20-6 引入lambda表达式(匿名函数)
请考虑我们在第18.3节——标准库算法介绍中介绍的这段代码片段:
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
// Our function will return true if the element matches
bool containsNut(std::string_view str)
{
// std::string_view::find returns std::string_view::npos if it doesn't find
// the substring. Otherwise it returns the index where the substring occurs
// in str.
return str.find("nut") != std::string_view::npos;
}
int main()
{
constexpr std::array<std::string_view, 4> arr{ "apple", "banana", "walnut", "lemon" };
// Scan our array to see if any elements contain the "nut" substring
auto found{ std::find_if(arr.begin(), arr.end(), containsNut) };
if (found == arr.end())
{
std::cout << "No nuts\n";
}
else
{
std::cout << "Found " << *found << '\n';
}
return 0;
}
该代码遍历字符串数组,寻找首个包含子字符串“nut”的元素。因此,它产生以下结果:
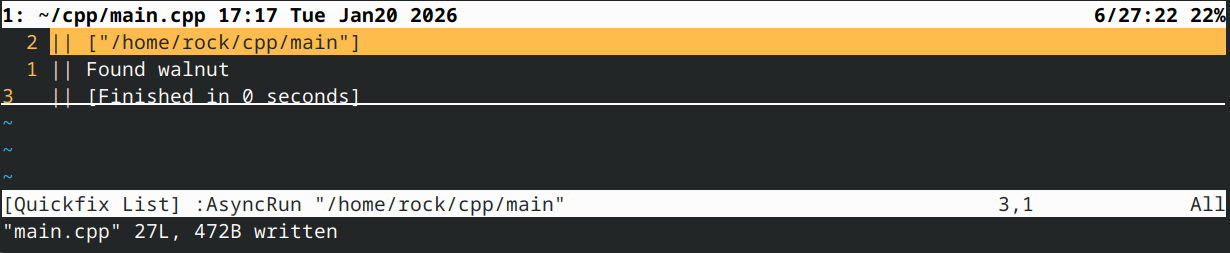
虽然它能正常工作,但仍有改进空间。
问题的根源在于std::find_if要求我们传入函数指针。因此我们被迫定义一个仅使用一次的函数,必须为其命名,且必须置于全局作用域(因为函数不能嵌套!)。该函数极其简短,从单行代码中理解其功能反而比通过函数名和注释更直观。
Lambda表达式是匿名函数
Lambda表达式lambda expression(也称为lambda或闭包closure)允许我们在另一个函数内部定义匿名函数。这种嵌套结构至关重要,它既能避免命名空间污染,又能将函数定义得尽可能靠近使用位置(提供额外上下文)。
Lambda的语法是C++中较为奇特的部分,需要一定时间适应。其形式如下:
[ captureClause ] ( parameters ) -> returnType
{
statements;
}
- 捕获子句在无需捕获时可以为空。
- 参数列表在无需参数时可以为空。除非指定返回类型,否则参数列表也可完全省略。
- 返回类型为可选项,若省略则默认采用 auto(即通过类型推断确定返回类型)。虽然我们此前指出应避免对函数返回类型进行类型推断,但在本场景中使用并无不妥(因这类函数通常极其简单)。
另需注意,lambda 表达式(作为匿名函数)没有名称,因此无需提供。
顺带一提……:
这意味着一个简单的lambda定义看起来像这样:#include <iostream> int main() { [] {}; // a lambda with an omitted return type, no captures, and omitted parameters. return 0; }
让我们使用lambda表达式重写上述示例:
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
int main()
{
constexpr std::array<std::string_view, 4> arr{ "apple", "banana", "walnut", "lemon" };
// Define the function right where we use it.
auto found{ std::find_if(arr.begin(), arr.end(),
[](std::string_view str) // here's our lambda, no capture clause
{
return str.find("nut") != std::string_view::npos;
}) };
if (found == arr.end())
{
std::cout << "No nuts\n";
}
else
{
std::cout << "Found " << *found << '\n';
}
return 0;
}
这与函数指针的情况完全相同,并产生相同的结果:
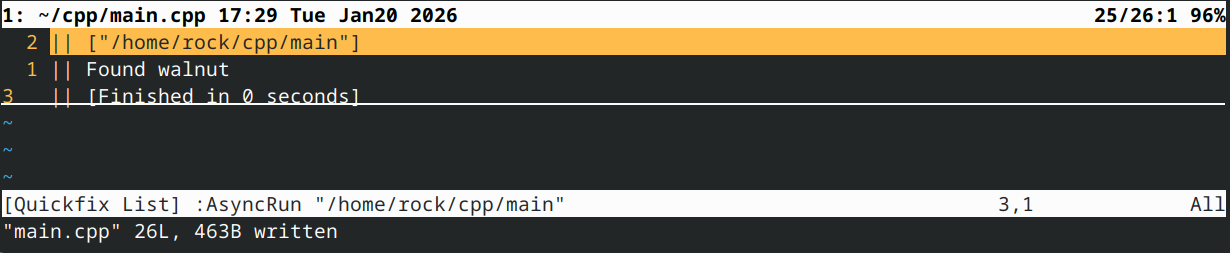
请注意我们的lambda表达式与containsNut函数多么相似。它们具有完全相同的参数和函数体。该lambda表达式没有捕获子句(我们将在下一课解释捕获子句的概念),因为它不需要捕获子句。我们省略了lambda表达式末尾的返回类型(为简洁起见),但由于运算符!=返回布尔值,因此我们的lambda表达式也将返回布尔值。
最佳实践:
遵循在最小作用域内定义事物且尽可能靠近首次使用位置的最佳实践,当需要将一个简单的一次性函数作为参数传递给其他函数时,应优先选择lambda表达式而非普通函数。
lambda的类型
在上例中,我们直接在需要的位置定义了lambda。这种使用方式有时被称为函数字面量function literal。
然而,将lambda与使用位置写在同一行有时会降低代码可读性。正如我们可以使用字面量(或函数指针)初始化变量以备后用,同样可以使用lambda定义初始化lambda变量,随后再调用它。命名lambda并赋予恰当的函数名能显著提升代码可读性。
例如,在下面的代码片段中,我们使用std::all_of函数检查数组中所有元素是否均为偶数:
// Bad: We have to read the lambda to understand what's happening.
