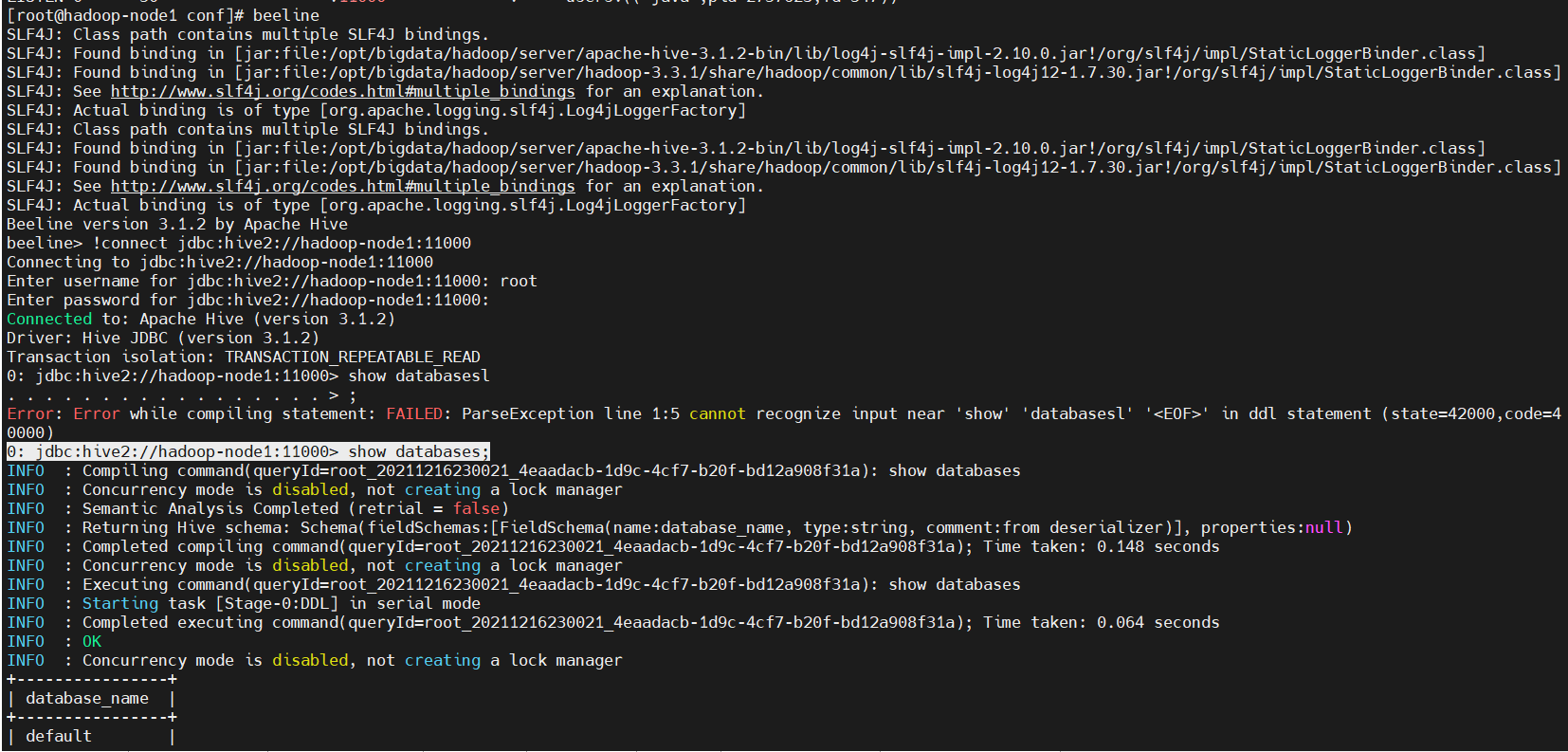
4)连接,这里root就是上面core-site.xml配置的代理用户
【第一种方式】
$ beeline
beeline> !connect jdbc:hive2://hadoop-node1:11000
Enter username for jdbc:hive2://hadoop-node1:11000: root
# 密码直接回车就行
Enter password for jdbc:hive2://hadoop-node1:11000:
0: jdbc:hive2://hadoop-node1:11000> show databases;
【第二种方式】
$ beeline -u jdbc:hive2://hadoop-node1:11000 -n root

5)在~/.bashrc中添加alias
$ alias beeline="beeline -u jdbc:hive2://hadoop-node1:11000 -n root"
$ beeline
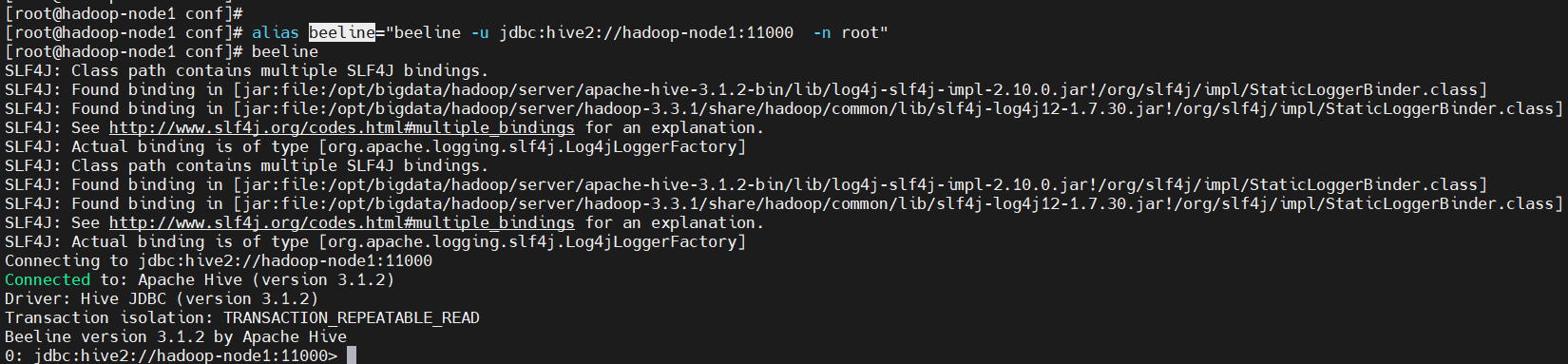
除了上面那种连接方式,还有以下几种方式
默认配置如下:
<!-- hs2端口 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- hs2用户登录方式,NONE表示不登录 -->
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
</property>
