榨干H100算力!GLM-4.6V×vLLM 极致推理实战:从9B到106B MoE的全链路优化
榨干H100算力!GLM-4.6V×vLLM 极致推理实战:从9B到106B MoE的全链路优化
我是大模型实验室Lab4AI,一个面向高校科研人员、AI开发者、行业用户及AIGC创作者的高性能GPU场景内容社区,持续分享火热项目实战。
最近,我完成了一个GLM-4.6V与vLLM的深度整合项目,成功在H100上实现了从轻量版9B到106B MoE模型的全链路推理优化。
今天,就带大家揭秘如何用vLLM榨干H100的每一滴算力!
01 项目背景
当“原生多模态”遇上“混合专家”.
智谱AI开源的GLM-4.6V系列代表了当前VLM(Vision-Language Model)的架构巅峰,但也给工程部署带来了前所未有的挑战:
-
双极分化的架构挑战:
- 9B Flash版:参数小,但在高并发场景下,如何避免Vision Encoder成为瓶颈?如何喂饱H100的巨大算力?
- 106B MoE版:1060亿参数/120亿激活的MoE架构,对显存带宽和通信拓扑提出了严苛要求。
-
长上下文与多模态的显存黑洞:
支持128k上下文意味着KV Cache的显存占用呈指数级增长;“图像即参数”的原生工具调用机制,要求推理引擎必须高效处理异构数据流。
而硬件方面,NVIDIA H100 80GB SXM5是AI算力的天花板,但实际部署中,我们常痛心地发现算力被浪费:显存墙导致并发数上不去,FP8算力闲置,小模型无法极致并发。