return std::all_of(array.begin(), array.end(), [](int i){ return ((i % 2) == 0); });
我们可以按以下方式提高其可读性:
// Good: Instead, we can store the lambda in a named variable and pass it to the function.
auto isEven{
[](int i)
{
return (i % 2) == 0;
}
};
return std::all_of(array.begin(), array.end(), isEven);
注意最后一行读起来多么顺畅:“返回数组中所有元素是否均为偶数”
关键洞见:
将lambda存储在变量中,能为lambda赋予有意义的名称,从而提升代码可读性。
将lambda存储在变量中还使我们能够重复使用该lambda。
但lambda isEven的类型是什么?
事实上,lambda本身没有可显式使用的类型。当我们编写lambda时,编译器会为其生成专属类型,该类型不会暴露给我们。
进阶读者须知:
实际上,lambda 并非函数(这正是其规避 C++ 不支持嵌套函数限制的关键机制)。它们属于名为“函子”的特殊对象类型。函子通过重载的 operator() 使自身具备函数般的可调用特性。
尽管无法获知lambda的具体类型,但存在多种方式在定义后存储lambda以供后续使用。若lambda的捕获子句为空(方括号[]内无内容),可直接使用普通函数指针。std::function或通过auto关键字进行类型推导同样有效(即使捕获子句非空)。
#include <functional>
int main()
{
// A regular function pointer. Only works with an empty capture clause (empty []).
double (*addNumbers1)(double, double){
[](double a, double b) {
return a + b;
}
};
addNumbers1(1, 2);
// Using std::function. The lambda could have a non-empty capture clause (discussed next lesson).
std::function addNumbers2{ // note: pre-C++17, use std::function<double(double, double)> instead
[](double a, double b) {
return a + b;
}
};
addNumbers2(3, 4);
// Using auto. Stores the lambda with its real type.
auto addNumbers3{
[](double a, double b) {
return a + b;
}
};
addNumbers3(5, 6);
return 0;
}
使用lambda实际类型的唯一方法是通过auto。与std::function相比,auto还具有零开销的优势。
若需将lambda传递给函数,有四种方案:
#include <functional>
