是什么引起了各个框架 Resize 操作的结果不同?——来自 ONNX 的标准化尝试
来源:https://zhuanlan.zhihu.com/p/107761106?tdsourcetag=s_pctim_aiomsg
炼丹师在转换模型的时候,经常会发现给转换前后的模型输入同样的图片,模型结果有微小的差别。其中的原因有数值算法的误差、不同 jpeg 解码库产生的结果不同等等,也有不同框架内部对某些算子的实现差异。
在给 ONNX 贡献 Resize 算子的 spec 的时候,我发现 Resize 是一个突出体现了框架实现差异的算子——多种 Resize 类型、不统一的超参数、将错就错的历史遗留 bug 和其它极易被忽略的问题集中在一起,导致几乎每个框架的 Resize 操作的结果都有差异,而 ONNX 是一个神经网络模型的中间格式,它应该尽量保留原始框架的算子的语义。经过查看相关论文和各种框架的源代码,我分析和总结了 Resize 操作众多的实现方式。最终为 ONNX 贡献了一个较为完善的、标准化的 Resize 算子的 spec,它包含多个(基本)正交的参数,TensorFlow 1.x、TensorFlow 2.x、PyTorch、OpenCV 的 resize/interpolation 方法都可以用这个算子 100% 无损的表达。本文将简单介绍各种 resize 操作的共同流程,并分析是哪些因素引起了不同框架 resize 操作的不同。
多维 tensor (例如二维图像)的 resize 操作是用多个在一维 tensor 上进行的 resize 操作组合出来的,所以我们只讨论一维 tensor 上的 resize 操作,经过分析各个框架的源代码,我发现它的流程可以总结如下:
设输出 tensor 长度为 length_out,遍历 i∈[0,length_out) ,对每一个 i
- 得到第 i 个像素点在 tensor 上的坐标 x=w(i)
- 计算 x 在输入 tensor 中的对应坐标 x′=f(x) ,它是输入 tensor 中的第 i′ 个像素点,这里i′=w−1(x′) (即在输入 tensor 上,用 w 的反函数把 x′ 变换回去,这样第三步找相邻像素点使用的坐标才是正确的),注意 x′ 和 i′ 都是浮点数
- 找到输入 tensor 中和第 i′ 个像素在空间上相邻的 N 个像素的像素值 a=g(i′) 和 i′ 距左侧像素点的距离 r,此处 a 是一个长度为 N 的数组, r 是一个浮点数
- 计算它们的加权平均值 h(a,r) ,计算加权平均值所用的权重是根据 r 决定的
所以设 i′=w−1(f(w(i))) ,那么 h(g(i′),r) 就是第 i 个像素点的像素值。
不同的 resize 实现,就是在这四个函数 w 、 f 、 g 、 h 的实现上有所不同。
先讨论 w 和 f , w(i) 是第 i 个像素点的坐标,乍一看, w(i) 完全可以等于 i 本身,其实没有这么简单。例如一个长度为 3 的 tensor,如果第 i 个像素点的坐标等于 i 本身,那么三个像素点在 tensor 中的位置就如下图中最左边的样子,横线的长度代表一维 tensor 的长度,圆圈代表像素点:
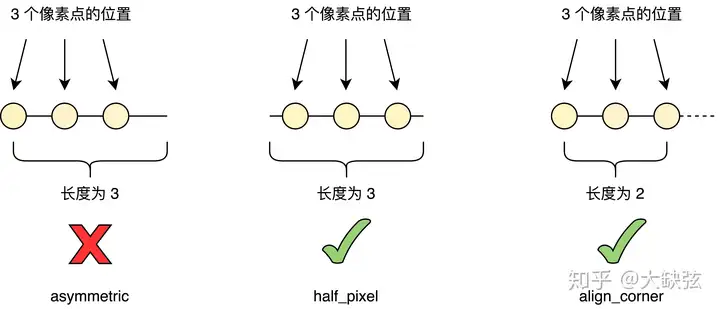
三个像素点没有对称地分布在 tensor 上,而是往左偏了。出于直觉,我们觉得这不是一件特别好的事情。在各种框架中,有两种常见的方法来解决这个问题:
