
ANR问题产生原理和分析思路总结
ANR问题是我们在开发中经常会遇到的问题。这种问题的发生往往是低概率并且难以复现,一旦发生就会给用户带来极差的体验。本文通过对ANR问题发生的原理、分析思路和案例的介绍,为分析ANR问题提供借鉴,帮助大家更好的理解和处理ANR问题。
ANR问题即使应用响应超时问题,它根据发生的原因不同,主要分为KeyDispatchTimeout、BroadcastTimeout、ContentProviderTimeout、ServiceTimeout四类。只要理解它们发生的原理以及典型分析方法,就可以快速着手进行分析。
目标
通过该案例帮助大家掌握以下内容:
1、ANR的概念
2、四种ANR问题产生的原理
3、ANR问题的分析思路
4、开发中如何避免产生ANR问题
概念与原理
1、ANR概念
ANR是Application not response的简写,即应用程序未响应。ANR问题是我们在进行应用开发时经常遇到的问题。当应用程序在UI线程阻塞太长时间,就会弹出系统弹框,询问我们继续等待还是关闭应用程序,此时发生了ANR。
1.1发生ANR原因
通常来说发生ANR原因主要有以下几点:
1、主线程频繁进行耗时IO操作,如读取数据、进行网络访问等;
2、多线程操作导致死锁,主线程被block;
3、进行binder通讯,binder连接数达到上线无法和对端通讯,或者对端处理超时,导致binder通讯超时;
4、系统服务WatchDog出现ANR
5、系统资源耗尽,如CPU、IO。
1.2ANR类型
ANR根据产生的原因不同,主要被分为四种:
KeyDispatchTimeout
用户输入事件在5秒内没有处理完,后面再一次发生输入事件时产生。
关键日志:“Input event dispatching timed out”。
BroadcastTimeout
广播事件处理超时产生的ANR问题。前台广播在10秒内没有处理完成或者后台广播在60秒内没有处理完成,则产生ANR。
关键日志:“Timeout of broadcast BroadcastRecord”。
ServiceTimeout
服务处理超时产生的ANR问题。前台服务在20秒内没有处理完成或者后台服务在200秒内没有处理完成则发生ANR。
关键日志:“Timeout executing sevice”。
ContentProviderTimeout
ContentProvider在10秒内没有处理完成发生ANR。
