
清华+快手联合提出 FilmWeaver 框架,攻克多镜头视频生成一致性难题
清华+快手联合提出 FilmWeaver 框架,攻克多镜头视频生成一致性难题
01 论文概述
每一部电影都是一个由镜头编织的梦境,但今天的AI却困在“单帧梦境”里。
尽管视频生成模型已能合成逼真的短片段,它们却难以讲述一个连贯的故事:当镜头切换,角色样貌会变幻不定,背景会突兀跳跃,叙事也会随之断裂。
这背后是两个根本的脱节:镜头之间缺乏记忆,导致角色与场景身份丢失;镜头内部缺乏流畅,使得运动生硬不连贯。现有方法或将多镜头压缩为单一序列,但这种方式牺牲了时长灵活性;或依赖复杂多模型管线的方法,这种方法会引入视觉断层。

为解决这一问题,清华大学深圳国际研究生院与快手Kling团队提出了FilmWeaver框架,其核心创新在于将一致性问题解耦为镜头间一致性与镜头内连贯性两个层面,并设计了一个双层缓存机制:
-
时间缓存(短期记忆):记住当前镜头的近期画面,让动作、画面流畅不卡顿;
-
镜头缓存(长期记忆):保存之前镜头的关键信息,确保角色、背景跨镜头不 “变样”。
模型结合文本提示和这两种记忆来生成视频,核心就是让多镜头内容既连贯又统一。
论文名称:FilmWeaver: Weaving Consistent Multi-Shot Videos with Cache-Guided Autoregressive Diffusion
论文链接:https://arxiv.org/pdf/2512.11274
Github地址:https://filmweaver.github.io/