#include <iostream>
// Case 1: use a `std::function` parameter
void repeat1(int repetitions, const std::function<void(int)>& fn)
{
for (int i{ 0 }; i < repetitions; ++i)
fn(i);
}
// Case 2: use a function template with a type template parameter
template <typename T>
void repeat2(int repetitions, const T& fn)
{
for (int i{ 0 }; i < repetitions; ++i)
fn(i);
}
// Case 3: use the abbreviated function template syntax (C++20)
void repeat3(int repetitions, const auto& fn)
{
for (int i{ 0 }; i < repetitions; ++i)
fn(i);
}
// Case 4: use function pointer (only for lambda with no captures)
void repeat4(int repetitions, void (*fn)(int))
{
for (int i{ 0 }; i < repetitions; ++i)
fn(i);
}
int main()
{
auto lambda = [](int i)
{
std::cout << i << '\n';
};
repeat1(3, lambda);
repeat2(3, lambda);
repeat3(3, lambda);
repeat4(3, lambda);
return 0;
}
有警告,但可以通过编译

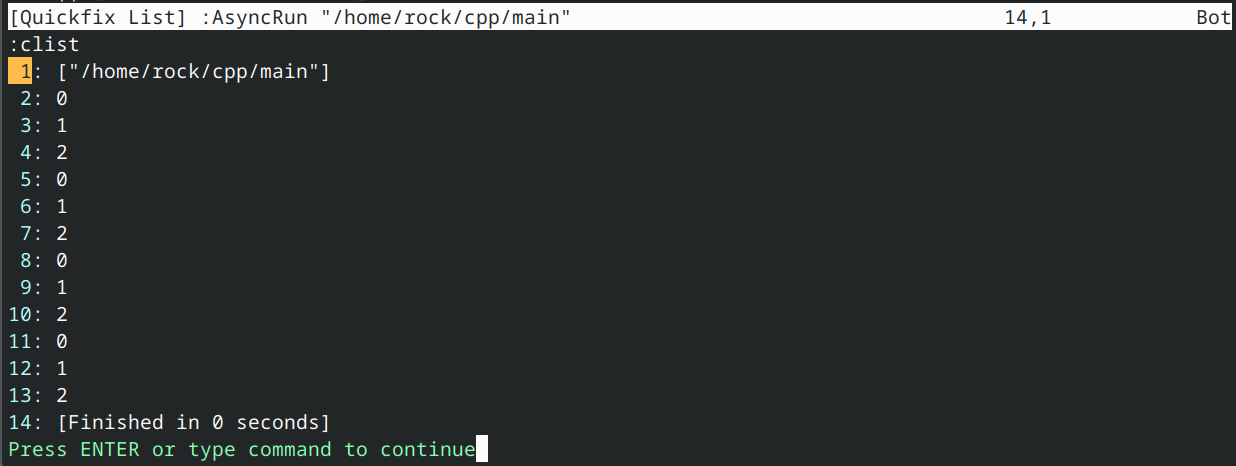
在情况1中,我们的函数参数是std::function类型。这种方式的优点在于能明确看到std::function的参数和返回类型。但每次调用函数时都需要隐式转换lambda表达式,这会增加额外开销。此方法还支持将声明(放在头文件)与定义(放在.cpp文件)分离,若需要这种分离性则尤为便利。
在情况2中,我们使用带类型模板参数T的函数模板。调用时会根据T匹配实际lambda类型实例化函数。这种方式更高效,但T的参数和返回类型不直观。
情况3采用C++20的auto特性调用简写函数模板语法,生成的函数模板与情况2完全一致。
情况4中函数参数为函数指针。由于无捕获的lambda表达式可隐式转换为函数指针,因此可直接向该函数传递无捕获的lambda表达式。
最佳实践:
将lambda存储在变量中时,请使用auto作为变量类型。向函数传递lambda时:
- 若支持C++20,请使用auto作为参数类型。
- 否则,请使用带类型模板参数的函数或std::function参数(若lambda无捕获则使用函数指针)。
泛型lambda表达式
在大多数情况下,lambda参数遵循与常规函数参数相同的规则。
一个显著的例外是:自C++14起,允许使用auto声明参数(注:在C++20中,普通函数也可使用auto声明参数)。当lambda包含一个或多个auto参数时,编译器将根据lambda的调用场景推断所需的参数类型。
