
【ARM Cache 与 MMU 系列文章 1.5 -- ARM Cache 直接映射 详细介绍】
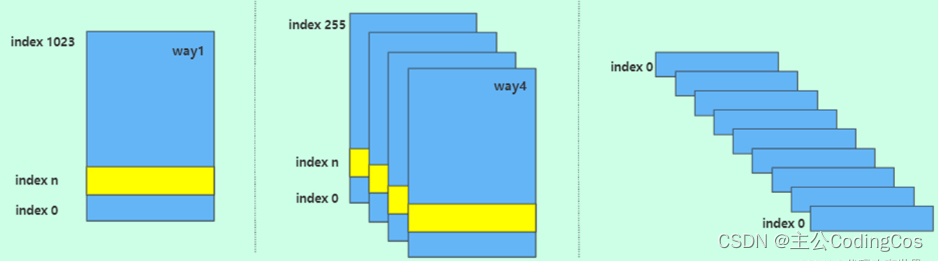
ARM Cache组织形式
在ARM体系结构中,缓存(Cache)是一种关键的硬件机制,用于减少处理器访问内存所需的时间。缓存可以根据其组织结构分为三种主要类型:全相连(Fully Associative),直接映射(Direct Mapped),和多路组相连(Set Associative)。每种类型在访问速度、硬件复杂度和成本之间提供了不同的折衷方案。
直接映射(Direct Mapped)
介绍: 在直接映射缓存中,每个内存地址通过某种映射函数(通常是地址的一部分)映射到一个特定的缓存行。这种结构简单,硬件实现成本较低,但可能会导致较高的缓存冲突(两个内存地址映射到同一缓存行),从而降低缓存效率。
在介绍直接映射之前,以停车场停车作为例子,先把结构的特点简单地概括出来,便于读者了解。
- 停车场 - cache
- 停车 - linefill
- 取车 - read cache line
直接映射示例
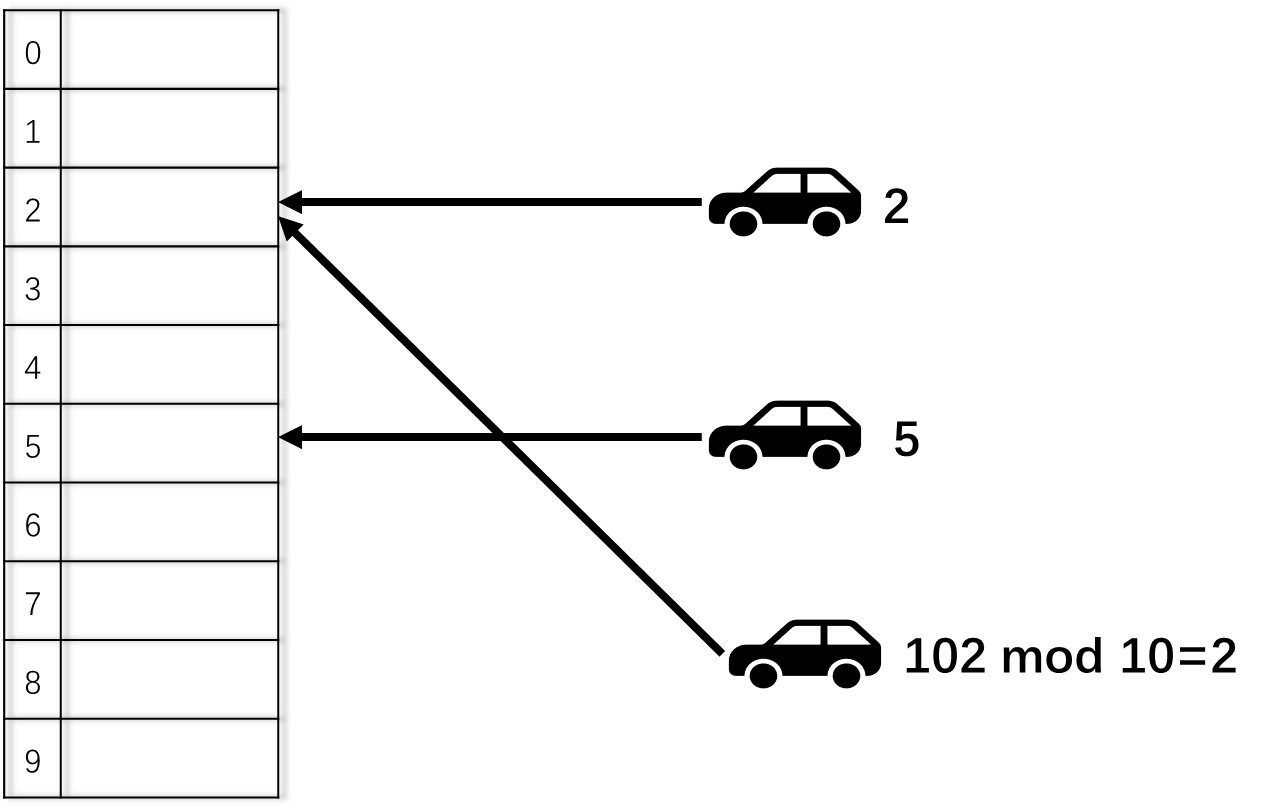
假如所有人的车都被赋予了一个独一无二的车牌号A(A=0,1,2,…,100,101,…),现在有一个共N=10个车位的停车场,每个车位号从0开始依次递增。现在规定车牌号为A的车子只能停在 停车位 n = A % N = A%10 的位置。如下图所示,车牌号为2的车子停在2号车位,车牌号为5的车子停在5号车位。
按照这种规则,如果又来了一辆车牌号为102的车子,即使其他车位上还有空位,102号车子也只能停2号车位,如果2号车位已经有2号车占了,按照直接映射的规则,102车(newer)会把2号车(older)给驱逐(evict)出去。
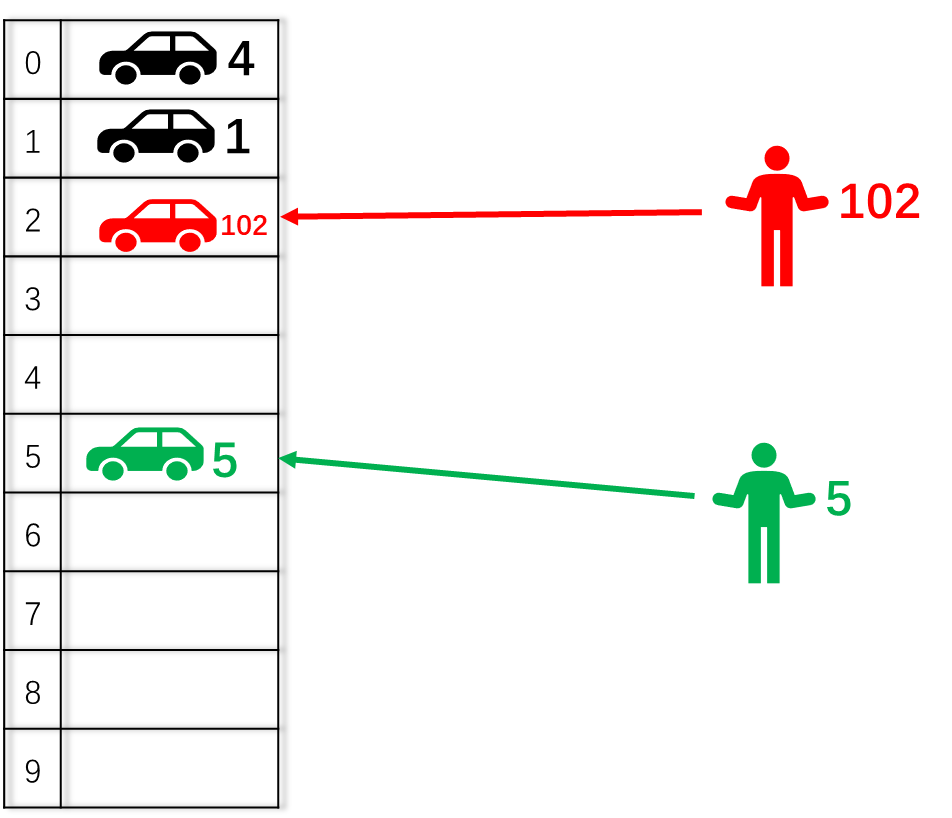
