剖析HashMap
我们将通过以下几个问题进行解答分析:
(1)HashMap 底层实现原理是什么?JDK8 做了哪些优化?
(2)HashMap 的工作原理?HashMap中链表的作用?
(3)为什么要添加红黑树?为什么链表大于 8才转?
(4)加载因子是什么?为什么是0.75?
(5)HashMap 是如何导致死循环的?
HashMap 底层实现原理是什么?JDK8 做了哪些优化?
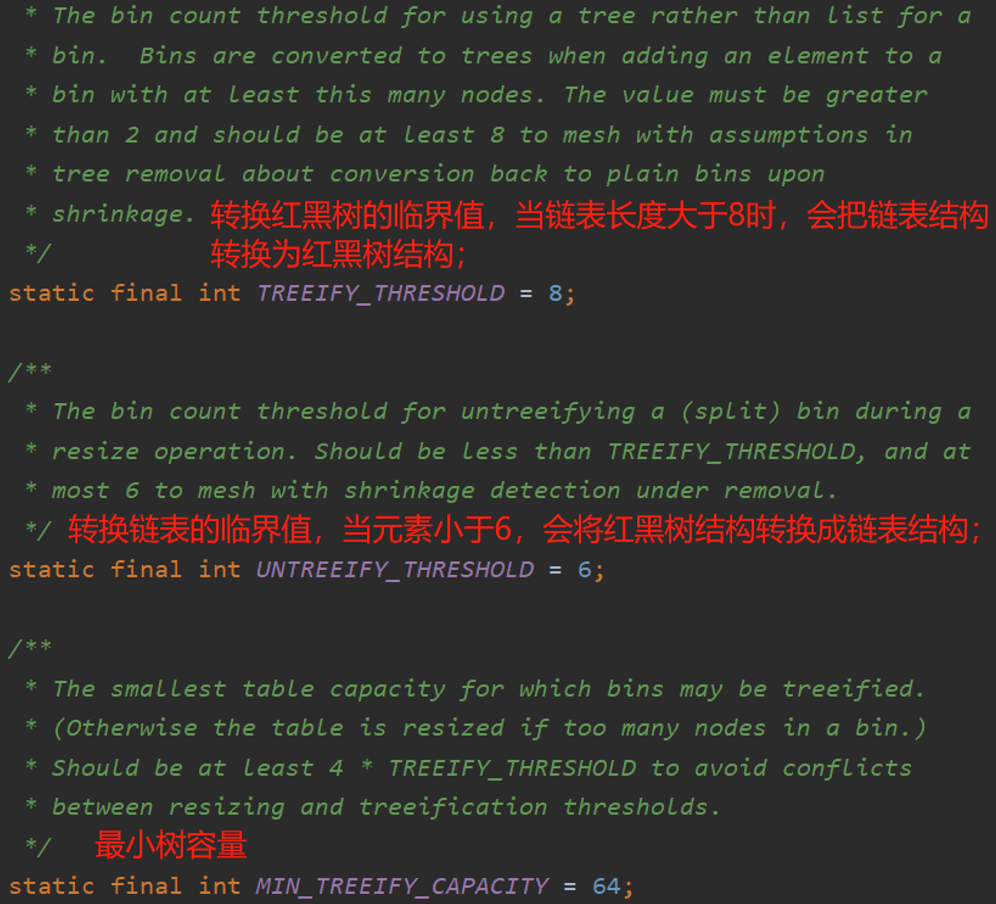
在 JDK 1.7 中 HashMap 是以数组加链表的形式组成的,JDK 1.8 之后新增了红黑树的组成结构,当链表长度大于等于 8 时并且容量(数组的长度)大于 64 时,链表结构会转换成红黑树结构。
