
【ARM Cache 与 MMU 系列文章 6.3 – Cache Tag 与物理地址是什么关系?】
Cache Tag 和 物理地址
在ARM架构中,缓存(Cache)的设计是提高数据访问效率的关键机制。每个缓存行(Cache Line)都有一个与之关联的标签( Tag ),该 标签记录了与该行相关联的外部存储器的物理地址 。缓存行的大小是由实现定义的(implementation defined),但由于互连(interconnect)的原因,所有核心(Cores)应该具有相同的缓存行大小。
缓存中数据的定位是通过访问的物理地址来确定的:
- 物理地址的最不重要位(Least Significant Bits)用于在缓存行内选择相关项, 比如一个cache line 的某个word;
- 物理地址中间位(Middle Bits)用作索引来选择缓存集合(Cache Set)中的特定行。
- 物理地址最重要位(Most Significant Bits)识别地址的其余部分,并用于与该行存 储的标签 进行比较。
在ARMv8体系结构中,数据缓存通常是物理索引 、物理标签(PIPT,Physically Indexed, Physically Tagged),但也可以是非别名虚拟索引、物理标签(VIPT,Virtually Indexed, Physically Tagged)。
缓存中的每一行包括:
- 标签值(Tag Value) :来自关联物理地址的标签值。
- 有效位(Valid Bits) :用于指示行是否存在于缓存中,即该标签是否有效。如果缓存在多个核之间是一致的,有效位也可以是MESI(Modify, Exclusive, Shared, Invalid)状态的状态位。
- 脏数据位(Dirty Data Bits) :用于指示缓存行中的数据与外部存储器不一致。
缓存的关键组成部分和功能
- 标签(Tag) :帮助缓存确定存储在特定缓存行中的数据对应于主存储器中的哪个位置。
- 有效位(Valid Bit) :指示缓存行中的数据是否有效,有助于缓存维护数据的一致性和正确性。
- 脏数据位(Dirty Bit) :指示缓存行中的数据自从被加载进来后是否被修改过,如果缓存行被标记为“脏”,则在该缓存行被替换前,其数据需要写回到主存储器以保持数据一致性。
- 索引(Index)和最不重要位(Offset) :用来定位缓存中的具体数据位置,从而快速访问缓存行中存储的数据。
缓存的这种组织方式是为了快速确定数据是否存在于缓存中,并快速定位和访问这些数据,从而减少对主存储器的访问次数,提高处理器的执行效率。
ARM缓存采用的是多路组相连(Set Associative)缓存的设计。这意味着对于任何给定的地址,都有多个可能的缓存位置(也称为“路”或“Ways”)。多路组相连缓存显著降低了缓存抖动(Cache Thrashing)的可能性,从而提高了程序执行速度,但代价是增加了硬件复杂性和轻微增加了功耗。
以Cortex-A57处理器的数据缓存为例,一个简化的四路组相连32KB L1缓存,其缓存行长度为16字(64字节)如下图:
