
【ARM Cache 与 MMU 系列文章 5.1 -- Cache 缓存一致性协议】
1. cache的组织
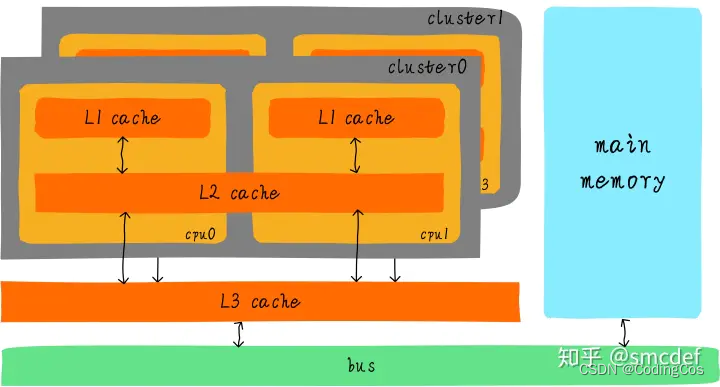
L1 cache 分为单独的 instruction cache(ICache)和 data cache(DCache)。
L1 cache是CPU私有的,每个CPU都有一个L1 cache。
一个cluster 内的所有CPU共享一个L2 cache,L2 cache不区分指令和数据,都可以缓存。
所有cluster之间共享L3 cache。L3 cache通过总线和主存相连。
2 多级cache之间的配合工作
当CPU试图从某地址load数据时,首先从L1 cache中查询是否命中,如果命中则把数据返回给CPU。
如果L1 cache缺失,则继续从L2 cache中查找,当L2 cache命中时,数据会返回给L1 cache以及CPU。
如果L2 cache也缺失,很不幸,我们需要从主存中load数据,将数据返回给L2 cache、L1 cache及CPU,这种多级cache的工作方式称之为 inclusive cache ,即某一地址的数据可能存在多级缓存中。与 inclusive cache 对应的是 exclusive cache ,这种cache保证某一地址的数据缓存只会存在于多级cache其中一级。也就是说,任意地址的数据不可能同时在L1和L2 cache中缓存。
3 多核心cache的一致性
在多核系统(简称MP,Multi-Processor),我们知道每个CPU都有一个私有的L1 Cache(不细分iCache和dCache)。
假设一个双核的系统,我们将会有 2 个 L1 Cache。 这就引入了一个问题,不同CPU之间的 L1 Cache 如何保证一致性呢 ?首先看下什么是多核Cache一致性问题。
假设 2 个CPU的系统,并且 L1 Cache 的 cache line 大小是 64 Bytes 。两个CPU都读取 0x00000040 地址数据,导致 0x00000040 开始的 64 B 字节内容分别加载到 CPU0 和 CPU1 的私有的 cache line。
CPU0执行写操作,写入值 0x01 ,CPU0私有的 L1 Cache 更新 cache line 的值,然后,CPU1读取 0x40 数据,CPU1发现命中cache,然后返回 0x00 值,并不是CPU0写入的 0x01 。这就造成了 CPU0 和 CPU1 私有L1 Cache数据不一致现象。
- 某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache,这个称为 写传播 ( Wreite Propagation );
- 某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的,这个称为 事务的串形化 ( Transaction Serialization )。
第一点写传播很容易就理解,当某个核心在 Cache 更新了数据,就需要同步到其他核心的 Cache 里。而对于第二点事务事的串形化,我们举个例子来理解它。
假设我们有一个含有 4 个核心的 CPU,这 4 个核心都操作共同的变量 i(初始值为 0 )。A 号核心先把 i 值变为 100,而此时同一时间,B 号核心先把 i 值变为 200,这里两个修改,都会「传播」到 C 和 D 号核心。
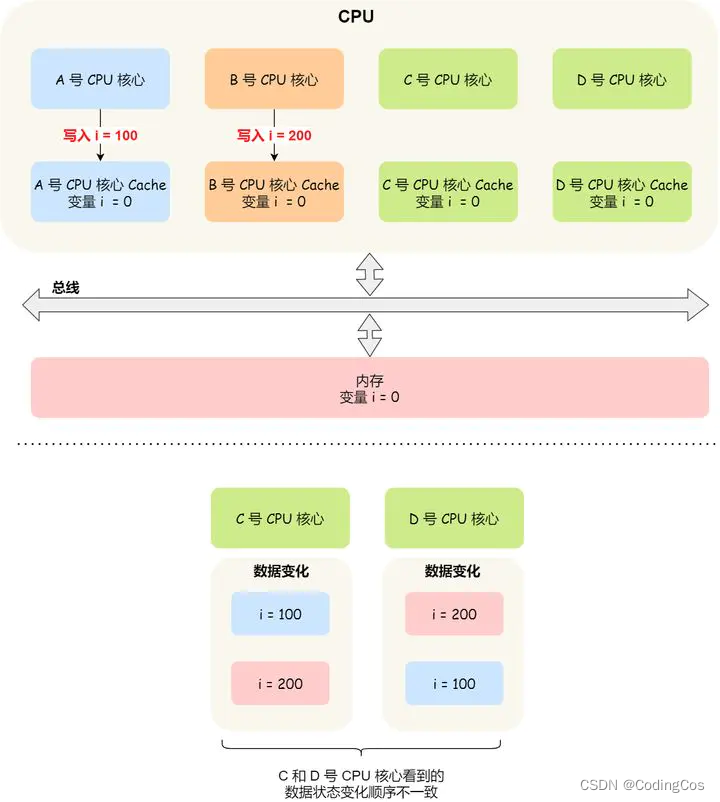
C 号核心先收到了 A 号核心更新数据的事件,再收到 B 号核心更新数据的事件,因此 C 号核心看到的变量 i 是先变成 100,后变成 200。
而如果 D 号核心收到的事件是反过来的,则 D 号核心看到的是变量 i 先变成 200,再变成 100,虽然是做到了写传播,但是各个 Cache 里面的数据还是不一致的。
所以,我们要保证 C 号核心和 D 号核心都能看到相同顺序的数据变化,比如变量 i 都是先变成 100,再变成 200,这样的过程就是事务的串形化。
