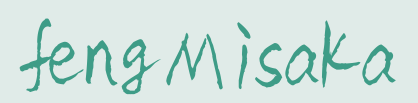

Windows下Tesseract-OCR的安装与使用
一、Tesseract 介绍
Tesseract 是一款开源的 OCR 引擎,由 Google 维护。它支持多种语言的文字识别,具有较高的识别准确率和良好的扩展性。Tesseract 的核心作用是对经过预处理的图像进行分析,提取其中的文字信息并转换为文本。它可以处理不同字体、大小和格式的文字,并且能够通过训练来提高对特定场景文字的识别能力。
官方网站:https://github.com/Tesseract-ocr/Tesseract
官方文档:https://github.com/Tesseract-ocr/tessdoc
语言包地址:https://github.com/Tesseract-ocr/tessdata
下载地址:https://digi.bib.uni-mannheim.de/Tesseract/
OCR是什么?
文字识别,即 Optical Character Recognition,简称 OCR,是指通过电子设备(如扫描仪、相机等)将图像中的文字转换为可编辑的文本格式的技术。其应用场景极为广泛:如电子文档转换,车牌识别系统的自动识别和管理;金融的票据识别提取支票、发票上的关键信息;翻译类 APP 通过摄像头识别外文并实时翻译,极大地便利了人们的跨语言交流。
然而,OCR 技术的实现并非易事,面临着诸多技术难点。首先是图像质量的影响,如模糊、倾斜、光照不均、存在噪声等,都会导致文字识别准确率下降。其次,文字的字体、大小、颜色各异,以及可能存在的复杂背景,也会给识别带来挑战。此外,对于手写体文字,由于其个性化强、规范性差,识别难度更大,所以一般需要使用 OpenCV 来搭配处理图像。
Tesseract 的特点
Tesseract 最初是由惠普公司开发的 OCR 引擎,后来被 Google 收购并开源。经过多年的发展和优化,Tesseract 已经成为目前最受欢迎的开源 OCR 引擎之一。
Tesseract 具有以下特点:
- 开源免费:可以自由使用和修改,无需支付任何费用,降低了开发成本。
- 多语言支持:支持超过 100 种语言的文字识别,包括中文、英文、日文、韩文等,满足不同场景的需求。
