Hey Gift:二至三
Jeremy Sp @Track. 3: greedy
随机训一点思维题。打 * 的是自己做出来的。
*CF1796E Colored Subgraphs
对无根树进行某种树剖之后让最短的链最长。
考虑确定根之后我们怎么剖。当我们位于一个点上,这个点上有一条链决策走往哪个子树时,我们一定走往儿子子树内最浅的叶子最浅的那个儿子。显然如果不这样那我们的答案上界被定死了不超过这个叶子到当前点的距离,而这是显然不优于把这条链接过去的。
据此每个点向答案贡献它所有儿子子树的最浅叶子中的次浅者,还要加上最后根出发的那条链的长度。
换根用 multiset 维护即可。
CF755F PolandBall and Gifts
转成在环上选一些点,如果一条边两端都被选了就获得贡献,最大最小化贡献。
考虑最大化。我们肯定是贴着选,我们发现一个环选完了就能 \(n\) 个点转化成 \(n\) 条边的贡献,否则只能转化成 \(n-1\) 条边。所以答案是 \(k\) 还是 \(k-1\) 看的是能不能找出一堆环的环长和是 \(k\),是一个背包问题。
考虑最小化。我们肯定是先在每个环上都选一个独立集,然后奇环可以贡献出一个点选上之后答案 \(+1\),之后就只能 \(+2\) 了。直接贪心即可。
考虑优化那个背包。我们对置换环环长根号分治,大于根号直接是 01 背包,小于根号需要做多重背包。实际上根据某场核桃 T2(按度数根号分治,最后二项式反演那个题)的结论,我们可以把小于根号的部分直接二进制分组,之后还是单根号的——它们实际上满足 \(\sum\limits_{i=1}^{\sqrt n}ix_i=n\),可以证明 \(\sum \log(x_i)=\sqrt n\)。然后直接 bitset 优化,复杂度 \(\mathcal O(\frac{n\sqrt n}{w})\)。
*CF797F Mice and Holes
考虑老鼠之间不可能跨越匹配。
所以问题实际上总是只有两种形态。前面老鼠过多来匹配后面的洞,或者前面的洞过多来匹配后面的老鼠。两边都费用提前计算,dp 过去即可。需要写一个单调队列优化多重背包,时间复杂度 \(\mathcal O(nc)\)。所以为啥不保证 \(\sum c\)。
CF37E Trial for Chief
我觉得这种题难炸了……
操作到某个状态的题,考虑逆操作。可以发现逆操作就是选择一个极大连通块反色,不选极大显然不优。
把反色理解成和周围连在一起,那么我们的目标就是把所有连通块连同外框(因为有可能第一步是全选成 B)连在一起。考虑合并连通块之后连图,那么可以发现,我们操作一个点会把它和它的邻居全部合并在一起。于是我们的目的就变成花费最少的代价把整个图合并成一个点。
可以发现代价等于我们选一个点做根,从它出发最远的连通块的深度。枚举根跑最短路即可。
随后发现我们无需提前合并连通块,连成 \(0\) 费用的边即可。
*CF2119E And Constraint
先考虑如何满足 \(b_i\& b_{i+1}=a_i\)。可以发现这是在说 \(b_i\) 最后要包含 \(l_i=a_i|a_{i+1}\) 作为子集,并且和 \(l_{i-1},l_{i+1}\) 的交都为空。
可以发现这实际上是锁定了二进制下一些位的值,剩下的无所谓。我们考虑先找到最小的值 \(v_i\) 使得满足所有锁定的值且大于等于 \(b_i\)。
然后考虑我们可能要在这个基础上再加一些,只要不动被固定的位就没事。然后可以发现,我们的加法实际上是在不断地推平非固定位置的后缀,而我们推完之后在后面继续推是无意义的——不但会增多花费,而且给下一位限制更紧了。所以我们实际上每一个位置只有 \(\mathcal O(\log V)\) 种结果。
直接把所有结果预处理出来 dp 过去,复杂度 \(\mathcal O(n\log ^2V)\)。
*CF1656F Parametric MST
先考虑固定 \(t\) 的时候怎么求出 \(f(t)\)。显然对所有 \(a_i\gets a_i+t\) 之后一条边的贡献转成两个点的点权乘积,最后减掉 \(t^2(n-1)\) 即可。考虑类似 prim 的过程,从最大的正数出发,那么下一步一定会取最小的负数,之后负数全部挂在最大的正数上,正数全部挂在最小的负数上。只有正数,只有负数的情况是平凡的。
接下来我们大胆猜测整个 \(f\) 关于 \(t\) 是凸的,并且出现平台当且仅当在最大值处,直接二分然后就过了。时间复杂度 \(\mathcal O(n\log V)\)。
实际上有更加长脑子的做法。考虑对 \(a\) 排序,那么我们扫描 \(t\),会产生一段后缀是正数,一段前缀是负数。当所有数都是正数或所有数都是负数时,答案可以表示为一次函数,据此可以判定掉无解,顺便可以证明答案的 \(t\) 一定在 \([-a_n,-a_1]\) 之内。之后容易证明 \(t\) 一定取到一个 \(-a_i\) 处有最大值,全部 check 一遍即可,用前缀和优化 check 即可。时间复杂度 \(\mathcal O(n\log n)\)。
*CF1468L Prime Divisors Selection
纯种分讨题,不过还是有点意思的。
不妨重新考虑 \(A\)“理想”的充要条件。它等价于不存在一个不友好的 \(P\),也即不存在一个 \(P\) 使得里面有只出现一次的质数。容易发现,如果我们枚举这个质数 \(p\),\(A\) 当中不存在两个数 \(p^i,p^j\),则我们一定至少可以使得 \(p\) 只出现恰好一次(可能还有别的质数只出现一次,但无关紧要了)。
所以我们希望找出 \(k\) 个数,使得里面出现的每个质数 \(p\) 都存在两个数 \(p^i,p^j\)。
不妨把数分为质数幂和其他数。考虑所有满足整个序列中至少存在两个数 \(p^i,p^j\) 的质数 \(p\) 构成的集合 \(S\),集合 \(S\) 中所有质数的质数幂的总个数 \(c\)。
- \(k\ge c\),我们先选满所有 \(c\) 个数,然后在满足质数只包含 \(S\) 中质数的其他数中选择 \(k-c\) 个。
- \(k<c\):
- 存在一个 \(q\in S\) 有大于 \(2\) 个质数幂。对于 \(k\) 是奇数,我们先选 \(3\) 个 \(q^i\),然后往里面两个两个塞,塞完了就能变成可以一个一个塞了;对于 \(k\) 是偶数,我们就往里面两个两个塞,塞完了也能变成一个一个塞。总之可以解决所有 \(k>1\)。
- 所有 \(q\in S\) 都恰有两个 \(2\) 个质数幂。对于 \(k\) 是偶数问题是简单的。\(k\) 是奇数比较麻烦的是我们只能选一部分 \(p\in S\),然后必须在外面选奇数个。考虑在外面选 \(>1\) 个的构造是无意义的,外面可以退掉两个多选一个 \(p\)。于是只需枚举在外面选的数,check 至少要选多少个 \(p\in S\) 即可。
于是考虑实现细节,主要的问题在于分类。考虑 \(3\) 次方及以上的可以哈希表预处理之,主要考虑平方项。我们只需要 check 如果存在 \(x,x^2\) 则它们是否是质数幂。显然此时 \(x\le 10^9\),所以我们挂到 \(x\) 上判断它是否是质数即可,至多只有 \(n\) 项需要 check。
总时间复杂度 \(\mathcal O(n^2+n\sqrt[4]{V})\)。
CF1658F Juju and Binary String
不是,我猜到了答案 \(\le 2\),猜到答案 \(=2\) 是一个前缀一个后缀,结果我怎么没一眼看出来样例二的构造啊?(实际上是取 \([1,1]\) 和 \([4,8]\)。)
这种看上去不太可做的构造性问题,一定要习惯性考虑答案的上界。比如构造一个操作序列,构造一个划分方案,构造一个括号串等问题都遇到过很多次。
考虑证明答案要么是一个区间,要么是一段前缀一段后缀。实际上这等价于在环上取一个长度为 \(m\) 的区间,使得 \(\texttt{1}\) 的数量等于我们想要的值 \(C\)。
Proof.
