分区表-实战
分区表的理论知识请查看我的另一篇博文,谢谢——分区-理论
需求说明
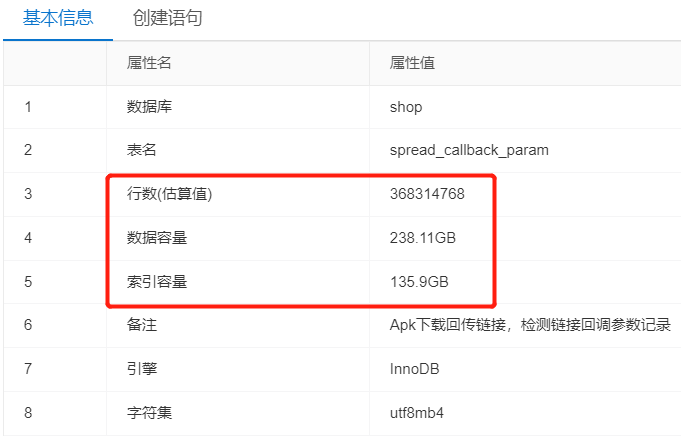
广告投放系统中监测链接表的数据以每天500w+的速度递增(用户每次点击广告生成),但是热点数据就10天左右,其余都是没用的历史数据。采用定时任务Delete的方式,只是做了逻辑上的标记删除,在磁盘上数据并没有被真正删除。同时通过Delete方式删除数据的效率太低,最终采用分区表的形式(现在分表的话成本太高),利于数据的维护;
注意:当数据量超大的时候,B-Tree索引就无法起作用了。除非是索引覆盖查询,否则数据库服务器需要根据索引扫描的结果回表,查询所有符合条件的记录,如果数据量巨大,这将产生大量随机I/O,随之,数据库的响应时间将大到不可接受的程度。另外,索引维护(磁盘空间、I/O操作)的代价也非常高。
修改前
表是以id为自增主键的,创建时间created_at为timestamp类型。


CREATE TABLE `spread_callback_param` ( `id` int(11) NOT NULL AUTO_INCREMENT, `adid` varchar(128) DEFAULT NULL COMMENT '广告计划id', `cid` varchar(128) DEFAULT NULL COMMENT '广告创意 id,长整型', `imei` varchar(128) DEFAULT NULL COMMENT '安卓的设备 id 的 md5 摘要,32位', `idfa` varchar(128) DEFAULT NULL COMMENT 'ios 6+的设备id字段,32位', `androidid` varchar(128) DEFAULT NULL COMMENT '安卓id原值的md5,32位', `oaid` varchar(128) DEFAULT NULL COMMENT 'android q及更高版本的设备号,32位', `oaid_md5` varchar(128) DEFAULT NULL COMMENT 'android q及更高版本的设备号的md5摘要,32位', `os` varchar(128) DEFAULT NULL COMMENT '操作系统平台,安卓:0,ios:1,其他:3', `mac` varchar(128) DEFAULT NULL COMMENT '移动设备mac地址,转换成大写字母,去掉“:”,并且取md5摘要后的结果', `mac1` varchar(128) DEFAULT NULL COMMENT '移动设备 mac 地址,转换成大写字母,并且取md5摘要后的结果,32位', `ip` varchar(128) DEFAULT NULL COMMENT '媒体投放系统获取的用户终端的公共ip地址', `ua` varchar(255) DEFAULT NULL COMMENT '用户代理(user agent),一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、cpu类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等', `geo` varchar(128) DEFAULT NULL COMMENT '位置信息,包含三部分:latitude(纬度),longitude(经度)以及precise(确切信息,精度)', `ts` varchar(128) DEFAULT NULL COMMENT '客户端发生广告点击事件的时间,以毫秒为单位时间戳', `callback` varchar(128) DEFAULT NULL COMMENT '一些跟广告信息相关的回调参数,内容是一个加密字符串,在调用事件回传接口的时候会用到', `model` varchar(128) DEFAULT NULL COMMENT '手机型号', `phone` varchar(128) DEFAULT NULL COMMENT '手机型号', `channel` varchar(10) NOT NULL DEFAULT '' COMMENT '投放渠道号', `app_id` varchar(128) DEFAULT