面对这些痛点,我们基于vLLM框架,通过一系列工程手段,实现了从“跑通”到“极致”的跨越。而完成这次项目实战的破局点就在:
-
FP8 KV Cache(Hopper 专属):
利用 H100 的 Transformer Engine,将 KV Cache 显存占用直接砍半,在单卡上实现 128~150 个并发。
-
并发调优:
将长 Prompt 拆解计算,防止显存峰值瞬间爆炸(OOM),同时显著降低首字延迟(TTFT)。
-
异构计算调度:
让 Vision Tower 在数据并行模式下运行,消除多图输入时的流水线空转。
我们先来看看,如何通过两个实战项目,带你体验vLLM的极致推理与H100算力压榨。

02 实战一 驯服巨兽4×H100 扛起 GLM-4.6V-106B(MoE)
大模型实验室项目体验
首先进入项目,在 大模型实验室Lab4AI 中搜索项目榨干 H100 算力!GLM-4.6V × vLLM 极致推理实战:从 9B 到 106B MoE 的全链路优化,建议开启4卡进行体验。
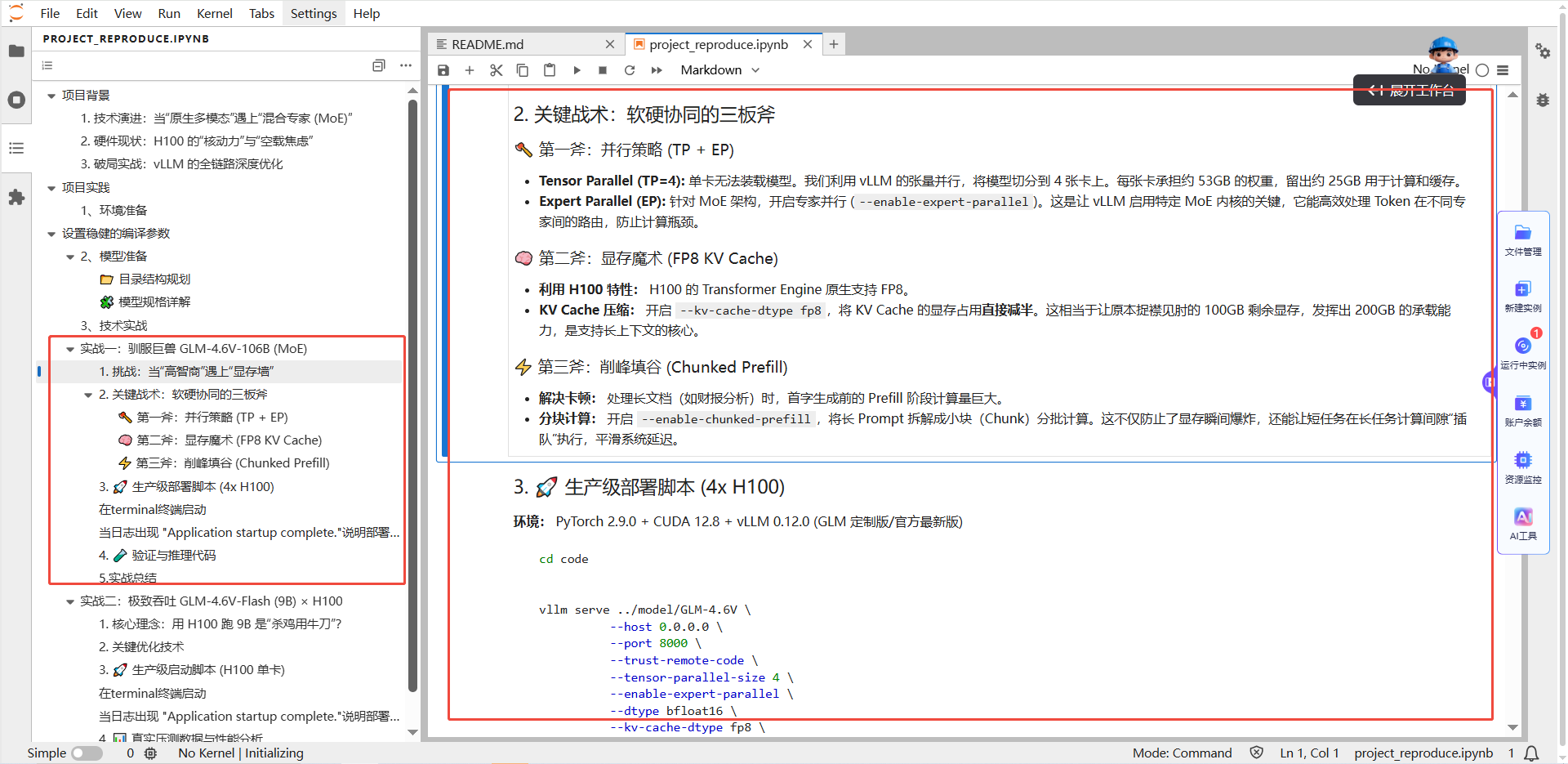
GLM-4.6V-106B 是典型的“高智商、大胃王”:虽然它的激活参数只有 12B(推理快),但静态权重高达 212GB (FP16),加上 128k 上下文产生的巨大 KV Cache。如何在 H100 上不炸显存且跑满算力,是本次实战的核心。
核心战术:三位一体优化.
- 并行切分 (TP4 + EP): 利用张量并行 (TP=4) 将模型切分至 4 张卡,并开启专家并行 (EP) 释放 MoE 推理性能。