假设整个环上所有长度为 \(m\) 的区间中的 \(\texttt{1}\) 的个数都大于 \(C\) 或者都小于 \(C\),那么不可能使得整个串当中 \(\texttt{1}\) 的数量是 \(\frac{Cn}{m}\),考虑 \(\texttt{1}\) 的密度或者类似括号串进行 \(A,-B\) 的赋值均可。
所以整个环上一定存在一个长度为 \(m\) 的区间中 \(\texttt{1}\) 的个数大于 \(C\) 一个小于 \(C\)。考虑每次将区间移动一位 \(\texttt{1}\) 的数量恰好变化 \([-1,1]\),根据介值定理,我们一定可以找到一个符合条件的环上的区间。
剩下的就是 trivial 的工作了。
P14364 [CSP-S 2025] 员工招聘 / employ
场上没时间了。感觉这个技巧是见过的。
\(\forall i,s_i=1\) 有一个按照 \(c\) 插入的做法,是我的考场做法,应该是对的。然而很遗憾该做法需要用到插入 \(c_x=i\) 的人的时候只在乎 \(c<i\) 的人的性质,而这在 \(\exist i,s_i=0\) 的时候是错误的。不过据此可以启发出正解,这都是后话了。
直接考虑 dp,设 \(f_{i,j}\) 表示前 \(i\) 天里面已经有 \(j\) 个人倒闭了,考虑我们接下来决策这一天要填什么人的时候非常关心他是 \(c_x\le j\) 的人还是 \(c_x>j\) 的人。虽然这两种人对于这个位置来说都是本质相同的,但是显然 \(c_x\le j\) 的人已经全部没有区别了,而 \(c_x>j\) 的人在之后会区分出来区别。所以我们简单地想应该加一维 \(k\),表示 \(c_x>j\) 的人在前面用了多少个。
考虑转移。
设 \(s_i=1\),那么:
- 填一个 \(c_x>j\) 的人,从 \(f_{i-1,j,k}\) 直接转移到 \(f_{i,j,k+1}\)。这里就是这个题最重要的技巧,我们暂时不在这里钦定这些 \(c_x>j\) 的人是谁,而是延后钦定 / 费用延后计算。
- 填一个 \(c_x\le j\) 的人,从 \(f_{i-1,j,k}\) 转移到 \(f_{i,j+1,p}\),意味着我们在前面填了 \(k-p\) 个 \(c_x=j+1\) 的人,组合系数是两半:选一个 \(c_x\le j\) 的人出来,从 \(c_x=j+1\) 的人里面选 \(k-p\) 个出来填在前面的位置。
设 \(s_i=0\),那么:
无论填的是怎样的人,我们都要从 \(f_{i-1,j,k}\) 转移到 \(f_{i,j+1,p}\)。但是两边的组合系数是不一样的。具体和 \(s_i=1\) 的时候类似。
注意到对于每一对 \(i,k\),\(j,p\) 的枚举量之和是 \(\mathcal O(n)\) 的。所以最后复杂度是 \(\mathcal O(n^3)\)。
单峰
考虑直接排序之后调整,可以发现我们可以拆散一整个连续段插到后面的连续段的后方去,每拆散一个完整的连续段可以让答案变大 \(1\)。
于是可以直接写出一个 dp,获得 \(70\) 分。
这个 dp 无法优化。我们容易猜到,这个题应该是可以反悔贪心的。
充分发扬人类智慧,考虑如果我们正着做,对未来决策当前的连续段是否拆散是比较困难的,所以我们倒着做。那么问题可以如下贪心地刻画:
- 维护一个计数器 \(c\),初始为 \(0\)。
- 每个长度为 \(l\) 的连续段有两种可能:\(c\gets c+1\);\(c\ge l\) 的情况下,\(c\gets c-l\),答案增大 \(1\)。
我们希望第二种决策发生的次数尽量多。这就是一个比较板的反悔贪心了。考虑如果当前的 \(c\ge l\),那么我们直接操作。否则我们可能要回退前面的一个答案增大 \(1\),使得当前的 \(c\) 更大,而答案不改变。
猫与神秘打野点
先考虑 \(1\) 的部分怎么做。
一个简洁的想法是考虑 \(f_i\) 表示走到 \(i\) 的期望次数,最终我们需要对所有 \(1\) 的位置求 \(\sum f_i\)。无疑这是对的,但是很遗憾因为没有任何一个点的 \(f\) 可以预先确定所以无法转到线性树上递推。
考虑 \(i=\sum 1\) 展开。实际上我们也可以求 \(f_i\) 表示从 \(i\) 开始到某个叶子结束经过的 \(1\) 的期望数量,最终只需求得 \(f_1\) 即可。这样我们就有:
考虑用 CF1823F Random Walk 转化为线性树上递推即可。
然后考虑 \(0\) 怎么做。考虑 \(t_i\) 表示经过了 \(i\) 的概率,我们只需求 \(\sum t_i\)。那么考虑经过 \(i\) 必须经过 \(fa_i\),我们用 \(fa_i\) 和它递推。不妨设 \(g_i\) 表示站在 \(fa_i\) 走到 \(i\) 的概率,\(h_i\) 表示站在 \(i\) 走到 \(fa_i\) 的概率。
考虑递推 \(h_v\),直接移项从下往上推就可以了。叶子的 \(h_i=0\)。
考虑递推 \(g_u\),直接移项从上往下推就可以了。根的 \(g_1=0\)。
考虑递推 \(t_u\),直接从上往下推就可以了。根的 \(t_1=1\)。
T3. 辰与泫
我真的想不清楚这种大型树形 dp 啊。加训 dp 之。/ng
考虑类似 CSP T4 的套路,我们设 \(f_{i,j}\) 表示 \(i\) 子树内留出 \(j\) 个空位给 \(i\) 子树外落下来的球的方案数,那 \(j\) 个空位我们等待遇到那些球时再确定。注意到我们只要知道 \(j\) 个空位的集合就可以唯一确定这些位置的相对顺序,所以我们钦定时只需确定落球的球编号顺序即可。
考虑转移。对于叶子来说情况是平凡的。一个儿子的情况和两个儿子时类似。
对于两个儿子的情况,我们设 \(i\) 是其父亲的左儿子,\(b_i\) 表示 \(i\) 子树中只考虑 \(i\) 字数中球的情况下的空位数量。我们考虑当前节点上的 \(a_i\) 个球中取 \(k\) 个球落向左侧(无球的节点假设 \(a_i=0\)),剩下的 \(a_i-k\) 个球落向右侧,那么这些球落下之后现有的留出的 \(j\) 个空位中,\(p=\min(j,b_l-k)\) 个会在左侧,剩下的 \(j-p\) 个会在右侧或者点 \(i\) 上。于是我们可以写出转移:
注意这里需要使用排列数。虽然这 \(j\) 个空位的顺序是固定的,但是来自祖先的球之间的顺序是不确定的,所以实际上这些球还是可以每一个独立地选择自己喜欢的位置,剩下的位置可以留给更往上的球来占据。
注意这里有一个调整量 \(C\)。\(C=1\) 时意味着刚好左右儿子都填满,有一个球要放在 \(i\) 上。一个儿子的情况也需要考虑调整量,需要注意实现细节。
算答案的时候考虑钦定 \(1\) 属于左儿子即可。反正我们最后需要的是 \(f_{1,0}\),不管称呼 \(1\) 是谁,两边都总会抵消掉。
QOJ6608. Descent of Dragons
01 转化还有人类吗。
考虑维护 \(5\times 10^5\) 个 01 序列,第 \(i\) 个 01 序列的位置 \(j\) 表示该位置上的数是否 \(\ge i\)。这样查询时我们只需二分答案即可。
考虑怎么维护操作。可以发现,在我们进行操作时,第 \(x\) 个 01 序列的区间 \([l,r]\) 一定是第 \(x+1\) 个 01 序列该区间的超集,超出去的那部分就是 \(=x\) 的数。所以我们强行把当前的这个区间的信息复制到第 \(x+1\) 个序列上即可,这显然是使用可持久化线段树实现。
P3580 [POI 2014] ZAL-Freight
我有一个不一样的做法
考虑 $f_{i,j}$ 表示前 $i$ 辆车发车之后有 $j$ 辆未返回,且最后一刻是发车的最短时间。- 从 \(f_{i-1,j}\) 转移,发第 \(i\) 辆车。
- 从 \(f_{i-1,k},k>j\) 转移,先返回 \(k-j\) 辆车,然后发第 \(i\) 辆车。
写出 \(\mathcal O(n^3)\) dp 之后可以把状态移项成 \(f_{i,j}\gets f_{i,j}+j\)。
我们充分发扬人类智慧,只给 \(j=1\) 转移 \(k>1\)。事实上这就是在拟合下面的结论。