这里需要稍微讲一下hive.server2.authentication的这种类型,连接方式如下:
- NONE:这种类型就是默认值,hive没有启用用户安全认证,任何登录者都拥有超级权限,可以对hive进行任意操作。
- NOSASL:需要任意一个用户名,不需要密码,不填写或者填写错误用户名会导致报错。
- KERBEROS:用户需要拥有hive的keytab文件(类似于ssh-key等密钥),有了keytab就相当于拥有了永久的凭证,不需要提供密码,因此只要linux的系统用户对于该keytab文件有读写权限,就能冒充指定用户访问hadoop,因此keytab文件需要确保只对owner有读写权限。
- LDAP:hive采用ldap统一认证服务,连接访问时需要提供username和password。
- PAM:hive采用pam认证模块,同样需要提供username和password,只是原理大不相同。
PAM(Pluggable Authentication Modules)即可插拔式认证模块,它是一种高效而且灵活的用户级别的认证方式,它也是当前Linux服务器普遍使用 的认证方式。PAM可以根据用户的网段、时间、用户名、密码等实现认证。并不是所有需要验证的服务都使用PAM来验证,如MySQL-Server就没有安 装相应的PAM文件。
- CUSTOM:可以根据自身需求对用户登录认证进行一定客制,比如将密码通过md5进行加密等。
3)DataGrip客户端
这里提供一个别人破解安装DataGrip的教程,如果没安装DataGrip,可以参考一下:http://www.32r.com/soft/70050.html