关键日志:“timeout publishing content providers”。
2、ANR触发机制
ANR是安卓系统监控应用程序响应是否及时的监控机制。从实现的角度,流程大概有三部:
a、应用进程进行某项操作时,AMS启动监控倒计时;
b、应用进程操作完成,停止到计时,此时安全;
c、倒计时完,说明操作未完成,超时,触发ANR弹框。
2.1 ServiceTimeout ANR
2.1.1 ANR发生原理
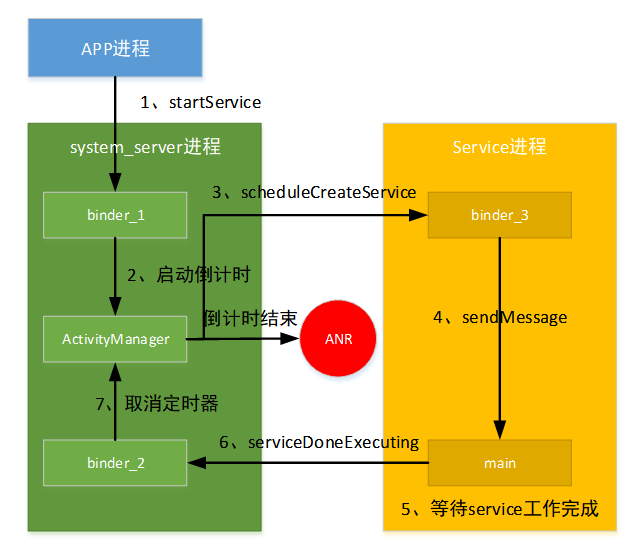
1)应用进程通过Binder向系统进程发起请求服务;
2)系统进程收到请求后,向AMS发送消息开启超时响应倒计时;
3)系统进程通过Binder通讯向目标服务进程发起请求;
4)服务进程收到消息后,转交给自己的业务程序;
5)服务进程进行事务处理,执行启动服务的声明周期;
6)服务启动完成,向系统进程发消息,告知处理完成;
7)系统进程向AMS发消息,取消超时响应倒计时;
从第2)步开始,到第7)步结束,这期间如果超过倒计时时间,则在倒计时结束时,AMS就会触发ANR弹框上来,就发生了ANR。
这个倒计时时间,就是上面说的前台服务20s,后台服务200s。
2.1.2 前台服务与后台服务
前台服务和后台服务发生ANR时间是不同的。分别是20秒和200秒。
在startService时,根据调用进程的所属的进程调度组决定被启动的服务是前台服务还是后台服务。。当放弃放进程不属于后台进程组ProcessList.SCHED_GROUP_BACKGROUND,则认为是前台服务,否则为后台服务。前后台服务被标记在ServiceRecord的createdFromFg成员变量中。
进程是否属于SCHED_GROUP_BACKGROUND主要是通过AMS的oom_adj进行判断的。AMS将进程调度组分为前台进程、可见进程、服务进程、后台进程和空进程。
oom_adj值小于0的都为系统进程,优先级是最高的;值为0的是前台进程;值在100~200属于可见进程;值大于200对用户来说基本是无感知的,属于后台进程。
2.2 BroadcastQueueTimeout ANR
2.2.1 ANR发生原理
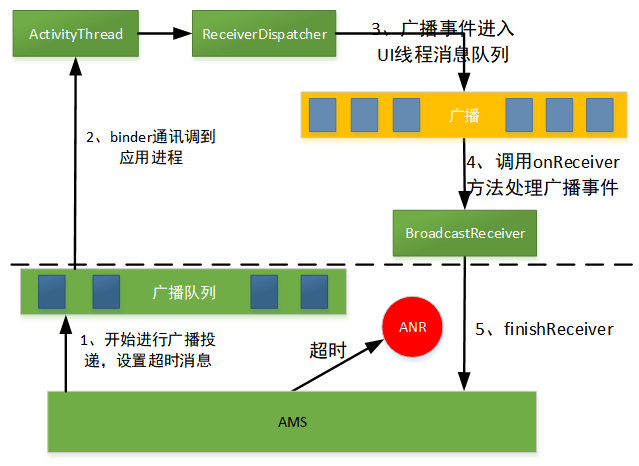
广播事件处理超时响应机制主要有这样几个过程:
0)应用或系统广播产生并发送给AMS;
