
【ARM CoreLink 系列 3 -- CCI-550 控制器介绍 】
CCI Family

CCI-550 简介
Arm CoreLink CCI-550 Cache Coherent Interconnect 扩展了 CoreLink CCI-500。它在 big.LITTLE 处理器集群之间提供完整的缓存一致性,并为其他代理(如 Mali GPU、网络接口或加速器)提供 I/O 一致性。
CoreLink CCI-550 提供可扩展和可配置的互连,使 SoC 设计人员能够以尽可能小的面积和功耗满足性能目标,并且还增加了可降低整体系统延迟的监听滤波器。
与 CoreLink CCI-400 相比,CoreLink CCI-500 提供高达两倍的峰值系统带宽,30% 处理器内存性能提升、更低的系统功耗,以及高度缩放和配置能力,能够满足各式应用的需求。
CCI-550 功能
CCI-550 主要功能:
- ACE masters 之间的数据一致性;
- QoS 服务,用于配置transaction优先级;
- 输入和输出(I/O) 与 ACE-Lite master的一致性;
- master 和s laver之间的交叉开关互连功能;
- 性能监控单元(PMU),用于对与性能相关的事件进行计数;
- 用于MMU 之间通信的主设备之间的DVM 消息传输;
- 侦听过滤器(核心功能) ,可降低侦听功率并提高侦听未命中的性能;
- 支持 Arm TrustZone 技术以提供安全、非安全和受保护状态。
缓存一致性和共享数据问题
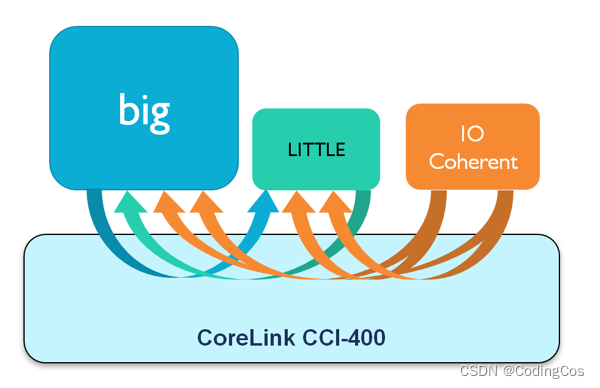
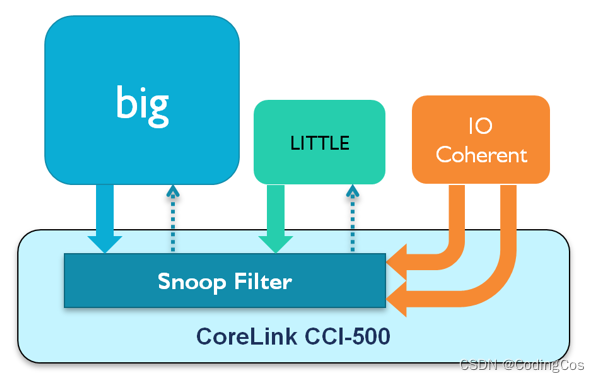
例如,上图中的箭头表示 big 和 LITTLE 处理器群集之间的监听,以及从 IO 接口到两个处理器群集的监听。 这些监听是访问任何共享数据必需的,以此确保其缓存为硬件一致性缓存。 换而言之,确保所有处理器和 IO 看到同一个一致内存视图。
对于大多数工作负载而言,作为监听请求结果而执行的大部分查询将不命中,也就是它们无法在缓存中找到所请求数据的副本。 这意味着许多由监听引发的查询可能造成对带宽和能源的不必要使用。 当然,我们已经剔除了软件缓存维护的更高成本, 但或许我们可以进一步优化 ?