1、创建工程

2、关联本地目录到工程
3、配置连接hive

六、实战操作
Hive SQL跟mysql等关系型数据库的操作非常相似,如果了解过或学习过关系型数据库,使用Hive SQL就非常简单,学习成本也非常低。
1)建库,建表
hive有个默认的数据库default
1、建库
# 建库
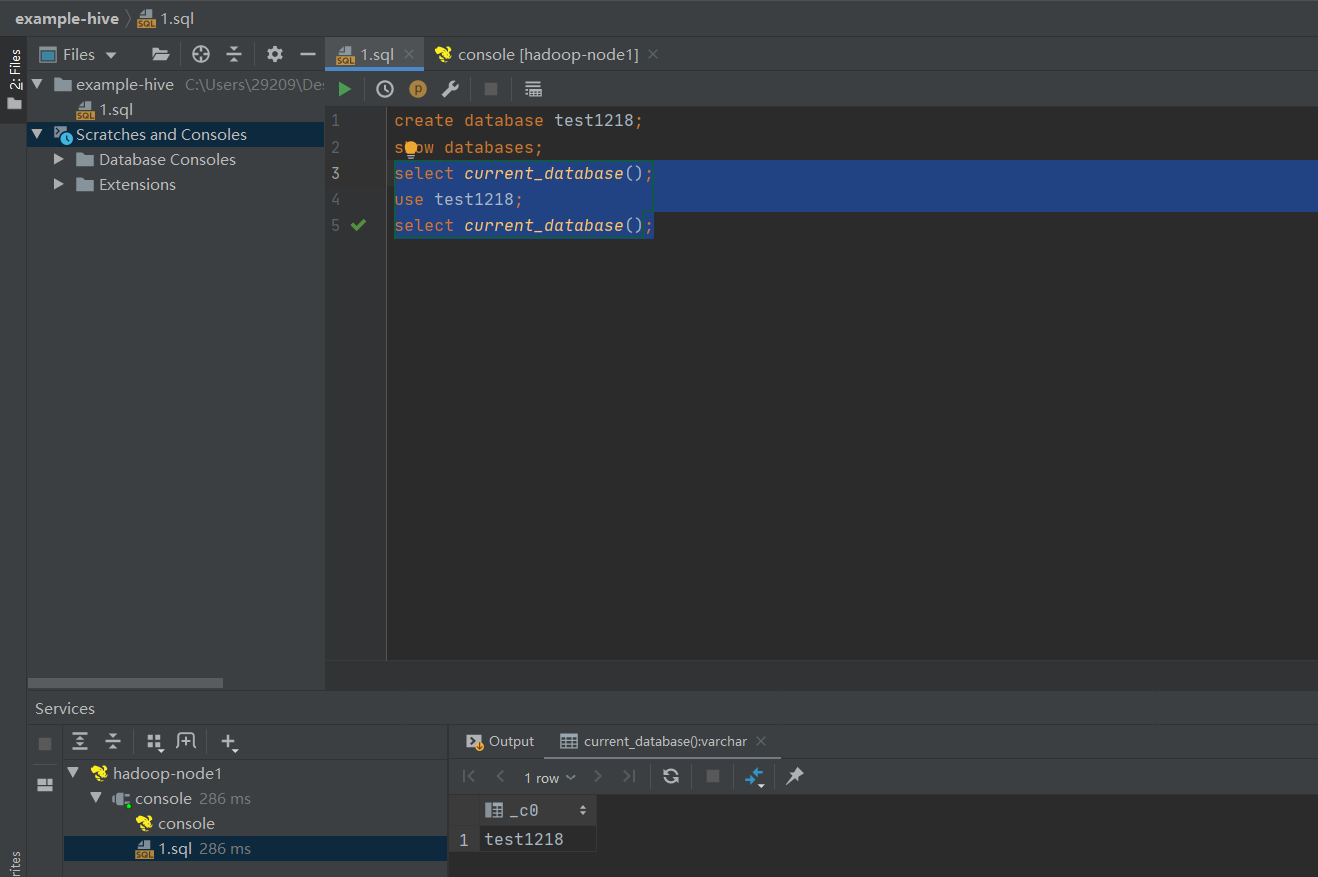
create datatabse test1218
# 查库
show databases;
# 查看当前所在库
select current_database();
# 切库
use test1218;
select current_database();
2、建表
分隔符
Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法。
\n 每行记录分隔符
^A 分隔列(八进制 \001),对应ascii码SOH;
^B 分隔ARRAY或者STRUCT中的元素,或者MAP中多个键值对之间分隔(八进制 \002)
^C 分隔MAP中键值对的“键”和“值”(八进制 \003)
对应sql设置
row format delimited
fields terminated by '\001'
collection items terminated by '\002'
map keys terminated by '\003'
lines terminated by '\n'
stored as textfile;
创建表
-- 创建表时指定库,默认分隔符