组成结构如下图:

数组中的元素我们称之为哈希桶,每个哈希桶中包含了四个字段:hash、key、value、next,其中 next 表示链表的下一个节点。它的定义如下:
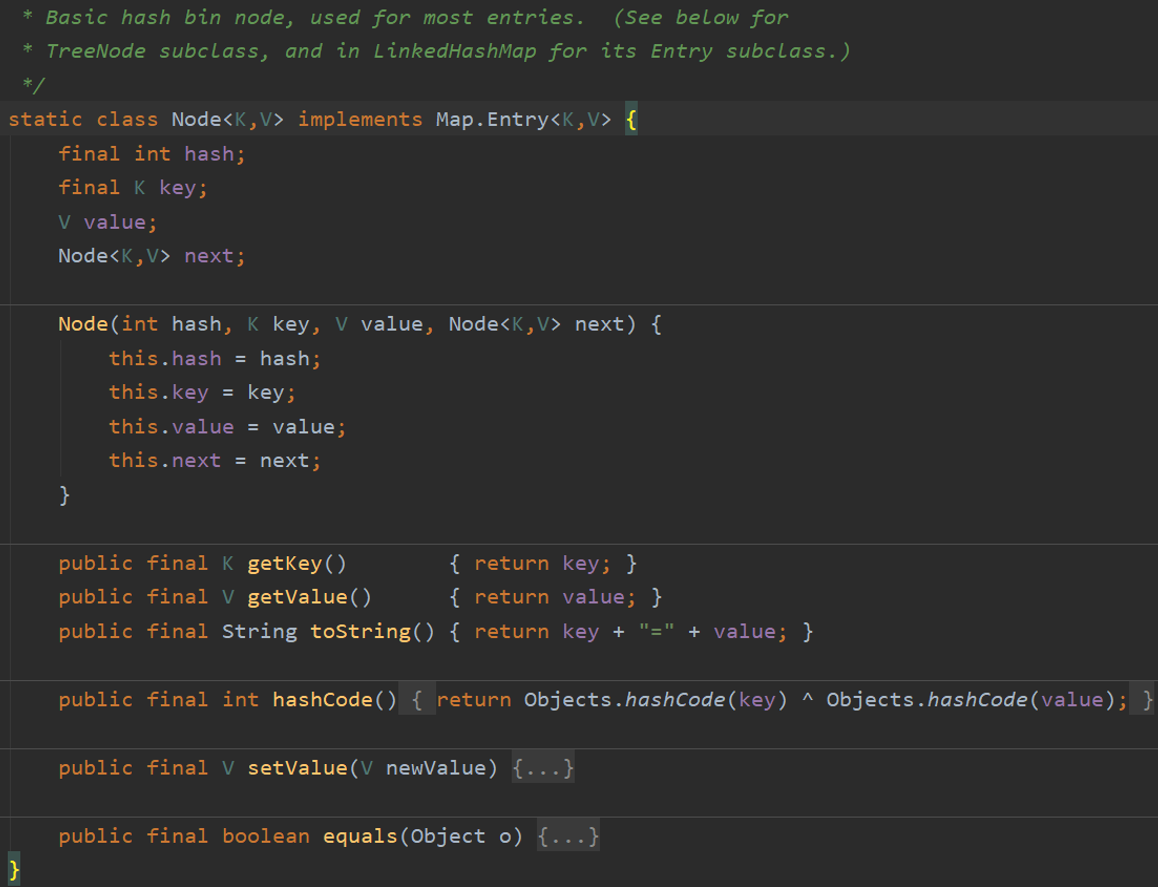
HashMap中链表的作用?
从HashMap的工作原理我们可知,HashMap是利用“拉链法”处理Hash的碰撞问题。
补充:Hash碰撞冲突可以使用开放地址法、再哈希法、链地址法(拉链法)、建立一个公共溢出区、等方法解决。
为什么要添加红黑树?为什么链表大于 8才转?
详细介绍请查阅我的另一篇文章 -- 链表转红黑树的原因?为什么阈值为8?
HashMap源码分析
主流的JDK版本1.8为例
加载因子是什么?为什么是0.75?
