21-9 重载下标运算符
在处理数组时,我们通常使用下标运算符([])来索引数组中的特定元素:
myArray[0] = 7; // put the value 7 in the first element of the array
然而,请考虑以下 IntList 类,它包含一个作为数组的成员变量:
class IntList
{
private:
int m_list[10]{};
};
int main()
{
IntList list{};
// how do we access elements from m_list?
return 0;
}
由于成员变量 m_list 是私有的,我们无法直接从变量列表访问它。这意味着我们无法直接获取或设置 m_list 数组中的值。那么我们该如何获取或向列表中添加元素呢?
在没有运算符重载的情况下,典型方法是创建访问函数:
class IntList
{
private:
int m_list[10]{};
public:
void setItem(int index, int value) { m_list[index] = value; }
int getItem(int index) const { return m_list[index]; }
};
虽然这能行得通,但用户体验并不理想。请看以下示例:
int main()
{
IntList list{};
list.setItem(2, 3);
return 0;
}
我们是将元素2设置为值3,还是将元素3设置为值2?在未看到setItem()的定义前,这点并不明确。
你也可以直接返回整个列表,然后使用[]运算符访问元素:
class IntList
{
private:
int m_list[10]{};
public:
int* getList() { return m_list; }
};
虽然这也行得通,但语法上有些奇怪:
int main()
{
IntList list{};
list.getList()[2] = 3;
return 0;
}
重载下标运算符[]
然而,在此情况下更优的解决方案是重载下标运算符[],以便访问m_list的元素。下标运算符是必须作为成员函数重载的运算符之一。重载的[]运算符函数始终接受一个参数:用户在花括号中指定的下标。在IntList示例中,我们期望用户传入整数索引,并返回整数值作为结果。
#include <iostream>
class IntList
{
private:
int m_list[10]{};
public:
int& operator[] (int index)
{
return m_list[index];
}
};
/*
// Can also be implemented outside the class definition
int& IntList::operator[] (int index)
{
return m_list[index];
}
*/
int main()
{
IntList list{};
list[2] = 3; // set a value
std::cout << list[2] << '\n'; // get a value
return 0;
}
现在,每当我们在类对象上使用下标运算符([])时,编译器都会从m_list成员变量中返回对应元素!这使我们能够直接获取和设置m_list的值。
这种设计在语法和理解上都非常简洁。当求值list[2]时,编译器首先检查是否存在重载的operator[]函数。若存在,则将花括号内的值(此处为2)作为参数传递给该函数。
需注意:尽管可为函数参数提供默认值,但若未使用下标直接调用operator[],则被视为语法错误,因此默认值设置毫无意义。
提示:
C++23新增了对多下标重载operator[]的支持。
为什么[]运算符返回引用
让我们仔细观察 list[2] = 3 的求值过程。由于下标运算符的优先级高于赋值运算符,list[2] 先被求值。list[2] 调用我们定义的[]运算符,该运算符返回指向 list.m_list[2] 的引用。由于[]运算符返回的是引用,因此它返回实际的 list.m_list[2] 数组元素。此时表达式部分求值为 list.m_list[2] = 3,这便成为标准的整数赋值操作。
在第12.2节《值类别(左值与右值)》中,你已知晓赋值语句左侧的任何值都必须是左值(即拥有实际内存地址的变量)。由于 operator[] 的结果可用于赋值左侧(如 list[2] = 3),其返回值必须是左值。事实上,引用始终是左值,因为只有具有内存地址的变量才能被引用。因此通过返回引用,编译器确认我们返回的是左值。
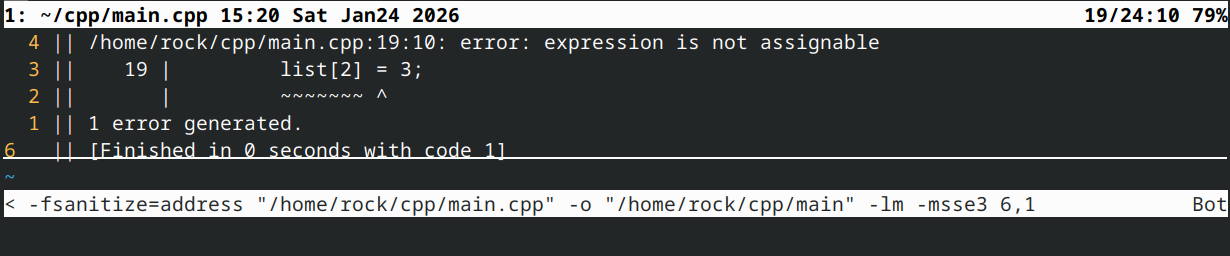