NULL COMMENT '父产品id', `scenes` int(11) NOT NULL COMMENT '回调场景值', `media` varchar(64) NOT NULL DEFAULT '' COMMENT '媒体标识,字典表code=''mediacode''', `campaign_id` varchar(128) DEFAULT NULL COMMENT '广告组Id', `csite` varchar(128) DEFAULT NULL COMMENT '广告投放位置', `convert_id` varchar(128) DEFAULT NULL COMMENT '转化ID', `request_id` varchar(128) DEFAULT NULL COMMENT '请求ID', `union_site` varchar(128) DEFAULT NULL COMMENT '对外广告位编码', `created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP, `disabled` bit(1) DEFAULT NULL, `created_by` varchar(64) DEFAULT NULL, `updated_at` datetime DEFAULT NULL, `updated_by` varchar(64) DEFAULT '', `version` bigint(20) DEFAULT NULL, PRIMARY KEY (`id`), KEY `device_imei` (`imei`), KEY `device_androidid` (`androidid`), KEY `device_idfa` (`idfa`), KEY `channel` (`channel`), KEY `ctime` (`created_at`), KEY `device_mac` (`mac`) USING BTREE, KEY `device_ip` (`ip`) USING BTREE, KEY `idx_app_id` (`app_id`) USING BTREE, KEY `idx_media` (`media`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=704389061 DEFAULT CHARSET=utf8mb4 COMMENT='Apk下载回传链接,检测链接回调参数记录'
分区操作步骤
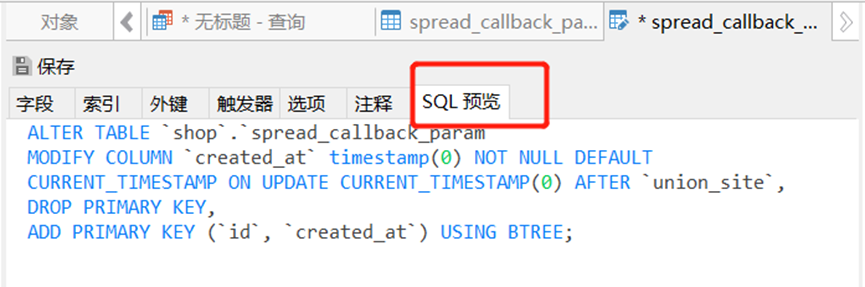
(1) 修改创建时间created_at不为空,将创建时间created_at加入到主键当中
分区中很重要的一点是主键中必须包含表的分区函数中的所有列,因为我们需要按照创建时间created_at进去分区,所以需要将created_at加入到主键当中,同时设置为非空。
//修改创建时间不为空,将创建时间加入到主键当中 ALTER TABLE `shop`.`spread_callback_param` MODIFY COLUMN `created_at` timestamp(0) NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP(0) AFTER `union_site`, DROP PRIMARY KEY, ADD PRIMARY KEY (`id`, `created_at`) USING BTREE;
我们可以在客户端(Navicat)中进行修改后,直接在SQL预览中复制。
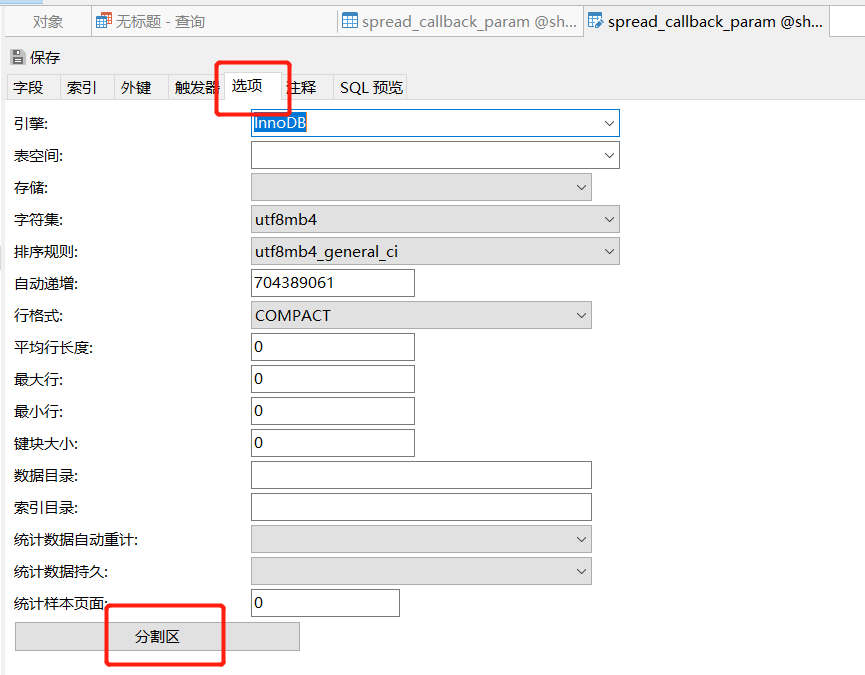
(2)完成分区创建
我们可以通过使用客户端工具(Navicat)来便捷的进行分区,对表点击右键,选择设计表后,点击选项栏中的分割区按钮。
随后我们就可以根据你的需要设置分区相关的参数。
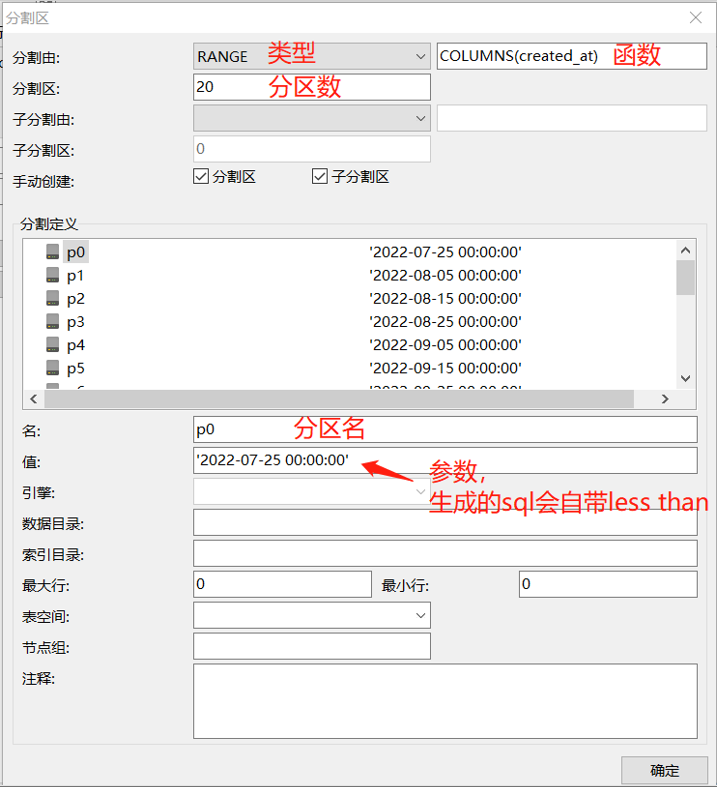
当你设置后点击右下方的确定按钮后,可以先预览SQL,无误则保存,完成分区创建。
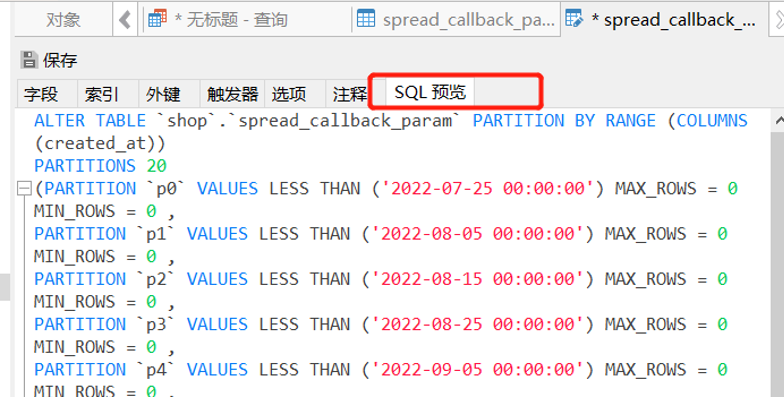
