
Qt+Tesseract实现文字识别
Tesseract 的介绍可以参考我的这篇博客:Windows下Tesseract-OCR的安装与使用
上面博客安装的是软件,只能通过命令行来识别,不能调用其代码 API,有很大的局限性,下面讲解通过 Tesseract API 的方式,与 Qt 配合实现一个简单的图片文字识别程序。
一、Tesseract API的介绍和使用准备
1.1 Tesseract API的基本概念
Tesseract API 是 Tesseract OCR 引擎的编程接口,允许开发者在自己的应用程序中集成文字识别功能。它支持多种编程语言,包括但不限于 C++、C#、Python 等。通过 API,用户可以执行包括图片上传、图像预处理、文字识别和结果处理等在内的操作。
Tesseract API的主要组件包括:
-
Tesseract::TessBaseAPI : 这是一个基本的 OCR 类,提供了几乎所有的 OCR 操作接口。
-
TessBaseAPISetImage : 用于设置要识别的图像。
-
TessBaseAPIRecognize : 用于执行识别操作。
-
TessBaseAPIGetUTF8Text : 用于获取识别结果。
1.2 Tesseract API的使用说明
tesseract 提供了丰富的 C++ 接口,方便开发者进行调用。下面介绍一些主要的接口及其使用说明。
tesseract::TessBaseAPI类:这是 tesseract 的核心类,提供了文字识别的主要功能。- 构造函数:
tesseract::TessBaseAPI(),创建一个 TessBaseAPI 对象。
Init 方法
Init 方法:用于初始化 tesseract 引擎。其原型为:
int Init(const char* datapath, const char* language, OcrEngineMode oem = OEM_DEFAULT);
- datapath 是语言数据包所在的目录,如果为 NULL,则使用默认目录;
- language 是要识别的语言,如 “eng” 表示英文,“chi_sim” 表示简体中文;oem是 OCR 引擎模式,默认使用 OEM_DEFAULT。
调用方法如下:
tesseract::TessBaseAPI tess;
if (tess.Init(NULL, "chi_sim+eng") != 0) {
qDebug() << "无法初始化tesseract引擎!";
return -1;
}
上述代码就是初始化 Tesseract 引擎,并设置支持简体中文和英文识别。
SetImage 方法
SetImage 方法:设置要识别的图像。其原型有多种,常用的有:
void SetImage(const unsigned char* imagedata, int width, int height, int bytes_per_pixel, int bytes_per_line);
- imagedata 是图像数据的指针;
- width 和 height 是图像的宽度和高度;
- bytes_per_pixel 是每个像素的字节数,如灰度图像为 1,RGB 图像为 3;
- bytes_per_line 是每行图像的字节数。
调用方法如下(结合 OpenCV):
cv::Mat image = cv::imread("test.png");
if (image.empty()) {
qDebug() << "无法读取图像!";
return -1;
}
tess.SetImage(image.data, image.cols, image.rows, image.channels(), image.step);
代码中将 OpenCV 读取的图像设置为 Tesseract 要识别的图像。
GetUTF8Text 方法
GetUTF8Text 方法:获取识别到的 UTF-8 编码的文本。其原型为:
char* GetUTF8Text();
调用如下:
char* outText = tess.GetUTF8Text();
qDebug() << "识别结果:" << QString(outText);