- 高识别准确率:在经过适当的图像预处理和训练后,Tesseract 能够达到较高的识别准确率,尤其是对于印刷体文字。
- 跨平台性:可以在 Windows、Linux、Mac 等多个操作系统上运行。
- 可扩展性:支持用户自定义训练数据,以提高对特定字体、特定场景文字的识别能力。
Tesseract 的核心功能与工作原理
Tesseract 的核心功能是对图像中的文字进行识别并转换为文本。其工作原理主要包括以下几个步骤:
- 图像预处理:Tesseract 首先会对输入的图像进行一些基本的预处理,如二值化、去噪等,但这部分功能相对简单,通常需要结合 OpenCV 进行更复杂的预处理。
- 文字区域检测:Tesseract 会分析图像,找出其中可能包含文字的区域。
- 字符分割:将文字区域中的字符逐个分割出来,以便进行单独识别。
- 特征提取:对每个分割出来的字符提取特征,如形状、轮廓、笔画等。
- 字符识别:将提取到的字符特征与训练数据中的特征进行比对,从而识别出字符。
- 文本输出:将识别出的字符组合成文本,并输出给用户。
二、下载Tesseract安装包
当前选择 5.5.0 版本下载,下载地址为:
https://github.com/Tesseract-ocr/Tesseract/releases/tag/5.5.0
选择示意图如下:

下载完成后,运行安装程序,需要特别注意的是,安装过程中会涉及到语言数据包的选择,初学者可以选择英语作为基础语言包,后期可按需下载其他语言包进行安装。
三、运行安装包进行安装
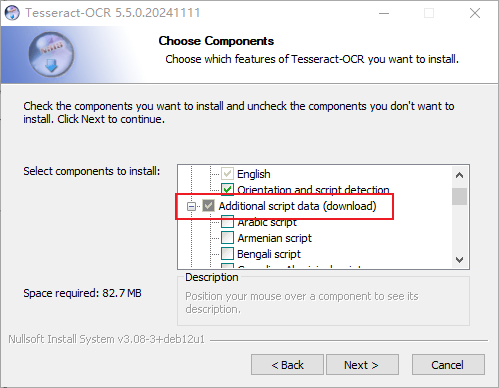
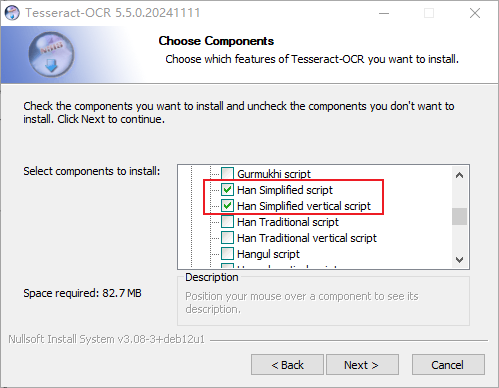
(1)选择附加脚本和语言数据。
没特殊需要只下载中文语言包就行:
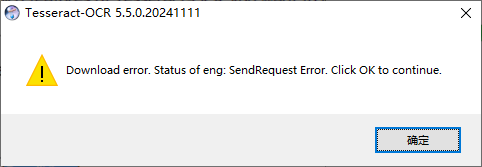
(2)忽略安装过程中的报错警告框
安装语言包,即使是默认带的英文语言包,也大概率会因为网络问题安装失败报错,不过先点击确定按钮忽略继续安装,报错的解决方案下面会讲:
(3)选择软件安装位置
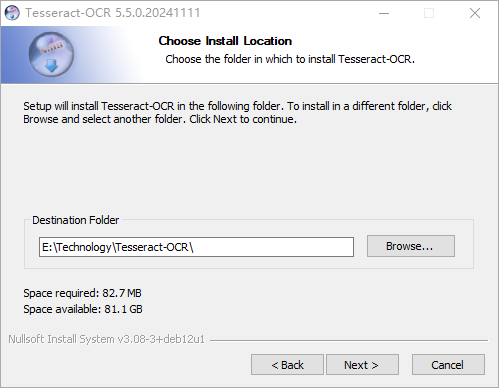
(4)选择是否创建快捷方式
到这一步就安装完成了,下面配置环境变量。