这样就是 \(\mathcal O(n^2)\) 了。但是式子里面还有和 \(t_i+s+j\) 取 \(\max\),这是复杂度瓶颈。我们充分发扬人类智慧,只给后缀取 \(\max\)。事实上这也是在拟合正解用于维护的一个结论。
然后就可以用 deque 维护珂朵莉树整体 dp。空间略卡。时间复杂度 \(\mathcal O(n\log n)\)。
首先有一个很强的结论。如果我们发车了一堆列车,那么我们之后会把这些列车全部发回,而不是留到之后和之后的列车一起发回。感性理解一下,在这里一起发回只需要 \(1\) 的代价,而如果和之后的列车一起发回不会比这里更少,而且还可能导致后面的列车等待最小发车时间。
据此设 \(f_i\) 表示 \([1,i]\) 全部发车并返回的最小总时间,我们分段 dp 它,找到一个点 \(j\),从 \(f_j\) 开始发车 \((j,i]\) 中的所有列车再返回转移而来。时间复杂度 \(\mathcal O(n^2)\)。
转移里面有两坨 \(\max\),拆开之后可以发现一边占了一个前缀,另一边占了一个后缀,分别转移。用单调队列和双指针均可。
P6287 [COCI 2016/2017 #1] Mag
分析性质和调整法还在追我。
Lemma. 一定不会选 \(>2\) 的数。
Proof. 假设答案中包含一个 \(3\),我们来证明退掉它一定是优的。假设我们退掉它损失的全是 \(1\),这样显然是最劣的,假设算上 \(3\) 退掉了 \(t\ge 1\) 个数,那么:\[\frac{x}{y}>\frac{x}{3(y-t)} \]对 \(t<\frac{2y}{3}\) 都成立。显然我们存在一种退掉不超过 \(\frac{y}{2}\) 个数的方法来退掉这个 \(3\),所以一定成立。
Lemma. 至多选一个 \(=2\) 的数。
Proof. 类似的,假设答案中包含超过一个个 \(2\),我们来证明退掉其中至少一个一定是优的。类似上面的证法,我们考虑不等式:\[\frac{x}{y}>\frac{x}{2(y-t)} \]对 \(t<\frac{y}{2}\) 都成立。假设序列里面有至少 \(3\) 个 \(2\),那么必然删掉某一个 \(2\) 只需要删严格少于一半的数。如果是序列里面有恰好 \(2\) 个 \(2\),那么只有偶数要删恰好一半,而这是不劣的。我们据此还很容易发现选一个 \(2\) 时唯一的特殊情况是一个 \(2\) 两边挂两条等长的 \(1\) 的链,此时这个 \(2\) 无法以更优的方式删掉。
根据上述两条结论,我们只需求出每个点向上和向下的最长全 \(1\) 链就能解决整个问题了。这是一个简单的树形 dp。
和声的秘密
先拿一个放缩把 \(m\) 的上界搓出来。
考虑这 \(2m\) 个数的和,容易得到:
之后显然按照 \(n\bmod 5\) 分类去取上界。下面给出一种构造:
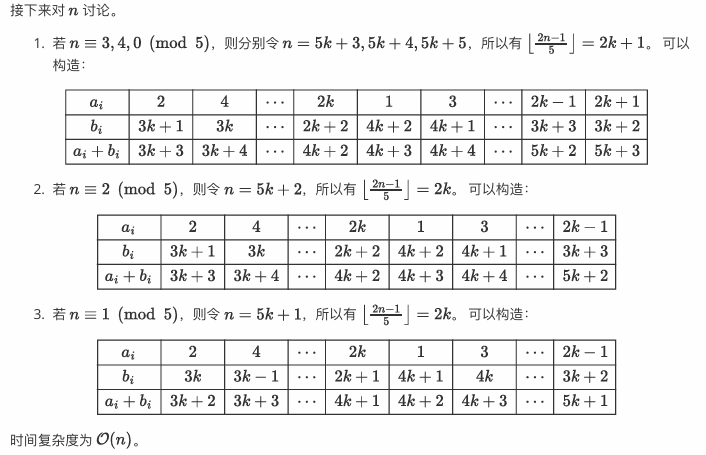
P3554 [POI 2013] LUK-Triumphal arch
为什么我的思路还是那么一条路走到黑。
考虑这个题最麻烦的就是 A 的一次操作之后多余的点去哪里了,然后这会影响 B 的决策。我们发现,如果我们在点 \(u\) 上可以选择 \(j\) 个点,我们一定会选择一个以 \(u\) 为根的连通块,然后我们按照每个儿子中的连通块大小递归到子问题,儿子的连通块选法也是在上面的基础上的。于是我们可以写出一个 \(\mathcal O(n^2)\) 的树形背包 dp 这个问题,设 \(f_{i,j}\) 表示以 \(i\) 为根,初始有一个包含根的大小为 \(j\) 的连通块的最小的 \(k\)。我们考虑把这个连通块分配给每个儿子来递归子问题:
当然有可能这个点的连通块是在这个点上选出来的,所以:
可以获得 \(50\) 分。
然后我们发现这个背包强得没法优化,\(k\) 的值和连通块大小两个维度都要存。然而我们实际上可以确定 \(k\)。
考虑二分答案,那么我们可以不用管 \(k\) 的事了。\(f_i\) 表示 \(i\) 点上连通块至少要有多大才能让 \(k\le mid\),那么:
其中叶子的 \(f\) 为 \(1\)。
P7154 [USACO20DEC] Sleeping Cows P
做一道不会一道,我做啥啊。涉及两个序列大小关系的贡献问题,一定要考虑归并在一起之后用一个匹配 dp 算完。
考虑极大匹配的性质:
- 如果里面存在一只奶牛 \(s_i\) 没有进入匹配,那么所有 \(t_j\ge s_i\) 的牛棚 \(j\) 都必须匹配干净。
容易发现这是充分必要的。
考虑这样我们可以得出一个 \(\mathcal O(n^3)\) 的做法,我们按照 \(s_i\) 从小到大枚举第一头不进入匹配的奶牛,那么之后有一个奶牛的前缀和一个牛棚的后缀需要全选,剩下的随便。
考虑如何 dp 这个东西,我们要写出一个能够维护牛和牛棚的必选的状态(有一种设计状态的思路是维护前面的匹配数来确定这里有多少牛/牛棚可匹配,这维护不了必选的要求)。不妨把牛棚序列和牛序列压在一起,值相同就把牛棚放在牛后面,那么实际上是后面的牛棚可以匹配前面的牛。我们使用 \(f_{i,j}\) 表示前 \(i\) 个位置考虑完,还有 \(j\) 头牛没有找到棚。那么对于必选的奶牛来说,我们转移到 \(j+1\) 让它进入备选集合;对于必选的牛棚来说,我们从 \(j+1\) 转移表示必选这个棚即可。
变为正确复杂度也是简单的。从小到大第一头不进入匹配的奶牛的出现显然也可以压在状态里,因为这样的奶牛只有一头,所以它是否出现我们可以用一个 \(0/1\) 来记录。直接 dp 即可。
路径
我靠,为什么我不会这个题啊?
考虑有超过两个颜色的边一定可以选择和两侧不一样的那种颜色,所以一定有贡献。那么我们可以把它变成一种没有出现过的颜色,这样相当于所有边都只有至多两种颜色了。
考虑这个显然可以 dp,\(f_{i,0/1}\) 表示从 \(i\) 开始,最后一条边的颜色是第一种还是第二种的答案。
考虑转成倍增 ddp,\(f_{i,j,0/1,0/1}\) 表示从 \(i\) 开始,向上 \(2^j\) 条边,第一条边和最后一条边的颜色是第一种还是第二种的答案。倍增合并之即可。
树
刻画错了。
肯定先考虑不带修怎么做。显然问题可以转化成选择一条最长的路径,使得路径的两端都是大小至少为 \(k\) 的子树。
关于子树大小的问题我们考虑直接拿重心当根,然后就可以发现我们选择的这条路径放在新树上不可能是祖先-儿子关系并且不包含重心的——否则我们可以向重心扩展,不影响合法性。
然后可以发现我们实际上可以选的点构成一个包含根的连通块,包含所有 \(siz_i\ge k\) 的点,这里面任意两个点都可以构成合法的路径。
考虑按 \(k\) 离线,那么不带修的情况实际上就是动态加点维护点集直径,经典地维护即可。
带修的情况,按照修改的边掰成两半分别求点集直径即可。需要用线段树维护直径。
CF1996G Penacony
我为啥菜成这样。不会做这个题。
考虑断掉一条边之后,所有人选择哪个半环就固定下来了。据此我们可以枚举断边获得一个扫描线做法,但是这太暴力了。
我们考虑断掉一条边之后还有哪些边是可以断的。假设我们可以得知每条边断完之后所有人选择的半环的状态 \(S\),那么当且仅当所有 \(S\) 相同的边可以一起断掉,证明显然。
所以如果我们可以为每条边处理出来断掉它之后每个人选择的半环状态并合并等价类,我们就可以直接贪心选出权重最大的那个等价类断掉。显然可以用异或哈希来完成。
P4657 [CEOI 2017] Chase
刻画不好,被恶心吐了。
考虑先刻画一波答案,直接硬考虑他的流程太恶心了。容易发现,如果我们取起点作为树根,那么实际上选取一个点对答案产生的贡献就是其所有儿子节点的铁球数量和——所有不在路径上的铁球会飞过来阻拦追逐者,而下一步路径上的球也会飞过来阻拦追逐者并导致逃亡者走到下一步恰好不产生负贡献,所以答案就是所有选择的点的儿子的铁球数量之和。
现在考虑回到以 \(1\) 为根进行树形 dp。我们显然维护两个量来合成路径:\(f_{i,j,0/1}\) 表示从下往上,走到第 \(i\) 个点,第 \(i\) 个点是否选择的最大答案;\(g_{i,j,0/1}\) 表示从上往下,从第 \(i\) 个点出发,第 \(i\) 个点是否选择的最大答案。
那么转移和合并都是轻易的。
QOJ8088. Eevee
和妙蛙种子在一场比赛里。dp 领域大神吗?