如上图1-1 描述了按照直接映射规则停车的过程,下图则是车主取车的过程(也就是从cache 中读取数据)。
假设我是102号车主,通过简单计算停车位 n =102%10 =2 ,很容易知道我的车子停在2号车位。
直接映射规则下的停车场,每个车位都与车牌号直接对应,即使停车场还有大量空位,2号车和102号车也只能停2号车位。并按照后来者居上的原则,102号车会把2号车给驱逐出去,如果又来一辆52号车,102号车也会被52号车挤出去。所以驱逐现象( eviction )会频繁发生。
直接映射其优势 在于车主很容易就知道自己的车子停在哪个车位, 不用进行 look-up 来确认是否 miss还是hit。
直接映射原理
在众多的 cache 实现方式中,直接映射方式是最简单的。主存中的每个地址都能在 cache 中找到对应的 cache line,不过主存空间是远远大于cache的存储空间的,所以它必须按照上述直接映射停车场的规则: n= A % N ,将所有满足 n= A % N 的地址A放入cache下边为n的 cache line。
如下图所示的 cahce,N=4,一个 cache line 大小为 4 个word,主存地址为 0x0 、 0x40 、 0x80 、…、的数据都将放在该cache的第 0 个cache line,以此类推。
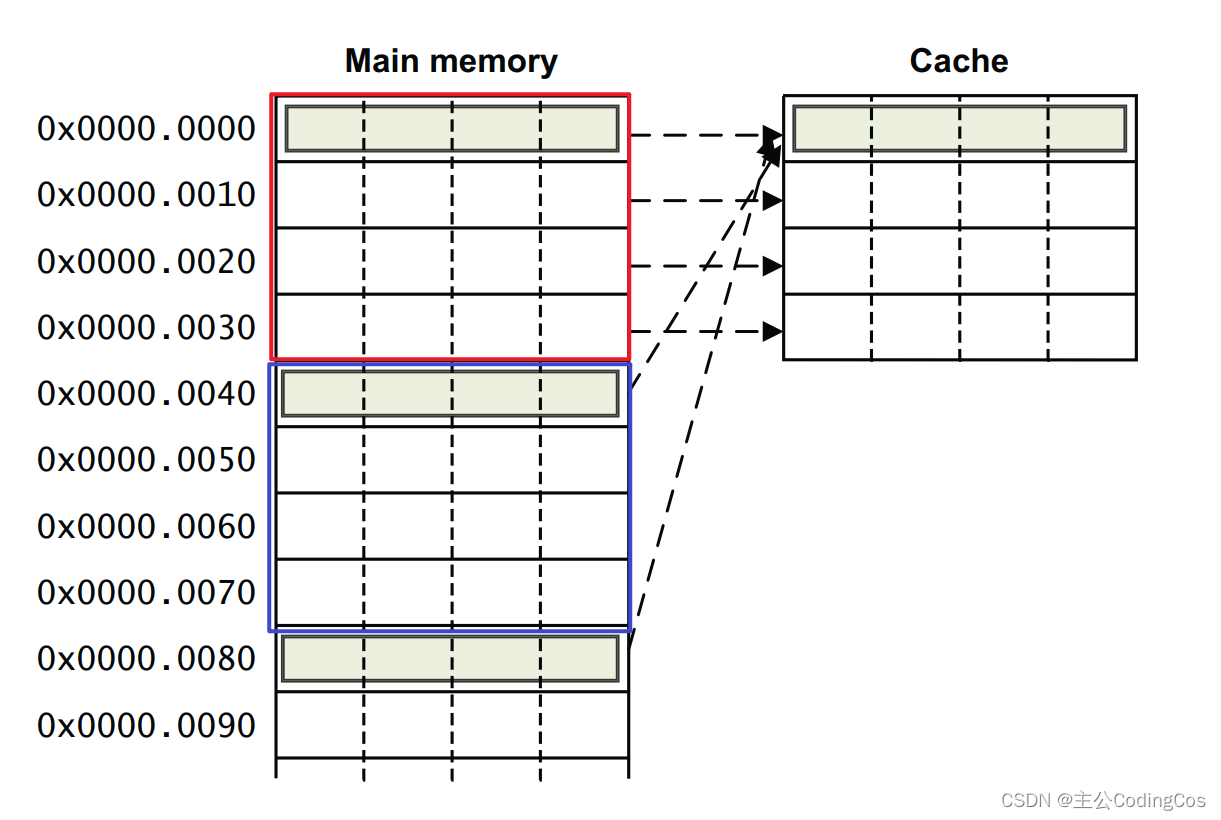
我们可以推算出一个主存的地址如何被划分成 cache 地址,如下图1-4 所示,
- 由于该cache只有
4个cache line,所以只需2个bit即可描述 cache line 的 index(0b00 \ 0b01 \ 0b10 \ 0b11),这里我们使用地址的bits [5:4]。 - 一个cache line有
4个 word,也只需 2 个 bit 即可描述每个word的具体位置(0b00 \ 0b01 \ 0b10 \ 0b11),这里我们使用地址的[3:2]。 - 地址的