CREATE TABLE IF NOT EXISTS test1218.person (
id INT,
name STRING,
age INT,
likes ARRAY<STRING>,
address MAP<STRING,STRING>
);
-- 创建表时指定库,指定分隔符
CREATE TABLE IF NOT EXISTS test1218.person_1 (
id INT COMMENT 'ID',
name STRING COMMENT '名字',
age INT COMMENT '年龄',
likes ARRAY<STRING> COMMENT '爱好',
address MAP<STRING,STRING> COMMENT '地址'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
show tables;

在HDFS页面上查看对应的文件

3、上传表数据到HDFS
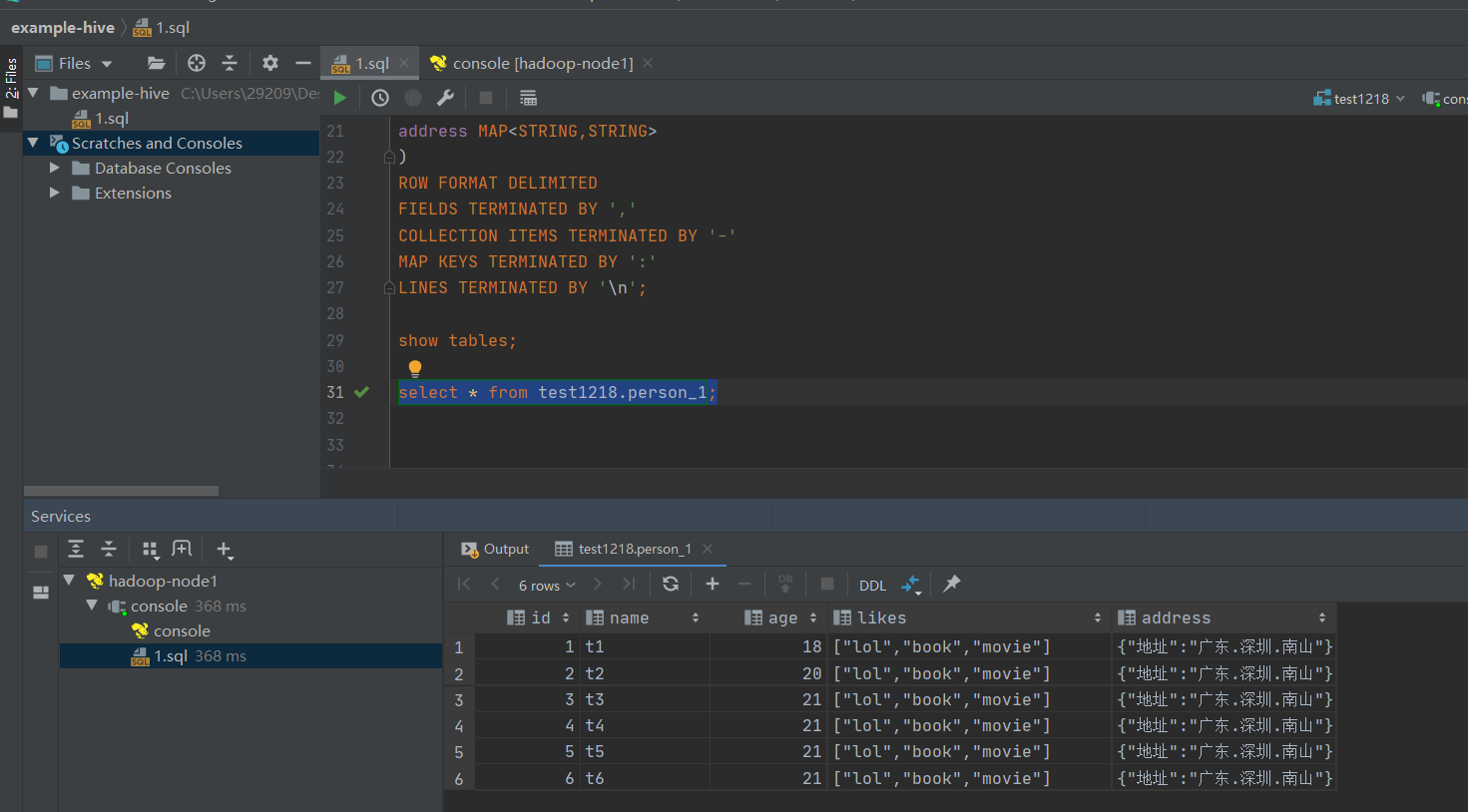
person_1表数据
1,t1,18,lol-book-movie,地址:广东.深圳.南山
2,t2,20,lol-book-movie,地址:广东.深圳.南山
3,t3,21,lol-book-movie,地址:广东.深圳.南山
4,t4,21,lol-book-movie,地址:广东.深圳.南山
5,t5,21,lol-book-movie,地址:广东.深圳.南山
6,t6,21,lol-book-movie,地址:广东.深圳.南山
通过命令上传数据