我们可以轻易对原问题写出一个 \(\mathcal O(n^2k^2)\) 的做法,这个做法我觉得相当 classical:考虑对每个区间都暴力做,那么设 \(f_i\) 表示 \(i\) 是第一种连续出现的数,从完全在它前面(被 \(k\) 维偏序)的数 \(j\) 容斥地扣掉 \(f_j\) 乘上中间的多重集排列数即可。使用一些预处理手法即可做到 \(\mathcal O(n^2k^2)\)。
然后我们发现复杂度瓶颈实际上是每次都要 \(\mathcal O(n)\) 地找到被它完全偏序的那些数来参与容斥。注意读题,本题数据随机,所以直觉上不会有很多数构成严格偏序关系。事实上总共大约是 \(\mathcal O(nk^2)\) 的。
接下来事情就非常容易了,我们只需强行随着区间扫描的过程维护每个数完全偏序的数的集合即可。\(\mathcal O(nk^2\log)\) 是简单的,但是需要注意常数,set 的 log 过不了但排序可以。也可以用显然的离线手法做到 \(\mathcal O(nk^2)\),但是我太懒了。最终总时间复杂度 \(\mathcal O(n^2k+nk^2)\)。
CF1499F Diameter Cuts
虽然非常简单但是害怕自己搞忘所以还是写一下…… 上次就忘记了。
考虑一个直接的想法是 \(f_{i,j,d}\) 表示 \(i\) 子树内到根的最长链长度为 \(j\),直径为 \(d\) 的断边方案数,本质上是把求直径那个 dp 给 dp of dp 进状态了。然而这个显然过不了,因为状态就是 \(\mathcal O(n^3)\) 的。
考虑我们把直径扔进状态的主要目的是为了避免直径长度超过 \(k\)。但实际上,我们处理限制可以下放在状态里限制,也可以下放到转移里限制。可以发现这个限制恰好是可以通过转移限制的,我们在转移直径那个 dp 的时候需要把子树一个一个接上来,取最大的两条最长链接在一起,而我们转移这个外层 dp 也是一个子树一个子树接上来,于是我们直接要求最长链长度之和 \(>k\) 不转移即可。这样就能省掉最后一维状态,转移复杂度付诸树形背包。
P9192 [USACO23OPEN] Pareidolia P
考虑 ddp,\(f_{i,j}\) 表示前 \(i\) 位匹配完,有多少个后缀现在匹配到第 \(j\) 位。同时设 \(g_i\) 表示前 \(i\) 位的答案。显然 \(f_i\) 从 \(f_{i-1}\) 转移而来,注意满配和失配的都需要跳一下 border,不过 bessie 这个串性质比较好没这么麻烦的东西。\(g_i\) 从 \(f_{i-1}\) 和 \(g_{i-1}\) 转移而来。
注意转移细节。特别是从 \(f_{i-1}\) 把满配的串转移到 \(g_i\) 的时候要乘一下 \(n-i+1\),因为所有以这些后缀作为前缀的子串都会发生这样的匹配。
P4587 [FJOI2016] 神秘数
假设我们已经给 \(a:[l,r]\) 排好序了,考虑扩展可以凑出的前缀。一开始是 \(r=0\)。
- 如果 \(a_i\le r+1\),那么我们显然一定可以多凑出 \((r,r+a_i]\) 中的数,于是 \(r\gets r+a_i\)。
- 如果 \(a_i>r+1\),那么 \(r+1\) 凑不出来,并且之后也凑不出来了。
所以我们的目标就是找到这个凑不出来的分界线。
感受上这里面应该有一个 \(\mathcal O(\log)\) 的东西,考虑优化暴力。不妨设我们现在加入了 \([0,k]\) 中的数,前缀来到了 \([0,r]\),那么我们这一步可以加入 \((k,r+1]\) 中的数。可以发现如果接下来两次加数都成功,那么两轮之后 \(k\) 和 \(r\) 一定会翻倍。所以加数的次数是 \(\mathcal O(\log V)\) 的。
用主席树来维护加数即可。时间复杂度 2log。
但是这样太暴力了不优美,我们考虑更强的结论:
Lemma. 把值域分割成 \([2^k,2^{k+1})\),那么每一块值域要么全部加入要么全部不加入。
Proof. 设 \(x\) 为某块当中最小的数,那么:
- 如果 \(x>r+1\),那么显然这一块和后面的块都废了。
- 如果 \(x\le r+1\),那么 \(r\gets r+x\),因为 \(r\ge x-1,x\ge 2^k\),所以新的 \(r\ge 2^{k+1}-1\),这一整块都能塞进去了。
据此我们可以有另外一种 2log,查询每一块的和是一个简单二维数点。但是这个结论这么强,只有 \(\mathcal O(\log)\) 块,强行二维数点 2log 也太慢了。
考虑把每一块离线下来,那么对于每个还没有确定答案的询问来说就是一个 RMQ 和求区间和。后者用前缀和即可 \(\mathcal O(n)-\mathcal O(1)\)。
RMQ 直接用 ST 表。但是实现上注意不要对 \(\log\) 块都 \(\mathcal O(n\log n)\) 地 ST 表,我们只对在这一块中的元素做 ST 表。这样所有块中需要 ST 表的元素总和就是 \(\mathcal O(n)\) 的。
总时间复杂度 \(\mathcal O((n+q)\log V+n\log n)\)。
CF1175F The Number of Subpermutations
排列的最大值和长度是相等的,这是一个非常关键的观察。
考虑枚举最大值,那么实际上也确定了长度。确定长度的好处是枚举一个端点之后我们可以直接确定整个区间。这启发我们在笛卡尔树上启发式分裂来枚举一个端点。
考虑确定整个区间之后怎么判定它是一个排列,毕竟我们现在只知道它的长度和最大值相当。当然可以用异或哈希的方式来判断,确定性的办法是判断里面每个元素是否都恰好出现一次,显然我们可以对每个 \(r\) 维护出 \(lim_r=\max\limits_{i=1}^n lst_i+1\) 来判断,只有 \(lim_r\le l\) 的左端点是合法的。
这样做是 \(\mathcal O(n\log n)\) 的,实际上比较暴力。
考虑我们问题的本质是,如果能一边维护最大值一边扫端点就好了,这样就能直接确定区间然后用异或哈希 check。我们仍然考虑分治,但我们这次按照 \(1\) 的位置分治——任何一个排列都必须包含恰好一个 \(1\),我们相当于钦定到这个 \(1\) 上来数,而对于每个 \(1\) 来说,跨越它的合法排列的右端点有且只有它到它右边那个 \(1\) 中间的点。最后总和是 \(\mathcal O(n)\) 的!