02 方法
FilmWeaver的核心创新是 “自回归扩散 + 双级缓存” 的协同设计,通过 “解耦镜头间一致性与镜头内连贯性”,同时解决 “一致性” 与 “可控性” 问题,以确保能够生成任意长度和镜头数量的多镜头视频。
1. 双层次缓存机制(解决问题的核心引擎)
双级缓存分别负责 “镜头间长期一致性” 和 “镜头内短期连贯性”,且均通过上下文注入实现(无需修改模型架构,兼容性强)。
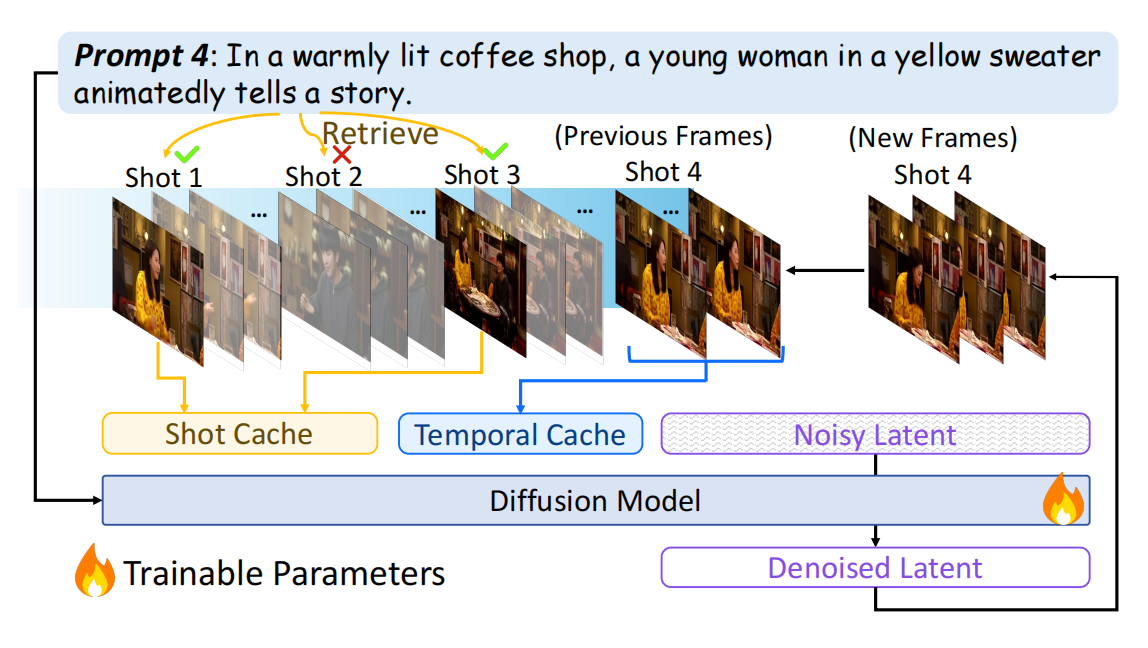
- 时序缓存:负责镜头内连贯性。它是一个压缩的滑动窗口,存储当前镜头中刚生成的最新几帧的隐表示。窗口内的帧按时间远近进行不同程度的压缩(越近的保留越完整),从而以低成本保证动作流畅、无闪烁。
- 镜头缓存:负责跨镜头一致性。当需要生成一个新镜头时,系统会根据新提示词,从之前所有镜头的关键帧库中,通过CLIP语义相似度检索出最相关的K帧。这些帧作为视觉“锚点”,注入生成过程,确保角色、风格、背景的延续。
2. 四阶段推理流程(架构的动态工作模式)
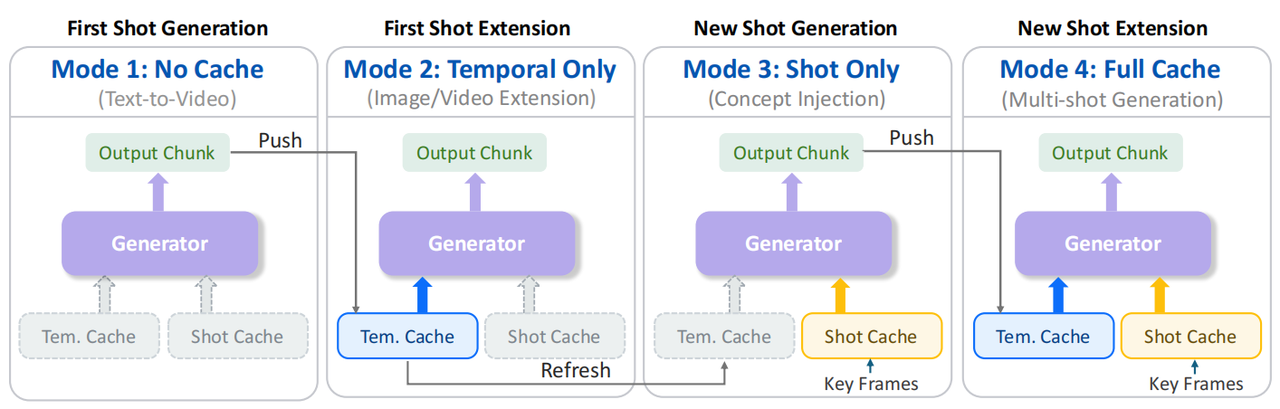
基于缓存的不同状态,我们的框架灵活支持四种生成模式,覆盖了从零开始创作到中途编辑的全流程:
- 模式1(无缓存):故事开篇,生成第一个镜头,并填充初始缓存。
- 模式2(仅时间缓存):延伸当前镜头,用于制作长镜头或视频扩展。
- 模式3(仅镜头缓存):开启新镜头,继承历史镜头的关键视觉元素,实现场景转换。
- 模式4(全缓存):在新镜头中继续延伸,同时保持长期一致与短期流畅。
3.训练策略
FilmWeaver的训练策略可概括为:采用两阶段渐进式课程学习,并结合针对性的数据增强,以稳定、高效地训练模型掌握双重缓存机制。其核心设计如下:
- 两阶段课程:
- 第一阶段(学连贯):仅启用时间缓存,训练模型生成长而连贯的单镜头视频,使其掌握镜头内的运动动力学基础。
- 第二阶段(学一致):同时启用时间缓存与镜头缓存,在混合了四种推理模式的数据上对模型进行微调,使其学习在保持镜头内连贯的同时,实现跨镜头的视觉一致性。
- 关键增强策略:
- 负采样:在镜头缓存中随机引入无关关键帧,迫使模型学会根据提示词甄别有用信息。
- 非对称噪声注入:对镜头缓存施加强噪声以鼓励创新并防止“复制粘贴”;对时间缓存仅施加弱噪声以保护运动连贯性。此举有效缓解了模型对缓存的过拟合,显著提升了其文本提示跟随能力。
4.多镜头数据集构建
论文构建的一个高质量多镜头视频数据集,开发了一套完整的数据构建流水线。该流水线主要包含以下步骤:
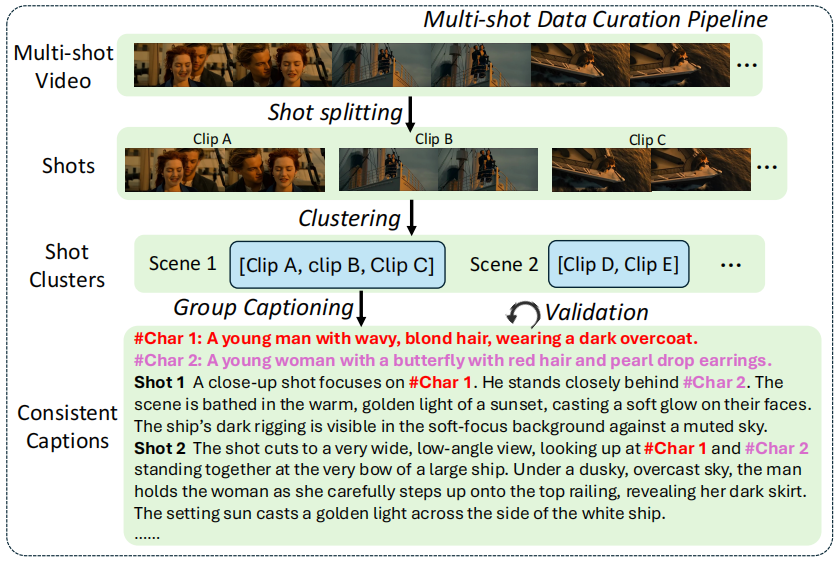
- 镜头切分:使用一个专家模型(如Panda-70M)将原始长视频分割成独立的镜头。
- 场景聚类:利用CLIP特征计算镜头间的相似度,通过滑动窗口聚类,将描述同一场景或事件的多个镜头聚合成一个多镜头序列。
- 分组标注:将同一个场景聚类中的所有镜头(通常2-5个)作为一个整体,输入给Gemini 2.5 Pro大语言模型,让它为所有镜头同时生成描述。这种“联合标注”策略是关键,它能强制模型在描述中保持同一角色外观、物体属性在不同镜头间的一致性。
- 验证与过滤:对生成的描述进行验证和精炼,并过滤掉过短(<1秒)或人物过多(>3人)的片段,以保证数据质量。
对于评测,论文同样指出缺乏公开基准,因此作者使用 Gemini 2.5 Pro 根据一个精心设计的提示(要求生成包含5个镜头、角色描述严格一致的电影场景),构造了20个全新的多镜头叙事场景作为测试集。
03 实验效果
1. 定量结果
论文在自建的多镜头测试集上,从 “视觉质量”、“一致性”和“文本对齐” 三个核心维度,将FilmWeaver与三类主流方法进行了全面量化对比。
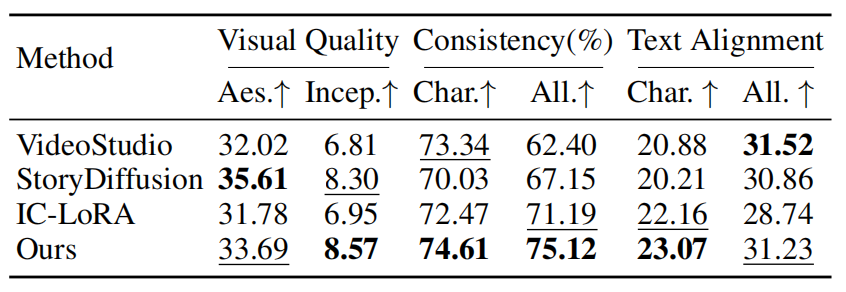
- 一致性:FilmWeaver在角色一致性和整体一致性两项指标上均取得最高分(74.61% 和 75.12%),显著领先其他方法。这直接证明了其双层缓存机制在维持跨镜头稳定性的有效性。
- 文本对齐:在角色层面的文本对齐指标上,FilmWeaver同样排名第一(23.07%),表明其能更好地根据提示词生成并保持特定角色特征。
- 视觉质量:FilmWeaver取得了最高的Inception Score,代表其生成内容的多样性和真实性最佳。虽然在美学评分上略低于StoryDiffusion,但在所有指标综合表现上最为均衡和突出。
2. 定性结果
场景一:多人对话(交替使用全景与特写)