一个是选取 w(i)=i+0.5 ,以一个长度为 3 的一维 tensor 为例,它第 0 个像素点在 0.5 位置,第 1 个像素点在 1.5 位置,第 2 个像素点在 2.5 位置,这称为 half_pixel,也就是上图中中间的方法。这种方法中,f(x)=x∗length_inlength_out(这很符合直觉)。
另一个是仍让 w(i)=i ,但改变函数 f ,使 f(x)=x∗length_in−1length_out−1 ,仍以长度为 3 的一维 tensor 为例,这种方法相当于在 resize 时砍掉了最右边长度为 1 的部分,使像素点的分布“被”对称了。这称为 align_corner,也就是上图中最右边的方法,在各种框架的 resize 方法的参数里常见的 align_corner=True/False 就是它了,它的名字来源于它可以让 tensor 中第一个和最后一个像素(即 corner)在缩放后保持不变。
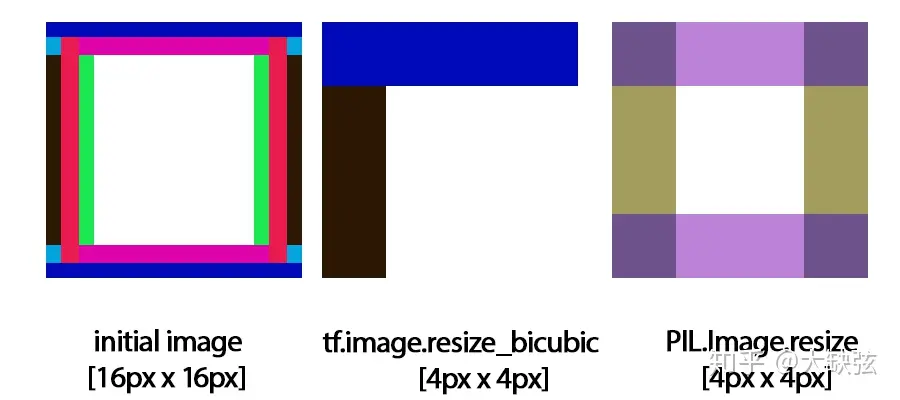
那如果我们不采用这两种方法,一定要使用“直觉不好”的 asymmetric 方法,究竟会发生什么呢?TensorFlow 1.x 就给我们提供了这样一个反面典型,它在 align_corner=False 时的实现是错的,原因就是使用了上图中错误的 asymmetric 方法,这会导致奇怪的缩放结果,这篇博客 中,作者用 TensorFlow 1.x 训练的超分辨率神经网络总是出现奇怪的问题,最终他发现问题根源是 TensorFlow 错误的 resize 实现,他还给了一个形象的例子:把 16x16 的下图左侧图像缩小到 4x4,本应得到如下图右侧所示的图像,而 TensorFlow 1.x 却给出了下图中间的奇怪结果,图像的对称性被完全破坏了,其中的原因就如上文所述。TensorFlow 1.x 的 resize 结果和其它框架不同的一大原因就是它错误的 resize 实现,好在 TensorFlow 2.x 已经修复了这个问题。
接下来讨论另外两个函数 g 和 h ,nearest, linear, cubic 这三种常见的 resize 的不同方式,是在 g 和 h 上有所不同。 如上文所述,函数 g(i′) 得到离 i′ 最近的像素点,nearest 只需要找最近的一个像素点,linear 要找最近的两个(左右各一个),cubic 要找最近的四个(左右各两个);函数 h(a,r) 是计算这一个/两个/四个像素点的加权平均值,其中权值是由 r 确定的(如上文所述,r 是 i′ 距左侧像素点的距离)。对 nearest/linear/cubic 的每一种来说,如何从 r 得到各个像素点的权值都有各自标准的实现,nearest resize 不必说,对于 linear resize,两个像素点的权值是
(1−rr)
对 cubic 来说,四个像素点的权值是
(((A∗(r+1)−5∗A)∗(r+1)+8∗A)∗(r+1)−4∗A((A+2)∗r−(A+3))∗r∗r+1((A+2)∗(1−r)−(A+3))∗(1−r)∗(1−r)+1((A∗((1−r)+1)−5∗A)∗((1−r)+1)+8∗A)∗((1−r)+1)−4∗A)
[1]其中 A 是一个固定的参数,它的取值却是每个框架不同,两个常见的选择是 -0.5 (TensorFlow 部分版本的实现)和 -0.75(PyTorch)。因为 A 没有统一的标准取值,所以各个框架的 cubic resize 结果不同是常见的事情。