delete[] outText; // 注意释放内存
End 方法
End方法:释放 tesseract 引擎占用的资源。其函数原型为:
void End();
在程序结束时,调用该方法释放资源。
SetPageSegMode 方法
SetPageSegMode 方法:设置页面分割模式,用于指定 tesseract 如何分割图像中的文字区域。例如:
tess.SetPageSegMode(tesseract::PSM_AUTO); // 自动页面分割模式
SetVariable 方法
SetVariable 方法:设置 tesseract 的一些变量参数,以调整识别效果。例如:
tess.SetVariable("tessedit_char_whitelist", "0123456789"); // 只识别数字
二、开发环境搭建
2.1 编译 Tesseract 动态库
我这里没有自己编译 Tesseract 动态库,而是网上下载已经通过源码编译好的库(windows64位的版本)。
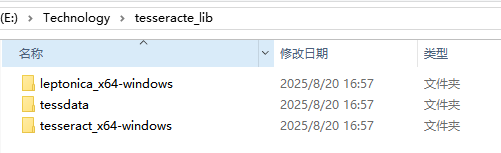
当然你也可以在 GitHub 上找到 Tesseract 的开源项目下载源码自己编译,可以使用 VS、vcpkg、CMake 等方式进行编译。
库下载地址: https://pan.baidu.com/s/1RPYJt2FV3PODw5aJ83BmBQ?pwd=8888 (提取码: 8888)
2.2 配置对应的 MSVC 编译器
这个库如果要在 Qt Creator 上运行,创建的 Qt 工程需要安装配置好对应的 MSVC 编译器,详细过程这里不再赘述,可以参考我的另一篇博客:QtCreator安装配置MSVC编译器
三、使用Tesseract进行简单的文字识别
(1)新建一个工程,使用配置好的 MSVC 编译器,在 .pro 文件中添加下面四个语句:
#配置Tesseract库路径
INCLUDEPATH += E:\Technology\tesseracte_lib\tesseract_x64-windows\include
LIBS+= E:\Technology\tesseracte_lib\tesseract_x64-windows\lib\tesseract41.lib
#配置Leptonica库路径
INCLUDEPATH += E:\Technology\tesseracte_lib\leptonica_x64-windows\include
LIBS+= E:\Technology\tesseracte_lib\leptonica_x64-windows\lib\leptonica-1.78.0.lib
其中,INCLUDEPATH 指定了头文件的所在目录,LIBS 指定了库文件的所在目录以及需要链接的库文件。需要根据实际的 Tesseract 和 Leptonica 安装路径和版本进行修改。
另外介绍下 Leptonica,其是一个图像处理库,Tesseract OCR 依赖于 Leptonica 进行图像处理。
(2)导入头文件(最重要的是最下面的两个 <tesseract/baseapi.h> 和<tesseract/strngs.h>)。使用刚才下载的路径导入即可:
#include <tesseract/baseapi.h>
#include <leptonica/allheaders.h>
(3)代码编写,先不使用 Qt 编写界面,纯 C++ 实现一下文字识别功能,main.cpp 改为:
#include <tesseract/baseapi.h>
#include <leptonica/allheaders.h>
int main() {
// 初始化Tesseract API
tesseract::TessBaseAPI *ocr = new tesseract::TessBaseAPI();
// 初始化API,路径设置为tessdata目录的位置
if (ocr->Init(NULL, "eng")) {
fprintf(stderr, "Could not initialize tesseract.\n");
