SpringCloud系列十二:SpringCloudSleuth(SpringCloudSleuth 简介、SpringCloudSleuth 基本配置、数据采集)
声明:本文来源于MLDN培训视频的课堂笔记,写在这里只是为了方便查阅。
1、概念:SpringCloudSleuth
2、具体内容
Sleuth 是一种提供的跟踪服务,也就是说利用 sleuth 技术可以实现完整的微服务的访问路径的跟踪操作。
2.1、SpringCloudSleuth 简介
微服务可以将整个的系统拆分为无数个子系统,于是这样一来就有可能出现几种可怕的场景:
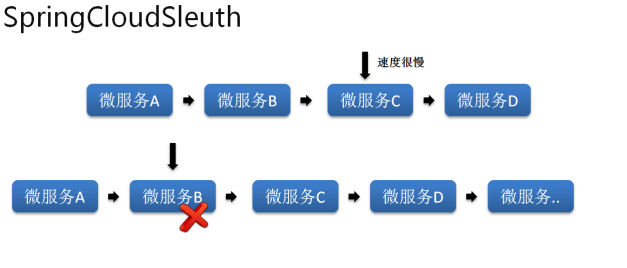
· 代码的调试:
|- 你的系统有可能变慢了,于是这个时候就需要去追踪每一个微服务的执行的速度;
|- 如果现在你的微服务采用了串联的方式进行了互相调用,那么如何确认某一个微服务出现了问题呢?
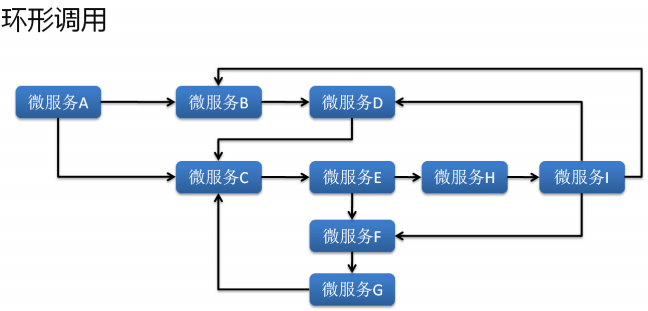
· 微服务混合调用:
|- 现在微服务变为了环形调用,那么这些关系该如何描述出来?
在创建微服务的时候一定要有一些合适的开发契约,所有的开发者以及服务的调用者要按照统一的方式进行程序的调用处理, 这样才可以成为一个优秀的微服务设计。
所以在 SpringCloud 之中提供的 Sleuth 技术就可以实现微服务的调用跟踪,也就是说它可以自动的形成一个调用连接线,通过这个连接线使得开发者可以轻松的找到所有微服务间关系,同时也可以获取微服务所耗费的时间, 这样就可以进行微服务调用状态的监控以及相应的数据分析。
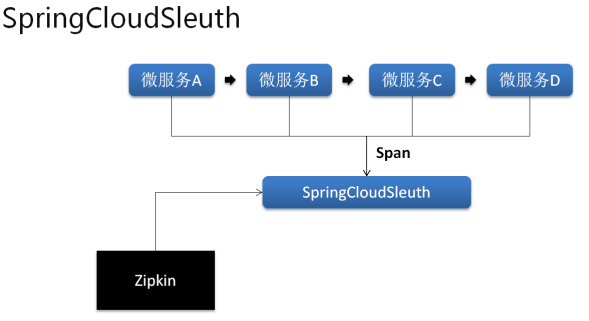
Span 里面包含有如下内容:
· cs-Client Sent:客户端发出一个请求,描述的是一个 Span 开始;
· sr-Server Received:服务端接收请求,利用 sr-cs 就属于发送的网络延迟;
· ss-Server Sent:服务端发送请求(回应处理),ss-sr 就属于服务端的消耗时间;
· cr-Client Received:客户端接收到服务端数据,cr-ss 就表示回复所需要的时间。
2.2、SpringCloudSleuth 基本配置
SpringCloudSleuth 使用的核心组件在于 Twitter 推出的 zipkin 监控组件,所以本次的配置的模块一定要包含 zipkin 相关配置依赖,本次实现一个基础的调用逻辑:consumer-zuul-dept。
1、 【microcloud-sleuth-8601】通过“microcloud-provider-company-8101”项目复制得来;
2、 【microcloud-sleuth-8601】修改 pom.xml 配置文件:
· 由于 sleuth 的应用比较复杂,而且也牵扯到埋点的数据分析,本次不使用安全处理模块:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-server</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> </dependency>
3、 【microcloud-sleuth-8601】修改 application.yml 配置文件:
server:
port: 8601
spring:
application:
name: microcloud-zipkin-server
4、 【microcloud-sleuth-8601】修改程序启动类:
package cn.study.microcloud; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker; import org.springframework.cloud.client.discovery.EnableDiscoveryClient; import zipkin.server.EnableZipkinServer; @SpringBootApplication @EnableCircuitBreaker @EnableZipkinServer public class Zipkin_8601_StartSpringCloudApplication { public static void main(String[] args) { SpringApplication.run(Zipkin_8601_StartSpringCloudApplication.class, args); } }
5、 修改 hosts 配置文件,追加一个新的主机名称映射:
127.0.0.1 zipkin.com
6、 【microcloud-consumer-feign、microcloud-zuul-gateway-9501、microcloud-provider-dept-8001】修改 pom.xml 配置文件,追加 zipkin 相关依赖程序包:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
7、 【microcloud-consumer-feign、microcloud-zuul-gateway-9501、microcloud-provider-dept-8001】修改 application.yml 配置文件:
spring:
zipkin:
base-url: http://zipkin.com:8601 # 所有的数据提交到此服务之中
sleuth:
sampler:
percentage: 1.0 # 定义抽样比率,默认为0.1
application:
name: microcloud-consumer-feign
一定要有每一个微服务的名字,这样会比较好观察程序的执行轨迹。
8、 依次启动所有的服务:microcloud-sleuth-8601、microcloud-consumer-feign、microcloud-zuul-gateway-9501、microcloud-provider-dept-8001;
输入访问地址:http://zipkin.com:8601;就可以看到各个微服务之间的调用关系了
2.3、数据采集
现在已经成功的实现了一个 SpringCloudSleuth 基础操作,但是需要考虑一个实际的问题,现在所有的统计的汇总操作都是记录在内存之中的,也就是说如果你现在已经关闭了 zipkin 服务端,那么这些统计信息就将消失,很明显这样的做法并不符合实际要求,数据应该被记录下来,而且有可能你很多的微服务要发送大量的数据信息进入,为了解决这种高并发的问题,可以结合消息组件(Stream)进行缓存处理,而且本次为了方便可以将统计的结果保存在数据库之中(mysql)。
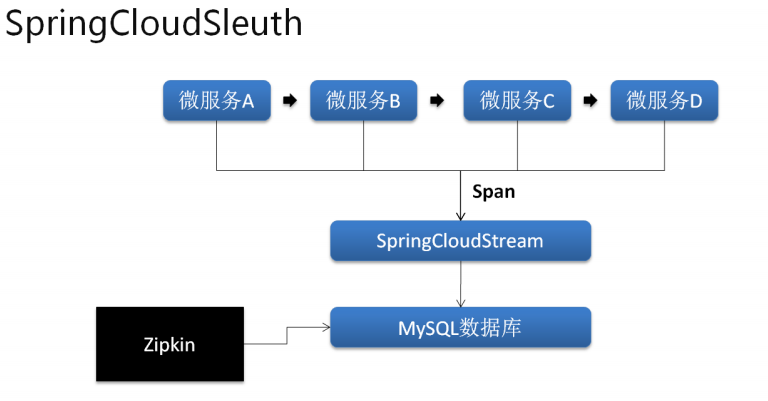
1、 需要创建数据库脚本,脚本是从官网拷贝下来的直接复制使用即可:
DROP DATABASE IF EXISTS zipkin ; CREATE DATABASE zipkin CHARACTER SET UTF8 ; USE zipkin ; CREATE TABLE IF NOT EXISTS zipkin_spans ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL, `id` BIGINT NOT NULL, `name` VARCHAR(255) NOT NULL, `parent_id` BIGINT, `debug` BIT(1), `start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL', `duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`); ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`); ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`); ALTER TABLE zipkin_spans ADD INDEX(`name`); ALTER TABLE zipkin_spans ADD INDEX(`start_ts`); CREATE TABLE IF NOT EXISTS zipkin_annotations ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id', `span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id', `a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1', `a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB', `a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation', `a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp', `endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address', `endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`); ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) ; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`); ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`); ALTER TABLE zipkin_annotations ADD INDEX(`a_type`); ALTER TABLE zipkin_annotations ADD INDEX(`a_key`); CREATE TABLE IF NOT EXISTS zipkin_dependencies ( `day` DATE NOT NULL, `parent` VARCHAR(255) NOT NULL, `child` VARCHAR(255) NOT NULL, `call_count` BIGINT ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);
2、 【microcloud-sleuth-8601】修改 pom.xml 配置文件,追加相关的依赖程序包:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <!-- <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> -->
3、 【microcloud-sleuth-8601】修改 application.yml 配置文件:
server:
port: 8601
spring:
rabbitmq:
host: rabbitmq-server
port: 5672
username: studyjava
password: hello
virtual-host: /
datasource:
driver-class-name: org.gjt.mm.mysql.Driver # 配置MySQL的驱动程序类
url: jdbc:mysql://localhost:3306/zipkin # 数据库连接地址
username: root # 数据库用户名
password: mysqladmin # 数据库连接密码
initialize: true
application:
name: microcloud-zipkin-server
zipkin:
storage: # 设置zipkin收集的信息通过mysql进行存储
type: mysql
4、 【microcloud-sleuth-8601】可以打开安全配置项:
<dependency> <groupId>cn.study</groupId> <artifactId>microcloud-security</artifactId> </dependency>
5、 【microcloud-consumer-feign、microcloud-zuul-gateway-9501、microcloud-provider-dept-8001】修改 pom.xml 配置文件:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <!-- <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> -->
6、 【microcloud-consumer-feign、microcloud-zuul-gateway-9501、microcloud-provider-dept-8001】修改 application.yml 配置文件:
spring:
rabbitmq:
host: rabbitmq-server
port: 5672
username: studyjava
password: hello
virtual-host: /
同时删除掉已有的 zipkin.base-url 的配置项。
7、 【microcloud-sleuth-8601】修改启动程序类的使用注解:
package cn.study.microcloud; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker; import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer; import zipkin.server.EnableZipkinServer; @SpringBootApplication @EnableCircuitBreaker @EnableZipkinStreamServer public class Zipkin_8601_StartSpringCloudApplication { public static void main(String[] args) { SpringApplication.run(Zipkin_8601_StartSpringCloudApplication.class, args); } }
8、 此时依次启动各个微服务之后所有的信息都将被记录到 MySQL 数据库之中,这样即使当前的 zipkin 服务关闭了,那么也可以进行信息的持久化存储,下次启动之后依然可以读取到执行顺序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号