由于包含auto参数的lambda可能处理多种类型,因此被称为泛型lambdageneric lambdas。
对于高级读者:
在lambda表达式中使用时,auto只是模板参数的简写形式。
让我们看一个泛型lambda示例:
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
int main()
{
constexpr std::array months{ // pre-C++17 use std::array<const char*, 12>
"January",
"February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December"
};
// Search for two consecutive months that start with the same letter.
const auto sameLetter{ std::adjacent_find(months.begin(), months.end(),
[](const auto& a, const auto& b) {
return a[0] == b[0];
}) };
// Make sure that two months were found.
if (sameLetter != months.end())
{
// std::next returns the next iterator after sameLetter
std::cout << *sameLetter << " and " << *std::next(sameLetter)
<< " start with the same letter\n";
}
return 0;
}
输出:
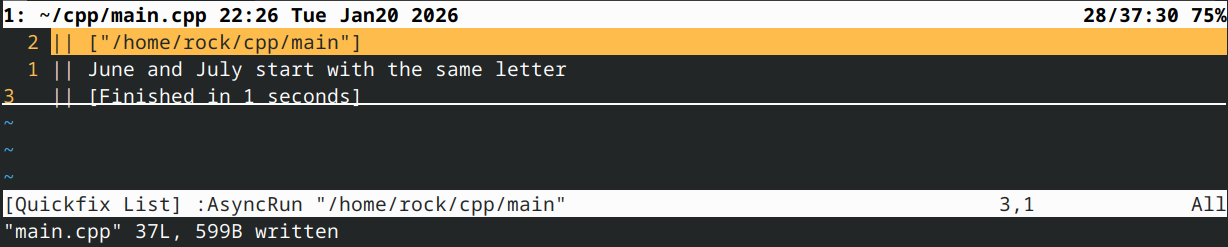
在上例中,我们使用 auto 参数通过 const 引用捕获字符串。由于所有字符串类型都允许通过 [] 运算符访问其单个字符,因此无需关心用户传递的是 std::string、C 风格字符串还是其他类型。这使得我们能够编写接受任意字符串的 lambda 表达式,意味着即使日后更改类型,也无需重写 lambda。
然而auto并非总是最佳选择。请考虑以下情况:
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
int main()
{
constexpr std::array months{ // pre-C++17 use std::array<const char*, 12>
"January",
"February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December"
};
// Count how many months consist of 5 letters
const auto fiveLetterMonths{ std::count_if(months.begin(), months.end(),
[](std::string_view str) {
return str.length() == 5;
}) };