试想若operator[]按值返回整数而非引用会发生什么:list[2]调用operator[]时,它将返回list.m_list[2]的值。例如当m_list[2]值为6时,operator[]会直接返回6。此时list[2] = 3将部分评估为6 = 3,这显然毫无意义!若尝试此操作,C++编译器将报错:
const对象的重载[]运算符
在上面的IntList示例中,[]运算符是非const的,我们可以将其作为左值来改变非const对象的状态。但如果我们的IntList对象是const的呢?这种情况下,我们无法调用非const版本的[]运算符,因为这可能导致const对象的状态被改变。
好消息是,我们可以分别定义非 const 和 const 版本的 operator[]。非 const 版本将用于非 const 对象,const 版本则用于 const 对象。
#include <iostream>
class IntList
{
private:
int m_list[10]{ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }; // give this class some initial state for this example
public:
// For non-const objects: can be used for assignment
int& operator[] (int index)
{
return m_list[index];
}
// For const objects: can only be used for access
// This function could also return by value if the type is cheap to copy
const int& operator[] (int index) const
{
return m_list[index];
}
};
int main()
{
IntList list{};
list[2] = 3; // okay: calls non-const version of operator[]
std::cout << list[2] << '\n';
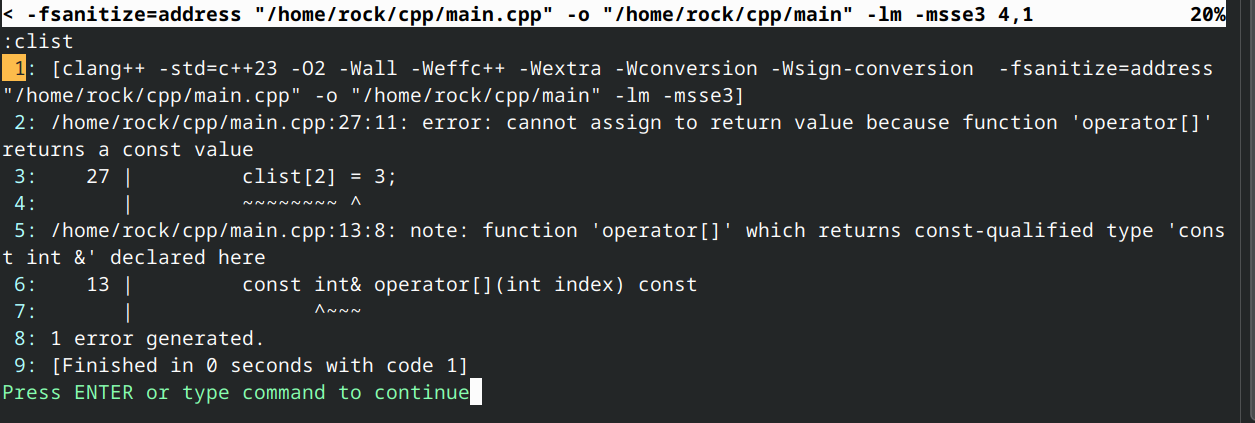
const IntList clist{};
// clist[2] = 3; // compile error: clist[2] returns const reference, which we can't assign to
std::cout << clist[2] << '\n';
return 0;
}
移除const与非const重载间的重复代码
在上例中,请注意int& IntList::operator与const int& IntList::operator const的实现完全相同,唯一区别在于函数的返回类型。
当实现非常简单(例如仅一行代码)时,允许(且推荐)两个函数使用相同的实现。由此产生的少量冗余无需消除。
但若这些运算符的实现较为复杂,需要多条语句呢?例如,验证索引有效性可能至关重要,这要求在每个函数中添加大量冗余代码。
此时,大量重复语句造成的冗余更显棘手,我们需要一个可同时适用于两个重载的统一实现方案。但如何实现?通常我们只需让其中一个函数调用另一个函数即可。但此处存在技术障碍:常量版本无法调用非常量版本,因为这将导致常量对象的常量性被破坏;而非常量版本虽可调用常量版本,但常量版本返回常量引用,而我们需要返回非常量引用。所幸存在解决之道。
首选方案如下:
- 实现常量版本函数的逻辑。
- 让非常量函数调用常量函数,并使用const_cast移除常量限定。
最终解决方案大致如下:
#include <iostream>
#include <utility> // for std::as_const
class IntList
{
private:
int m_list[10]{ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }; // give this class some initial state for this example
public:
int& operator[] (int index)
{
// use std::as_const to get a const version of `this` (as a reference)
// so we can call the const version of operator[]
// then const_cast to discard the const on the returned reference
