python爬虫--爬取豆瓣top250电影名
关于模拟浏览器登录的header,可以在相应网站按F12调取出编辑器,点击netwook,如下:
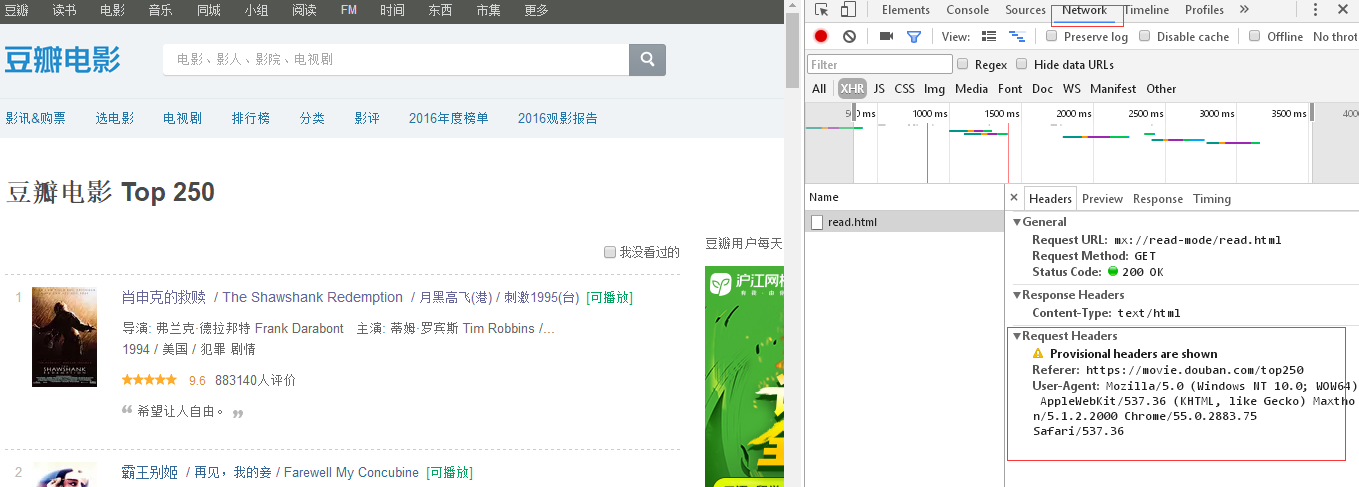
以便于不会被网站反爬虫拒绝。
import requests from bs4 import BeautifulSoup def get_movies(): headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36', 'Host': 'movie.douban.com' } movie_list = [] for i in range(0, 10): link = 'https://movie.douban.com/top250?start=' + str(i * 25) r = requests.get(link, headers=headers, timeout=10) print(str(i + 1), "页响应状态码:", r.status_code) soup = BeautifulSoup(r.text, "lxml") div_list = soup.find_all('div', class_='hd') for each in div_list: movie = each.a.span.text.strip() movie_list.append(movie) return movie_list movies = get_movies() print(movies)
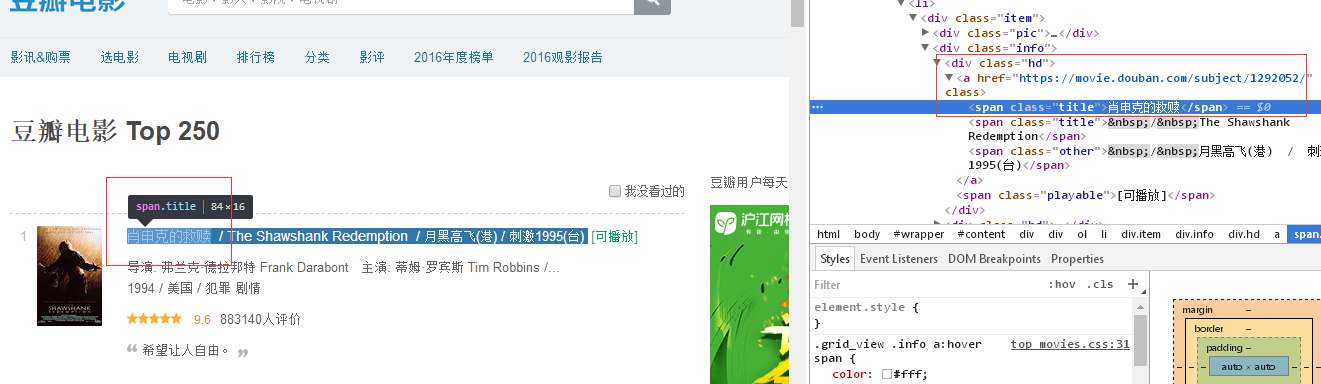
或者:
import requests from bs4 import BeautifulSoup # 设置请求头,模拟浏览器访问 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36', } # 发送请求获取网页内容 url = 'https://movie.douban.com/top250' response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, 'html.parser') # 定位电影列表 movie_list = soup.find('ol', class_='grid_view').find_all('li') # 遍历电影列表,提取信息 for movie in movie_list: # 电影名称 title = movie.find('span', class_='title').text # 导演和主演 info = movie.find('div', class_='bd').p.text info = info.replace('\n', '').strip() director = info.split('\xa0\xa0\xa0')[0] actors = info.split('\xa0\xa0\xa0')[1].split('\xa0/\xa0') # 评分 rating = movie.find('span', class_='rating_num').text # 打印结果 print('电影名称:', title) print('导演:', director) print('主演:', actors) print('评分:', rating) print('---')
每一页数据提取:
import requests from bs4 import BeautifulSoup # 设置请求头,模拟浏览器访问 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36', } # 发送请求获取网页内容 for i in range(0, 10): url = 'https://movie.douban.com/top250?start=' + str(i * 25) response = requests.get(url, headers=headers,timeout=10) soup = BeautifulSoup(response.text, 'html.parser') # 定位电影列表 movie_list = soup.find('ol', class_='grid_view').find_all('li') for movie in movie_list: title = movie.find('span', class_='title').text # 导演和主演 info = movie.find('div', class_='bd').p.text.replace('\n', '').split('主演: ') if len(info) > 1: director = info[0].strip().split('导演: ')[-1] actor = info[-1].strip() else: director = '未知' actor = '未知' # 评分 rating = movie.find('span', class_='rating_num').text # 打印结果 print('电影名称:', title) print('导演:', director) print('主演:', actors) print('评分:', rating) print('---')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号