- 显存魔术 (FP8 KV): H100 的 Transformer Engine 原生支持 FP8,我们利用H100的特性,开启 --kv-cache-dtype fp8,将KV Cache的显存占用减半,让100GB 剩余显存发挥出200GB 的承载力。
- 削峰填谷 (Chunked Prefill): 开启分块预填充,防止长文本首字生成时显存瞬时爆炸 (OOM) 。
配置完成后,在终端进行启动:
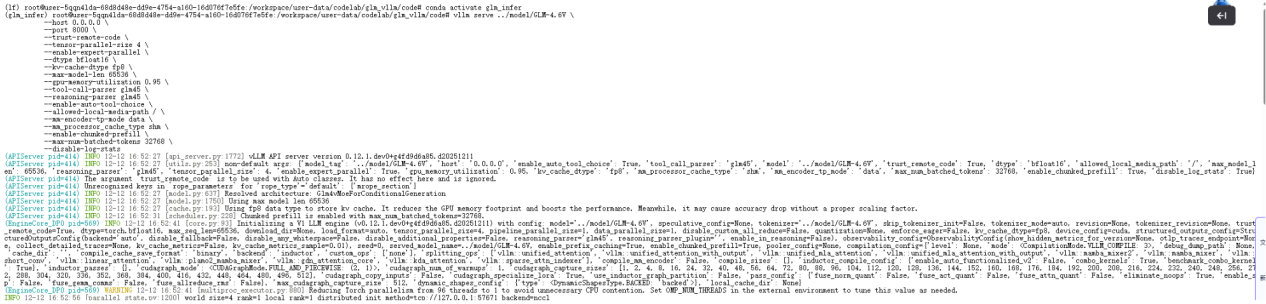
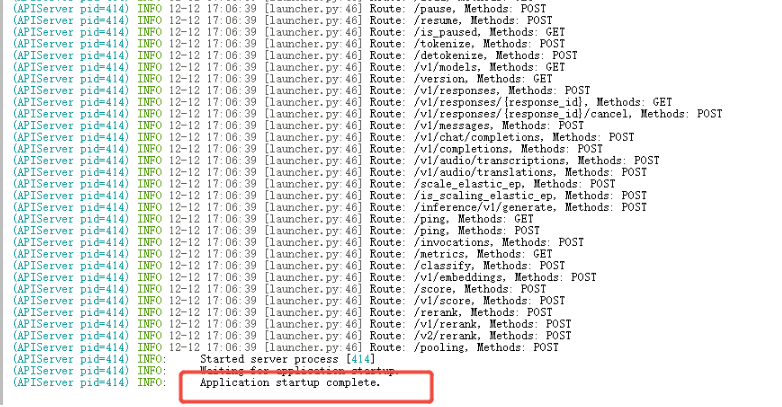
当日志出现 "Application startup complete."说明部署完成
服务启动后,推荐使用OpenAI SDK 进行调用。该代码支持本地图片读取并在 Jupyter 环境中预览。直接在ipynb中的代码块部分填入url和key即可,运行代码,可以查看如下:

实战总结:通过上述配置,我们成功将GLM-4.6V-106B 部署在 4 张 H100 上,利用 FP8 KV Cache 解决了长文本显存瓶颈,并通过 Expert Parallel 释放了 MoE 架构的推理性能。这是一个可直接用于生产环境的高性能方案。
03 实战二
单卡 H100 把 9B Flash 榨到“接近物理上限”.