return const_cast<int&>(std::as_const(*this)[index]);
}
const int& operator[] (int index) const
{
return m_list[index];
}
};
int main()
{
IntList list{};
list[2] = 3; // okay: calls non-const version of operator[]
std::cout << list[2] << '\n';
const IntList clist{};
// clist[2] = 3; // compile error: clist[2] returns const reference, which we can't assign to
std::cout << clist[2] << '\n';
return 0;
}
通常我们应避免使用const_cast移除const限定,但在此情况下可接受。若调用了非const重载版本,则表明当前操作对象为非const类型。此时移除非const对象的const引用限定是可行的。
对于高级读者:
在 C++23 中,我们还能通过运用本教程系列尚未涉及的若干特性实现更优方案:#include <iostream> class IntList { private: int m_list[10]{ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }; // give this class some initial state for this example public: // Use an explicit object parameter (self) and auto&& to differentiate const vs non-const auto&& operator[](this auto&& self, int index) { // Complex code goes here return self.m_list[index]; } }; int main() { IntList list{}; list[2] = 3; // okay: calls non-const version of operator[] std::cout << list[2] << '\n'; const IntList clist{}; // clist[2] = 3; // compile error: clist[2] returns const reference, which we can't assign to std::cout << clist[2] << '\n'; return 0; }
检测索引有效性
重载下标运算符的另一个优势在于,它能比直接访问数组更安全。通常访问数组时,下标运算符不会检查索引是否有效。例如,编译器对以下代码不会报错:
int list[5]{};
list[7] = 3; // index 7 is out of bounds!
然而,如果我们知道数组的大小,就可以让重载的下标运算符进行检查,确保索引在有效范围内:
#include <cassert> // for assert()
#include <iterator> // for std::size()
class IntList
{
private:
int m_list[10]{};
public:
int& operator[] (int index)
{
assert(index >= 0 && static_cast<std::size_t>(index) < std::size(m_list));
return m_list[index];
}
};

在上例中,我们使用了 assert() 函数(包含在 cassert 头文件中)来确保索引有效。若 assert 内的表达式评估为 false(即用户传入了无效索引),程序将终止并显示错误信息,这远优于另一种可能(内存损坏)。此类错误检查中,这可能是最常见的方法。
若不想使用 assert(该函数在非调试构建中会被编译掉),可改用 if 语句配合首选的错误处理方式(例如抛出异常、调用 std::exit 等):
#include <iterator> // for std::size()
class IntList
{
private:
int m_list[10]{};
public:
int& operator[] (int index)
{
if (!(index >= 0 && static_cast<std::size_t>(index) < std::size(m_list))
{
// handle invalid index here
