
Linux 监控和调试利器 Sysdig 入门教程
Sysdig 简介
Sysdig 官网 上对自己的介绍是:
Open Source Universal System Visibility With Native Contaier Support.
它的定位是系统监控、分析和排障的工具,其实在 Linux 平台上,已经有很多这方面的工具 strace、tcpdump、htop、iftop、lsof、netstat,它们都能用来分析 Linux 系统的运行情况,而且还有很多日志、监控工具。为什么还需要 Sysdig 呢?在我看来,Sysdig 的优点可以归纳为三个词语:整合、强大、灵活。
整合
虽然 Linux 有很多系统分析和调优的工具,但是它们一般都负责某个特殊的功能,并且使用方式有很大的差异,如果要分析和定位问题,一般都需要熟练掌握需要命令的使用。而且这些工具的数据无法进行共享,只能相互独立工作。Sysdig 一个工具就能实现上述所有工具的功能,并且提供了统一的使用语法。
强大
Sysdig 能获取实时的系统数据,也能把信息保存到文件中以供后面分析。捕获的数据包含系统的个个方面:
• 全方面的系统参数:CPU、Memory、Disk IO、网络 IO
• 支持各种 IO 活动:进程、文件、网络连接等
除了帮你捕获信息之外,Sysdig 还预先还有有用的工具来分析这些数据,从大量的数据中找到有用的信息变得非常简单。比如你能还简单地做到下面这些事情:
• 按照 CPU 的使用率对进程进行排序,找到 CPU 使用率最高的那个
• 按照发送网络数据报文的多少对进程进行排序
• 找到打开最多文件描述符的进程
• 查看哪些进程修改了指定的文件
• 打印出某个进程的 HTTP 请求报文
• 找到用时最久的系统调用
• 查看系统中所有的用户都执行了哪些命令
• ……
基本上自带的工具就能满足大部分的分析需求。
灵活
Sysdig 有着类似于 tcpdump 的过滤语法,用户可以随意组合自己的过滤逻辑,从茫茫的数据中找到关心的信息。除此之外,用户还可以自己编写 Lua 脚本来自定义分析逻辑,基本上不受任何限制。
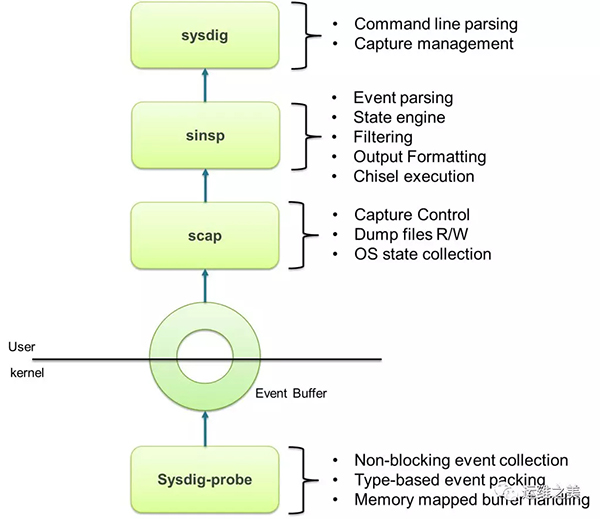
工作原理
Sysdig 通过在内核的 driver 模块注册系统调用的 hook,这样当有系统调用发生和完成的时候,它会把系统调用信息拷贝到特定的 buffer,然后用户模块的组件对数据信息处理(解压、解析、过滤等),并最终通过 Sysdig 命令行和用户进行交互。
安装
Sysdig 的安装在官方文档中有详细的说明,这里不再赘述。需要注意的是,Sysdig 对内核版本有一定的要求,请保证内核不要太旧。
另外,如果使用容器的方式安装,需要把主机的很多系统目录 mount 到容器中:
$ docker run -i -t --name sysdig --privileged -v /var/run/docker.sock:/host/var/run/docker.sock -v /dev:/host/dev -v /proc:/host/proc:ro -v /boot:/host/boot:ro -v /lib/modules:/host/lib/modules:ro -v /usr:/host/usr:ro sysdig/sysdig
Sysdig 基本用法
基本格式
直接在终端输入 sysdig 就能开始捕获系统信息,这个命令需要系统管理员权限,执行后你会看到终端有持续不断的输出流。
$ sudo sysdig
因为系统每时每刻都有大量的系统调用产生,这样是没办法看清更无法分析输出信息的,可以先使用 CTRL + c 来退出命令。
在讲解如何使用 Sysdig 的参数之前,我们先来解释一下它的输出格式:
5352209 11:54:08.853479695 0 ssh-agent (13314) < getrusage
5352210 11:54:08.853481094 0 ssh-agent (13314) > clock_gettime
5352211 11:54:08.853482049 0 ssh-agent (13314) < clock_gettime
5352226 11:54:08.853510313 0 ssh-agent (13314) > getrusage
5352228 11:54:08.853511089 0 ssh-agent (13314) < getrusage