$ hadoop fs -put person_1-data.txt /user/hive_remote/warehouse/test1218.db/person_1/
$ hadoop fs -ls /user/hive_remote/warehouse/test1218.db/person_1/
查看数据
select * from test1218.person_1;
2)查看
# 显示所有库
show databases ;
# 查看当前库
select current_database();
# 查看default库里的表
show tables in default;
# 查看当前数据里的表
show tables ;
# 查询显示一张表的元数据信息
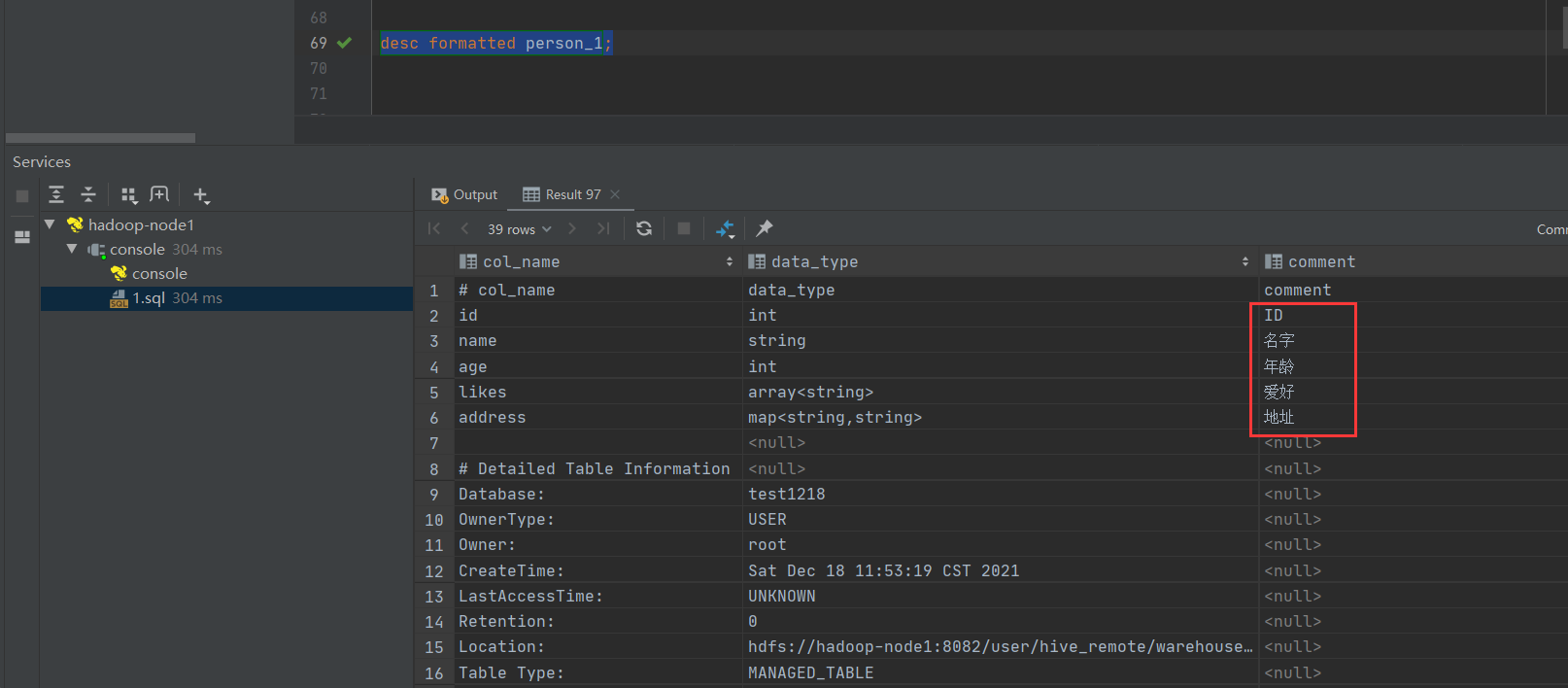
desc formatted person_1;
3)注释COMMENT中文乱码解决
【原因】元数据保存在mysql中,默认不支持中文,默认的编码是latin1
desc formatted person_1;

【解决】修改Hive存储的元数据信息(metastore),下面语句是在mysql中执行,数据库记得换成自己的。
use hive_local;
show tables;
alter table hive_local.COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table hive_local.TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table