bits [31:6]我们用作Tag 信息,即告诉cache controler该地址来自主存的何处,用于判断 hit or miss 。

当CPU读写一个地址时,cache controler会将该地址按照上图结构划分,并且进行如下操作:
- 首先抽取该地址的 index 位,直接去找 cache 中对应 index 的 cache line。
- 然后抽取该地址的 tag 信息,如果与当前 cache line里的tag一致,并且 该 cache line 的 valid bit 为
1(该cache line里的数据有效),即说明发生了 hit。如果 valid bit 为1,但是tag信息不一致,说明当前cache line保存的数据是其他地址的,接着需要将当前cache line里的数据 驱逐 到下一级内存中,并将新的地址上的数据填充进来。 - 如果是hit,接着把该地址的 Line 偏移量,可能还有 bytes 偏移量取出,在对应的cache line中提取数据。
所以内存中所有地址的bits [5:4] 相同的地址,都会映射到同一个位置的cache line 。但是在某个时刻,同一个cache line只能存放其中一个地址的数据,就像车位上某个时刻只能停一辆车一样。
Cache颠簸(cache thrashing)原因
直接映射的一大副作用就是cache颠簸(cache thrashing),下面笔者用一个示例来解释这种现象。有如下函数:
void add_array(int *data1, int *data2, int *result, int size)
{
int i;
for (i=0 ; i<size ; i++) {
result[i] = data1[i] + data2[i];
}
功能很简单,传入三个int类型指针: int *data1 , int *data2 , int *result ,并在有限的 size 个循环内求和: result[i] = data1[i] + data2[i] 。