9B 模型在 H100 上的权重仅占 20GB,剩余 60GB 显存如果闲置就是极大的浪费。普通的部署方式(默认配置)就像开着一辆核动力大巴车,却只允许坐 20 个人,极其浪费。
我们的目标是通过FP8 KV Cache 和超大并发槽位,把这60GB显存塞满,实现单卡9000+ tokens/s 的吞吐奇迹。
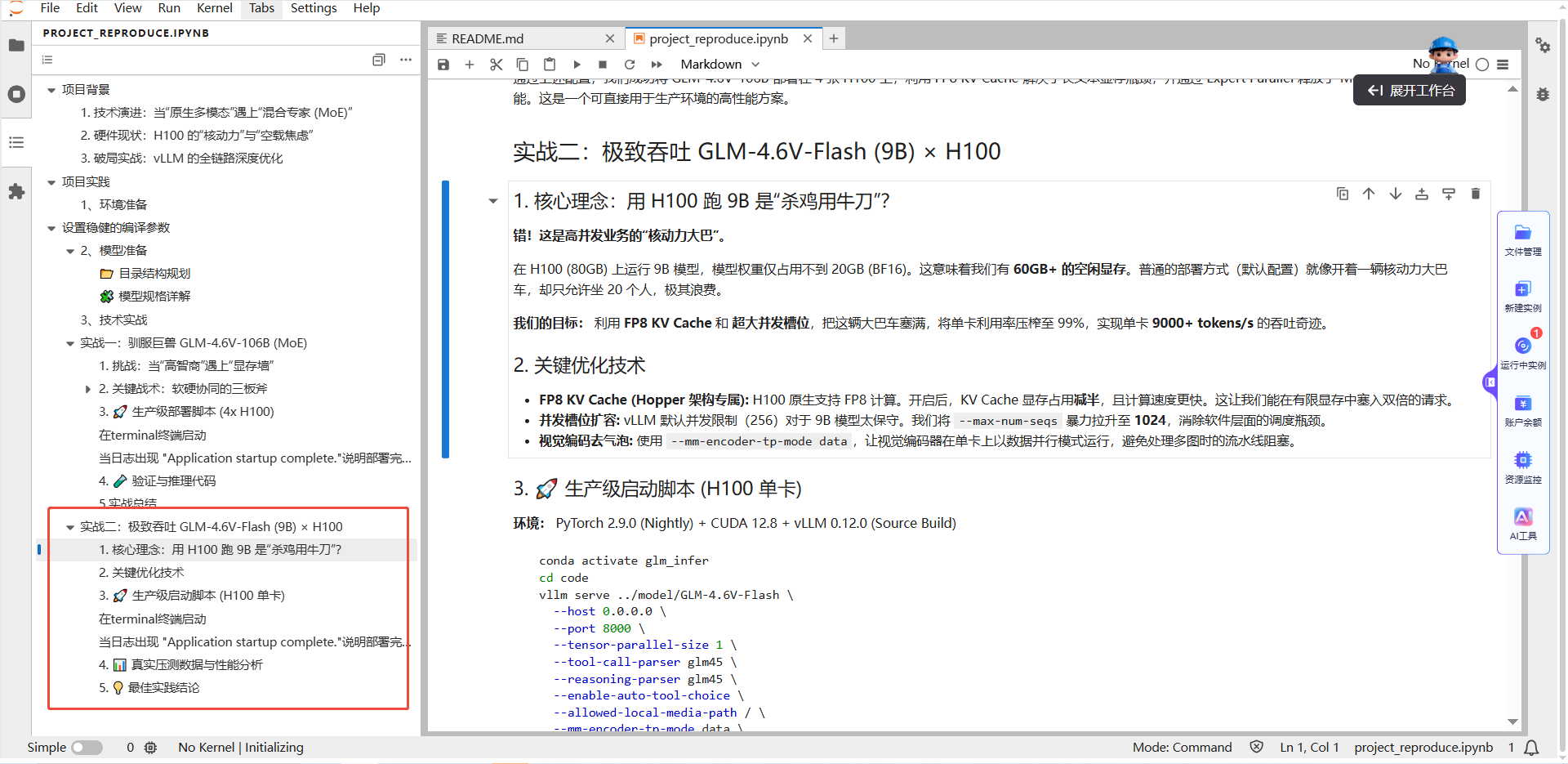
核心战术:把大巴车塞满.
- 空间翻倍(FP8 KV): 开启FP8 KV Cache,显存占用直接减半,让有限空间能塞入双倍请求 。
- 槽位扩容(Max Seqs): 拒绝默认的256 并发,暴力拉升至 1024,彻底消除软件调度瓶颈,喂饱 GPU 核心 。
- 视觉去气泡(MM Data Parallel): 视觉编码器开启数据并行模式,避免多图处理时的流水线阻塞。
配置完成后,同样在终端启动服务器,当日志出现"Application startup complete."说明部署完成。记得关闭之前的服务器。
直接在文档里面运行代码,这段代码的意思是:切到指定conda 环境,然后用 vLLM 自带的压测工具,对 GLM-4.6V-Flash(9B)做“随机数据模式”的高并发吞吐/延迟压测。
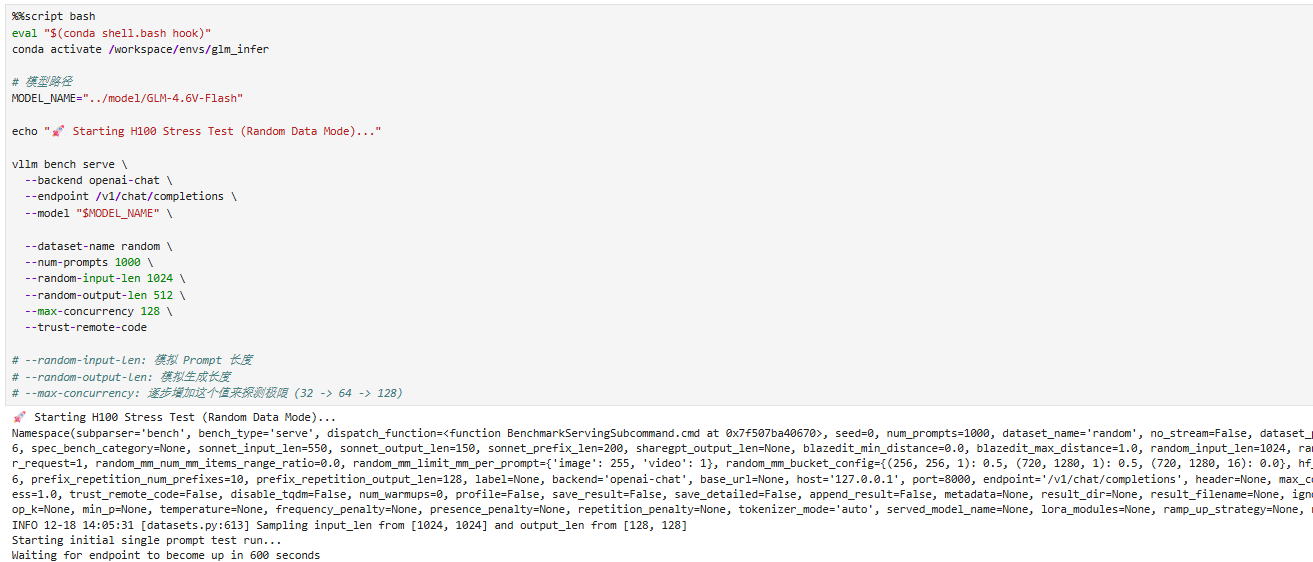
真实压测与性能分析:
为了排除网络下载数据集的不稳定性,我们使用vLLM 内置的 random 数据集进行纯算力压测,模拟高负载场景(输入 1024 tokens / 输出 512 tokens)。