注意MySQL的版本可能会影响你分区是否能正常创建,可能会出现一些报错。好比我的创建时间created_at为timestamp类型,而RANGE主要是基于整数的分区,所以我们需要通过UNIX_TIMESTAMP()函数将其转换成整型,否者可能会报如下的错。
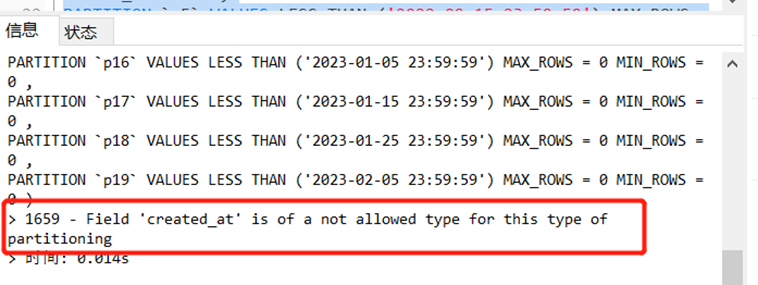
正确的分区语句如下
ALTER TABLE spread_callback_param PARTITION BY RANGE (UNIX_TIMESTAMP(created_at )) ( PARTITION `p0` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-07-25 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p1` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-08-05 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p2` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-08-15 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p3` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-08-25 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p4` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-09-05 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p5` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-09-15 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p6` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-09-25 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p7` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-10-05 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p8` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-10-15 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p9` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-10-25 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p10` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-11-05 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p11` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-11-15 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p12` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-11-25 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p13` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-12-05 