四、Tesseract-OCR配置 添加进环境变量
安装完成后,需要配置 2 个路径的环境变量。
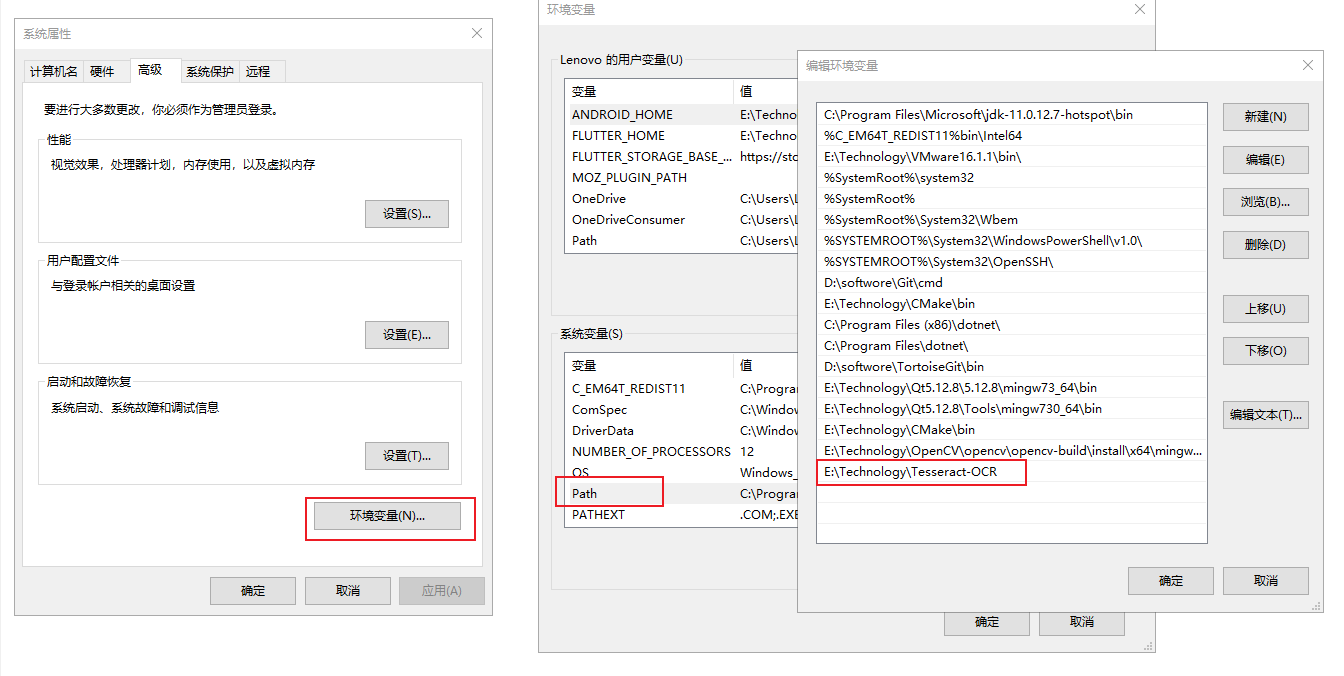
(1)安装路径的环境变量
将 Tesseract 的安装路径添加到系统的环境变量中。这样可以在命令提示符(CMD)中直接调用 Tesseract。具体步骤如下:
- 右键点击 “计算机” 或 “此电脑”,选择 “属性”。
- 点击 “高级系统设置”,然后在系统属性窗口点击“环境变量”按钮。
- 在 “系统变量” 区域,找到 “Path” 变量,选择它,然后点击 “编辑”。
- 点击 “新建”,将 Tesseract 的安装路径,例如
E:\Technology\Tesseract-OCR添加到列表中。 - 点击 “确定” 保存环境变量设置。
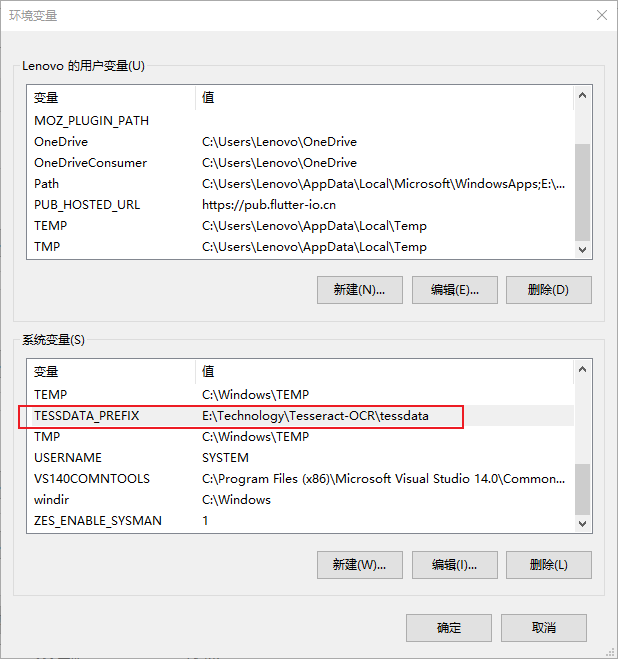
(2)语言包路径的环境变量
也要将语言包路径添加到环境变量中,环境变量名为:TESSDATA_PREFIX:
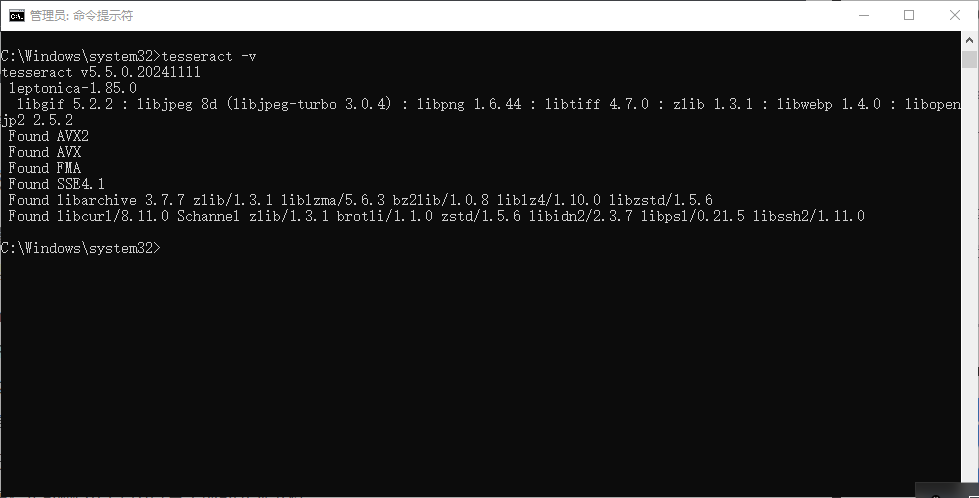
五、检查是否安装配置成功
打开 cmd,输入命令 Tesseract -v,看到输出版本信息即代表安装成功。
六、缺乏语言包使用报错和解决方案
识别命令
Tesseract 图片路径 结果文件名 -l 语言
- 将
cmd切换到图片所在路径,则可以只输入图片名,否则需要全路径 - 结果文件名不可以加后缀,必定会自动加
.txt后缀,如果结果文件名写a.txt,则最后输出的文件名为a.txt.txt。 -l是英文字母L,不是数字1,language 的意思。- 语言英文为
eng,简体中文为chi_sim
使用报错
google 的图片如下:

将 google.png 拷贝到安装目录下(E:\Technology\Tesseract-main), 然后打开 cmd,执行下面的识别命令:
Tesseract google.png google -l eng
报错:
Error opening data file E:\Technology\Tesseract-OCR/tessdata/eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory.