假如传入如下地址参数:
add_array(0x40, 0x80, 0x00, 16);
在一个直接映射cache实现下会发生什么呢?
完成求和运算 result[i] = data1[i] + data2[i] ,会经过如下步骤:
- 假设当前
i=0, 首先会读取data1[0],也就是 0x40上的数据,先发生 read miss,然后linefill,将0x40到0x4F一个cache line大小的数据填充到 cache的第 0 行:

- 首先会读取
data2[0],也就是0x80上的数据,地址0x80按照规则,其数据也将放在第 0 个cache line。先发生 read miss ,由于第0行已经存放了0x40的有效数据,所以会先进行 evict ,然后再把0x80上的数据替换进来:

- 最后进行求和操作
data1[0] + data2[0],并将结果保存在result[0],也就是地址0x00,0x00其数据也将放在第0个cache line。先发生 write miss ,由于第 0 行已经存放了0x80的有效数据,所以还会先进行 evict ,然后再把求和结果0x00上的数据写进cache line。

我们可以发现,仅仅是在一个求和 result[i] = data1[i] + data2[i] 循环中,就发生了 2 次 eviction。cache里同一个cache line里的数据经常被写入写出(linefill and evict),这就是cache thrashing。这样的现象会严重影响系统的性能,因此在ARM系列处理器中,直接映射类型的主缓存基本上没有,但是可以在一些,比 如ARM1136 处理器的分支目标地址缓存中看到直接映射缓存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号