std::cout << "There are " << fiveLetterMonths << " months with 5 letters\n";
return 0;
}
输出:
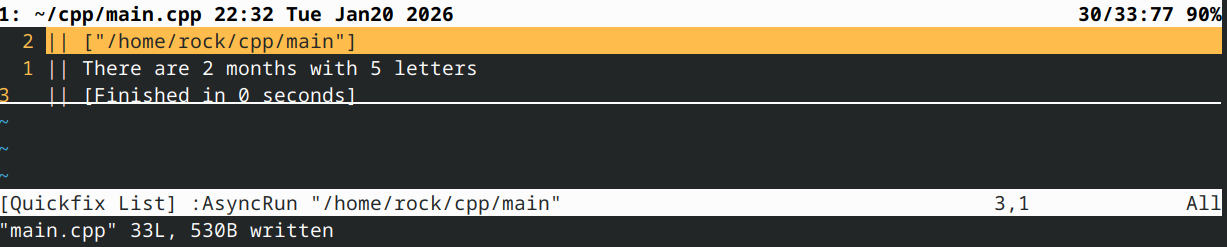
在此示例中,使用 auto 会推断出 const char* 的类型。C 风格字符串不易操作(除使用 [] 运算符外)。这种情况下,我们更倾向于显式将参数定义为 std::string_view,这能让我们更轻松地处理底层数据(例如,即使用户传入的是 C 风格数组,我们仍可查询字符串视图的长度)。
Constexpr lambdas
自C++17起,若lambda表达式的结果满足常量表达式的要求,则该lambda默认为常量表达式。这通常需要满足两个条件:
该lambda必须不包含捕获项,或所有捕获项均为常量表达式。
lambda调用的函数必须是constexpr。需注意,许多标准库算法和数学函数直至C++20或C++23才被声明为constexpr。
在上例中,该lambda在C++17中不会隐式成为constexpr,但在C++20中会(因std::count_if在C++20中被设为constexpr)。这意味着在C++20中我们可以将fiveLetterMonths设为constexpr:
constexpr auto fiveLetterMonths{ std::count_if(months.begin(), months.end(),
[](std::string_view str) {
return str.length() == 5;
}) };
泛型lambda表达式与静态变量
在第11.7节——函数模板实例化中,我们讨论过当函数模板包含静态局部变量时,每个从该模板实例化的函数都会获得独立的静态局部变量。若此行为非预期,则可能引发问题。
泛型lambda表达式遵循相同机制:对于自动解析出的每种不同类型,都会生成唯一的lambda表达式。
以下示例展示了一个泛型lambda如何转化为两个独立的lambda表达式:
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
int main()
{
// Print a value and count how many times @print has been called.
auto print{
[](auto value) {
static int callCount{ 0 };
std::cout << callCount++ << ": " << value << '\n';
}
};
print("hello"); // 0: hello
print("world"); // 1: world
print(1); // 0: 1
print(2); // 1: 2
print("ding dong"); // 2: ding dong
return 0;
}
输出:
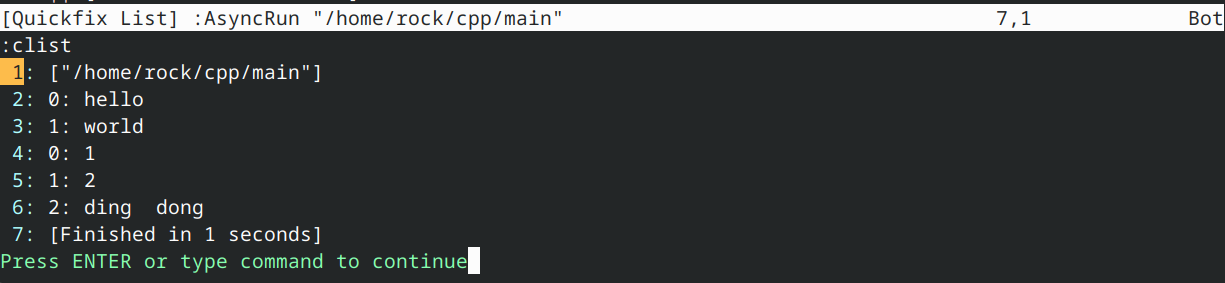
在上例中,我们定义了一个lambda表达式,随后使用两个不同参数(字符串字面量参数与整数参数)调用它。这将生成两个不同的lambda版本(一个带字符串字面量参数,一个带整数参数)。
多数情况下这无关紧要。但需注意:若泛型lambda使用静态持续期变量,这些变量不会在生成的lambda之间共享。