hive_local.PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table hive_local.PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table hive_local.INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
再查看还是没改过来,是因为对已经创建的表是不生效的,得删除表重新创建表才会显示正常。
# 删表
drop table test1218.person_1;
# 创建表
-- 创建表时指定库,指定分隔符
CREATE TABLE IF NOT EXISTS test1218.person_1 (
id INT COMMENT 'ID',
name STRING COMMENT '名字',
age INT COMMENT '年龄',
likes ARRAY<STRING> COMMENT '爱好',
address MAP<STRING,STRING> COMMENT '地址'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
再查看表的元数据信息,中文注释信息显示正常了
desc formatted person_1;
4)Load加载数据(推荐)
# 创建表
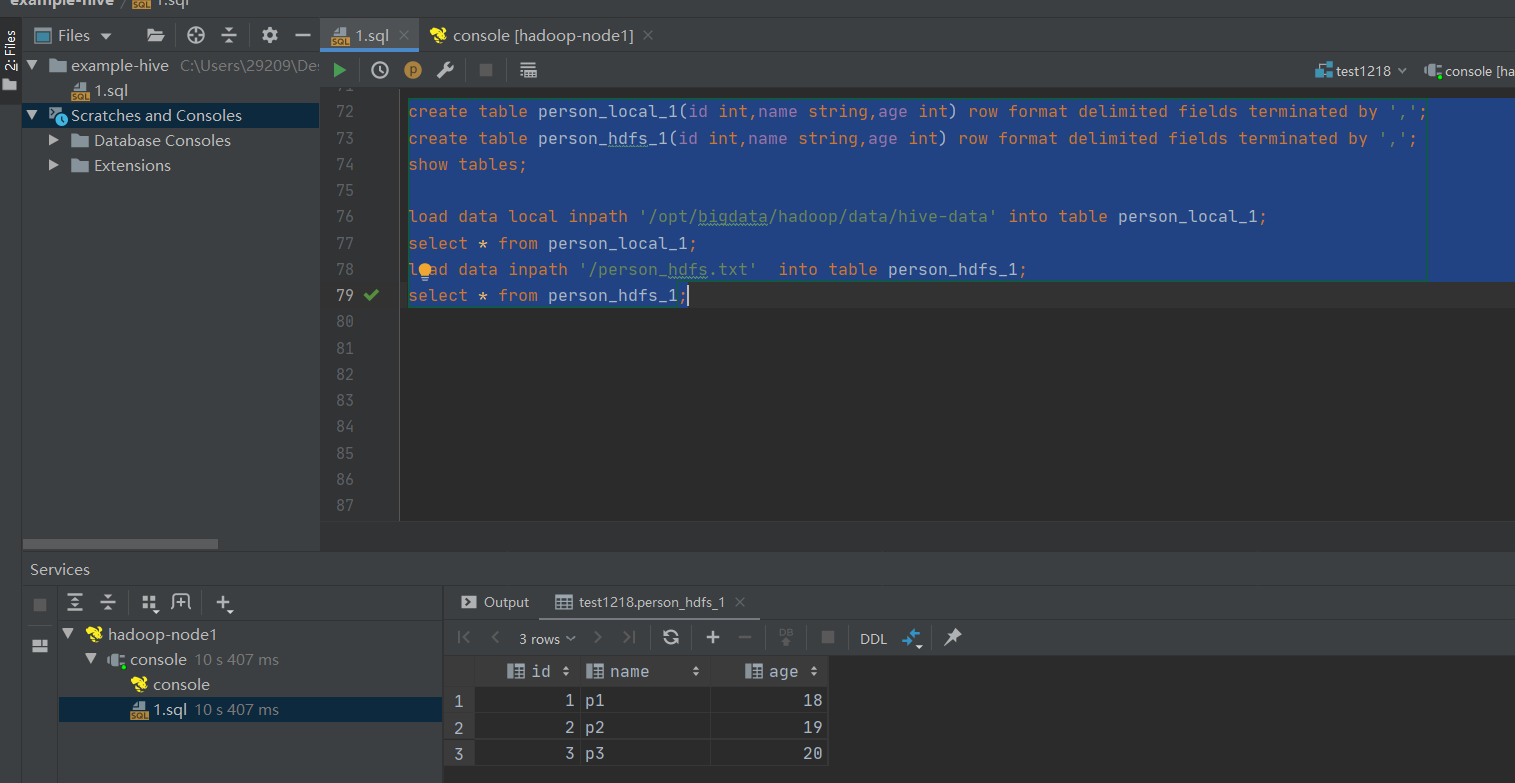