}
return m_list[index];
}
};
对象指针与重载的[]运算符不可混用
若尝试对对象指针调用[]运算符,C++会默认你正在对该类型对象的数组进行索引操作。
请看以下示例:
#include <cassert> // for assert()
#include <iterator> // for std::size()
class IntList
{
private:
int m_list[10]{};
public:
int& operator[] (int index)
{
return m_list[index];
}
};
int main()
{
IntList* list{ new IntList{} };
list [2] = 3; // error: this will assume we're accessing index 2 of an array of IntLists
delete list;
return 0;
}
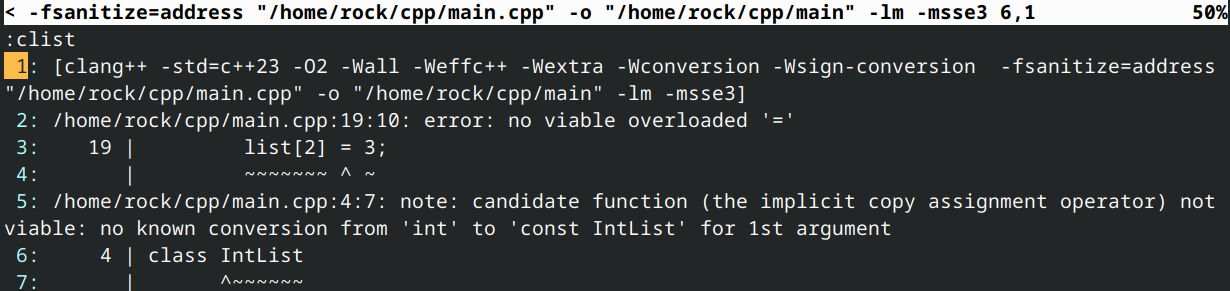
由于无法将整数赋值给 IntList,此代码无法编译。但若整数赋值有效,则代码可编译运行,但结果未定义。
规则:
请确保您未尝试对对象指针调用重载的operator[]运算符。
正确语法应先解引用指针(注意使用括号,因为operator[]运算符的优先级高于operator*运算符),再调用operator[]:
int main()
{
IntList* list{ new IntList{} };
(*list)[2] = 3; // get our IntList object, then call overloaded operator[]
delete list;
return 0;
}
这种做法既丑陋又容易出错。更理想的做法是,除非必要,否则不要将指针指向你的对象。
函数参数不必是整数类型
如前所述,C++会将用户在花括号内输入的内容作为参数传递给重载函数。多数情况下,该参数为整数值。但这并非强制要求——实际上,你可以定义重载的[]运算符接受任意类型的值。你可以将重载的[]运算符定义为接受双精度浮点数、std::string字符串或其他任意类型。
以下是一个荒谬的示例,仅为验证其可行性:
#include <iostream>
#include <string_view> // C++17
class Stupid
{
private:
public:
void operator[] (std::string_view index);
};
// It doesn't make sense to overload operator[] to print something
// but it is the easiest way to show that the function parameter can be a non-integer
void Stupid::operator[] (std::string_view index)
{
std::cout << index;
}
int main()
{
Stupid stupid{};
stupid["Hello, world!"];
return 0;
}
正如你所料,这段代码会输出:
重载运算符[]以接受std::string参数,在编写特定类时会很有用,例如那些使用单词作为索引的类。
测验时间
问题 #1
映射(map)是一种将元素存储为键值对的类。键必须唯一,用于访问关联的键值对。在本测验中,我们将编写一个应用程序,使用简单的映射类根据学生姓名分配成绩。学生的姓名作为键,成绩(以字符形式存储)作为值。
a) 首先编写名为StudentGrade的结构体,包含学生姓名(std::string类型)和成绩(char类型)。
显示解决方案
#include <string>
struct StudentGrade
{
std::string name{};
char grade{};
};
b) 添加名为GradeMap的类,包含名为m_map的StudentGrade类型std::vector容器。
显示解决方案
#include <string>
#include <vector>
struct StudentGrade
{
std::string name{};
char grade{};
};
class GradeMap
{
private:
std::vector<StudentGrade> m_map{};
};
c) 为该类重载[]运算符。该函数应接受std::string参数,并返回char类型的引用。函数体内需先检查学生姓名是否存在(可使用
以下程序应能运行:
#include <iostream>
// ...