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p14` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-12-15 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p15` VALUES LESS THAN ( UNIX_TIMESTAMP( '2022-12-25 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p16` VALUES LESS THAN ( UNIX_TIMESTAMP( '2023-01-05 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p17` VALUES LESS THAN ( UNIX_TIMESTAMP( '2023-01-15 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p18` VALUES LESS THAN ( UNIX_TIMESTAMP( '2023-01-25 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0, PARTITION `p19` VALUES LESS THAN ( UNIX_TIMESTAMP( '2023-02-05 23:59:59' ) ) MAX_ROWS = 0 MIN_ROWS = 0 );
分区增删改
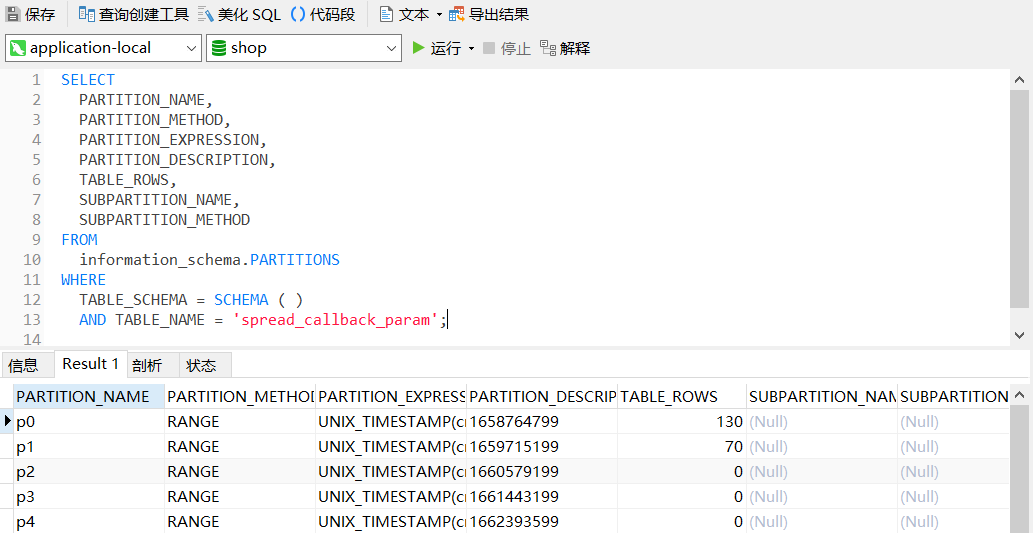
查询分区后的信息
SELECT PARTITION_NAME, PARTITION_METHOD, PARTITION_EXPRESSION, PARTITION_DESCRIPTION, TABLE_ROWS, SUBPARTITION_NAME, SUBPARTITION_METHOD FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA = SCHEMA ( ) AND TABLE_NAME = '表名';
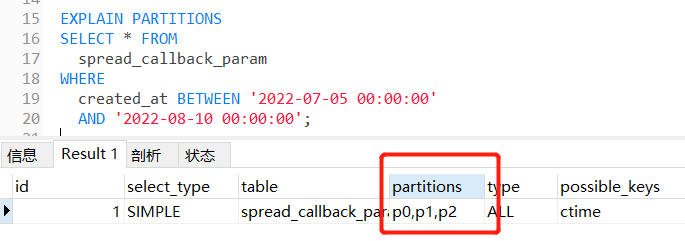
使用 EXPLAIN PARTITIONS 查看执行过程
新增分区
ALTER TABLE 表名 ADD PARTITION (PARTITION 分区名 VALUES LESS THAN (UNIX_TIMESTAMP( '2022-08-30 00:00:00' )));
针对timestamp类型,如果不是,去掉UNIX_TIMESTAMP()函数
清理分区数据
清理分区数据为空,保留分区不删除,仅仅是清理数据,命令如下
ALTER TABLE ‘表名’ TRUNCATE PARTITION 分区名(eg:p1);
删除表的特定分区
ALTER TABLE ‘表名’ DROP PARTITION 分区名(eg:p1);
注意TRUNCATE 和DROP 的区别,truncate table其实有点类似于drop table 然后create,只不过这个create table 的过程做了优化,比如表结构文件之前已经有了等等。所以速度上应该是接近drop table的速度。
truncate与drop,delete的对比
- truncate与drop是DDL语句,执行后无法回滚;delete是DML语句,可回滚。
- truncate只能作用于表;delete,drop可作用于表、视图等。
- truncate会清空表中的所有行,但表结构及其约束、索引等保持不变;drop会删除表的结构及其所依赖的约束、索引等。
- truncate会重置表的自增值;delete不会。
- truncate不会激活与表有关的删除触发器;delete可以。
- truncate后会使表和索引所占用的空间会恢复到初始大小;delete操作不会减少表或索引所占用的空间,drop语句将表所占用的空间全释放掉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号