Failed loading language 'eng'
Tesseract couldn't load any languages!
Could not initialize Tesseract.
报错原因:TESSDATA_PREFIX 环境变量已经配置了,但是 tessdata 目录下不存在 eng 英文语言包,因为前面安装的时候由于网络问题下载失败了。所以需要去 GitHub 下载。
解决方案
直接去 https://github.com/Tesseract-ocr/tessdata/blob/main/eng.traineddata 下载英文语言包:eng.traineddata,然后将其拷贝到 E:\Technology\Tesseract-OCR\tessdata 目录下。(其它比如简体中文语言包,也可在这个链接的上一级目录寻找下单独下载)
然后重新打开 cmd,执行命令 Tesseract --list-langs 检测语言包是否成功配置,这里成功配置了,如下图所示:

七、使用Tesseract进行OCR识别
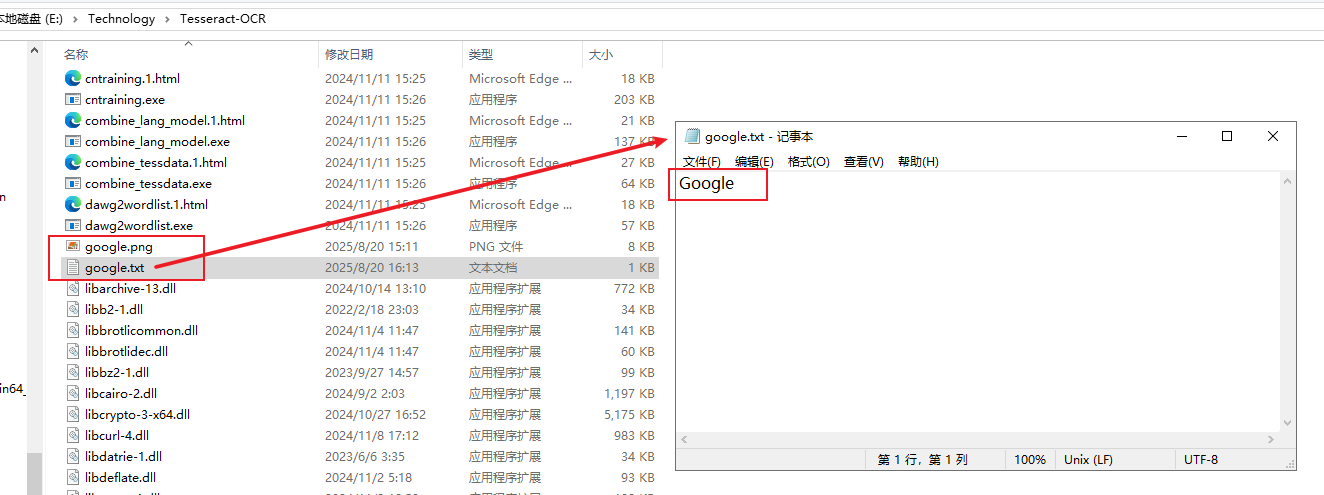
然后再执行下面的识别命令:
Tesseract google.png google -l eng
这时不会再报错了,成功产生了一个 google.txt 文件,打开就能看到转化后的文字了,如下图所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号