1)AMS将广播投递到广播队列后,开始启动超时检测;
2)广播通过Binder通讯机制被投递到目标应用进程;
3)应用进程将广播加入到自己的消息队列等待处理;
4)应用进程从消息队列取到广播消息,并调用响应的接收器进行处理;
5)广播消息处理完成,通知AMS。
这个过程如果没有发生超时,AMS取消超时检测,否则在超时时间达到触发ANR弹框。
2.2.2 前台广播与后台广播
根据广播发送中的intent是否带有FLAG_RECEIVER_FOREGROUND标记将广播分为前台广播和后台广播。前台广播超时时间是10s,后台广播超时时间是60s。默认情况下是后台广播,是不带这个标志的。
另外,只有串行处理的广播才会发生ANR。并行广播系统是通过一个循环一次性发送给所有接受者,不存在超时检测。
2.3 ContentProviderTimeout ANR
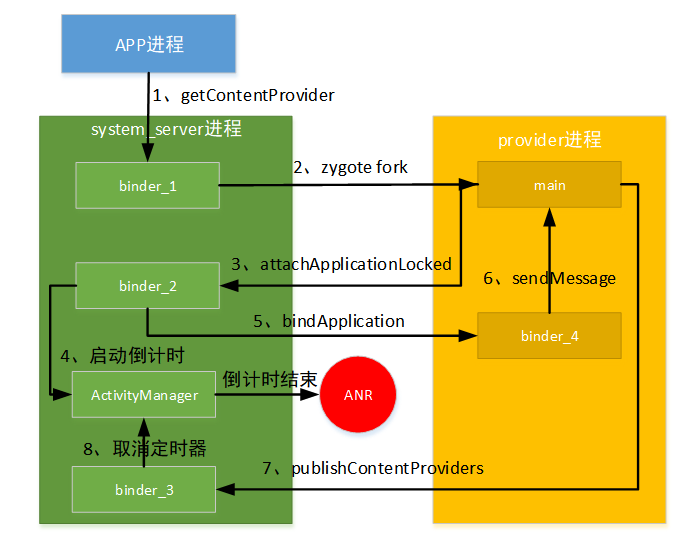
ContentProvider类型的ANR特别之处是在ContentProvider进程首次启动时才会检测。如果ContentProvider已经是启动后的状态,进行ContentProvider相关请求是不会触发ANR的。
-
应用进程向系统进程发起获取ContentProvider的请求;
-
此时ContentProvider没有启动,通过zygote创建Provider应用进程;
-
Provider通过AMS进行注册;
-
AMS启动超时检测机制;
-
AMS通过binder通知到Provider开始启动工作;
-
Provider进程进行启动相关工作;
-
Provider启动完成,通知到AMS;
-
AMS收到Provider启动完成,取消超时检测;
以上从4)到8)步骤中,发生超时,则触发弹出ANR问题。
2.4 InputDispatchingTimeout ANR
这种ANR跟上面介绍的三种有明显的不同。input超时机制不是到了定时时间就会触发,而是在处理后续输入事件时检查上一次是否超时,从而爆出ANR。
先来了解一下关于input的知识。intput有两个非常重要的线程。
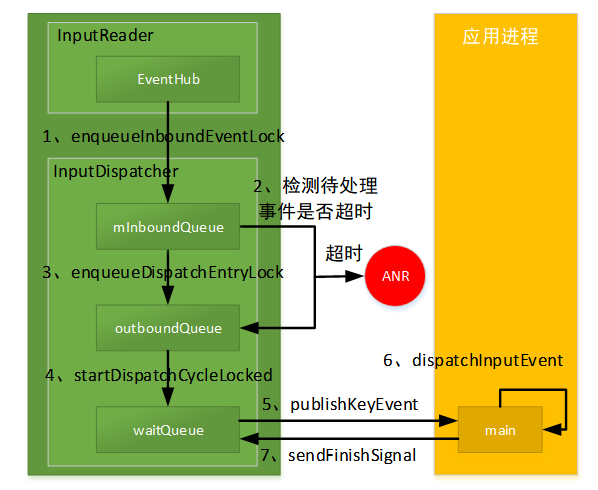
InputReader线程:负责通过EventHub(监听/dev/input)读取输入事件,当监听到输入事件则放入到InputDispatcher的mInBoundQueue队列中。