考虑这样就有端点了,然而没有最大值。我们不妨钦定最大值也在右侧,不在右侧的不合法情况显然无法被 check 成排列所以数不到。这样只需反着再做一遍即可。
P7984 [USACO21DEC] Tickets P
考虑暴力建图,建图的事我们可以不用管,这个一看就能线段树优化建图。主要考虑怎么算答案。
显然可以算两个数组 \(f_{1,i},f_{n,i}\),表示分别从 \(1,n\) 出发到每个点的最短路。然后考虑怎么算这个可以同时走到 \(1,n\) 的最短路。显然这个长成一个分岔路口状物,我们先从 \(i\) 走到一个点,然后在那个点上分岔。
我们直接令 \(g_i=f_{1,i}+f_{n,i}\) 钦定这个点上分岔,然后用 \(g\) 再推一遍最短路即可。考虑到不合法不优,正确性可以保证。
P3449 [POI 2006] PAL-Palindromes
啥时候能好好读题。没读到初始每个串都回文弄出来一个好麻烦的做法。
考虑直接哈希,然后判定 \(s,t\) 可以接在一起变成回文串的条件,显然是:
开个哈希表即可。
CF1693D Decinc Dividing
打开这题直接看了题解,因为 Gellyfish 在南京讲了这个题,是个离谱的东西。没想到是有正常人类做法的(见多头题解)。不过这题带来一个非常有用的启发,这种划分单调递增和单调递减序列的题可以考虑状态和转移的实际数量(另一个比较厉害的题是 CF1773L Lisa's Sequences)。
考虑枚举 \(l,r\),判定它是否是 Decinc 的。很明显我们有一个线性的 dp:\(f_{i,0}\) 表示当前这一位加入递增序列,递减序列最后一位的最大值;\(f_{i,1}\) 反之亦然。初始我们让 \(f_{1,0}=+\infty\),\(f_{1,1}=-\infty\),剩下的反过来,最后观察 \(f_{r,0}\ne -\infty\) 或者 \(f_{r,1}\ne +\infty\) 即可。
进一步地,我们可以扫描 \(r\) 顺便往后 dp 做到 \(\mathcal O(n^2)\)。
进一步地,我们其实可以把 \(l\) 倒着扫,这样是只增加的,我们可以考虑每次都用全新的信息去更新后面的一串 dp 值,如果更新到不再合法的 \(f_i\) 或者和之前一样的 \(f_i\) 就停止向后。看上去这只是常数优化,然而这是对的。
Lemma. 每个 \(f_i\) 至多被更新 \(7\) 次。
Proof.
在 \(i\) 之前取最大的 \(j\) 使得 \(a_j>a_{j+1}\),那么这两个数无法被同时选进递增序列里,而后面又是一串递增的数,分类讨论容易得知 \(f_{i,0}\) 要么是 \(a_j\) 要么是 \(a_{j+1}\),要么就是无解的 \(-\infty\)。特别地,如果找不到这个 \(j\),也有可能是 \(+\infty\)。
考虑到 \(f_{i,1}\) 是类似的。那么每次更新到 \(f_i\) 必然是因为状态有所变化,而每个 \(f_{i,0}\) 不可能随着前面数的增加反而变大(\(f_{i,1}\) 同理),所以加起来至多变化 \(7\) 次。
于是我们在 \(\mathcal O(n)\) 的时间复杂度解决了这道题。不过其实能想到这个复杂度证明,正解那个充要条件的一半都出来了。
CF1466G Song of the Sirens
显然这个东西可以类似一个分治的搞法,我们考虑在前 \(k\) 位里面匹配跨越型的贡献,然后乘上 \(2^{k-i}\) 贡献到答案就完事了。
考虑自从第 \(\mathcal O(\log |w|)\) 项开始,中间那个 \(t_i\) 周围 \(\pm |w|\) 位都是长得一模一样的,因为这样往两边插的构造方式不再能触及到之后新添加的部分了。这要求我们当前串两侧的串长超过了 \(|w|\le 10^6\),所以我们不妨取第 \(21\) 项及之前。第 \(22\) 项开始就看成两边不会再变化了,只保留中间 \(2|w|\) 位。
于是我们总共只需要考虑 \(21+26=47\) 个串作为母串。因为显然第 \(22\) 项之后的串可以按照中心字母压在一起算。
不妨枚举当前串当中每个位置作为跨越点,再枚举对应的母串,那么匹配是一个简单的哈希 实际上应该写 KMP。匹配上再乘一下系数就好了。
注意一下这个不要真的扩展 \(21\) 个串,因为 \(s_0\) 也是有长度的。这个 \(\log\) 其实应该是 \(\mathcal O(\log \frac{|w|}{|s_0|})\)。
最恶心的是这个题还卡空间卡得不是人,我们必须离线下来对 \(47\) 个串逐串处理,然后精细一下数组大小。

P9019 [USACO23JAN] Tractor Paths P
这个题做法很多,比较直观的做法是建出贪心树对其进行观察来解决第二问。
考虑先给所有区间排序并从左往右给予编号。
第一问是简单的,容易发现我们从 \(a\) 出发必然会走当前可以走到的所有区间中 \(r\) 最大的那个,于是每个区间 \(i\) 连向和自己相交的 \(r\) 最大的区间 \(f_i=j\),这样会构成一个内向树,我们直接在这个内向树上倍增即可。
第二问考虑直接在我们的贪心树上刻画它。不妨先考虑贪心树的性质。
我们容易发现,贪心树上每个点的深度实际上描述了从这个区间开始跳到 \(n\) 的最短距离。显然越往前的区间这个距离是越远的,于是我们容易发现这棵树上每一层的区间是编号连续的。进一步地,我们可以发现每个点的儿子一定也是编号连续的。
现在考虑在这棵性质美好的树上刻画移动。显然,从每个区间 \(i\) 出发可以抵达的点一定是 \((i,f_i]\) 中的所有区间。我们假设树的每一层也是按照点从小到大排好序的,那么实际上我们是可以从点 \(i\) 跳到它右侧的每一个点,以及上一层中 \(f_i\) 及其左侧的每一个点(左上方)。
我们考虑 \(a\to b\) 的过程。实际上我们会从 \(a\) 开始一直跳祖先,直到某个点 \(t\) 满足向左上跳一步或向右跳一步就可以抵达 \(b\)。不妨对 \(t\) 的位置分类讨论:
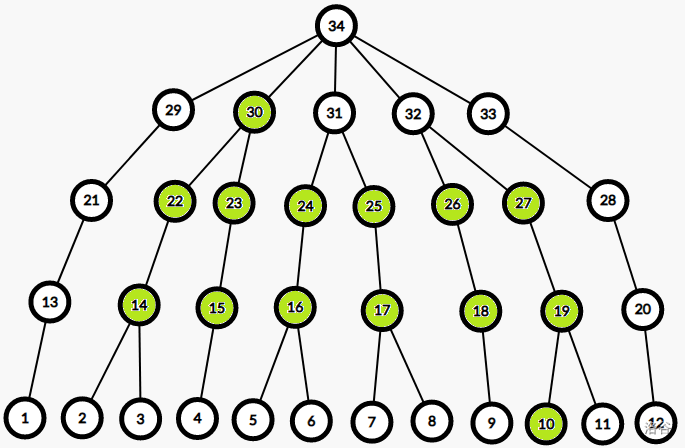
- 如果 \(b\) 在 \(t\) 的左上方,那么我们每一步都必须让深度减小 \(1\),否则就会浪费步数导致不是最短路。这意味着我们需要每一步都向左上跳,于是可以到达的点大概长这样(下图中 \(a=10,b=30,t=27\)):
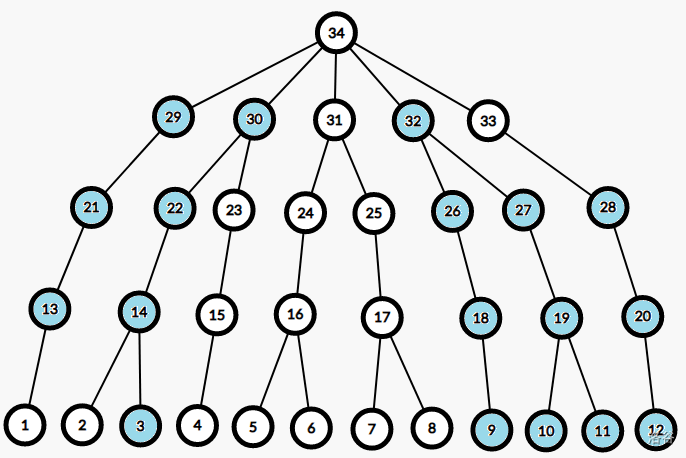
不难发现这实际上是 \(b\) 到 \(f_t\) 之间所有子树在某个深度范围内的所有点。于是容易把问题转到二维数点。 - 如果 \(b\) 在 \(t\) 的右侧,那么我们有且仅有恰好一步需要向右跳。容易发现把这一步向右跳留到中间用没有意义,我们要么先向右跳然后一直向左上跳到达 \(t\),要么先一直向左上跳然后向右跳到达 \(t\),所有可以抵达的点都能用两种方式其一获得,没有必要在中间向右跳。于是可以到达的点大概长这样(下图中 \(a=3,b=32,t=30\)):
不难发现这实际上也是两个类似的二维数点。
实际上更好写的数点方式是按照编号和 dfn 序做维度,不过这个刻画太简洁了怎么写都可以。
至此,我们在 \(\mathcal O((n+q)\log n)\) 的时间内解决了本题。我感觉我看到这个实体化的贪心树就像我第一次见到组合数问题上平面去刻画。
11.16 T3 - 双端队列(deque)
