Go xmas2020 学习笔记 04、Strings
 04-Strings、unicode、utf-8、类型描述符、go 字符串在内存中的存储、
Strings、
String structure、
String functions、
Practice
04-Strings、unicode、utf-8、类型描述符、go 字符串在内存中的存储、
Strings、
String structure、
String functions、
Practice
课程地址 go-class-slides/xmas-2020 at trunk · matt4biz/go-class-slides (github.com)
主讲老师 Matt Holiday

04-Strings
Strings

字符串在 go 中都是 unicode ,unicode 是一种特殊的技术用于表示国际通用字符。
rune 相当于 wide character,是 int32 的同义词,四个字节足够大,任何 unicode、字符,逻辑字符 可以指向它。
但是为了让程序更高效,我们不想一直用 4 个字节表示每个字符,因为很多程序使用 ascii 字符。
因此有一种称为 utf-8 编码的 unicode 技术,以字节 byte 表示 unicode 的简便方法。
从物理角度上看,strings 就是 unicode 字符的 utf-8 编码。
ascii characters 适合 0-127 的范围
func main() {
s := "élite"
fmt.Printf("%8T %[1]v %d\n", s, len(s))
fmt.Printf("%8T %[1]v\n", []rune(s))
b := []byte(s)
fmt.Printf("%8T %[1]v %d\n", b, len(b))
}
string élite 6
[]int32 [233 108 105 116 101]
[]uint8 [195 169 108 105 116 101] 6
é 为 233 超出了 ascii 的表示范围,由 2 个字节表示,而不是为每个字符使用 4 个字节,这是 utf8 编码的效果。中文字经常为 20000 的数字,五个中文字会用 15 个字节表示。
len(s) 显示 6 的原因,在程序中字符串的长度是在 utf-8 中编码字符串所必需的字节字符串的长度
The length of a string in the program is the length of the byte string that's necessary to encode the string in utf-8,not the number of unicode characters
就是说给定一个字符串,把它进行 utf-8 编码需要的字节数量就是它的长度,而不是 unicode 字符的数量。
String structure
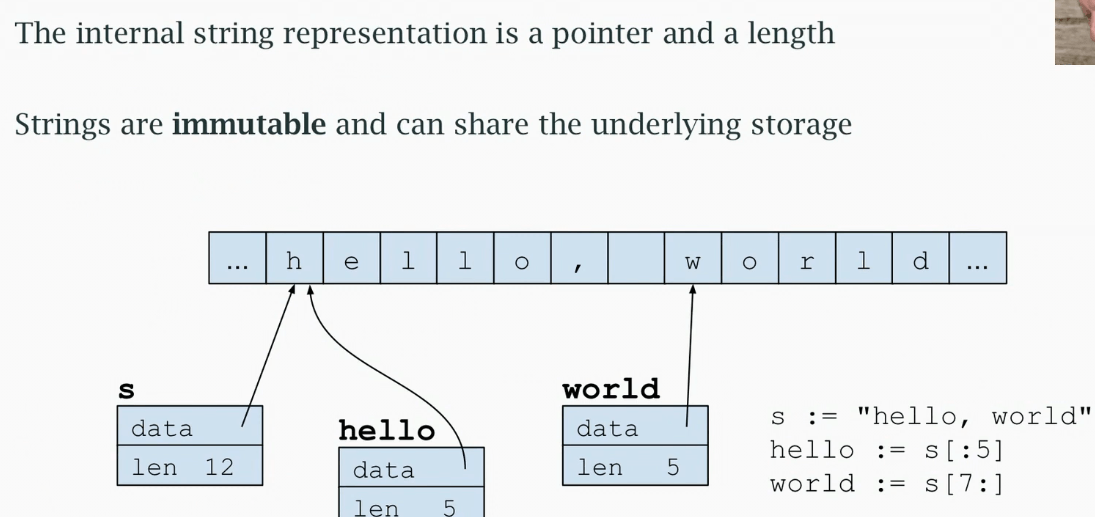
可以把图片左边的 s 理解为一个描述符(描述符不是指针、不是 go 的专业术语),它有指针和额外的信息(字节数)。
go 字符串末尾没有空字节,很多编程语言通过循环字符串判断空字节获取长度,效率并不高。在 go 中字符串长度直接保存在描述符中。
通过索引字符串创建 hello 的时候,hello 的 data 指向的是跟 s 描述符 data 的相同内存地址(共享存储)。
因为字符串没有空字节,而且它们是不可变的,所以共享存储是完全可行的。world 也是同理。它们重用 s 中的内存。
t := s 的结果是 t 将有与 s 一样的内容,但是 t 跟 s 是不一样的描述符。

b、c 与 s 共享存储。
d 开辟了新的内存空间,存入了新的字符串。
s[5] = 'a' 出错,字符串是不可变的,不能单独修改字符串。
s +="es" 相当于 s = s + "es" ,开辟了新的内存空间,复制原有内容,再添加新内容,并使 data 指向新的内存地址。
原来的字符串并没有改变、消失,因为 b、c 依旧指向原来的内存地址,s 指向了新开辟的内存地址。
String functions

s = strings.ToUpper(s) 字符串不允许被更改,所以会创建新字符串进行旧字符串的拷贝并大写。由于开辟了新的内存空间,将返回值给 s 也就很好理解了。
如果没有变量引用字符串,它会自动被垃圾回收。
Practice
做一个替换句子中指定单词的程序
main.go
package main
import (
"bufio"
"fmt"
"os"
"strings"
)
func main() {
if len(os.Args) < 3 {
fmt.Fprintln(os.Stderr, "not enough args")
os.Exit(-1)
}
old, new := os.Args[1], os.Args[2]
scan := bufio.NewScanner(os.Stdin)
for scan.Scan() {
s := strings.Split(scan.Text(), old)
t := strings.Join(s, new)
fmt.Println(t)
}
}
os.Args 运行 go 程序时附加的参数,具体可以看前几节的内容。
buffio.NewScanner(os.Stdin) 扫描仪是一个缓冲io工具,默认以行分割输入的内容。举个例子,如果输入特别大,就可以把它以一系列行的形式读取。
scan.Scan() 将循环读取行,如果有可用的行读取将会返回true。
scan.Text() 获取读取的行。
for 循环中使用 strings 标准库的 Split 方法根据旧单词 变量 old(大小写敏感)分割字符串获得字符串切片。
再将切片传入 strings 标准库的 Join 方法,通过新单词 变量 new 合并字符串。
test.txt
matt went to greece
where did matt go
alan went to rome
matt didn't go there
第一行留空行,因为会读取 BOM 头,具体请看这篇文章
重定向管道流读取TXT文本第一次读取为""空字符串 - 小能日记 - 博客园 (cnblogs.com)
result
cat test.txt | go run . matt ed
ed went to greece
where did ed go
alan went to rome
ed didn't go there
这里我们使用了重定向管道,读取 test.txt 的内容当做 main.go 的程序输入,指令在 linux 是 go run . matt ed < test.txt。
old, new := os.Args[1], os.Args[2]
old, new = new, old
值得注意的一点是初始化变量的方式,使用一行初始化两个变量。巧妙的是可以用这种方式进行两个变量值的交换。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号