补充一句题外话:cubic resize 的权值计算起来比 linear resize 复杂的多,所以它的耗时肯定会长一些,但产生的图像性质更好(这篇 paper 发现图片预处理使用 cubic resize 可以提升分类网络准确率。(更新:根据评论区,我又看了看这篇 paper,竟然找不到 cubic resize 相关的内容了。。))。
还有一个会引起 cubic resize 结果差异的细节是,cubic resize 需要找到 i′ 的左右各两个最相邻的像素点,但 i′ 左右两侧不一定能保证各有两个像素点(假设某种情况下计算得到 i′=0.6 ,那么它左边只有一个像素点),此时也有两种现存的不同方法,一种是对图像做 edge padding,即认为仍从左边找到了两个像素点,并且这两个像素点的值都是第一个像素点的值;另一种是认为找到了三个而不是四个像素点,并对三个像素点的权值做归一化。
此外还有一个易被忽略但影响很大的细节,如果 Resize 操作接受的参数是缩放比例 s (例如缩放 1/2 倍)而不是目标大小 length_out , length_out 则要根据 s∗length_in 计算得到,当这样计算得到的 length_out 不是整数的时候(例如 length_in=7,s=13 ),有些框架(例如 PyTorch)会把 length_out 取整,而有些不会。至于如何取整,又有 round、floor、ceil 三种不同的方法。
总结一下,各个框架 Resize 操作的结果不同的原因是多种多样的,例如 TensorFlow 用了自己发明的错误实现 ♂️、cubic resize 中参数 A 没有固定的取值、非整数的 length_out 是否自动取整等等。
ONNX Resize 算子的 spec 就是基于上面的分析写出来的,具体的描述在 https://github.com/onnx/onnx/blob/master/docs/Operators.md#Resize,Python 版的参考实现在 https://github.com/onnx/onnx/blob/master/onnx/backend/test/case/node/resize.py,其中比较核心的属性 coordinate_transformation_mode 是把 w 、 f 和 w−1 复合得到的单个函数 f′,即i′=f′(x)=w−1(f(w(i))) 。在这里没有用独立的函数 w 和 f 的原因除了看起来更简单之外,也有解决现实问题的考虑——有一些框架的某些 resize 实现没有使用 i′=w−1(f(w(i))) 的形式,而是直接让 i′=f(w(i)) ,虽然这显然是不合理的(coordinate_transformation_mode=tf_half_pixel_for_nn 就描述了这样一个不合理的实现),但也只能承认它们的存在(更新:后来发现 tf_half_pixel_for_nn 其实是经过了一个优化 trick 的公式,可以被其它参数的组合覆盖:https://github.com/onnx/onnx/pull/3026 )。相比起来,上一个版本的 ONNX Resize 算子 spec 的制定者没有意识到 Resize 算子的复杂性,完全模仿了 TensorFlow 的实现,不仅和其它框架的结果不一致,而且连 TensorFlow 的 bug 也一并模仿了。
现在 TensorFlow、PyTorch 都支持了导出这一版本的 Resize 算子,TensorRT 等部署框架也支持导入和运行这个 Resize 算子。我创造的东西能被众多知名框架跟进,奥利给

 浙公网安备 33010602011771号
浙公网安备 33010602011771号