考虑先二分答案,\(f_{i,j,0/1}\) 表示前 \(i\) 个数插完,当前数插在左边还是右边,当前数对面的值位于 \(j\) 是否可行。这个 dp 把 \(j\gets a_j\) 下放到值域上之后可以整体 dp,只有继承、查询区间中是否有 \(1\)、单点修改三种。
强行拿主席树写即可做到 \(\mathcal O(n\log n\log V)\) 并输出方案。
但是我们发现主席树存所有版本太愚蠢了,常数非常大。可以发现,我们实际上只需要特别存 \(f_{i,i-1,0/1}\) 这一种状态的转移,因为其它的状态一定是来自继承的,不需要存转移。于是只有 \(\mathcal O(n)\) 个转移需要存,主席树可以不要了改成线段树。
然而常数还是很大。可以发现我们的线段树做的事情太弱了,我们只是在单点修改查询区间是否有 \(1\)。显然我们可以用 set 存所有值为 \(1\) 的下标位置来取代线段树,于是常数减小了不少,可以随意地通过了。
CF1632E2 Distance Tree (hard version)
精巧的艺术品……
首先你要会做 \(n\le 3000\) 的 E1。E1 只有一个结论,就是我们选择的这条加边一定是 \((1,u)\) 之间的,容易通过调整证明。于是我们枚举 \(u\),那么每个点对 \(x\) 的贡献是一个 \(ans_x\stackrel{\min}{\gets}\max\limits_{v=1}^n\min(dis_{u,v}+x,dis_{1,v})\)。考虑优化内层 \(\max\),可以发现按照 \(dis_{1,v}-dis_{u,v}\) 排序之后,每个 \(x\) 的两种贡献分别是前缀和后缀,可以扫描线处理。时间复杂度 \(\mathcal O(n^2\log n)\)。
发现最大值最小,考虑对每个 \(x\) 二分答案。于是我们需要判定 \(\exist u,\min(dis_{u,v}+x,dis_{1,v})\le mid\)。考虑这意味着对于 \(dis_{1,v}>mid\) 的点来说,它们的 \((mid-x)\)-邻域有至少一个点的交。在树上这等价于这些点的直径不超过 \(2(mid-x)\)。于是我们希望对于每个 \(mid\) 预处理 \(dis_{1,v}>mid\) 的点的点集直径,这显然可以通过动态维护直径完成。总时间复杂度 \(\mathcal O(n\log n)\)。
P7152 [USACO20DEC] Bovine Genetics G
我又读错题了。
考虑 dp 给出的串中反转部分的划分方式。显然,一种合法的划分方式恰好对应一个原串,而一个原串也只有一种划分方式,所以是双射的。
不难发现合法的划分方式的充要条件:
- 第 \(i\) 段的最左侧字符和第 \(i+1\) 段的最右侧字符相等。
- 不存在任何一段中有相邻的相同字符。
于是很容易写出一个复杂度比较高的 dp:\(f_{i,j}\) 表示划分到前缀 \(i\),最后一段的最左侧字符是 \(j\),转移需要枚举上一次划分的点 \(k\) 和上一段的最左侧字符 \(p\),然后再用一个 dp 计算 \((k,i]\) 使得满足条件的划分数。
容易发现每次重新计算系数太蠢了,因为系数实际上也是一个线性 dp,我们可以把它压在一起转移。设 \(g_{i,j,k,l}\) 表示前缀 \(i\),最后一段最左侧是 \(j\),最右侧(即 \(s_i\))是 \(k\),最后一段(对于 \(i\) 来说是倒数第二段)最左侧字符恰为 \(l\) 的 \(f\) 之和。
朴素转移 \(f,g\) 即可,时间复杂度 \(\mathcal O(n|\Sigma|^4)\)。
冗余设计
为什么要在 T3 放简单题??
显然直接算非常不好算,注意到答案上界被确保不超过 \(V\),容易考虑按照 \(T\) 摊开。我们考虑 \([t,t+1]\) 之间产生的贡献。
trickily,我们容易把漏斗分成两部分。对于 \(t_i\le t\) 的漏斗,我们只考虑这些漏斗产生的水的容量就完了,容易写一个 dp \(f_{i,j}\) 求出这部分漏斗产生了容量为 \(j\) 的水的概率。对于 \(t_i>t\) 的漏斗,我们需要考虑它们一秒产生多少水,这也容易用一个背包 dp 求出。
完事之后就是合并两部分概率。枚举一下即可。
考虑背包具有继承性,我们每次只需加入 \(t_i=t\) 的漏斗,所以可以直接正着倒着扫两遍,\(\mathcal O(nV+V^2)\) 求出背包。
复杂度瓶颈在于最后的枚举是 \(\mathcal O(V^3)\) 的,这显然非常难受。不过已经足够让我们获得相当多的分数了。
考虑优化合并。假设 \(t_i\le t\) 的漏斗产生了 \(A\) 容量的水,\(t_i>t\) 的漏斗一秒产生的水量是 \(B\),那么显然的优化是 \(A+tB>V\) 是无意义的。于是均摊地,对于每个 \(V-A\) 来说,有用的 \(B\) 只有 \(\sum \frac{V-A}{t}\) 个,我们知道它是调和级数的,于是可以轻易得到一个 \(\mathcal O(V^2\ln V)\) 的做法。你也可以用相当 dirty 的前缀和来掉这个 ln。
另外这题题面上有个 \(\max(T,1)\) 其实是重要的,因为如果不取 \(\max\) 那么对一秒产生的水量的 dp 的值域需要开到 \(nV\) 了。
P11065 【MX-X4-T5】「Jason-1」占领高地
How does JueFan's mind work?
注意到我们实际上不在乎 \(h\) 的具体取值。考虑一个结论,\(h-\min h\) 只有 \(\mathcal O(n+m)\) 种本质不同的值。
Proof.
不妨取 \(\min h\) 所在的位置 \((i,j)\) ,那么 \(h_{x,y}\le h_{i,j}+|x-i|+|y-j|\),所以显然只有 \(n+m\) 种。
于是我们考虑离线,倒着扫 \(h=x\),每次加入 \(h_{i,j}=x\) 的点 \((i,j)\) 作为补给站,把它可达的点和它在并查集上合并在一起,然后扫一遍所有询问判定连通在一起没有即可。
直接暴力 \(\mathcal O(n^2m^2)\) 扫全图连边可以获得 \(50\) 分。
考虑满足 \((i,j)\) 补给站可达的点 \((x,y)\) 满足什么条件。容易化成 \(h_{x,y}\le h_{i,j}+p_{i,j}-(|i-x|+|j-y|)\)。容易发现这意味着 \(h_{x,y}\) 构成一个连通块:考虑我们从 \((i,j)\) 开始取 \(w=h_{i,j}+p_{i,j}\) 往外 BFS,每走一步 \(w\gets w-1\),这样可以获得每个点上的最大 \(w\)。可以发现如果 \(h_{x,y}\le w\) 总是可以和来的那个点联通,而当 \(h_{x,y}>w\) 的时候就没救了,因为再往外走 \(h\) 总是大于 \(w\),都是不合法的点。
据此我们考虑对每个 \(h=x\) 进行多源 BFS,使得每个点上的 \(w\) 都是它的最大值。在 BFS 的过程中连边即可,时间复杂度 \(\mathcal O((n+m)(nm+q))\),很遗憾被 szh 卡爆了一个点。
考虑我们还没有用到 \(0\le p\le 9\) 的性质,并且现在的 BFS 显然是比较愚蠢的——我们貌似没有利用上离线扫描中只会加点的性质来优化 BFS。实际上我们可以一直保留着每个点上的最大 \(w\),当后面的 BFS 在这个点上产生了更小的 \(w\) 同样不要继续 BFS 下去(如果不保留,这一层就会重新扫一遍在之前已经连在一起过的东西,这是没有意义的)。容易证明,每个点上的 \(w\) 至多减小 \(p\) 次。
Proof.