int main()
{
GradeMap grades{};
grades["Joe"] = 'A';
grades["Frank"] = 'B';
std::cout << "Joe has a grade of " << grades["Joe"] << '\n';
std::cout << "Frank has a grade of " << grades["Frank"] << '\n';
return 0;
}
解决方案
#include <algorithm>
#include <iostream>
#include <string>
#include <string_view>
#include <vector>
struct StudentGrade
{
std::string name{};
char grade{};
};
class GradeMap
{
private:
std::vector<StudentGrade> m_map{};
public:
char& operator[](std::string_view name);
};
char& GradeMap::operator[](std::string_view name)
{
auto found{ std::find_if(m_map.begin(), m_map.end(),
[name](const auto& student) { // this is a lambda that captures name from the surrounding scope
return (student.name == name); // so we can use name here
}) };
if (found != m_map.end())
{
return found->grade;
}
// otherwise create a new StudentGrade for this student and add
// it to the end of our vector. Then return the grade.
// emplace_back version (C++20 onward)
// StudentGrade is an aggregate and emplace_back only works with aggregates as of C++20
return m_map.emplace_back(std::string{name}).grade;
// push_back version (C++17 or older)
// m_map.push_back(StudentGrade{std::string{name}});
// return m_map.back().grade;
}
int main()
{
GradeMap grades{};
grades["Joe"] = 'A';
grades["Frank"] = 'B';
std::cout << "Joe has a grade of " << grades["Joe"] << '\n';
std::cout << "Frank has a grade of " << grades["Frank"] << '\n';
return 0;
}
提醒:
有关lambda表达式的更多信息,请参阅20.6节——lambda表达式(匿名函数)介绍。
提示:
由于映射结构很常见,标准库提供了 std::map,目前 learncpp 尚未涵盖该内容。使用 std::map,我们可以简化代码为:
#include <iostream>
#include <map> // std::map
#include <string>
int main()
{
// std::map can be initialized
std::map<std::string, char> grades{
{ "Joe", 'A' },
{ "Frank", 'B' }
};
// and assigned
grades["Susan"] = 'C';
grades["Tom"] = 'D';
std::cout << "Joe has a grade of " << grades["Joe"] << '\n';
std::cout << "Frank has a grade of " << grades["Frank"] << '\n';
return 0;
}
建议使用 std::map 而不是编写自己的实现。
问题 #2
额外加分题 #1:我们编写的 GradeMap 类和示例程序存在诸多低效之处。请描述一种改进 GradeMap 类的方法。
显示解答
std::vector 本质上是无序的。这意味着每次调用 operator[] 时,我们都可能遍历整个 std::vector 来查找目标元素。当元素数量较少时这不成问题,但随着不断添加名称,速度将日益缓慢。我们可通过保持 m_map 的排序状态并采用二分搜索来优化此过程,从而最大限度减少查找目标元素时需要遍历的元素数量。
问题 #3
额外加分题 #2:为什么这个程序可能无法按预期运行?
#include <iostream>
int main()
{
GradeMap grades{};
char& gradeJoe{ grades["Joe"] }; // does an emplace_back
gradeJoe = 'A';
char& gradeFrank{ grades["Frank"] }; // does a emplace_back
gradeFrank = 'B';
std::cout << "Joe has a grade of " << gradeJoe << '\n';
std::cout << "Frank has a grade of " << gradeFrank << '\n';
return 0;
}
显示解方案
#include <iostream>
int main()
{
GradeMap grades{};
char& gradeJoe{ grades["Joe"] }; // does an emplace_back
gradeJoe = 'A';
char& gradeFrank{ grades["Frank"] }; // does a emplace_back
gradeFrank = 'B';
std::cout << "Joe has a grade of " << gradeJoe << '\n';
std::cout << "Frank has a grade of " << gradeFrank << '\n';
return 0;
}
解决方案
当添加Frank时,std::vector可能需要扩展以容纳它。这需要动态分配新的内存块,将数组中的元素复制到新块,并删除旧块。此时,std::vector中对现有元素的所有引用都会失效(即成为指向已删除内存的悬空引用)。
换言之,在执行 emplace_back(“Frank”) 之后,若 std::vector 为容纳 Frank 而扩展,则 gradeJoe 引用将失效。此时访问 gradeJoe 打印 Joe 的成绩将导致未定义行为。
std::vector 的扩展机制属于编译器特有的细节,因此上述程序在某些编译器下运行正常,而在其他编译器下则可能出现异常。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号