5352229 11:54:08.853511646 0 ssh-agent (13314) > clock_gettime
5352231 11:54:08.853512020 0 ssh-agent (13314) < clock_gettime
5352240 11:54:08.853530285 0 ssh-agent (13314) > stat
5352241 11:54:08.853532329 0 ssh-agent (13314) < stat res=0 path=/home/cizixs/.ssh
5352242 11:54:08.853533065 0 ssh-agent (13314) > stat
5352243 11:54:08.853533990 0 ssh-agent (13314) < stat res=0 path=/home/cizixs/.ssh/id_rsa.pub
5353954 11:54:08.857382204 0 ssh-agent (13314) > write fd=16 size=280
所有的输入都是按照行来分割的,每行都是一条记录,由多个列组成,默认的格式是:
%evt.num %evt.outputtime %evt.cpu %proc.name (%thread.tid) %evt.dir %evt.type %evt.info
各个字段的含义如下:
• evt.num:递增的事件号。
• evt.time:事件发生的时间。
• evt.cpu:事件被捕获时所在的 CPU,也就是系统调用是在哪个 CPU 执行的。比较上面的例子中,值 0 代表机器的第一个 CPU。
• proc.name:生成事件的进程名字,也就是哪个进程在运行。
• thread.tid:线程的 id,如果是单线程的程序,这也是进程的 pid。
• evt.dir:事件的方向(direction),> 代表进入事件,< 代表退出事件。
• evt.type:事件的名称,比如 open、stat等,一般是系统调用。
• evt.args:事件的参数。如果是系统调用,这些对应着系统调用的参数
过滤
完整的 Sysdig 使用方法是这样的:
sysdig [option]... [filter]
因为 Sysdig 的输出内容很多,不管是监控还是查问题我们要关注的事件只是其中很小的一部分。这个时候就要用到过滤的功能,找到感兴趣的事件。Sysdig 的过滤功能很强大,不仅支持的过滤项很多,而且还能够自由地进行逻辑组合。
Sysdig 的过滤器也是分成不同类别的,比如:
• fd: 对文件描述符(file descriptor)进行过滤,比如 fd 标号(fd.num)、fd 名字(fd.name)。
• process: 进程信息的过滤,比如进程 id(proc.id)、进程名(proc.name)。
• evt: 事件信息的过滤,比如事件编号、事件名。
• user: 用户信息的过滤,比如用户 id、用户名、用户 home 目录、用户的登录 shell(user.shell)。
• syslog: 系统日志的过滤,比如日志的严重程度、日志的内容。
• fdlist: poll event 的文件描述符的过滤。
完整的过滤器列表可以使用 sysdig -l 来查看,比如可以查看建立 TCP 连接的事件:
$ sudo sysdig evt.type=accept
过滤器除了直接的相等比较之外,还有其他操作符,包括 =、!=、>=、>、<、<=、contains、in 和 exists,比如:
$ sysdig fd.name contains /etc
$ sysdig "evt.type in ( 'select', 'poll' )"
$ sysdig proc.name exists
更酷的是,多个过滤条件还可以通过 and、or 和 not 进行逻辑组合,比如:
$ sysdig "not (fd.name contains /proc or fd.name contains /dev)"
这些强大的功能综合到一起,就能让我们很容易定位到需要的事件,分析和监控更有目的性。
自定义输出格式
标准的输出已经打印出常用的信息,sysdig 还允许你自定义打印出的内容,参数 -p 可以加上类似于 C 语言 printf 字符串,比如:
$ sysdig -p"user:%user.name dir:%evt.arg.path" evt.type=chdir
user:ubuntu dir:/root
user:ubuntu dir:/root/tmp
user:ubuntu dir:/root/Download
上面的信息,可以很容易看到用户更改当前目录的情况。从上面的例子也可以使用 -p 的使用方法:
• 字段必须用 % 作为前缀,所有在 sysdig -l 中列出来的字段都可以使用
• 你可以在字符串中加入其他可读性的内容,它们会如实打印出来
• 如果某个字段在时间中不存在,默认这个事件会过滤掉,在这个字符串最前面加上 * 符号,会打印出所有的事件,不存在的字段会变成 ,比如:
$ sysdig -p"*%evt.type %evt.dir %evt.arg.name" evt.type=open
open > <NA>
open < /proc/1285/task/1399/stat
open > <NA>
open < /proc/1285/task/1400/io
open > <NA>
open < /proc/1285/task/1400/statm
open > <NA>
保存到文件
尽管可以用过滤器减少输出,直接在终端查看事件流还是没有办法让我们进行深入分析。
和 tcpdump 工具类似,Sysdig 也允许你把捕获的时间保存到本地的文件,然后再读取文件的内容进行分析。
保存到文件可以通过 -w 实现,从文件中读取需要 -r 参数,比如:
# 捕获事件,并保存到文件中,这样在终端是看不到输出的。
$ sudo sysdig -w sysdig-trace-file.scap
# 从文件中读取 Sysdig 格式的事件进行分析。
$ sudo sysdig -r sysdig-trace-file.scap
另一个有用的功能是,你可以控制捕获到文件的内容。通常情况下,Sysdig 捕获了系统所有的活动,因此这些数据会很大,如果一直捕获的话,会造成磁盘空间的浪费,Sysdig 提供了类似于 logrotate 的方式,让你只保存最新捕获的文件。
控制捕获文件大小的一个办法是在捕获的使用使用过滤器,之外,你还可以通过 -n 2000 指定捕获 2000 条事件之后就退出,或者通过 logrotate 的方式来滚动文件:
• sysdig -C 5 -W 10 -w dump.pcap :保证每个文件不超过 5M 大小,并且只保存最近的 10 个文件
• sysdig -G 60 -W 60 -w dump.pcap:每个文件只保存一分钟内的系统活动(-G 60),并且只保存 60 个文件,也就是说捕获最近一个小时的系统活动,每分钟的数据一个文件
• sysdig -e 1000 -W 5 -w dump.scap:保存 5 个文件,每个文件只有 1000 个事件
当使用 -w 保存文件的使用,还可以使用 -z 参数对保存的内容进行压缩,进一步减少占用的空间。
读取的时候也可以使用过滤器,如果我们只关心 write 系统调用:
$ sysdig -r sysdig-trace-nano.scap evt.type=write
而且读取的时候也可以进一步对文件进行分割,比如:
$ sysdig -r dump.scap -G 300 -z -w segments.scap
这个命令,就是读取 dump.scap 文件的内容,并且把它分割成五分钟(-G 300s)的多个文件。
常用的参数
除了上面介绍的过滤器参数,Sysdig 还有很多可用的参数,完整的列表和解释请参考 man sysdig 文档。这里介绍一下比较常用的:
• -A --print-ascii:把 buffer 中数据按照 ASCII 格式打印,方便用户阅读
• -x --print-hex:把 buffer 中数据按照十六进制格式打印
• -X --print-hex-ascii:把 buffer 中数据同时按照 ASCII 格式和十六进制格式打印
• -s 1024:捕获 buffer 的数据大小,默认为 80,如果这个值设置的过大,会产生很大的文件
• -N:不用把端口号转换成可读的名字,这个参数会提高处理的效率
Chisels:实用的工具箱
虽然有了过滤器和文件的输入输出,加上 Sysdig 其他的参数,我们可以按照需求去分析和监控系统了,但是很多场景需要更复杂的数据聚合。
Sysdig 提供了另外一个强大的功能:chisels,它们是一组预定义的功能集合,通过 Lua 脚本实现,用来分析特定的场景。