create table person_local_1(id int,name string,age int) row format delimited fields terminated by ',';
create table person_hdfs_1(id int,name string,age int) row format delimited fields terminated by ',';
show tables;
# 从local加载数据,这里的local是指hs2服务所在机器的本地linux文件系统
load data local inpath '/opt/bigdata/hadoop/data/hive-data' into table person_local_1;
# 查询
select * from person_local_1;
# 从hdfs中加载数据,这里是移动,会把hdfs上的文件mv到对应的hive的目录下
load data inpath '/person_hdfs.txt' into table person_hdfs_1;
# 查询
select * from person_hdfs_1;
5)Insert添加数据(特别慢,不推荐)
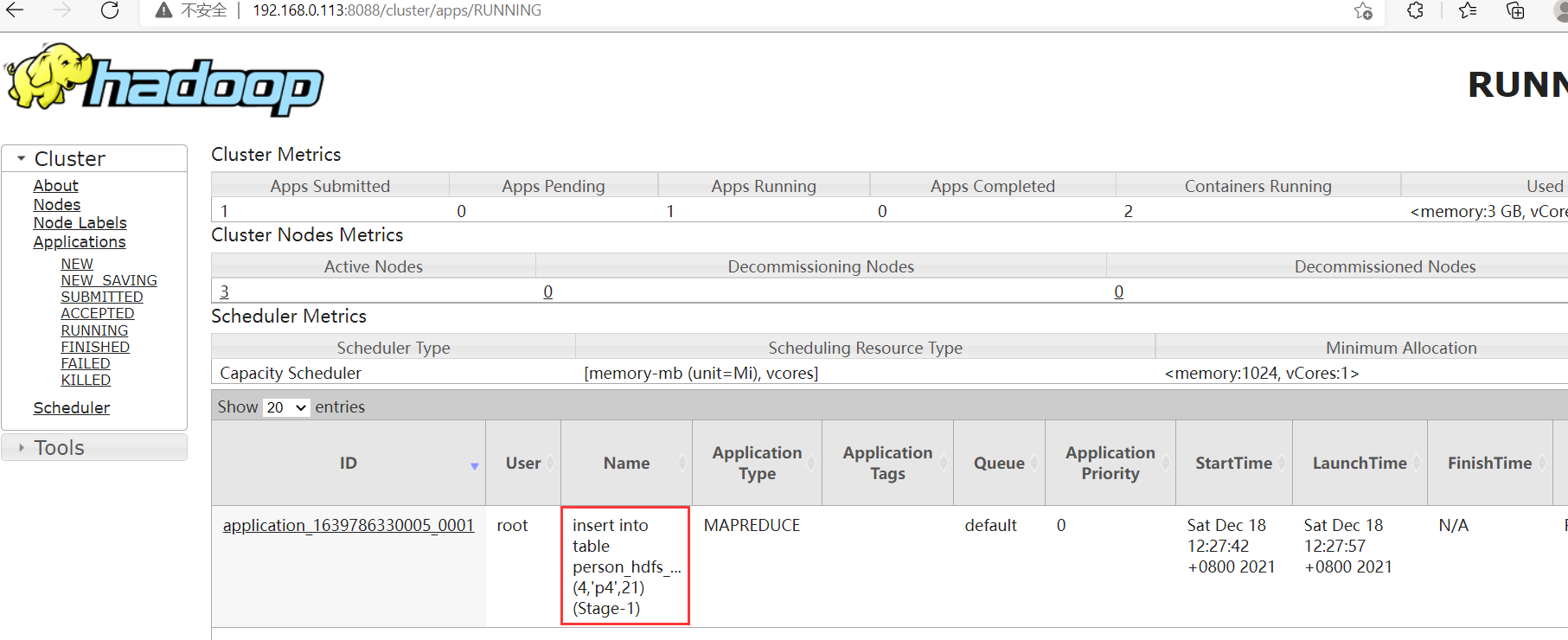
insert into table person_hdfs_1 values (4,'p4',21);
上面那条插入语句会启动一个MR任务
更多Hive SQL操作,可以参考官方文档:https://hive.apache.org/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号