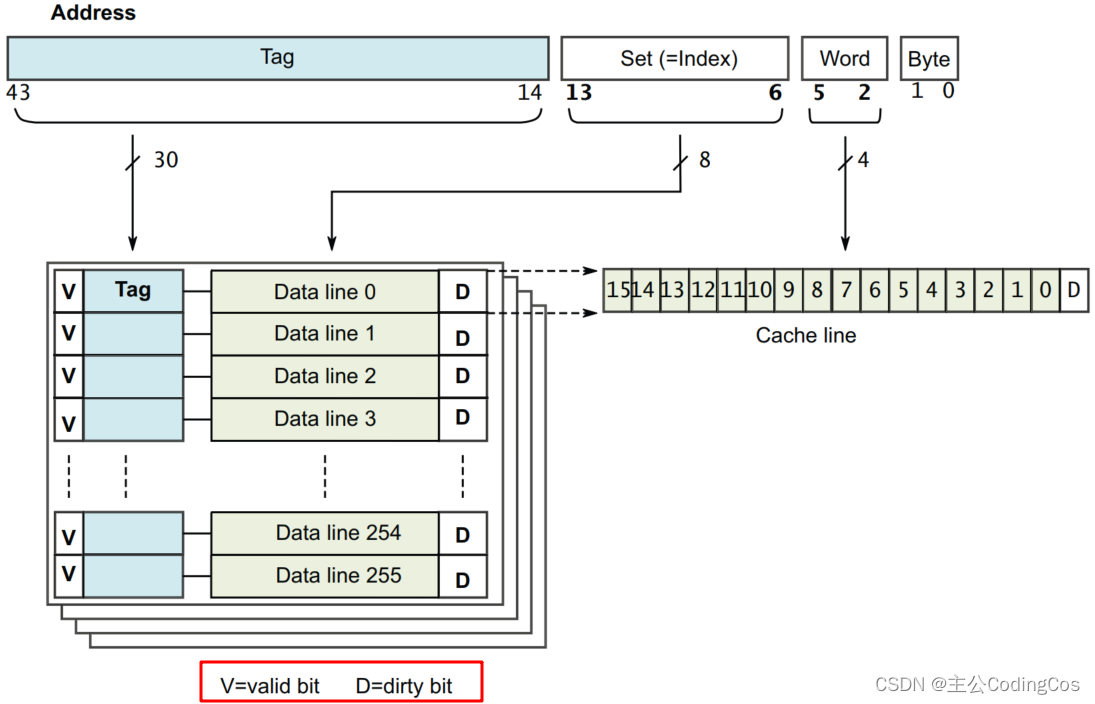
当CPU请求一个它想要获取的主存储器地址时,这个地址就被发送给cache,然后硬件就开始搜索cache来寻找相应的数据。为了搜索一个cache,来自 CPU 的地址经hash处理生成一个索引(index),这个index指向cache中的一个或者多个位置,比如 index=1 。 和许多hash算法一样,不同的地址可能产生相同的索引值 ,于是必须用这些位置上的tag和CPU所提供的地址进行比较。如果这个tag与来自CPU的地址相吻合,那么就称为一次cache hit,否则为cache miss。
Cache 与 MMU
很多时候cache都是和MMU一起使用的(即同时开启或同时关闭),因为MMU页表的entry的属性中控制着内存权限和cache缓存策略等
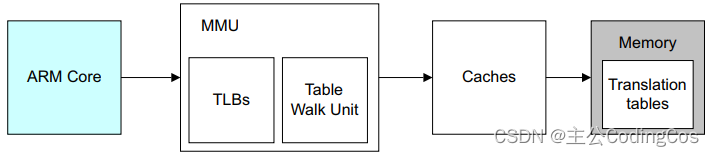
在ARM架构中,L1 cache都是 VIPT 的,也就是当有一个虚拟地址送进来,MMU在开始进行地址翻译的时候,Virtual Index就可以去L1 cache中查询了,MMU查询和L1 cache的index查询是同时进行的。如果L1 Miss了,则再去查询L2,L2还找不到则再去查询L3。 注意在arm架构中,仅仅L1是 VIPT ,L2和L3都是 PIPT 。
PIPT 与 VIPT 的区别
在 CPU 缓存架构中,VIPT 和 PIPT 是两种缓存寻址方式,主要区别在于使用虚拟地址还是物理地址来决定缓存索引和标记(tag):
✅ 1. VIPT (Virtually Indexed, Physically Tagged)
- Virtually Indexed:
缓存的 索引(index) 使用 虚拟地址的一部分。 - Physically Tagged:
缓存的 标记(tag) 使用 物理地址。 - 优点:
- 可以在 TLB 翻译完成前开始访问缓存(提高并行度)。
- 挑战:
- 如果缓存大小超过一个页大小(page size),可能出现 别名问题(aliasing),即不同虚拟地址映射到同一物理地址,导致缓存一致性问题。
- 常见应用:
- L1 数据缓存(D-Cache)常用 VIPT,因为它追求低延迟。
✅ 2. PIPT (Physically Indexed, Physically Tagged)
- Physically Indexed:
缓存的索引和标记都使用 物理地址。 - 优点:
- 没有别名问题,设计简单。
- 缺点:
- 必须等 TLB 翻译完成后才能访问缓存,增加访问延迟。
- 常见应用:
- L2/L3 缓存通常采用 PIPT,因为它们更大,延迟要求没那么苛刻。
✅ 为什么有 VIPT?
- 目的是 隐藏 TLB 延迟,在地址翻译和缓存访问并行进行,提高性能。
- 但为了避免别名问题,VIPT 缓存的 索引位数必须小于等于页偏移(page offset)位数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号