监听过滤器介绍
此时监听过滤器登上舞台。通过将监听过滤器集成到互联之中,我们可以维护一个处理器缓存内容目录,免除广播监听的必要。
监听过滤器的原理如下:
- 所有已缓存的共享内存的标记存储在互联内的一个目录中(监听过滤器)
- 所有共享访问将查询这一监听过滤器,可能的回复有两种:
- 命中 –> 数据在片上,提供一个指向具有该数据的群集的矢量
- 未命中 –> 转而从外部内存获取
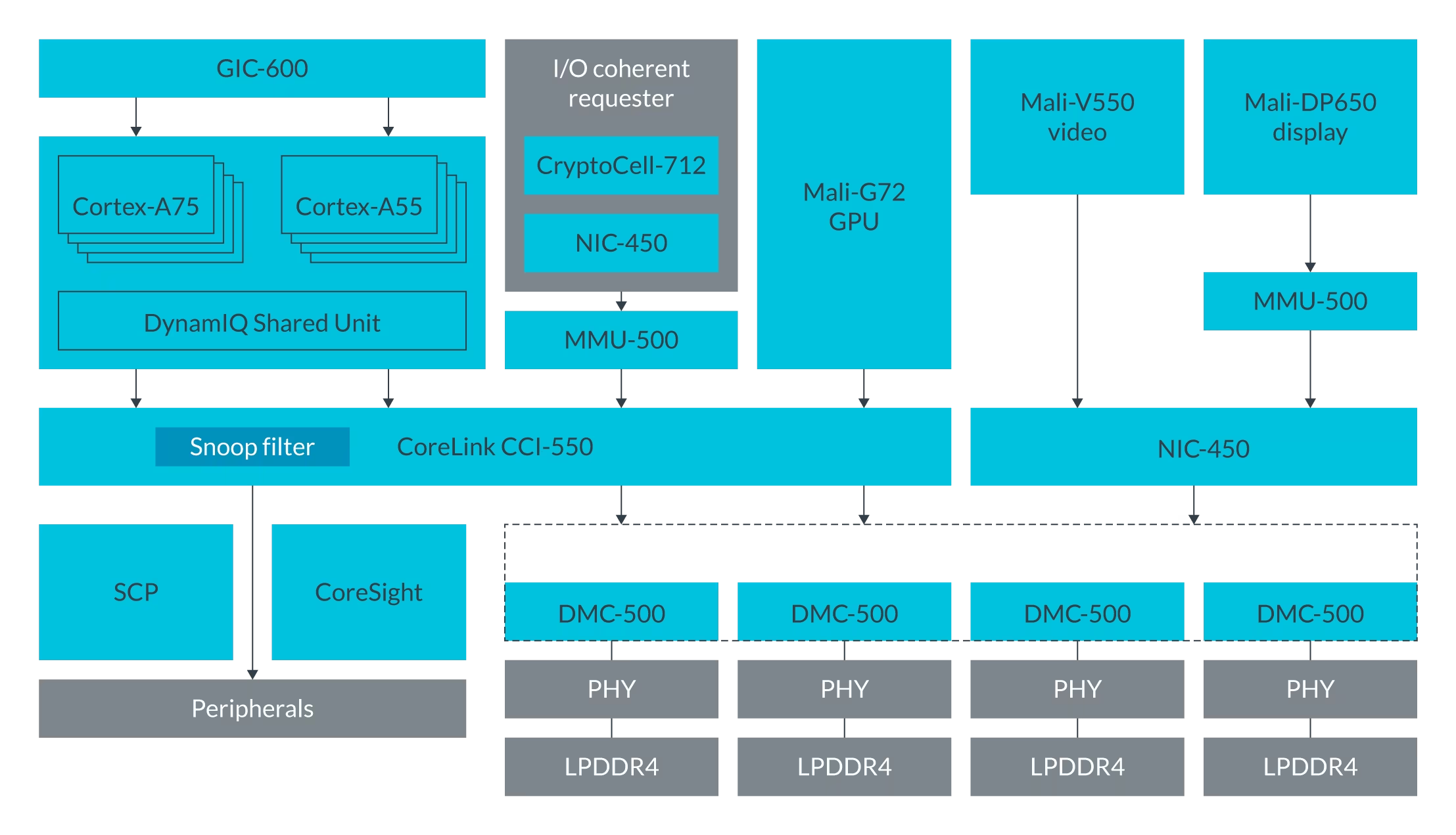
CCI-550 Interfaces
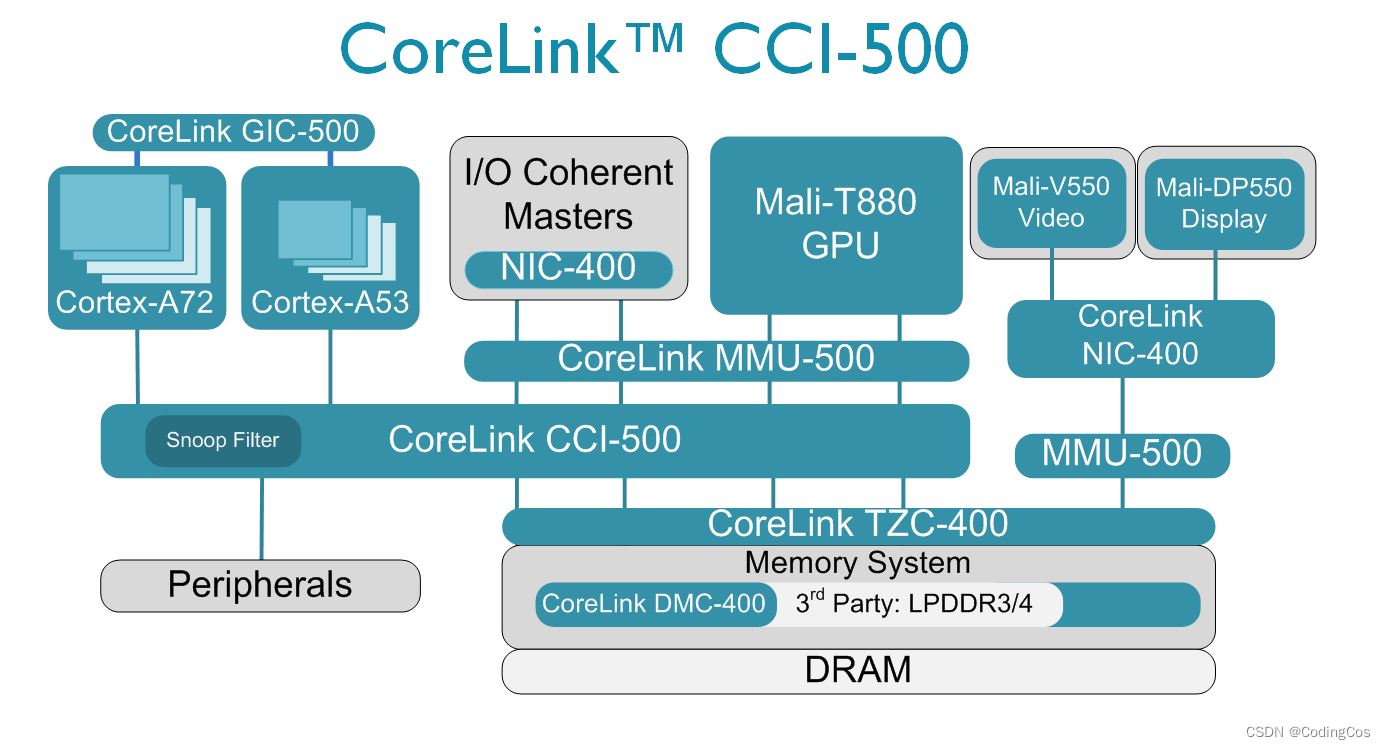
CCI-550 是高度可配的,你可以在系统中配置多个master 和 slave, 下图是一个基于CCI-550配置的系统框图:
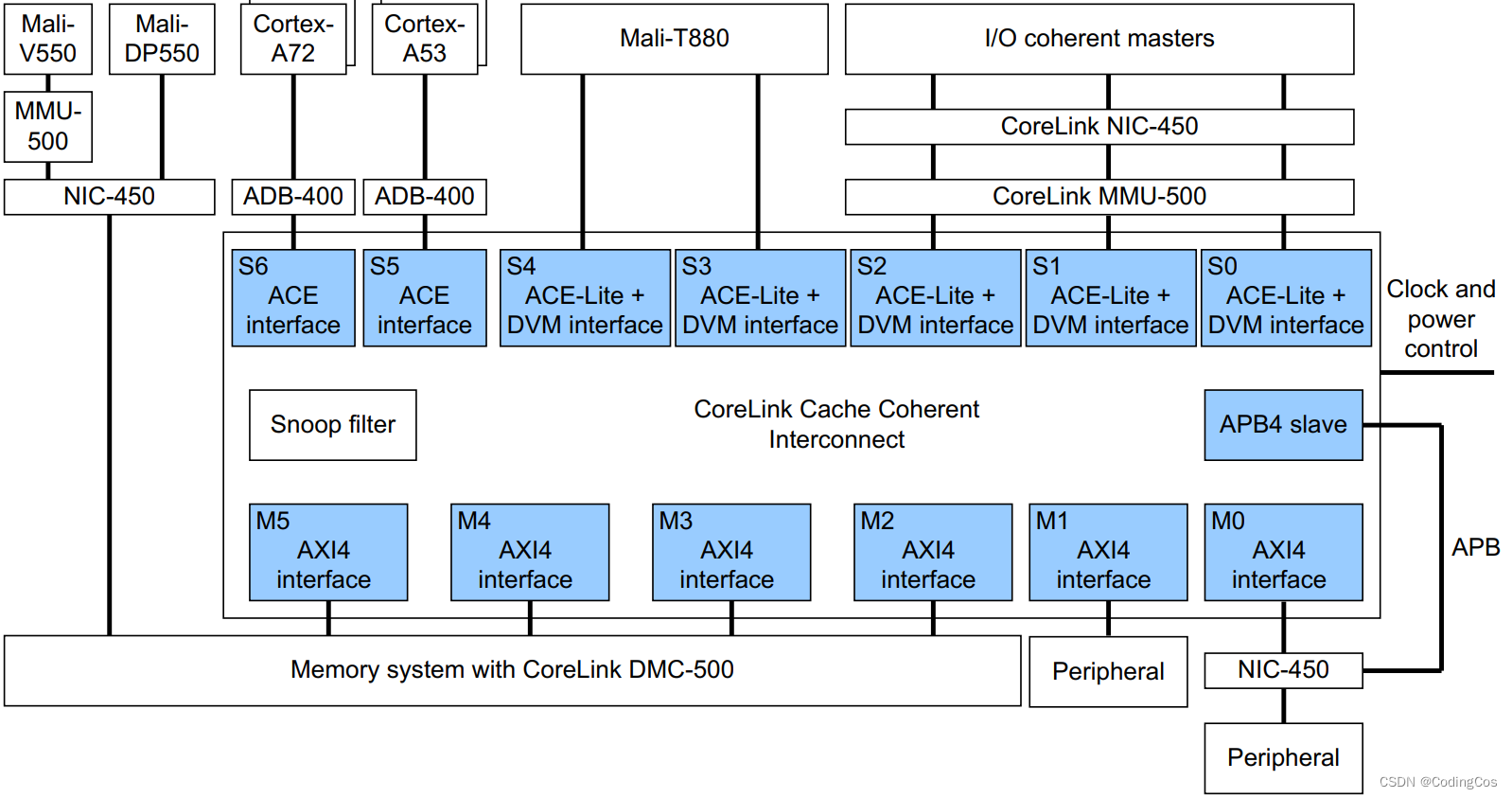
上图中可以看到 支持ACE 协议的 S5 和 S6 接口连接了 Cortex-A53 和 Cortex-A72 ,CCI-550 可以管理 L1 Cache 和 L2 Cache之间数据共享和数据同步。
在CCI-550 中可以使用ADB-400(AMBA Domain Bridge)集成多个 power domain 和 clock domian;
- S0-S4 连接了支持 ACE-Lite 的 Mali-T860 GPU 或者 Mali-T880 GPU,或者支持 ACE-Lite + DVM 的 MMU;
- CCI-500 提供了 APB Salve 接口,可以通过 APB 接口来对CCI-550 进行配置;
- M5-M2 连接了 Memory controller,从而可以支持LPDDR4 和 LPDDR3;
- 对于 CCI-500 clock 和 power的控制可以通过 Q-channel 和 P-channel。
Snoop filter 再介绍
CPU从内存中读取数据到 cache line 的操作被称为 “load” ,而将cache line中的数据写回到内存对应位置的操作则被称为 “store” 。在 硬件设计 中,cache属于CPU的一部分,而CPU和内存之间是通过bus(总线)相连的,因此不管是"load"还是"store"操作,都需要经过总线的传输,总线的一次传输被称为 “transcation” 。
总线被多个CPU所共享,某个CPU对总线的访问,都能被挂接在同一总线上的其他 CPU “ 看到 ”。
怎样看到 ?