InputDispatcher线程:负责输入事件的分发,当它收到来自inputReader的事件时,则将该事件分发给目标窗口。该线程维护了三个存放事件的队列。分别是mInBoundQueue、outBoundQueue、waitQueue。
mInBoundQueue存放来自InputDispatcher的输入事件;
outBoundQueue 存放即将发给目标窗口的输入事件;
waitQueue 记录已发送给目标应用,但尚未处理完成的输入事件。
InputDispatchingTimeout ANR发生过程:
1)InputReader线程监听到输入事件,将其放入mInboundQueue;
2)InputDispatcher收到输入事件后被唤醒。先检查是否有在处理的输入事件。如果没有则取出mInboundQueue队头事件开始处理,重置ANR超时事件,检查窗口是否就绪。如果有正在处理的事件,如果outBoundQueue或waitQueue不为空,则开始检查是否存在输入事件处理超时。如果超时则弹出ANR。
3)应用窗口准备就绪,将事件转移到outBoundQueue队列;
4)应用端连接正常,则将事件从outBoundQueue放入waitQueue;
5)InputDispatcher通过socket通讯,将事件发传递给目标进程;
6)目标进程收到事件后,开始事件分发和消费;
7)目标进程事件处理完成,通知InputDispatcher,将事件从waitQueue移除。
3、ANR问题分析思路
遇到ANR问题,通常按如下的步骤进行排查:
1)、找到发生ANR的进程以及ANR类型等摘要信息,判断是什么大概什么类型的问题。
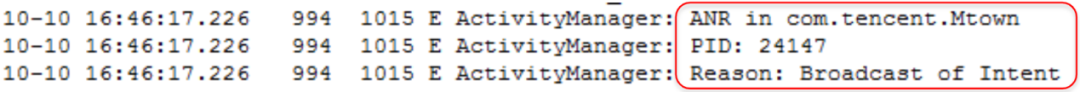
确定了ANR类型,查看系统日志,判断此次ANR经历的阶段。结合我们上面学到的ANR原理的知识。判断大概是哪个阶段出现问题。
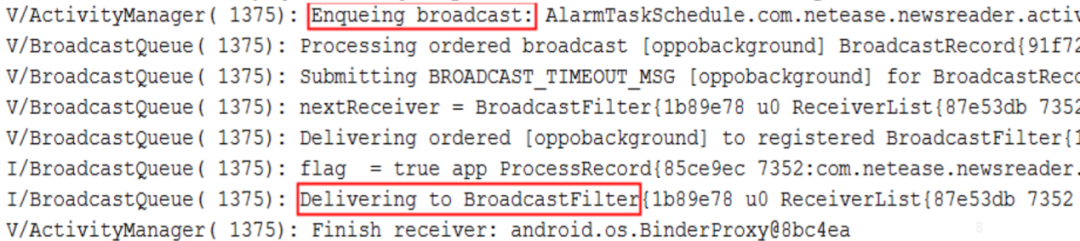
以广播类型ANR为例。通过搜索关键日志”Enqueing broadcast”(广播入队),“Delivering to BroadcastFilter”(广播派发)等,以及判断在这个阶段经历的时间,粗略判断是否正常。比如,广播入队时间长可能是系统的问题,系统繁忙时则会影响广播派发的效率。处理广播耗时较长,可能应用在接收端进行耗时处理。