每个点上的 \(w\) 的下界显然是 \(h_{x,y}\)。考虑对于任何一个 \((i,j)\),到达 \((x,y)\) 时的 \(w\) 为 \(w=h_{i,j}+p_{i,j}-(|i-x|+|j-y|)\),考虑到 \(h_{i,j}\le h_{x,y}+(|i-x|+|j-y|)\),所以 \(w\le h_{x,y}+p_{i,j}\)。因此每个点的 \(w\) 在整个过程中只会变化 \(10\) 次。
于是复杂度变为 \(\mathcal O(nmp+(n+m)q)\),可以通过。有一个可以把查询数量开到更大的做法,使用 Kruskal 重构树来处理查询,但建图的部分是类似的,可以做到复杂度 \(\mathcal O(nm(p+\log nm)+q\log nm)\)。
P11216 【MX-J8-T4】2048
你不太像人类。我说你的条件和 dp 都是。
显然这不是一个平推题,样例解释提示我们先找所有可能的局面,然后数它有多少个合法排列作为生成时刻的离散化结果。显然所有的可能局面是单峰的,没有平台的,长度为 \(n\) 且每个数 \(<x\) 的序列 \(a\),第 \(i\) 项表示这个位置上有一个 \(2^{a_i}\)。我们考虑对于每个可能的局面计算它有多少个排列 \(p\) 能成为生成时刻。
考虑刻画排列的充要条件。
Lemma 1. 这个排列满足 \(n-p_i+1\ge a_i\)。因为生成 \(a_i\) 至少需要 \(a_i\) 个格子,如果它在 \(p_i\) 时刻被生成,那么生成它的时候还剩下 \(n-p_i+1\) 个格子。
Lemma 2. \(p\) 是单谷的。容易用反证法证明,显然不存在一个块比它两边的更后生成。
我们猜测 \(p\) 的谷和 \(a\) 的峰重合,这显然是一个充分条件。然而你发现无法通过样例 \(2\)。因为 \([2,8,4,2]\) 存在一种 \([1,2,3,4]\) 的生成方法:

考虑这种方法的逻辑是什么。我玩了半个小时都没玩懂这种生成方法,然后做不出来这个题。
这实际上在说,如果我们 \(a\) 当中的峰 \(a_k\) 比它的某个邻居至少大 \(2\) 的话,我们可以先搓一个 \(a_k-1\),然后搓好它的邻居,然后再挑选一个合适的时候把它变成 \(a_k\),这样谷就不在 \(a_k\) 这里了,而是在它的邻居!
据此我们实际上也不难证明出谷不可能在比邻居更远的位置。因为如果邻居和邻居的邻居都好了,不难根据上面的构造方法感受到这实际上是一个非常脆弱的状态,我们难以在不改变邻居的情况下跨越邻居得到峰值。
于是这就是第三种条件:
Lemma 3. \(p\) 的谷和 \(a\) 的峰距离不超过 \(1\),并且 \(a\) 的峰 \(a_k\) 比那个位置上的 \(a\) 至少大 \(2\)。
这样就充要了。
接下来考虑用一个 dp 来计数。由于我们关心峰值,不妨从两边向中间填 \(a\)。\(f_{i,j,k}\) 表示当前在 \(t\) 中填完了 \(i\) 个数,\(t\) 的谷的左侧填的 \(a=j\),右侧填的 \(a=k\)。注意这里谷是一个虚化的存在,我们实际上是从两边往中间填了两个单调递增序列,之后计算答案时我们会回收这个伏笔。
那么我们的转移方式是每次向左或右增添一个数 \(a\) 且比原来位置上的更大,这个位置就是现在 \(p=1\) 的位置;在 \(p\) 上则被体现为当前整个 \(p\gets p+1\),在原来 \(1\) 的旁边把新的 \(1\) 插进去。那么转移为:
还有两条关于 \(i\) 的限制是因为,考虑现在 \(a=j\) 位置上的 \(p\) 是 \(1\),dp 到最后它上面的值会变成 \(n-i+1\)。那么根据 Lemma 1 的限制,我们最终希望 \(n+1-(n-i+1)\ge l\),那么就是 \(l\le i\)。
接下来的操作是考虑如何得到答案。这时候暂时不填峰值的好处就展示出来了,我们枚举峰值 \(j\),那么对于第一种峰和谷重叠的情况,答案是:
对于谷在峰邻居的情况,我们再枚举一个邻居就好了:
这样我们就可以得到长度为 \(i\),峰值为 \(j\) 的方案数 \(g_{i,j}\) 了。那么答案即为 \(\sum\limits_{j<x\land j\le n} g_{n,j}\)。
使用前缀和优化 dp,即可做到 \(\mathcal O(nx^2+T)\)。
说句题外话,根据习惯性思维,做这个题你可能会考虑反过来 dp,从峰往外面扩展,然而这样复杂度太差了,因为 \(j,k\) 的限制会变为 \(\le n-i\),不得不变成 \(\mathcal O(Tnx^2)\) 的做法。这也是这个题 dp 方式最牛的地方。
星之卡比(mismatch)
一眼根号分治然后不会做大的部分,我的脑子呢?
考虑对总串长 \(|S|\) 根号分治。
对于串长小于 \(\sqrt{|S|}\) 的部分,我们考虑扫描上面的所有区间。这些区间一共只有 \(\sum\limits_{i=1}^{\sqrt {|S|}}i^2c_i\le |S|\sqrt {|S|}\) 个。
考虑怎么判定所有以 \((x,y)\) 为两端的区间内部都完全相等。容易发现只需判断是否 \(x\) 后面那个位置上的数都相等即可。考虑我们判定了所有的数对,所以实际上是在递归地付诸到子问题上。使用哈希表实现即可。
对于串长大于根号的部分,我们考虑对于每个串 \(s\),\(\mathcal O(t_i)\) 地判定它和剩下所有串 \(t_i\) 合法。显然这个复杂度不会超过 \(\mathcal O(|S|\sqrt{|S|})\)。
我们考虑维护 \(t_i\) 中每个数在 \(s\) 中出现的位置。我们从左往右扫描 \(t_i\),找到第一个匹配得到的数。那么接下来一定会是一段顺着的连续的匹配,一旦无法顺着匹配下去,那么之后的匹配必须匹配到当前所有匹配的左侧。大概是长成这样的结构:
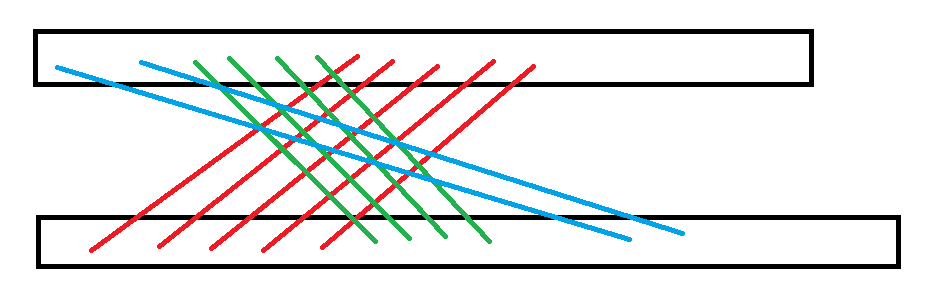
可以发现这是充要的,就做完了。
P12009 【MX-X10-T5】[LSOT-4] Masuko or Haru?