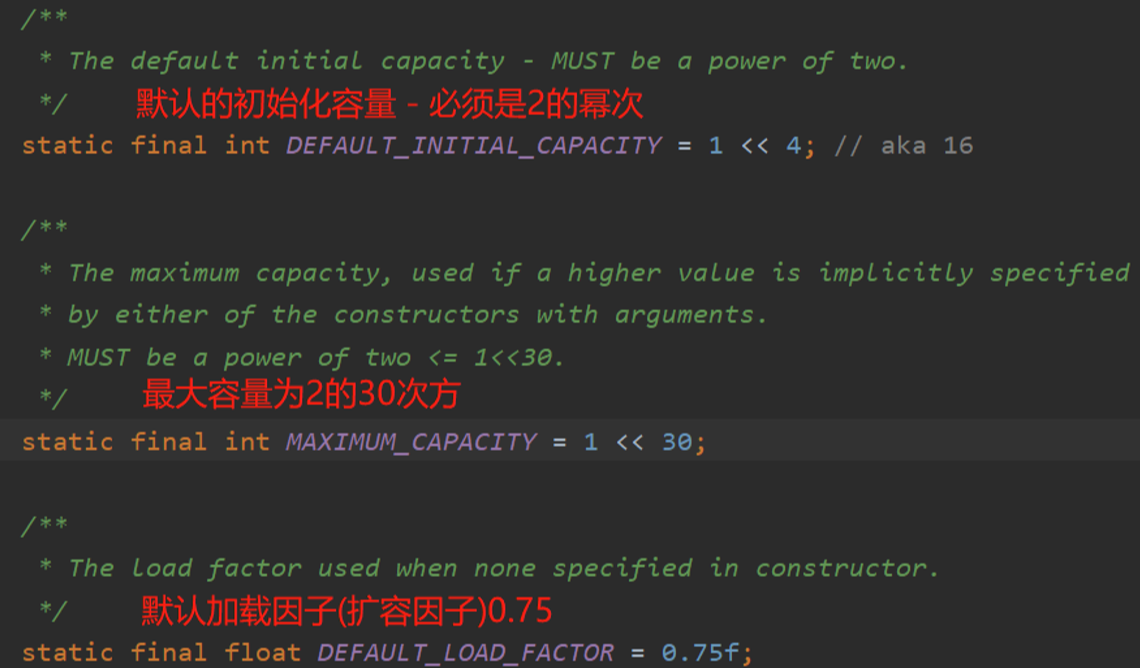
加载因子也叫扩容因子或负载因子,用来判断什么时候进行扩容的,好比默认的加载因子是0.75,HashMap的初始化容量是16,那么当HashMap中有16*0.75=12个元素时,HashMap就会进行扩容。
为什么不是 0.5 或者 1.0 呢?
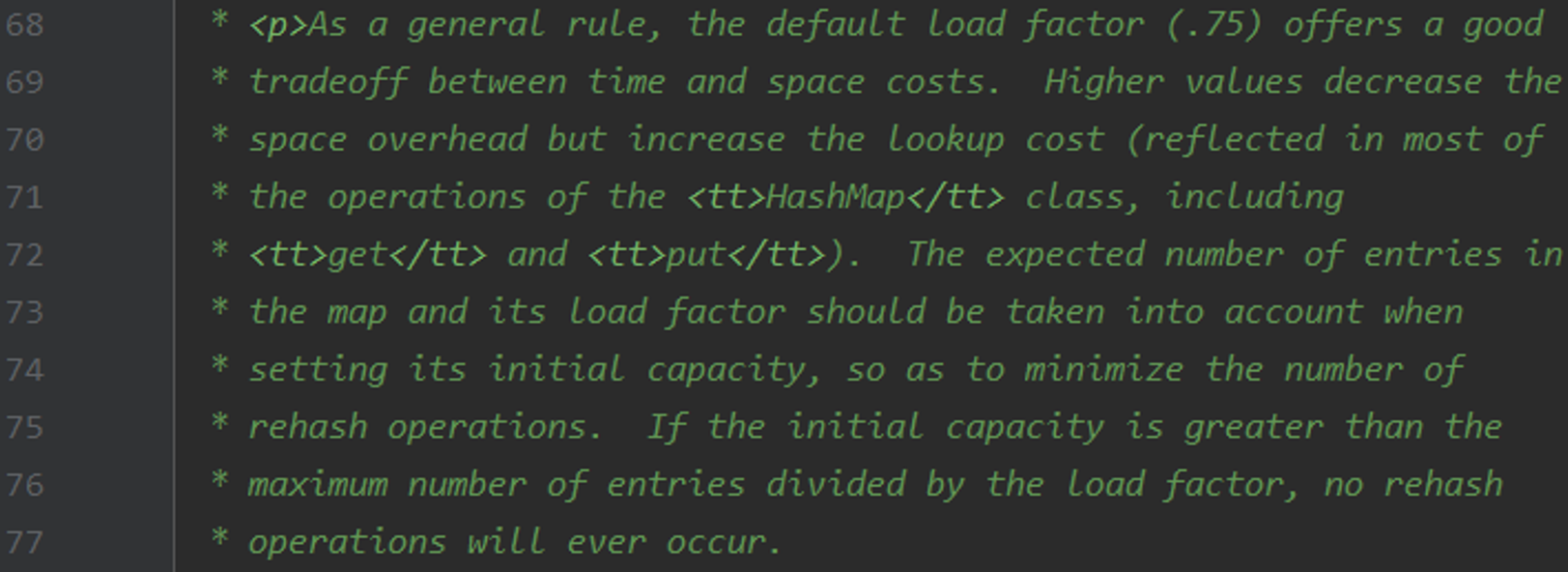
翻译如下:
一般情况下,HashMap默认负载因子为0.75,是对时间和空间开销的权衡。较高的值减少了空间开销,但却会增加查找成本(反映在HashMap的大多操作上,包括get和put等)。在设置初始容量时,要考虑(be taken into account 被考虑在内)哈希表预计存储的条目数以及负载因子大小,尽量减少rehash操作的次数。如果初始容量大于预计存放条目数除以负载因子的商(即预计存放条目数小于初始容量与负载因子的乘积),则永远不会发生 rehash 操作。
HashMap 是如何导致死循环的?
发生死循环的原因是JDK1.7链表插入方式为首部倒序插入,这个问题在JDK1.8得到了改善,变成了尾部正序插入。
有人曾经把这个问题反馈给了 Sun 公司,但 Sun 公司认为这不是一个问题,因为 HashMap 本身就是非线程安全的,如果要在多线程下,建议使用 ConcurrentHashMap 替代,但这个问题在面试中被问到的几率依然很大,所以在这里需要特别说明一下。
HashMap 的工作原理?