Snooping 机制采用广播的形式,也就是当一个CPU 修改了cache line之后,将广播通知到总线上其他所有的CPU。收听广播是需要 耳朵 的,对于CPU来说这个“ 耳朵 ”就是一个硬件单元,它会负责监听总线上所有 transactions 的广播。
广播的方式虽然简单,但要时刻监听总线上的一切活动,可得累个够呛,而且CPU之间共享的内存数据毕竟只占少数,大部分监听可以说都是白费力气,所以才引入了一个用于过滤的 snoop filter , 过滤的标准就是看自家的CPU有没有缓存这个transaction涉及到的内存位置,或者说有没有对应的cache line 。
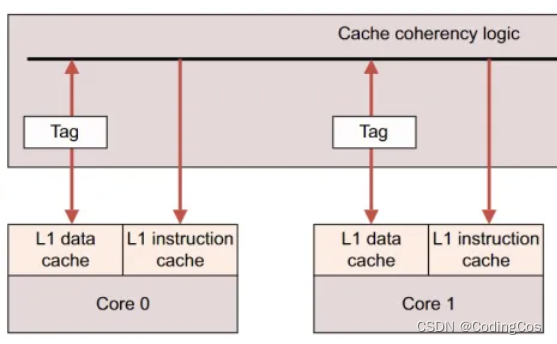
那怎么判断有没有呢?
答: 识别 cache line的标准,自然是 Tag 比对:
过滤之后接收方的工作减轻了,可广播还一直在那儿呢,每个CPU产生的总线transaction,都要广播给其他的每个CPU,这得多消耗总线带宽(bandwidth)啊。假设CPU的个数是N,那么需要的总线带宽就是: N * (N-1) = N 2 - N
所以,如果总线上CPU的数目比较少还好(2到8个),这按平方的增长速度,多了总线可就吃不消了。
CCI-550 Snoop filter
如上文所述,CCI-550 包含一个监听过滤器(snoop filter),用于记录存储在ACE master cache中数据的地址。
如果 coherency总线发起一个 snoop transaction 之后,但是这个时候,在其他master中并不存在所需的数据,snoop filter 就会给snoop transaction返回一个respons。
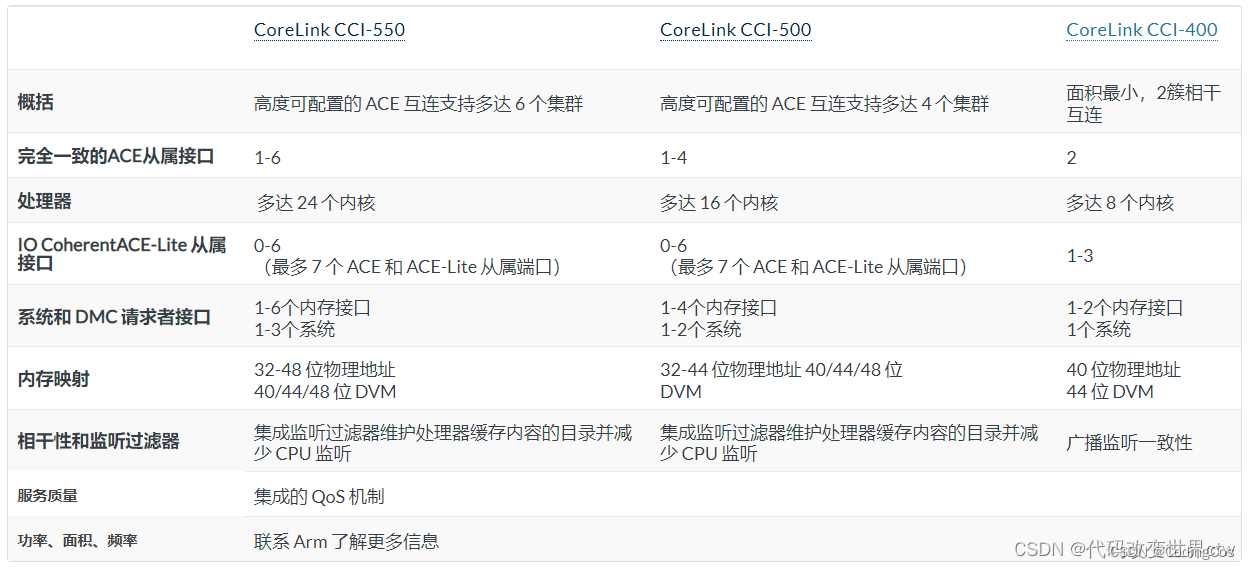
Question:CCI400 与 CCI500 的区别
CCI400 和 CCI500 都是 ARM 公司推出的 Cache Coherent Interconnect(缓存一致性互连)IP 核,主要用于多核SoC系统中连接CPU、GPU、DMA等多个主设备,实现高效的数据流通与缓存一致性。
主要区别如下:
一、功能特性
| 特性 | CCI-400 | CCI-500 |
|---|---|---|
| 发布年代 | 2011年左右 | 2016年左右 |
| 总线协议 | AMBA AXI3/AXI4 | AMBA AXI4 |
| 主端口数目 | 最多4个 | 最多6个 |