可以通过 sudo sysdig -cl 列出支持的所有 chisels,我们来解释一些比较常用的 chisels:
• httplog:输出所有的 HTTP 请求。
• topprocs_cpu:输出按照 CPU 使用率排序的进程列表。
• echo_fds:输出进程读写的数据。
• netstat:列出网络的连接情况。
• spy_file:输出文件的读写数据,可以提供某个文件名作为参数,这样就只输出该文件的读写内容。
有些 chisel 可能需要参数才能正常运行,如果要了解某个 chisel 的具体使用说明,可以用 -i 参数,比如要了解 spy_file 的用法:
$ sudo sysdig -i spy_file
Category: I/O
-------------
spy_file Echo any read/write made by any process to all files. Optionall
y, you can provide the name of one file to only intercept reads
/writes to that file.
This chisel intercepts all reads and writes to all files. Instead of all files,
you can limit interception to one file.
Args:
[string] read_or_write - Specify 'R' to capture only read event
s; 'W' to capture only write events; 'RW' to capture read and w
rite events. By default both read and write events are captured
.
[string] spy_on_file_name - The name of the file which the chis
el should spy on for all read and write activity.
文章最开始的时候,我提到过 Sysdig 可以满足大部分的日常分析,它们主要就是通过 chisel 完成的。比如:
按照网络的使用情况对进程进行排序:
$ sysdig -c topprocs_net
按照建立连接数量对进程进行排序:
$ sysdig -c fdcount_by fd.sport "evt.type=accept"
查看系统中用户执行的命令:
$ sysdig -r sysdig.pcap -c spy_users
更多的使用案例,可以参考 Sysdig Example 这篇 wiki。
在 Linux 机器上,这些 chisel 保存在 /usr/share/sysdig/chisels 文件夹中,每个 chisel 对应一个 Lua 脚本文件。如果提供的这些 chisel 还不能满足需求,用户也可以根据需求编写自己的 chisel。
对容器的支持
Sysdig 另外一个优势是它对容器( Docker 和 Kubernetes )的良好支持,这对于目前采用了容器化的系统管理员来说是很好的福利。
使用 -pc 参数就能自动在打印的事件中添加上容器的信息(容器名、容器 id 等),比如捕获 container 名字为 zen_knuth 的所有系统活动:
$ sysdig -pc container.name=zen_knuth
对容器的分析和原来的一样,只要通过 container.name=apache 指定要分析的容器名字就行,比如查看某个容器的网络连接:
$ sysdig -pc -c topconns container.name=wordpress1
要集成 Kubernetes 系统监控的话,使用 -k http://master_ip:8080 参数,后面是 apiserver 的地址,如果 apiserver 需要认证的话,需要指定 -K filename 来说明 apiserver CA 证书的文件地址。关于 Kubernetes 的监控和分析不是这篇文章的重点,读者可以参数 Sysdig 的博客或者其他文档。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号