要实现事务串形化,要做到 2 点 :
- CPU 核心对于 Cache 中数据的操作,需要同步给其他 CPU 核心;
- 要引入 锁 的概念,如果两个 CPU 核心里有相同数据的 Cache,那么对于这个 Cache 数据的更新,只有拿到了 锁 ,才能进行对应的数据更新。
现在,再让我们看看写传播和事务串形化具体是用什么技术实现的。
4 Lock 指令
在早期的CPU当中,是通过在总线上加 LOCK 锁的形式来解决缓存不一致的问题。因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加 LOCK 锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU 能使用这个变量的内存。在总线上发出了LCOK 锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从其内存读取变量,然后进行相应的操作。这样就解决了缓存不一致的问题。
但是由于在锁住总线期间,其他CPU无法访问内存,会导致效率低下。
关于LOCK 的内容请见:ARM AMBA AXI 入门 6 - AXI3 协议中的锁定访问之AxLOCK信号
1.1.5 Bus Snooping Protocol
写传播的原则就是当某个 CPU 核心更新了 Cache 中的数据,要把该事件广播通知到其他核心。最常见实现的方式是总线嗅探(Bus Snooping)。
我还是以前面的 i 变量 例子来说明总线嗅探的工作机制,当 A 号 CPU 核心修改了 L1 Cache 中 i 变量 的值,通过总线把这个事件广播通知给其他所有的核心,然后每个 CPU 核心都会监听总线上的广播事件,并检查是否有相同的数据在自己的 L1 Cache 里面,如果 B 号 CPU 核心的 L1 Cache 中有该数据,那么也需要把该数据更新到自己的 L1 Cache。
可以发现,总线嗅探方法很简单, CPU 需要每时每刻监听总线上的一切活动,但是不管别的核心的 Cache 是否缓存相同的数据,都需要发出一个广播事件,这无疑会加重总线的负载。
另外,总线嗅探只是保证了某个 CPU 核心的 Cache 更新数据这个事件能被其他 CPU 核心知道,但是并不能保证事务串形化。
于是,有一个协议基于总线嗅探机制实现了事务串形化,也用状态机机制降低了总线带宽压力,这个协议就是 MESI 协议,这个协议就做到了 CPU 缓存一致性。
5 MESI Protocol
MESI是现在一种使用广泛的协议,用来维护多核Cache一致性。可以将MESI看做是状态机,将每一个cache line标记状态,并且维护状态的切换。其大概思想就是:
一个Cache加载一个变量的时候,是Exclusive状态,当这个变量被第二个Cache加载,更改状态为Shared;这时候一个CPU要修改变量, 就把状态改为Modified,并且Invalidate其他的Cache,其他的Cache再去读这个变量,达到一致。
- MESI 协议中的 cache line 的四种状态
| 消息名称 | 定义 |
|---|---|
| Read | 如果CPU需要读取某个地址的数据 |
| Read Response | 可以由主存或者其他CPU发出,包含"Read"消息请求的主存地址的数据,当发出"Read"消息的CPU收到该消息后,将"Read Response"中的数据 放入自身的 cache line |
| Invalidate | 其中包含待失效的主存地址,其他CPU收到消息后将某地址对应的 cache line 移除,并将返回"Invalidate Acknowledge" |
| Invalidate Acknowledge | 在收到 Invalidate 消息后,必须移除对应的cache line,并返回"Invalidate Acknowledge" |
| Read Invalidate | Read + Invalidate消息的结合 |
