
【ARM Cache 与 MMU 系列文章 4 – Cache 与 CPU 乱序执行】
1.1 Cache 之乱序执行
程序里面的每行代码的执行顺序,有可能会被编译器和cpu根据某种策略,给打乱掉,目的是为了性能的提升,让指令的执行能够尽可能的并行起来。
知道指令的乱序策略很重要,原因是这样我们就能够通过barrier(内存屏障)等指令,在正确的位置告诉cpu或者是编译器,这里我可以接受乱序,那里我不能接受乱序等等。从而,能够在保证代码正确性的前提下,最大限度地发挥机器的性能。
1.1.1 CPU Pipline
在 cpu 中为了能够让指令的执行尽可能地并行起来,从而发明了流水线技术。但是如果两条指令的前后存在依赖关系,比如数据依赖,控制依赖等,此时后一条语句就必需等到前一条指令完成后,才能开始。
cpu为了提高流水线的运行效率,会做出比如:
- 对无依赖的前后指令做适当的乱序和调度;
- 对控制依赖的指令做分支预测;
- 对读取内存等的耗时操作,做提前预读。
以上内容都可能会导致指令乱序执行。
1.1.2 Cache Store Buffer 引入背景
假设CPU有两个核心,CPU0和CPU1, 此时CPU0想写新数据到自己的缓存,下面的做法的目的是为了缓存一致性:
- 首先CPU0先完成新数据的创建;
- CPU0向全体其他核心发送无效化指令,告诉其他核心其所对应的缓存区中的这条数据已经过期无效。本图例中只有一个其他核心,为CPU1;
- 其他核心收到广播消息后,将自己对应缓存的数据的标志位记为无效,然后给CPU0回确认消息;
- 收到所有其他cpu的确认消息后,CPU0才能将新数据写回到它所对应的缓存结构中去。
根据上面的信息,可以发现,影响时间瓶颈主要有两块:
- 无效化指令 :CPU0需要通知所有的核心,该变量对应的缓存在其他核心中是无效的。在通知完之前,该核心不能做任何关于这个变量的操作。
- 确认响应 :CPU0需要收到其他核心的确认响应。在收到确认消息之前,该核心不能做任何关于这个变量的操作,需要持续等待其他核心的响应,直到所有核心响应完成,将其对应的缓存行标志位设为 Invalid,才能继续其它操作。
针对无效化指令的加速:在缓存的基础上,引入 Store Buffer 结构 。
1.1.3 Cache Store Buffer
Store Buffer 是一个特殊的硬件存储结构, 核心可以先将变量写入Store Buffer,然后再处理其他事情。如果后面的操作需要用到这个变量,就可以从Store Buffer中读取变量的值,核心读数据的顺序变成:
Store Buffer → 缓存 → 内存
这样在任何时候核心都不用卡住,做不了关于这个变量的操作了。
到这里为止只是解决了 1.1.2 节提到的 无效化指令 的问题,对于 确认响应时间 的问题还是存在的。为了解决确认响应时间的问题,又引入了 Invalidata Queue 的结构。
1.1.4 Invalidata Queue
针对确认响应时间的问题,硬件工程师又在缓存的基础上,引入Invalidate Queue 这个结构。当其他核心收到CPU0的Invalidate 的命令后,立即给CPU0回Acknowledge,并把Invalidate这个操作,先记录到Invalidate Queue里,当其他操作结束时,再从Invalidate Queue中取命令,进行Invalidate操作。 所以当CPU0收到确认响应时,其他核心对应的缓存行可能还没完全置为Invalid状态 。
1.1.5 Store Buffer 引入乱序执行
从下图 1-1 可以看到 store buffer 存在于 cpu 核与cache之间,对于x86架构来说,store buffer是 FIFO,因此不会存在乱序,写入顺序就是刷入cache的顺序。
但是对于 ARM架构 来说,store buffer并未保证FIFO,因此核心先写入store buffer的数据,是有可能比后写入store buffer的数据晚刷入cache的。从这点上来说,store buffer的存在会让ARM架构出现乱序的可能。store barrier存在的意义就是将 store buffer 中的数据刷入cache。
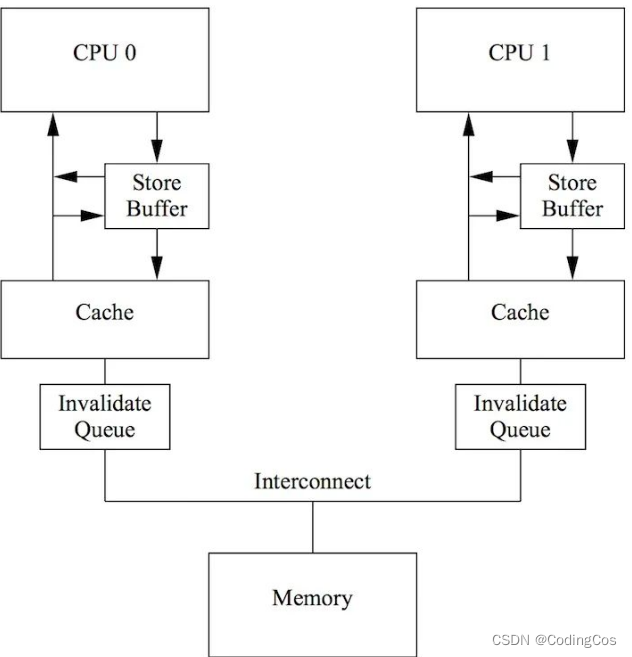
1.1.6 Invalid queue 引入乱序执行
invalid queue 用于缓存 cache line 的 invalidate(失效)消息, 如上图所示,当cpu0写数据进入store buffer,并从store buffer将修改刷入cache,此时cpu1读取到数据仍是可能是错误的。因为使 cache line失效的消息被缓冲在了invalid queue中,还未被应用到cache line上。这也可能会导致指令乱序的可能。针对1.1.5 和 1.1.6 节锁存在的问题, 软件工程 师需要用到内存屏障更正。
1.1.7 内存屏障
针对 Store Buffer:核心在后续变量的新值写入之前,把Store Buffer的所有值刷新到缓存;核心要么就等待刷新完成后写入,要么就把后续的后续变量的新值放到Store Buffer中,直到Store Buffer的数据按顺序刷入缓存。这种也称为内存屏障中的写屏障(Store Barrier)。
针对 Invalidate Queue:执行后需等待Invalidate Queue完全应用到缓存后,后续的读操作才能继续执行,保证执行前后的读操作对其他CPU而言是顺序执行的。这种也称为内存屏障中的读屏障(Load Barrier)。
1.1.8 C 语言中的volatile关键字作用
易变性 :volatile告诉编译器,某个变量是易变的,当编译器遇到这个变量的时候,只能从变量的内存地址中读取这个变量,不可以从缓存、寄存器、或者其它任何地方读取。
顺序性 :两个包含volatile变量的指令,编译后不可以乱序。注意是编译后不乱序,但是在执行的过程中还是可能会乱序的,这点需要由其它机制来保证,例如memory- barriers。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号