
【ARM CoreLink 系列 2 -- CCI-400 控制器简介】
CCI-400 介绍
CCI(Cache Coherent Interconnect)是ARM中的cache一致性控制器。

CCI-400将互连和一致性功能结合到一个模块中。它支持多达两个ACE 主节点的连接,例如:
- Cortex®-A7 processor
- Cortex-A15 processor
- Cortex-A17 processor
- Cortex-A53 processor
- Cortex-A57 processor
| Feature | Details |
|---|---|
| AMBA specifications | AMBA 4 ACE and ACE-Lite |
| ACE Slave interfaces | 2 for fully coherent processors including Arm Cortex |
| ACE-Lite slave interfaces | 1-3 for IO coherent devices such as Mali processors, accelerators and IO |
| Memory and system master interfaces | 1-2 memory interfaces 1 system interface |
| Coherency | Broadcast snoop protocol |
| Memory map | 40 bit Physical, configurable address map 44 bit DVM |
CCI-400还支持多达三个ACE-Lite主站,例如,ARM MaliTM-T600系列图形处理器单元(GPU)。
DVM消息
- 缓存一致性维护:在ARM多核系统中,不同处理器或设备可能共享内存。DVM消息用于同步各核心/设备的缓存状态,确保对同一内存地址的访问一致。
- 跨节点通信:在NUMA(非统一内存访问)架构中,DVM消息协调不同内存节点的数据同步,降低访问延迟。
所有这些接口都有可选的DVM消息支持,以管理分布式内存管理单元(MMU),例如CoreLink MMU-400。这些单元可以通过CCI-400与最多三个ACE-Lite从机进行通信。
硬件管理的一致性可以通过共享片上数据来提高系统性能和降低系统功耗。
CCI-400cache一致性控制器实现了ACE协议,demo系统框图如下所示:
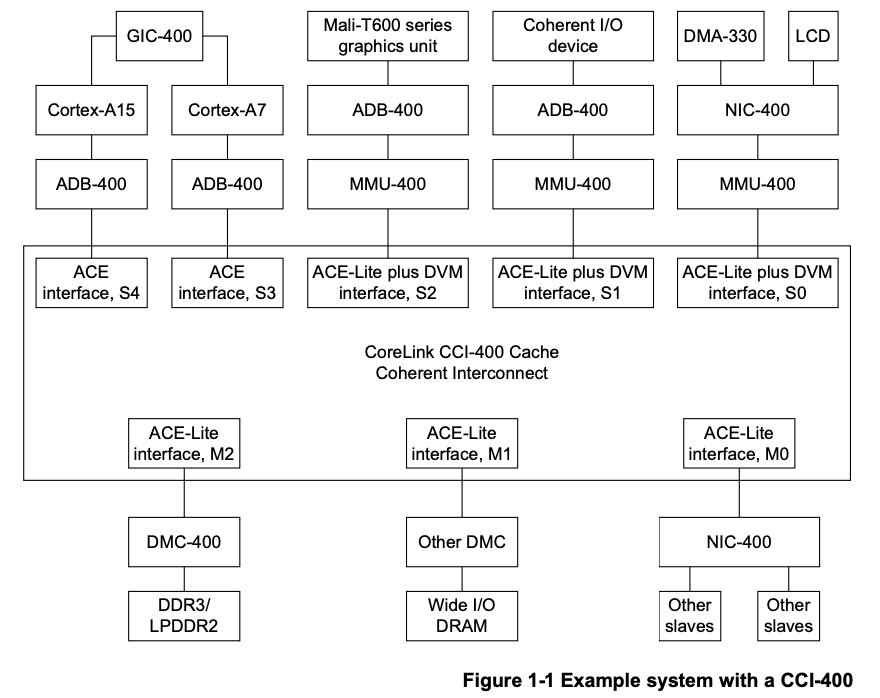
CCI-400cache一致性控制器是一个基础设施组件,支持以下内容:
- 在最多两个ACE主站和三个ACE-Lite主站之间的数据一致性,有三个独立的序列化点(PoS)和全屏障支持。
- 主站和最多三个从站之间的高带宽、跨栏互连功能。
- 主站之间的DVM消息传输。
- QoS虚拟网络(QVN)。本质上是一种 Virtual 的 Network,我们知道从一个 master 到一个slave,它中间走的实际路线叫做physical network,在physical network上根据需要还可以设置多个virtual 的 network,在 virtual network之间,通过类似于token这种机制(只有一个master获得了token,它才有资格去往下发送它的一些传输的请求)。QVN 机制使用这种 virtual network,使用这种基于token的机制去传输数据能够很好的避免系统拥塞。