| Writeback | 包含主存和待写回数据,该消息仅在cache line 为 modified 状态发出,该消息之后,对应的 cache line 如需要可以被移除,从而使其可以被用于存储别的主存块 |
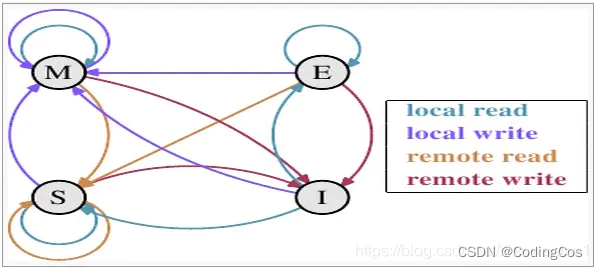
状态之间的相互转换关系可以使用下表来表示:
| M | E | S | I | |
|---|---|---|---|---|
| M | x | x | x | √ |
| E | x | x | x | √ |
| S | x | x | √ | √ |
| I | √ | √ | √ | √ |
继续上面的例子:
- 当 CPU0 读取
0x40数据,数据被缓存到 CPU0 私有Cache ,此时 CPU1 没有缓存0x40数据,所以我们标记 cache line 状态为 Exclusive 。
Exclusive 代表 cache line 对应的数据仅在数据只在一个CPU的私有Cache中缓存,并且其在缓存中的内容与主存的内容一致。 - 然后 CPU1 读取
0x40数据,发送消息给其他CPU,发现数据被缓存到CPU0私有Cache,数据从CPU0 Cache返回给CPU1。此时CPU0和CPU1同时缓存0x40数据,此时cache line状态从 Exclusive 切换到 Shared 状态。
Shared代表 cache line 对应的数据在 “多” 个CPU私有Cache中被缓存,并且其在缓存中的内容与主存的内容一致。 - 继续 CPU0 修改
0x40地址数据,发现0x40内容所在cache line状态是Shared。CPU0发出 invalid 消息传递到其他CPU,这里是CPU1。CPU1接收到invalid消息。将0x40所在的cache line置为Invalid状态。
Invalid状态 表示表明当前cache line无效。 - 然后
CPU0收到CPU1已经 invalid 的消息,修改0x40所在的cache line中数据。并更新 cache line 状态为 Modified 。
Modified表明 cache line 对应的数据仅在一个CPU私有Cache中被缓存,并且其在缓存中的内容与主存的内容不一致,代表数据被修改。 - 如果
CPU0继续修改0x40数据,此时发现其对应的cache line的状态是 Modified 。因此CPU0不需要向其他CPU发送消息,直接更新数据即可。 - 如果
0x40所在的cache line需要替换,发现cache line状态是Modified。所以数据应该先写回主存。
Cache 之间数据和状态同步沟通,是通过发送message 来完成的。MESI主要涉及一下几种message。
- Read: 如果CPU需要读取某个地址的数据。
- Read Response: 答复一个Read消息,并且返回需要读取的数据。
- Invalidate: 请求其他CPU将某地址对应的 cache line 移除。
- Invalidate Acknowledge: 回复 invalidate 消息,表明对应的 cache line已经被移除。
- Read Invalidate: Read + Invalidate消息的组合。
- Writeback: 该消息包含要回写到内存的地址和数据。
继续以上的例子,我们有5个步骤。现在加上这些message,看看消息是怎么传递的。
- CPU0 发出 Read 消息。主存返回 Read Response 消息,消息包含地址
0x40的数据。 - CPU1 发出 Read 消息,CPU0返回 Read Response 消息,消息包含地址
0x40数据。 - CPU0 发出 Invalidate 消息,CPU1接到消息后,返回Invalidate Acknowledge 消息。
- 不需要发送任何消息。
- 发送Writeback消息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号