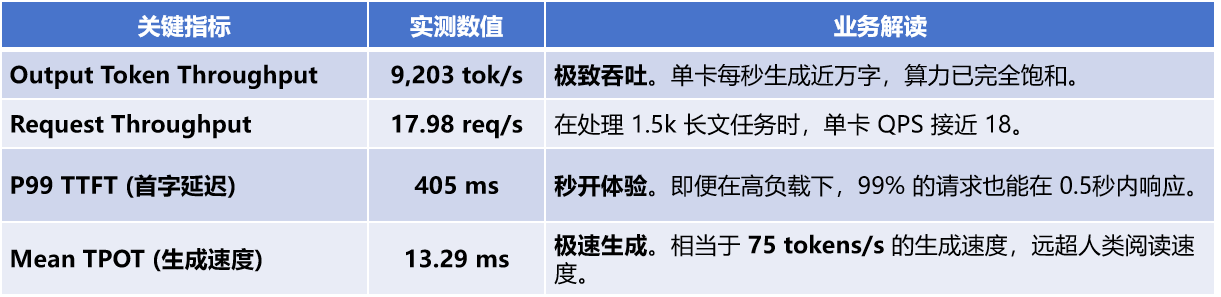
实战总结:并发数控制在128左右是最佳平衡点。
✅当并发低于64时,延迟极低,但 GPU 没吃饱,吞吐量浪费。
✅当并发大于256时,吞吐增幅开始变小,但排队效应爆炸,P99 会从400ms 拉到 7000ms+。
✅当并发等于128时,吞吐拉满同时延迟可控,9200 tok/s + 405ms 是一个非常适合上线的区间。
这里,我们给出一些生产建议:
✅网关层(Nginx / API Gateway)建议给单实例加“保险丝”:最大连接数/并发上限设到 ~150,过载时宁可限流,也不要让 P99 进入秒级排队区。
✅对GLM-4.6V-Flash,这套参数本身已经非常“接近单卡 H100 的上限区间”,一般不需要再大改;真正影响线上体验的,更多是输入输出长度分布和限流策略。|
04 总结
不止于“跑通”,更要“极致”.
大模型部署的核心,不是能跑就行,而是把硬件潜力发挥到极致。
这是一套可直接用于生产环境的部署方案:既能承载MoE 权重,也能稳住长文本场景,同时让 MoE 的推理性能真正跑出来。
这套方案不仅适用于GLM-4.6V,更可迁移到其他 VLM 模型,为高并发多模态服务提供了可直接落地的参考。如果你也在部署大模型时遇到算力浪费、显存不足等问题,不妨试试这套方案,让你的H100 真正“物超所值”!
关注“大模型实验室Lab4AI”,第一时间获取前沿AI技术解析!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号