- 服务质量(QoS)调节,用于塑造流量曲线。QoS机制可认为是一种资源分配的机制,比如根据 outstanding 的能力,去限制某一个端口发送数据的能力。还可以根据发送速率或者传输的latency来分配transaction,这些都是QoS-400能够做到的。
- 性能监测单元(PMU),统计与性能有关的事件。
DVM 机制介绍
Distributed Virtual Memory(DVM)机制是一种用于实现分布式虚拟内存的技术。它允许多个处理器共享同一块物理内存,并通过高速网络连接进行通信。
DVM机制的核心思想是将物理内存划分为多个虚拟内存空间,并将这些虚拟内存空间分配给不同的处理器。每个处理器只能访问自己的虚拟内存空间,但可以通过网络与其他处理器进行通信和共享数据。
DVM机制的实现主要依赖于以下几个关键技术:
- 虚拟内存管理:每个处理器都有自己的虚拟地址空间,通过地址转换机制将虚拟地址映射到物理地址。这样可以实现不同处理器之间的地址隔离和虚拟内存的管理。
- 数据共享:处理器可以通过网络连接,将自己的虚拟内存中的数据共享给其他处理器。这种数据共享可以通过消息传递、远程存取等方式实现。
- 一致性维护:由于多个处理器共享同一块物理内存,需要保证数据的一致性。当一个处理器修改了共享内存中的数据时,其他处理器需要及时获得最新的数据,以保证一致性。这通常需要使用一致性协议和缓存一致性机制。
DVM机制的优点是可以充分利用多处理器系统的计算资源,提高系统的性能和可扩展性。它适用于需要高并发和大规模数据共享的应用场景,例如分布式计算、数据中心等。
需要注意的是,DVM机制并非 ARM处理器 中的内置特性,而是一种通用的分布式计算技术。在ARM处理器中,可以通过软件实现DVM机制,或者使用一些专门的硬件实现,如ARM的CoreLink CCI(Cache Coherent Interconnect)系列产品。这些产品提供了高性能的互连网络和缓存一致性机制,以支持分布式虚拟内存的实现。
DVM 消息传输过程
DVM消息的传输过程如下:
- 当一个处理器需要改变某段内存的状态时(例如,写入数据),它会生成一个DVM消息,并将其发送到CCI。
- CCI在收到DVM消息后,会将其转发到其他连接到CCI的处理器。这些处理器在收到DVM消息后,会检查自己的缓存,如果缓存中包含了该内存,那么会根据DVM消息的类型进行相应的操作,例如,更新缓存或者将缓存失效。
- 当所有的处理器都对DVM消息进行了响应之后,CCI会向原始处理器发送一个确认消息,表示该DVM消息已经被所有的处理器处理完毕。
如下是 DVMop 一个典型的应用:

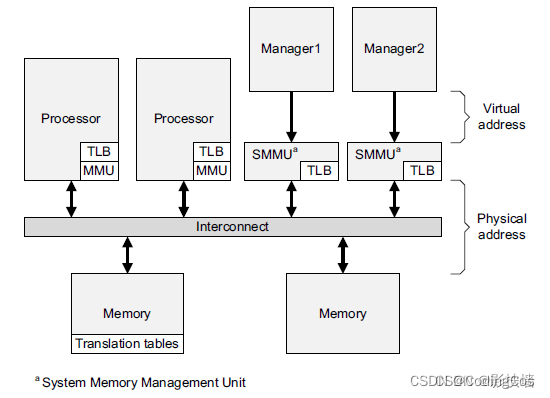
通过DVM消息,处理器可以有效地维护缓存一致性,确保在多处理器系统中,所有的处理器都可以看到最新的数据。这对于提高多处理器系统的性能和可靠性具有重要意义。
需要注意的是,DVM消息的具体实现可能会因ARM的不同产品而有所不同。具体的细节,如DVM消息类型、格式和传输过程,需要参考相关的硬件文档和规范。
TOKEN 机制介绍
在多个设备同时访问总线时,如果不进行流量控制,可能会导致数据冲突和混乱。为了避免这种情况,ARM引入了总线token机制。
总线token机制基于一个令牌(token)的概念。令牌可以理解为一种权限,只有持有令牌的设备才能在总线上进行数据传输。当一个设备需要访问总线时,它必须请求令牌。如果当前总线上没有令牌可用,设备必须等待,直到有令牌可用为止。一旦设备获得令牌,它就可以在总线上进行数据传输。当传输完成后,设备释放令牌,使其可供其他设备使用。
总线token机制具有以下特点:
- 确保数据传输的有序性:每次只有一个设备可以持有令牌,这样可以保证数据传输按照请求的顺序进行。