- 现有方法问题:出现了严重的身份混淆。不同角色的面部特征、服装细节在镜头间发生混合与错乱,导致“A角色的脸配B角色的衣服”。同时,背景(如墙上的画)在镜头间无法保持一致。
- FilmWeaver表现:成功稳定保持了每位角色的独特外观,并且背景细节在切换镜头时完全一致,镜头3中男子身后的壁画等细节与镜头1完全一致。这证明了Shot Cache在区隔并记忆多个独立概念上的能力。
场景二:动态动作序列

- 现有方法问题:在动作过程中,角色外观会发生不可控的抖动与变化。
- FilmWeaver表现:在激烈的运动下,FilmWeaver始终保持稳定角色身份和服装。
04 总结与展望
本文提出了 FilmWeave,一种基于缓存引导的自回归扩散框架,用于解决多镜头视频生成中的跨镜头一致性与镜头内连贯性问题。
1. 新颖的双层缓存机制
- Shot Cache:通过检索历史镜头中的关键帧,实现长期视觉概念(如角色、场景)的持久记忆与一致性保持。
- Temporal Cache:采用压缩滑动窗口保存近期帧,确保镜头内运动的自然流畅。
2. 灵活的四模式推理框架
支持从首镜头生成、镜头延伸、新镜头过渡到全缓存生成的全流程,允许用户交互式构建任意长度与镜头数的视频叙事。
3. 高质量数据构建流程
针对多镜头数据缺失问题,设计了一套从镜头切分、场景聚类到分组标注的数据构建流水线,并构建了用于评测的多镜头测试集。
未来工作可从数据、控制与效率三方面推进:进一步提升多镜头训练数据的规模与标注精度;探索结合语义剧本的更强叙事控制;优化缓存检索与压缩机制以支持更复杂、更长的电影级生成任务。
GitLink开源创新服务平台与Lab4AI大模型实验室联合发起「论文头号玩家」论文复现计划。寻找百万「论文头号玩家」计划 | 首批复现体验官开放申请,最高可获500元算力金!本计划开放高性能H800 GPU算力,旨在降低复现门槛,推动学术成果的实践转化。
参与活动您将获得:

关注“大模型实验室Lab4AI”,第一时间获取前沿AI技术解析!
点击阅读原文,跳转至Lab4AI官网,领取算力福利~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号