其他类型ANR也是这样的思路分析。
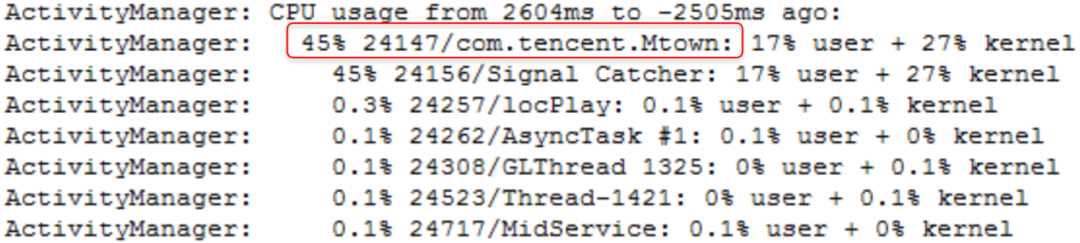
2)、查看当前系统负载情况,CPU、内存、IO这些。
如果当前应用的CPU占比较高,说明应用在进行耗时操作,大概率从应用本身找原因。如果系统CPU占比较高,这个时候可能系统处于繁忙状态。其他应用CPU占比高,就看占比高的应用当前在进行什么操作。
其他情况,IO、内存占比高也是类似的分析思路。
3)、查看调用堆栈以及分析代码。这是最重要的分析步骤,这里面可能遇到多种情况。常见的有主线程正在进行耗时操作,主线程在进行同步操作时被block在锁上等。
case1:主线程在进行耗时操作
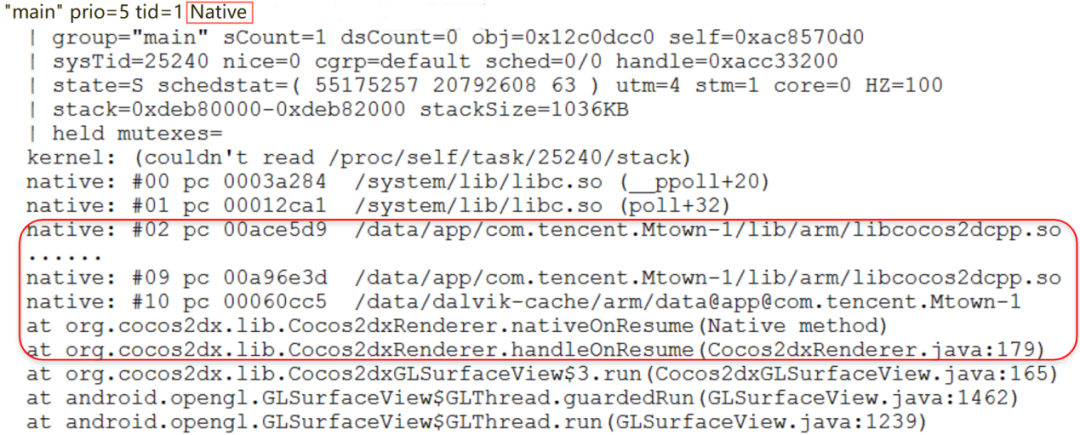
这种情况是比较直观的,在抓取的trace.txt文件中,搜索”main”线程,观察它此时的线程状态,以及调用栈信息。
线程状态主要的有RUNABLE(可执行状态)、WAITING/ BLOCKED(阻塞)、NATIVE(native方法执行中)、SUSPENDED(挂起中,GC或者debug时)比较常见。
以下面的trace为例,看到是“Native”状态,正在执行本地方法,此时是正在执行的状态,大概率此时主线程正在进行超时操作。继续查看他的调用栈信息,找到响应的代码,看此时正在执行什么操作,进一步定位和解决问题。
case2:主线程被block
这种也是非常常见的情形,以下面trace为例。此时是“Waiting”状态,说明主线程此时block状态。通过关键字locked找到此时在等待的锁是“0x2bbf9d9e”这个对象。然后在trace文件搜索这个锁当前被谁持有。再分析持有锁的线程此时在进行什么操作。进而定位和解决问题。
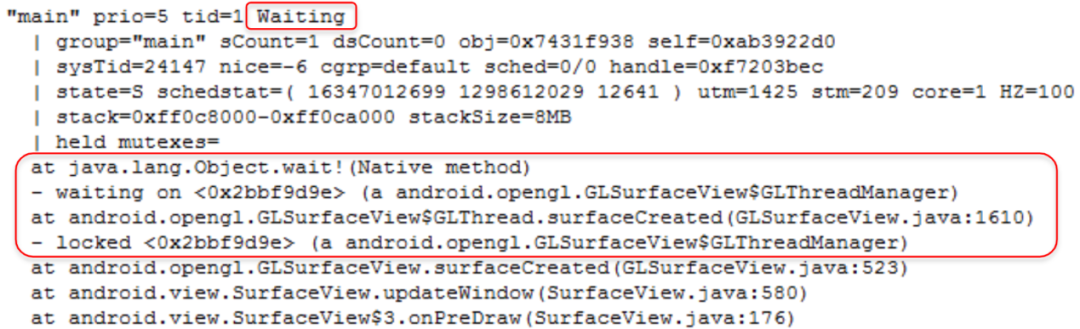
trace文件详细解读
阅读trace文件是分析ANR最主要的途径,下面对各字段的意义进行详细的解读。
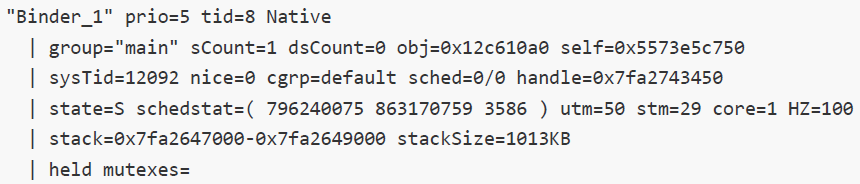
第1行:
线程名: “Binder_1”是一个binder线程。“main”标识的是主线程。其他线程,命名是“Thread-x”的格式,x是递增的id号;
prio: 线程优先级,默认是5;
tid:线程唯一标识ID;
线程状态:NATVIE表示正在执行本地方法;
第2行:
group: 线程组名称;
