Deep Supervised Cross-modal Retrieval学习笔记
Deep Supervised Cross-modal Retrieval
摘要
在本文中提出了一种新颖的跨模式检索方法,称为深度监督跨模式检索(Deep Supervised Cross-modal Retrieval, DSCMR)。它旨在找到一个通用的表示空间,在其中可以直接比较来自不同模态的样本。
共享
- 提出了一个监督的跨模态学习结构作为不同模态的桥梁。它可以通过保留语义的区分性和模态的不变性有效学习到公共的表达。
- 在最后一层开发了两个具有权重共享约束的子网,以学习图像和文本模态之间的交叉模态相关性。 此外,模态不变性损失被直接计算到目标函数中,以消除跨模态差异。
- 应用线性分类器对公共表示空间中的样本进行分类。
方法
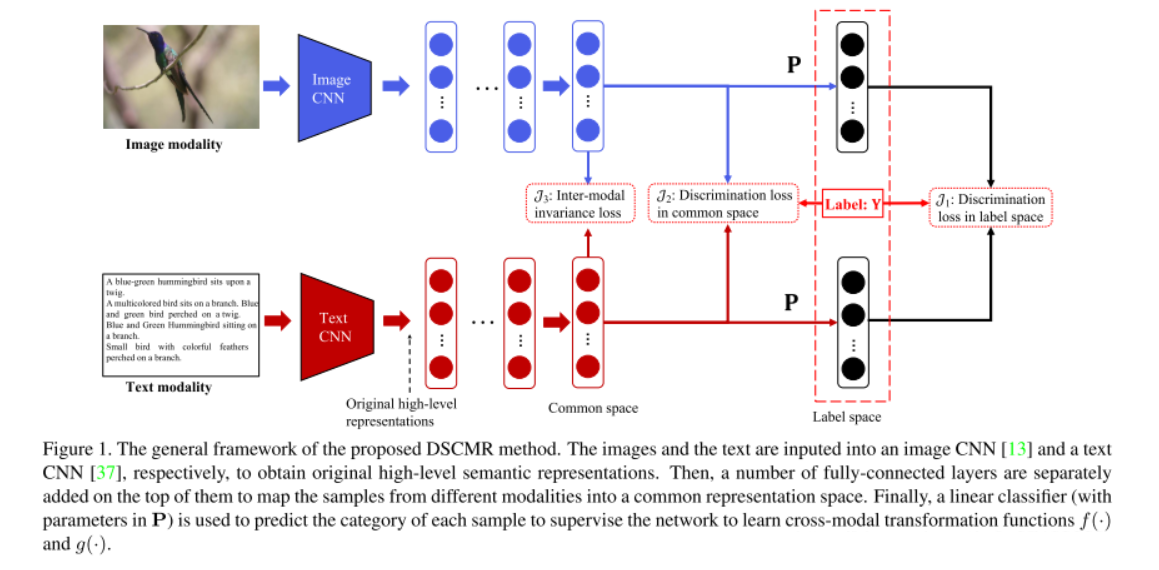
框架
- 包括两个子网络——一个是图像模态,另一个是文本模态,端到端训练
- 对于图像:利用预训练在 ImageNet 的网络提取出图像的 4096 维的特征作为原始的图像高级语义表达。然后后续是几个全连接层,来得到图像在公共空间中的表达。
- 对于文本:利用预训练在 Google News 上的 Word2Vec 模型,来得到 k 维的特征向量。一个句子可以表示为一个矩阵,然后使用一个 Text CNN来得到原始的句子高级语义表达。之后也是同样的形式,后面是几个全连接层来得到句子在公共空间中的表达。
- 为了确保两个子网络能够为图像和文本学到公共的表达,我们使这两个子网络的最后几层共享权重。直觉上这样可以使得同一类的图片和文本生成尽可能相似的表达。
- 最后面是一层全连接层来进行分类。
目标函数
只需要了解两个。。剩下的那个emm比较麻烦,就不提了。
\[J_1 = \frac{1}{n}||P^TU-Y||_F + \frac{1}{n}||P^TV-Y||_F\\
J_3 = \frac{1}{n}||U-V||_F
\]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号