return 1;
}
// 打开一个包含文字的图像文件
Pix *image = pixRead("E:\\Learn\\learnGit\\untitled2\\ditto.png");
ocr->SetImage(image);
// 获取识别出的文本
char *text = ocr->GetUTF8Text();
printf("识别出的文本: %s\n", text);
// 清理内存
delete [] text;
pixDestroy(&image);
ocr->End();
return 0;
}
注意:
- 要使用 MSVC 的 Release 方式编译运行;
- 要打开的图片文件路径要是绝对路径,而不能是相对路径,否则会打不开图片文件而报错;
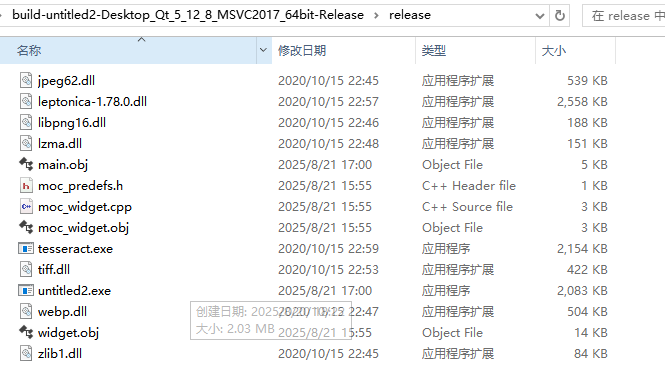
(4)将 tesseracte_lib\tesseract_x64-windows\tools\tesseract 目录下的全部文件复制到可执行程序的同级目录下,否则运行后程序会马上终止运行。拷贝后的可执行文件目录图如下所示:
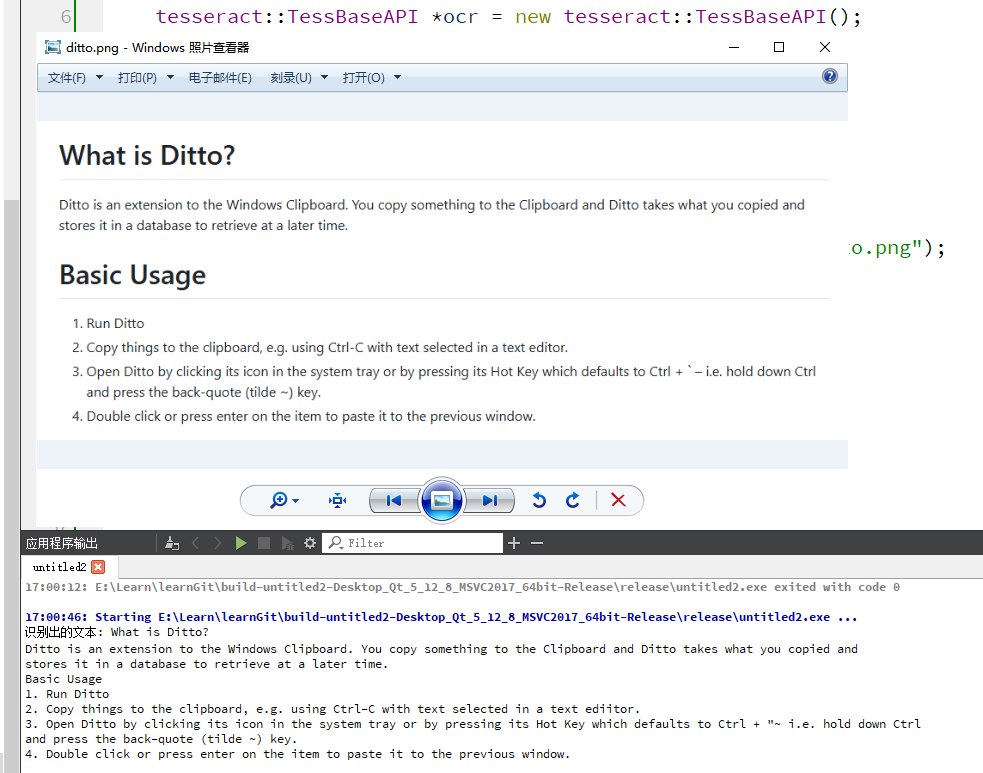
(5)然后可以正常运行识别出了图片文字。运行效果图如下:
四、Qt + Tesseract 实现文字识别界面
这里使用 Qt 编写一个包含 "打开图片" 按钮,选择要识别的图片文件,用标签显示打开的图片,然后使用 Tesseract 文字识别,将识别后的字符串显示在编辑框中。
main.cpp
#include "widget.h"
#include <QApplication>
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
Widget w;
w.show();
return a.exec();
}
widget.h
#ifndef WIDGET_H
#define WIDGET_H
#include <QWidget>
#include <QLabel>
#include <QPushButton>
#include <QTextEdit>
#include <QFileDialog>
#include <QVBoxLayout>
#include <QTextCodec>
#include <QDebug>
#include <tesseract/baseapi.h>
#include <leptonica/allheaders.h>
class Widget : public QWidget
{
Q_OBJECT
public:
Widget(QWidget *parent = nullptr);
~Widget();
private:
QLabel *m_pLabImgBasic; // 基本操作图像Widget
QPushButton *m_pBtnOpen; // 打开图片按钮
QTextEdit *m_pEditOcr; // 显示OCR识别出字符串的编辑框
};
#endif // WIDGET_H
widget.cpp
#include "widget.h"
Widget::Widget(QWidget *parent) : QWidget(parent)
{
// 界面初始化
this->setFixedSize(800, 600);
this->setAttribute(Qt::WA_StyledBackground); // 不继承父窗口样式
// 基本操作图像Widget
m_pLabImgBasic = new QLabel;
m_pLabImgBasic->setFixedSize(640, 360);
m_pLabImgBasic->setStyleSheet("QLabel{border: 1px solid green;}");
// 打开图片
m_pBtnOpen = new QPushButton;
m_pBtnOpen->setFixedSize(100, 30);
m_pBtnOpen->setText(tr("Open"));
// 显示OCR识别出字符串的编辑框