sCount: 线程被挂起的次数;
dsCount: debug时线程被调试器挂起的次数;
obj: 对象地址;
self: 线程native地址;
第3行:
sysTid: 线程号(主线程的线程号与进程号相同);
nice: 线程调度优先级;
sched: 线程调度策略及优先级;
cgrp: 调度归属组;
handle: 线程处理函数地址;
第4行:
state: 线程调度状态;
schedstat: CPU调度时间统计。括号里三个值分别是running、runable、switch的时间。(running是运行时间,单位ns;runable是排队等待时间,单位ns;switch是cpu调度切换次数);
utm: 线程在用户态执行时间片,单位jiffies,需要配合Hz字段计算时间;
stm: 线程在内核态执行时间片,单位jiffies,需要配合Hz字段计算时间;
core: 线程执行在哪个CPU核心。通常数字小为小核,数字大为大核;
Hz: 时钟频率,1秒内时间片的数量。100Hz,即每个时间片10ms;
第5行:
stack: 线程栈的地址区间;
stackSize: 栈的大小;
第6行:
mutex: 持有锁的类型。exclusive是独占锁,shared是共享锁;
关于线程状态,它的来源有java层和navite层两个,他们的对应关系和意义如下:
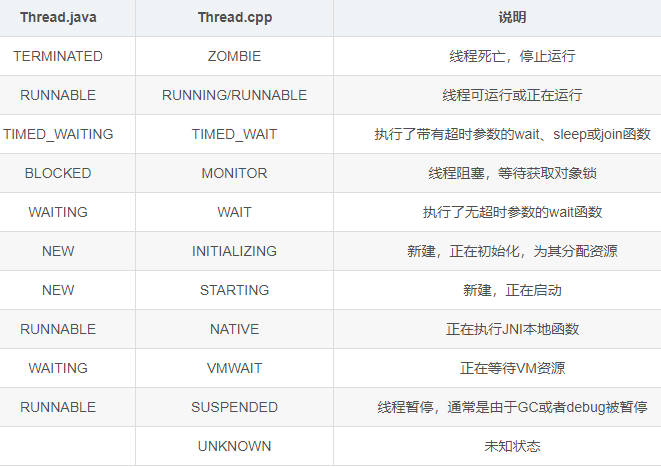
小结
结合ANR分析的案例场景,总结出ANR分析的大概流程:
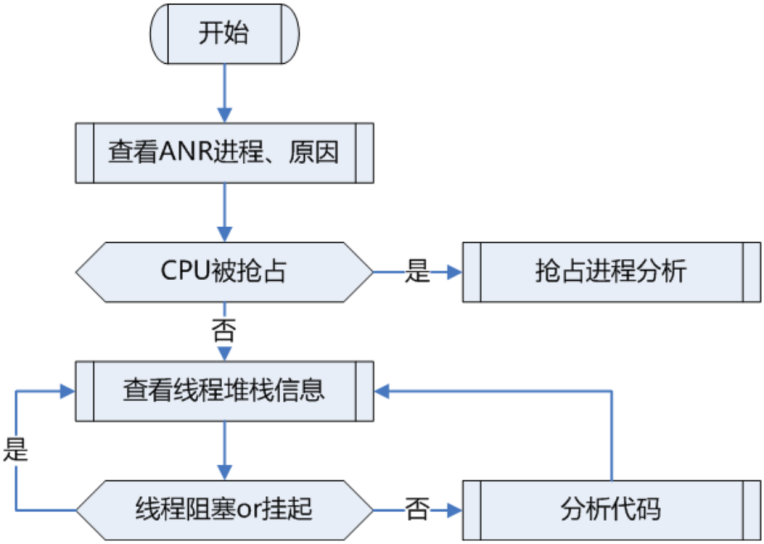
在工作中我们应该保持良好编程习惯,避免ANR问题的发生:
1)避免在主线程进行复杂耗时的操作,如读写文件、操作数据库、进行网络请求等;
2)广播接收器中不要进行复杂的逻辑处理,复杂操作可以开线程执行;
3)在service、activity声明周期中,避免复杂操作;
4)编码中注意循环操作的边界控制,避免出现无限循环;
5)设计编码中注意同步逻辑,避免出现同步死锁问题。
反思与启示
ANR总体上不是很难处理的问题,但是它的发生会极大的降低用户体验。我们理解它产生的原理,以及掌握相应的分析方法。不仅为了更好的解决ANR问题。更是为了提高我们的技能水平,在日常开发中,尽可能避免ANR问题的发生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号