考虑转化到差分上,那么操作等价于每次进行 \(a_l\gets a_l\oplus 1,a_{r+1}\gets a_{r+1}\oplus 1\),问最后能否使得 \(s=t\)。
考虑连边 \(l\leftrightarrow r+1\),那么对每个连通块考虑,我们实际上是选择一些边反转这些边两端点的点权。容易发现一个必要条件是,每个连通块中 \(s_i\ne t_i\) 的点的出现次数是偶数。因为我们最后希望有 \(0\) 个,而选择边进行反转不影响奇偶性。
可以证明这是充分的:
考虑取出该大小为 \(k\) 的连通块的一个生成树,那么我们可以通过边反转达成任意两个点的点权反转。于是我们一一匹配偶数个不对的点来达到目的即可。
考虑到异或的结合律,条件又等价于 \(s\) 中每个连通块点权的异或和分别等于 \(t\) 中每个连通块点权的异或和。于是我们考虑用集合哈希来记录每个串的连通块集合 \(S\) 使得这个串在且仅在 \(S\) 中的这些连通块满足异或和为 \(1\)。随机权值 xor hashing 即可。
考虑加上连边操作。trickily,有效的改变连通块的连边至多发生 \(\mathcal O(m)\) 次,所以我们每次暴力重算哈希是 \(\mathcal O(nm)\) 的。
总复杂度 \(\mathcal O(nm)\)。这题不知道为什么有些很烦人的细节,恶心死我了。
P13833 【MX-X18-T5】「FAOI-R6」纯蓝
逆天完了。好讨厌整体 dp。
考虑经典结论,我们知道一个序列的两两异或最小值产生在排序之后相邻两两异或的最小值。
如果我们试图直接对着这个东西 dp 状态会非常臃肿。因为我们至少需要记一个 \(i\) 描述位置,\(j\) 描述两两异或最小值,这样做出来的转移也不好优化。
经典地,我们把和摊开成 \(f(a)=\sum\limits_{i=0}^{f(a)-1}1\),那么只需计算 \(g_i\) 表示 \(f(a)>i\) 的 \(a\) 的数量。这样我们枚举 \(i\),那么关于异或的限制来到转移上。为了满足 \(\le l_i\) 的上限要求,可以发现我们从小到大填 \(a\) 是不方便的,因为我预先用到后面的,所以我们倒着填,这样就能确定用了多少后面的。取 \(c_j\) 表示有多少个 \(l_i\ge j\),直接 \(f_{i,j}\) 表示当前填了 \(a\) 的前 \(i\) 大项,最后一项 \(a_i=j\),我们一边往前做一边放到任意一个满足限制的位置:
这个转移显然非常有得优化。考虑拆位,枚举 \(x\oplus j>k\) 的位,那么实际上会转变成要求 \(x\) 在某个二进制区间之内,前缀和优化即可。这样看上去会带 \(\log\),但显然通过精细实现可以简单地去掉。
具体来说,首先所有的 \(x\) 的区间一定要么整个在 \(j\) 之上,要么整个在 \(j\) 之下的,因为区间显然不可能包含 \(j\) 且合法。于是在 \(j\gets j+1\) 的过程中,我们可以通过对每个位上产生的区间进行前缀和的方式使得我们只需重算被进位的部分,不需要重算没有变化的更高位,因为这些更高位的贡献在不变的情况下不可能从合法变到不合法。这样每个位被重算的次数等于更高位进位的次数,即 \(2^{\log V-i}\)。求和之后是 \(\mathcal O(V)\) 的。
这个过程也可以看成是在 trie(或者说,由于它是满的,所以已经是线段树状物了)上 dfs。
于是单次转移总复杂度 \(\mathcal O(V)\)。现在的时间复杂度看上去是 \(\mathcal O(nV^2)\) 的。
考虑我们是不是真的要计算所有 \(k\)。实际上有个剪枝是当答案为 \(0\) 时我们就不需要往后算更多的 \(k\) 了。下面我们证明这个复杂度是对的!
Lemma. \(f(a)<\frac{2V}{n-1}\)。
Proof. 考虑 \(2^{k+1}>f(a)\ge 2^k\),那么我们至少需要所有 \(\left\lfloor\frac{a_i}{2^k}\right\rfloor\) 的值互不相同。那么这意味着 \(V\ge 2^k(n-1)\),于是我们有 \(2^k\le \frac{V}{n-1}\),那么 \(f(a)<\frac{2V}{n-1}\)。
于是复杂度实际上是 \(\mathcal O(V^2)\),可以通过。
P5664 [CSP-S 2019] Emiya 家今天的饭
考虑数不合法方案数。钦定超出的那种食材,那么所有的食材实际上分成两种,超出的和不超出的。那么直接 \(f_{i,j}\) 表示前 \(i\) 个烹饪方法中,超出食材的菜肴减去非超出食材的菜肴的数量为 \(j\) 的方案数即可。最后用答案总数减去所有不合法方案。时间复杂度 \(\mathcal O(n^2m)\)。
P13011 【MX-X13-T6】「KDOI-12」能做到的也只不过是静等缘分耗尽的那一天。
要学会使用除法和转概率。有的时候不需要枚举那么多的。不过好像是因为我没转置,给位置安排数做不了,但是好像如果给每个数安排位置就能往后推了。
考虑钦定 \(x<y\)。不难发现 \(T(p)\) 中每个树实际上就是一条左链。不难刻画得出这两个数需要同时享有相同的左侧第一个比自己大的数 \(i\),且 \(x\) 是 \((i,x]\) 中的前缀 \(\max\)。
先不管 \(i=0\) 的情况,考虑确定所有排列中有多少个使得:
- \([i,y]\) 中,\(i\) 是 \(\max\)。
- \([i+1,y]\) 中,\(y\) 是 \(\max\)。
- \([i+1,x]\) 中,\(x\) 是 \(\max\)。
考虑区间上的随机排列,某个数成为该区间 \(\max\) 的概率显然为 \(\frac{1}{r-l+1}\),具体来说这是因为我们可以把这个区间的排列映射到外面,所有排列的系数都是一样的。
于是这一块的方案数就是 \(\frac{n!}{(y-i+1)(y-i)(x-i)}\)。
考虑 \(i=0\),显然类似的是 \(\frac{n!}{xy}\)。
这样我们就得到了一个 \(\mathcal O(Tx)\) 的做法,可以获得 \(45\) 分。
考虑怎么快速计算 \(\sum\limits_{i=1}^{x-1}\frac{1}{(y-i+1)(y-i)(x-i)}\)。一堆 \(i\) 在分母上,我们显然要使用裂项技术来把关于 \(i\) 的因式分离开。先考虑经典的 \(\frac{1}{y-i}-\frac{1}{y-i+1}=\frac{1}{(y-i)(y-i+1)}\),那么可以转化为:
然后继续拆开往下裂,不难得到:
显然是一堆 \(\frac{1}{i}\) 前缀和,于是就做完了。
P2576 [ZJOI2005] 梦幻折纸
很有趣的一道题,不过也许是结束之前最后一题了。
主播主播,折一个二维平面太抽象了,我们先考虑怎么判定一个 \(1\times n\) 的长纸条能不能折出来。考虑最后形成的形态,整个东西实际上是一个 \(n\times m\) 层纸形成的一叠纸,只是每一层都通过左侧或者右侧和另一层纸连接。
不难发现,如果我们钦定第 \(i\) 层和第 \(j\) 层通过左侧连接,那么不允许存在 \(i<p<j<q\) 的 \(p,q\) 两层也通过左侧连接。这是不难理解的,因为 \(i,j\) 层之间的左侧连接会包裹住中间所有的纸层,那么 \(p,q\) 层之间如果想要左侧连接就必须让纸穿过自己,这是不被允许的。不难发现这是充要条件,只要目标纸叠不存在这种交叉情况,我们就一定能折出来 其实是摊开。
现在我们考虑怎么找出原来纸条上的这种连接关系。不难发现,如果我们钦定 \(1,2\) 两个格子通过左侧连接,那么 \(2,3\) 两个格子就一定是通过右侧连接。以此类推,\(i,i+1\) 格子的连接方向与它们的奇偶性有关。据此我们直接按照奇偶性分类,那么对于一侧来说,我们直接判定这些连接是否是不交的即可(因为我们最后希望整个纸叠是 \(1\) 到 \(nm\) 从上往下依次排列,所以不需要进行重标号工作,如果有目标纸叠的话那么需要重新把每个层重标号成它出现的层数)。
现在考虑 \(n\times m\) 的二维纸张。显然这是容易推广的:所有行的 \(1,2\) 两个格子都需要通过左侧连接,依次类推。不难发现对于列是对称的,每层纸会多一个前后的维度用于在列上连接,这个维度显然和左右是独立的。据此,我们对行/列的左右/上下分别判定一次不交性即可。
P2726 [SHOI2005] 树的双中心
想不到重心是不是很没救。。
考虑选完 \(x,y\) 之后整棵树上其实是一个连通块选 \(x\),一个连通块选 \(y\),两个连通块的并是整棵树,中间通过一条边切割。那么不妨反过来,考虑枚举这条切割边,再在两个连通块里面选 \(x,y\),容易发现这里有不合法不优。显然我们要选择的是两边带权重心。
于是我们的问题变成怎么一边断边一边找树的重心并维护答案。不妨取原树重心当根 \(r\),根据重心经典结论,如果我们断掉一条边 \((u,v)\) 并钦定 \(dep_u<dep_v\),那么两个重心分别在 \(r\) 的重链上和 \(v\) 的重链上。显然可以通过预处理子树和的方式一边移动重心一边计算答案。于是复杂度 \(\mathcal O(nH)\)。
貌似可以通过一些 dirty work 做到复杂度不带 \(H\)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号