- 控制总线的带宽:通过令牌管理,可以控制总线上的设备数量,以控制总线的带宽使用情况,避免过多设备同时访问总线导致的性能下降。
- 提高系统的可靠性:总线token机制可以避免数据冲突和竞争,从而提高系统的可靠性和稳定性。
总线token机制是ARM处理器中用于管理总线上的数据传输的一种重要机制,能够保证数据传输的有序性和可靠性。在多设备同时访问总线的情况下,总线token机制可以有效地管理和控制数据传输。
Question:
ARM L1\L2 CACHE 缓存一致性是由DVM 实现的吗
在ARM架构中,L1/L2缓存的一致性并非直接由DVM(Distributed Virtual Memory)实现,而是通过硬件一致性协议(如ACE或CHI)完成的。以下是关键点解析:
1. 缓存一致性的核心机制
-
硬件一致性协议:
ARM多核系统的L1/L2缓存一致性主要通过AMBA总线协议(如ACE或CHI)实现。- ACE (AXI Coherency Extensions): 用于多核间缓存同步(如Cortex-A7/A15)。
- CHI (Coherent Hub Interface): 更高性能的协议(如Cortex-A76/Neoverse N1)。
- MESI/MOESI协议: 在缓存行级别维护一致性状态(Modified/Exclusive/Shared/Invalid)。
-
硬件自动维护:
当CPU核心访问内存时,缓存控制器会自动通过总线协议广播消息,确保其他核心的缓存状态同步,无需软件干预。
2. DVM的辅助角色
DVM主要用于跨系统范围(如多集群、NUMA节点)的一致性管理,而非直接处理L1/L2缓存:
- 跨域同步:
在多集群架构(如ARM DynamIQ)中,不同集群(Cluster)可能属于不同的缓存一致性域(CCIX),DVM消息用于协调跨域操作。 - 虚拟化扩展:
在虚拟机(VM)或安全世界(TrustZone)间隔离内存时,DVM消息协助维护物理内存映射的一致性。 - 系统级操作:
如全局缓存维护指令(DC CIVAC)会触发DVM消息广播到所有节点,确保所有缓存层级(包括L1/L2)被清理。
3. 示例:缓存操作如何关联DVM
当执行一条全局缓存无效化指令时:
DC CIVAC, X0 // 无效化地址X0对应的缓存行
DSB ISH
- 硬件会通过总线协议(如CHI)更新本地L1/L2缓存。
- 如果目标地址属于其他一致性域(如另一个NUMA节点),则生成DVM消息通知远端节点同步。
4. 对比:DVM vs 硬件一致性协议
| 特性 | 硬件一致性协议 (ACE/CHI) | DVM |
|---|---|---|
| 作用范围 | 单芯片内多核的L1/L2缓存 | 跨集群/NUMA节点的系统级内存 |
| 实现方式 | 硬件自动完成 | 硬件消息+软件协同 |
| 性能影响 | 低延迟(硬件优化) | 较高延迟(跨域通信) |
| 典型场景 | 多核CPU共享内存 | 多芯片/虚拟机/异构计算 |
5. 开发者注意事项
- 无需手动处理L1/L2一致性:
硬件协议已自动维护,除非涉及DMA设备(需调用__clean_dcache_area_poc等内核API)。 - 跨域操作需显式同步:
若数据可能被其他一致性域访问,需使用DVM相关指令或内存屏障(如DSB)。 - 性能敏感场景避免DVM:
频繁的跨节点DVM消息可能导致总线拥堵,需优化数据局部性。
结论:
L1/L2缓存一致性由硬件协议(ACE/CHI)直接实现,DVM则用于更大范围的系统级内存同步,两者协同但职责不同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号