m_pEditOcr = new QTextEdit;
// 图像控件布局
QVBoxLayout *pLayoutImage = new QVBoxLayout;
pLayoutImage->addStretch();
pLayoutImage->addWidget(m_pLabImgBasic);
pLayoutImage->addSpacing(12);
pLayoutImage->addWidget(m_pEditOcr);
pLayoutImage->addStretch();
pLayoutImage->setAlignment(Qt::AlignHCenter);
pLayoutImage->setMargin(0);
// 主布局
QHBoxLayout *pLayoutMain = new QHBoxLayout(this);
pLayoutMain->addStretch();
pLayoutMain->addLayout(pLayoutImage);
pLayoutMain->addStretch();
pLayoutMain->addWidget(m_pBtnOpen);
pLayoutMain->addStretch();
pLayoutMain->setSpacing(0);
pLayoutMain->setMargin(0);
// 打开图片按钮-信号槽
connect(m_pBtnOpen, &QPushButton::clicked, [=]{
// 图片文件对话框(打开中文图片)
QString imagePath = QFileDialog::getOpenFileName(this, tr("Image Dialog"), "F:",tr("Image file(* png * jpg)"));
// 标签显示图片
QPixmap pixmap = QPixmap(imagePath);
pixmap = pixmap.scaled(m_pLabImgBasic->size(), Qt::KeepAspectRatio, Qt::SmoothTransformation); // 自适应图片大小
m_pLabImgBasic->setPixmap(pixmap);
// 初始化Tesseract API
tesseract::TessBaseAPI *ocr = new tesseract::TessBaseAPI();
// 初始化API,路径设置为tessdata目录的位置(这里使用中文语言包)
if (ocr->Init("E:/Technology/tesseracte_lib/tessdata", "chi_sim")) {
fprintf(stderr, "Could not initialize tesseract.\n");
return;
}
// 转码
QTextCodec *code = QTextCodec::codecForName("GB2312");
std::string str = code->fromUnicode(imagePath).data();
// 打开一个包含文字的图像文件
Pix *image = pixRead(str.c_str());
ocr->SetImage(image);
// 获取识别出的文本
char *text = ocr->GetUTF8Text();
qDebug() << text;
// 显示在编辑框中
m_pEditOcr->setText(QString(text));
// 清理内存
delete [] text;
pixDestroy(&image);
ocr->End();
});
}
Widget::~Widget()
{
}
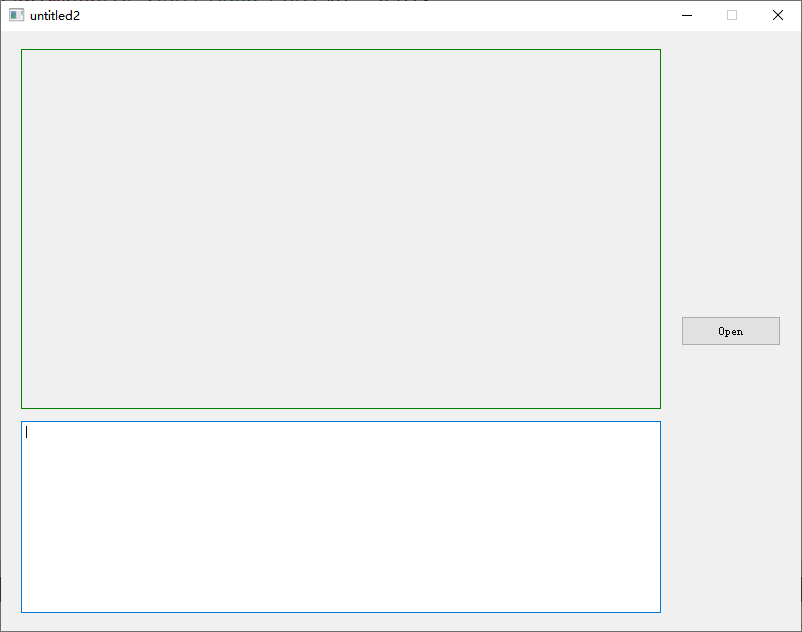
运行后的效果图如下所示:
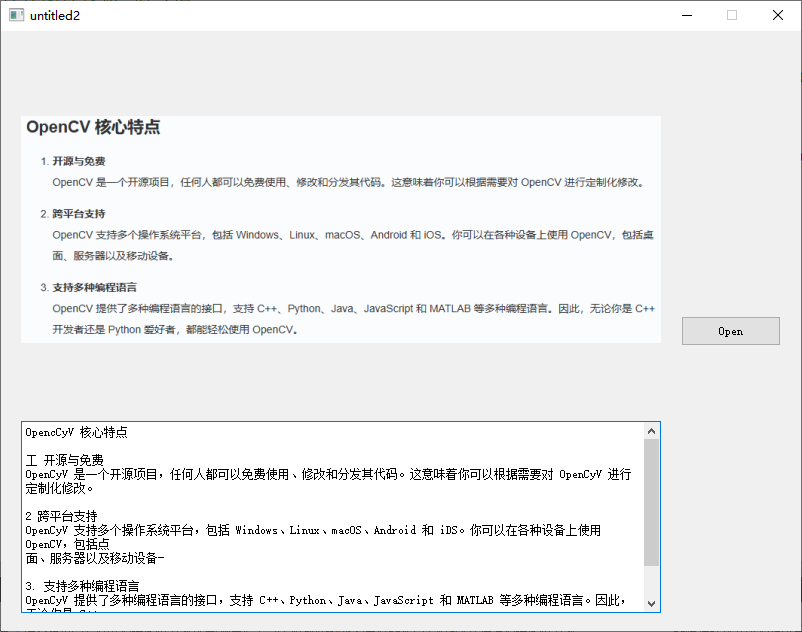
然后点击 Open 按钮打开图片,等待一会儿文字识别成功后的效果图如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号