HashMap 底层是 hash 数组和单向链表实现,数组中的每个元素都是链表,由 Node 内部类(实现 Map.Entry接口)实现,HashMap 通过 put & get 方法存储和获取。
存储对象时put() 方法
1.判断table(数组)是否为空,如果为空则调用resize()方法初始化table(数组)。
2. 判断当前插入的键值对的key的哈希值是否已经存在(是否发生hash碰撞(冲突))。
i.如果没有发生hash碰撞则创建一个新结点newNode()插入就行了。
ii.如果 key的 hash 值在 HashMap 中存在(发生hash碰撞),且它们两者 equals 返回 true,则更新键值对;
iii. 如果 key 的 hash 值在 HashMap 中存在(发生hash碰撞),且它们两者 equals 返回 false,则插入链表的尾部(JDK 1.7 之前使用头插法、JDK 1.8 使用尾插法)或者红黑树中。
获取对象 get() 方法
1.计算 key的 hash 值从而获取该键值所在链表的数组下标;
2.顺序遍历链表,equals()方法查找相同 Node 链表中 key 值对应的 value 值。
hashCode 是定位的,存储位置;equals是定性的,比较两者是否相等。
<END>
⭐️希望本文章对您有帮助,您的「 转发、点赞 」是我创作的无限动力。
扫描下方二维码关注微信公众号,您会收到更多优质文章推送。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号