从上例可见,每种类型(字符串字面量和整数)都有独立的计数器!虽然我们只编写了一次lambda,却生成了两个实例——且各自拥有独立的callCount变量。若要使两个生成的lambda共享计数器,必须在lambda外部定义全局变量或静态局部变量。正如前课所述,全局变量和静态局部变量都可能引发问题并增加代码可读性难度。在下一课讲解lambda捕获机制后,我们将能避免使用此类变量。
返回类型推导与尾随返回类型
若使用返回类型推导,lambda表达式的返回类型将根据其内部的return语句推导得出,且所有return语句必须返回相同类型(否则编译器无法确定优先选择哪个类型)。
例如:
#include <iostream>
int main()
{
auto divide{ [](int x, int y, bool intDivision) { // note: no specified return type
if (intDivision)
return x / y; // return type is int
else
return static_cast<double>(x) / y; // ERROR: return type doesn't match previous return type
} };
std::cout << divide(3, 2, true) << '\n';
std::cout << divide(3, 2, false) << '\n';
return 0;
}
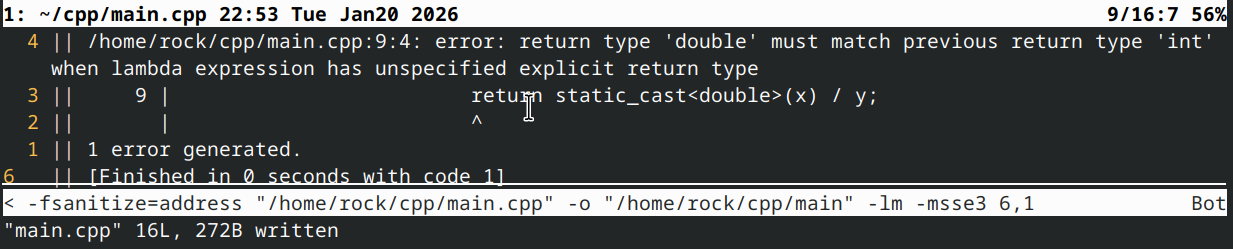
这会导致编译错误,因为第一个返回语句的返回类型(int)与第二个返回语句的返回类型(double)不匹配。
当需要返回不同类型时,我们有两种选择:
- 显式进行类型转换以使所有返回类型匹配,或
- 为lambda表达式显式指定返回类型,让编译器执行隐式转换。
通常第二种方案更优:
#include <iostream>
int main()
{
// note: explicitly specifying this returns a double
auto divide{ [](int x, int y, bool intDivision) -> double {
if (intDivision)
return x / y; // will do an implicit conversion of result to double
else
return static_cast<double>(x) / y;
} };
std::cout << divide(3, 2, true) << '\n';
std::cout << divide(3, 2, false) << '\n';
return 0;
}
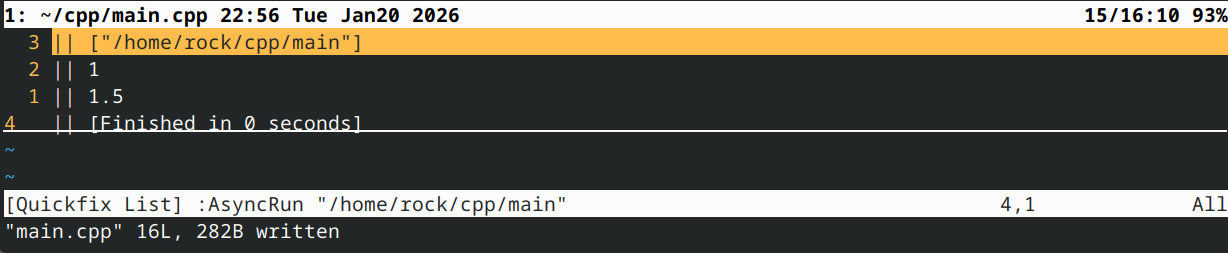
这样一来,如果你决定更改返回类型,通常只需修改lambda表达式的返回类型,而无需触碰lambda主体。
标准库函数对象
对于常见操作(如加法、取反或比较),您无需编写自己的lambda表达式,因为标准库提供了许多可替代的基本可调用对象。这些对象定义在< functional >头文件中。
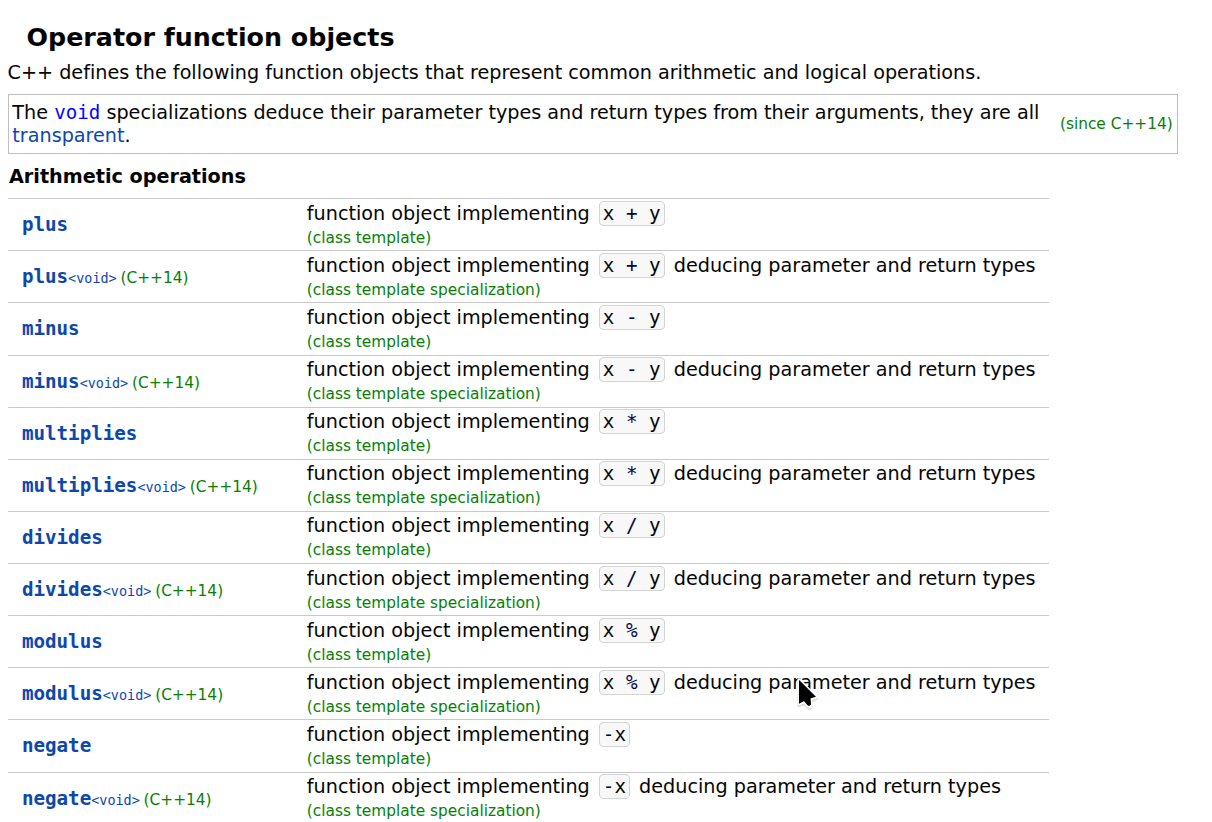