| 从端口数目 | 2个 | 3个 |
| 数据带宽 | 2x128bit | 3x128bit (可达384bit) |
| 时钟域支持 | 单一时钟域 | 多时钟域 |
| QoS支持 | 支持基本QoS | 增强型QoS、更好的流量控制 |
| ACE-Lite 支持 | 部分支持 | 完全支持 |
| ACE/ACE-Lite一致性 | 支持ARM ACP和DVM接口 | 支持更多ACE-Lite端口 |
| 安全特性 | 基本 | TrustZone安全性增强 |
| 低功耗特性 | 一般 | 支持功耗域隔离、低功耗优化 |
| 对称多核支持 | 有限 | 支持更多大核+小核(支持HSA架构) |
二、应用与定位
- CCI-400:主要应用于较早期的ARM Cortex-A7/A15/A17/A53/A57 配置的多核SoC(如部分早期的高通骁龙、三星Exynos)。
- CCI-500:适用于需要更高带宽、更多端口、更强一致性、更低功耗和安全需求的SoC(如Cortex-A72/A73等更高端处理器)。
三、技术演进
- CCI-500 相比 CCI-400,针对大型手机、平板SoC中“big.LITTLE”异构多核,有更强的数据一致性和带宽优化,并改进了功耗和安全机制。
- CCI-500引入了更多企业级特性,适合服务器和高性能计算方向的ARM芯片。
四、简要总结
- CCI-400:面向基础多核一致性互连,满足智能手机、平板等中低端需求;
- CCI-500:带宽更大,端口更多,支持更复杂的多核架构,更强的一致性和安全性,适合高端移动设备甚至服务器。
实用对比举例:
- 2014年发布的部分旗舰安卓SoC采用 CCI-400;
- 2016年后期的高端SoC则多改用 CCI-500 或更先进的CMN产品。
Snoop Filter 介绍
- Snoop Filter 是一种缓存一致性优化机制,用于减少不必要的嗅探(snoop)流量。
- 在多核系统中,CPU之间需要通过嗅探机制保持缓存一致性。没有 Snoop Filter 时,所有嗅探请求都会广播到所有相关主设备,带来带宽和延迟开销。
- CCI-500 内置 Snoop Filter,可以记录哪些缓存行被哪些主设备缓存,从而只向真正需要的主设备发起嗅探请求,极大减少了总线流量和功耗,提高了系统性能。
- CCI-400 没有 Snoop Filter,所有嗅探请求都需要广播。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号