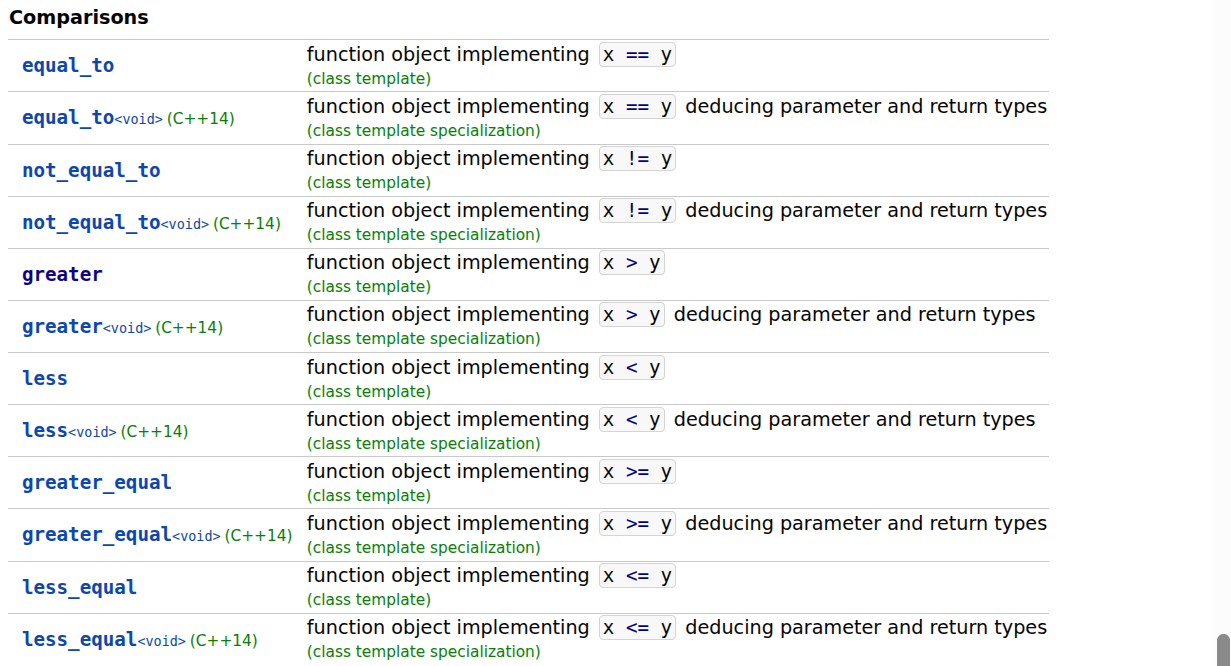
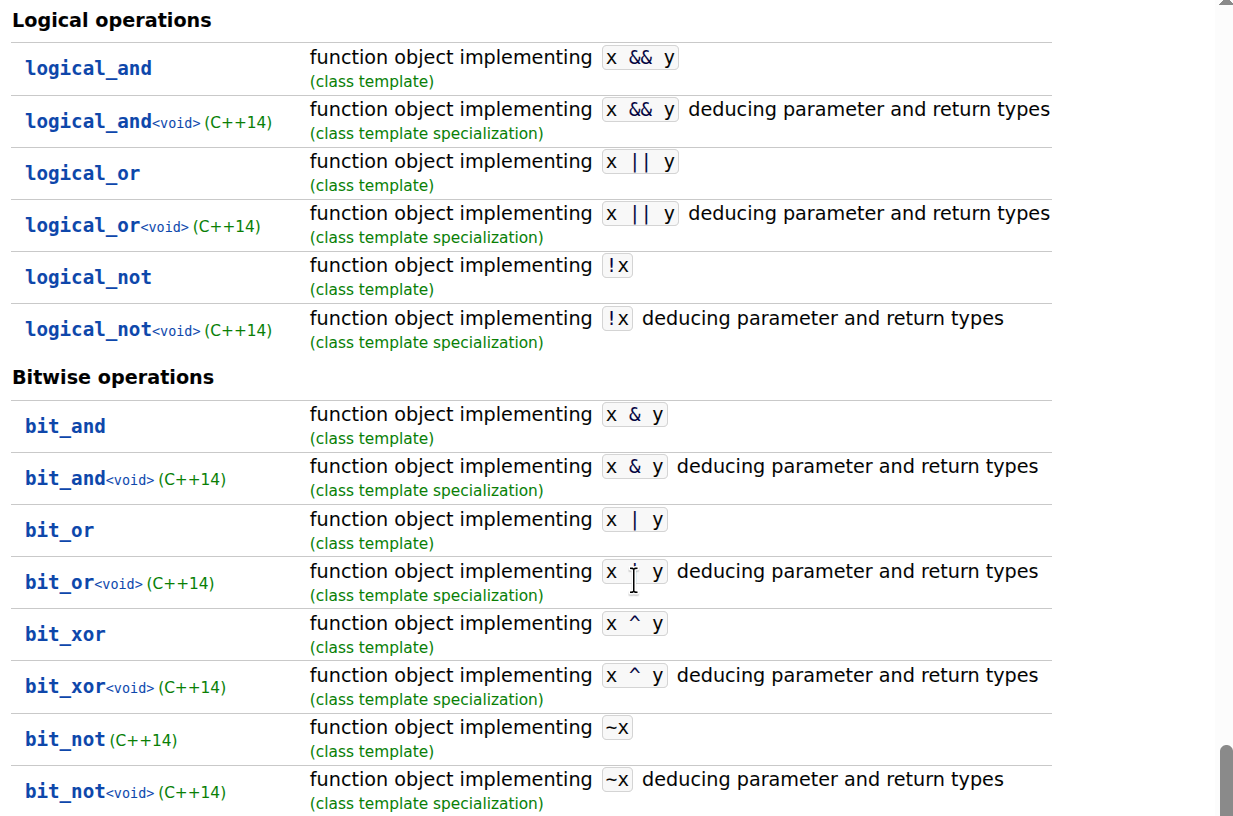
在下面的示例中:
#include <algorithm>
#include <array>
#include <iostream>
bool greater(int a, int b)
{
// Order @a before @b if @a is greater than @b.
return a > b;
}
int main()
{
std::array arr{ 13, 90, 99, 5, 40, 80 };
// Pass greater to std::sort
std::sort(arr.begin(), arr.end(), greater);
for (int i : arr)
{
std::cout << i << ' ';
}
std::cout << '\n';
return 0;
}
输出:
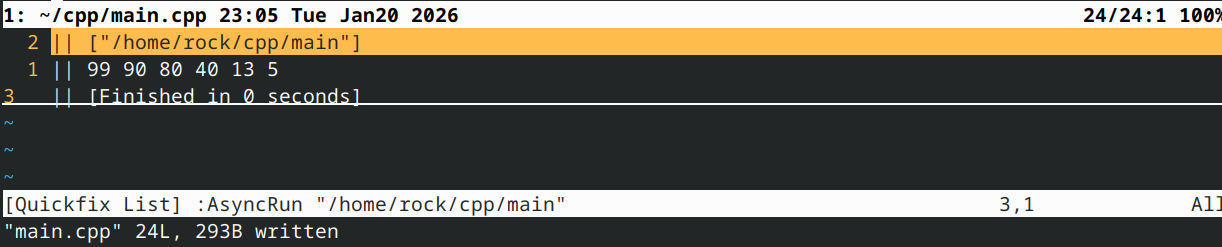
与其将我们的 greater 函数转换为 lambda 表达式(这会稍微模糊其含义),我们不妨直接使用 std::greater:
#include <algorithm>
#include <array>
#include <iostream>
#include <functional> // for std::greater
int main()
{
std::array arr{ 13, 90, 99, 5, 40, 80 };
// Pass std::greater to std::sort
std::sort(arr.begin(), arr.end(), std::greater{}); // note: need curly braces to instantiate object
for (int i : arr)
{
std::cout << i << ' ';
}
std::cout << '\n';
return 0;
}
输出:
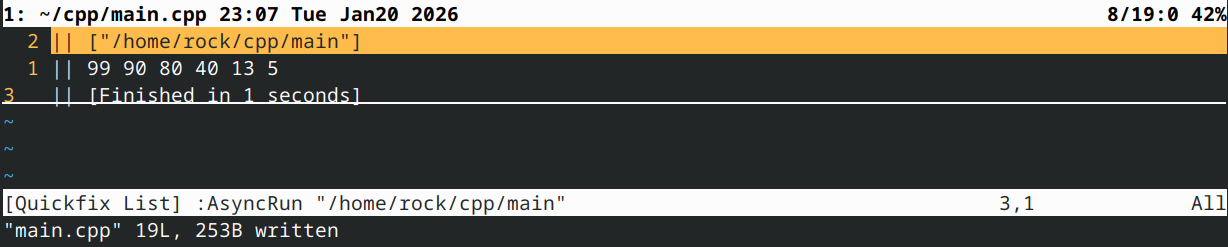
结论
相较于使用循环的解决方案,Lambda表达式与算法库的组合看似不必要地复杂。然而这种组合能在寥寥数行代码中实现极其强大的操作,且比自行编写循环更具可读性。更重要的是,算法库提供了强大且易用的并行处理能力——这是循环无法实现的。升级使用库函数的源代码比升级使用循环的代码更为简便。
Lambda表达式固然优秀,但并非适用于所有场景。对于非简单且可复用的情况,仍应优先选用常规函数。
测验时间
问题 #1
创建一个名为 Student 的结构体,用于存储学生的姓名和分数。创建一个学生数组,使用 std::max_element 查找得分最高的学生,并打印该学生的姓名。std::max_element 需要列表的起始和结束位置,以及一个接受两个参数的函数——该函数若第一个参数小于第二个参数则返回 true。
给定以下数组:
std::array<Student, 8> arr{
{ { "Albert", 3 },
{ "Ben", 5 },
{ "Christine", 2 },
{ "Dan", 8 }, // Dan has the most points (8).
{ "Enchilada", 4 },
{ "Francis", 1 },
{ "Greg", 3 },
{ "Hagrid", 5 } }
};
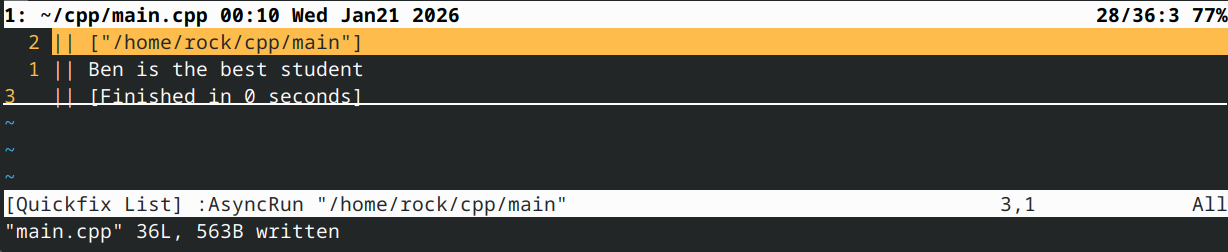
你的程序应该输出
Dan is the best student
显示提示
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
struct Student
{
std::string_view name{};
int points{};
};
int main()
{
constexpr std::array<Student, 8> arr{
{ { "Albert", 3 },
{ "Ben", 5 },
{ "Christine", 2 },
{ "Dan", 8 },
{ "Enchilada", 4 },
{ "Francis", 1 },
{ "Greg", 3 },
{ "Hagrid", 5 } }
};
const auto best{
std::max_element(arr.begin(), arr.end(), /* lambda */) // returns an iterator
};
std::cout << best->name << " is the best student\n"; // must dereference iterator to get element
return 0;
}
显示解答
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
struct Student
{
std::string_view name{};
int points{};
};
int main()
{
constexpr std::array<Student, 8> arr{
{ { "Albert", 3 },
{ "Ben", 5 },
{ "Christine", 2 },
{ "Dan", 8 },
{ "Enchilada", 4 },
{ "Francis", 1 },
{ "Greg", 3 },
{ "Hagrid", 5 } }
};
const auto best { // returns an iterator
std::max_element(arr.begin(), arr.end(), [](const auto& a, const auto& b) {
return a.points < b.points;
})
};
std::cout << best->name << " is the best student\n"; // must dereference iterator to get element
return 0;
}
问题 #2
在以下代码中使用 std::sort 和 lambda 表达式,按平均温度升序对季节进行排序。
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
struct Season
{
std::string_view name{};
double averageTemperature{};
};
int main()
{
std::array<Season, 4> seasons{
{ { "Spring", 285.0 },
{ "Summer", 296.0 },
{ "Fall", 288.0 },
{ "Winter", 263.0 } }
};
/*
* Use std::sort here
*/
for (const auto& season : seasons)
{
std::cout << season.name << '\n';
}
return 0;
}
该程序应输出
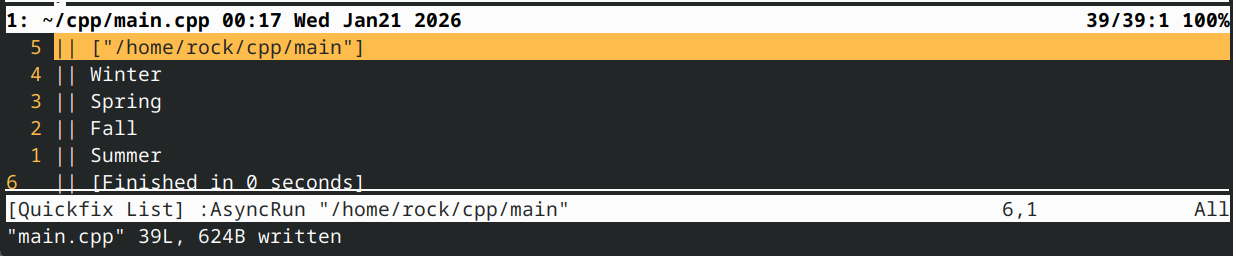
显示解决方案
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
struct Season
{
std::string_view name{};
double averageTemperature{};
};
int main()
{
std::array<Season, 4> seasons{
{ { "Spring", 285.0 },
{ "Summer", 296.0 },
{ "Fall", 288.0 },
{ "Winter", 263.0 } }
};
// We can compare averageTemperature of the two arguments to
// sort the array.
std::sort(seasons.begin(), seasons.end(),
[](const auto& a, const auto& b) {
return a.averageTemperature < b.averageTemperature;
});
for (const auto& season : seasons)
{
std::cout << season.name << '\n';
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号