Qwen-Video-8B与LLaMA-Factory联动实现垂类视频理解
Qwen-Video-8B与LLaMA-Factory联动实现垂类视频理解
多模态学习是一种 利用来自不同感官或交互模态的数据(如文本、图像、音频、视频等) 进行机器学习的方法。
它通过融合多种信息来源来训练模型,从而增强模型的感知与综合理解能力,实现跨模态的信息交互与深度融合。
常见的多模态任务包括视觉问答、视觉推理、文字检测与识别、音频事件分析以及全模态理解等。
视频理解,作为多模态学习的重要分支,旨在对视频中的视觉、语音、文本等信息进行整体解析。
而在这一领域中,“垂类视频理解”进一步聚焦于特定行业的专业场景,它不是简单地“泛泛看懂视频”,而是面向行业实际需求,将画面、声音、文字等内容进行深度融合,提炼出“有用、精准、专业”的结论。如同为视频配备一位“行业专属顾问”,帮助从业者快速获取关键信息,解决实际问题。
例如,在工业领域可用于设备故障判断,在教育场景中提炼知识点,在农业应用中总结技术要点,使用户无需逐帧观看即可高效获取所需内容。
尽管文本与图像的理解技术已相对成熟,AI 对视频内容,尤其是富含专业知识的垂类视频的深度理解,仍面临显著挑战。
现有通用视觉语言模型在处理此类视频时,常存在以下瓶颈:
- 领域知识匮乏:模型难以理解医疗、制造、农业等行业的专业术语、流程与上下文逻辑;
- 时序建模薄弱:对视频帧之间的动态关系捕捉不足,导致对动作、流程等时序内容的分析停留在表面;
- 多模态融合不足:语音、字幕、画面等元素之间缺乏深层协同推理,信息整合能力有限。
为应对上述问题,我们启动了 Qwen-Video-8B 项目。
该项目基于强大的 Qwen3-VL-8B-Instruct 模型结合LLaMA Factory大模型微调框架进行针对性微调,重点注入垂类领域知识,加强时序建模与多模态推理能力,带您了解Qwen-Video-8B在长视频理解领域的强大应用、训练流程和卓越效果,揭示其如何突破传统限制,开启视频智能分析的新篇章。
为什么是这两个组合?
Qwen3-VL的目标,是让模型不仅能“看到”图像或视频,更能真正看懂世界、理解事件、做出行动。
为此,Qwen团队在多个关键能力维度上做了系统性升级,力求让视觉大模型从“感知”走向“认知”,从“识别”迈向“推理与执行”。
LLaMA Factory是一个一站式的大模型微调框架。它整合了主流的高效训练技术,适配市场上数百个开源模型,让用户无需编写代码就能在网页端完成模型微调全流程。
无论是角色扮演、专业问答还是多模态应用,LLaMA Factory都能提供可视化、可控、轻量化的微调解决方案。
项目亮点
基于强大的Qwen3-VL-8B-Instruct通用模型,通过“垂类知识注入+时序能力强化+多模态融合优化”的专项特训,让模型精准适配特定领域需求。
这次项目中,团队选择了“城市风光”作为首个突破方向,整个优化过程简化为三个关键步骤:
- 1.精选专项数据集: 采用MiraData数据集,筛选出408个城市风光视频片段。这些视频不仅保留了完整的镜头切换和情节连贯性,为模型学习提供了优质“教材”;
- 2.针对性微调优化: 通过LoRA微调技术,将城市风光领域的知识注入模型,同时强化模型对视频时序关系的捕捉能力;
- 3.多轮效果验证: 分别用基础模型和微调后的模型对同一批城市风光视频进行解读,对比两者的解读效果,验证优化价值。
微调后结果一览
通过在Lab4AI平台上的一键体验,用户可以快速对比基线模型与微调后模型的效果。
在项目复现中的 “快速体验demo” 中进行快速体验,参考步骤进行操作,即可立即观察到基线模型和微调后模型的区别。
随机选取视频如下:
基线模型效果:

英文语料微调模型效果:

中文预料微调模型效果:

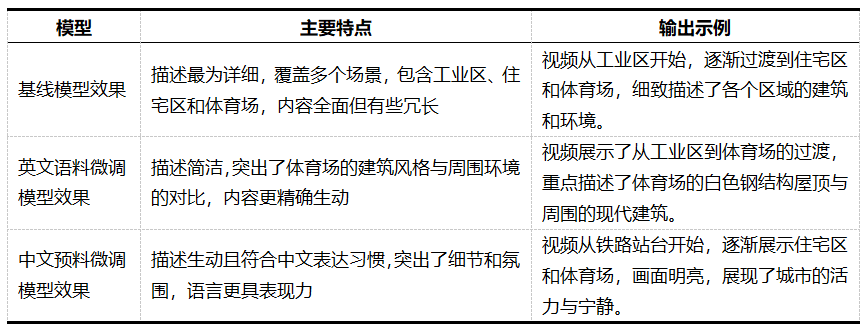
可以看出,基线模型提供了最为详细的场景描述,而英文微调模型则更加简洁且精准,中文微调模型则结合了中文表达习惯,提供了生动且富有氛围的描述。
详细实践步骤
Step 1 数据预准备
首先加载数据集,项目中共包含408个视频片段。
接着,将数据转换为LLaMA-Factory所要求的格式,确保每个视频包含对应的标签和相关信息。
然后,将数据集拆分为训练集、验证集和测试集,数据集已准备好并存放在指定文件夹中。
如果需要,也可以修改code/data目录下的dataset_info.json文件,添加自定义数据集的信息。
如果只是跟着本项目操作,可直接跳过。
Step2 基线模型测试
运行基线模型代码,随机选择一个视频进行测试。
确保数据和模型能够顺利加载并进行测试。
如果需要,您还可以根据具体需求调整模型或测试参数。
运行基线模型测试代码后,您将能够了解模型在未经过微调时的表现。
Step3 英文语料lora微调
使用预先配置的LoRA适配器加载英文语料数据。
我们提供了配置文件,您可以根据需要进行调整。
运行训练代码开始LoRA微调,训练过程将基于英文语料数据进行优化。
Step4 中文语料lora微调
同样的步骤,加载用于中文语料的LoRA适配器。
中文语料的处理类似英文语料,但要确保数据格式符合中文需求。
根据中文语料的特点,可以调整训练参数和学习率等超参数,确保模型能够充分适应中文文本。
使用微调脚本进行中文语料的训练,生成经过LoRA微调后的模型。
以上步骤介绍了从数据预处理到基线模型测试,再到英文和中文语料的LoRA微调过程。
在每个步骤中,您可以根据具体需求调整模型配置和训练参数,确保在不同语料和数据集上的优化效果。
Step5 效果查看

微调后的模型视频数据输出样本达到『场景正确 + 细节丰富 + 与真实标签语义一致』的可用标准,证明垂类微调已经成功把通用模型驯化成城市风光领域的专业描述员。
应用延伸
Qwen-Video-8B模型的成功微调,证明了通用大模型在垂直领域的巨大潜力。
未来,该技术不仅能应用于城市风光视频的理解,还可快速复制到更多专业领域:
- 旅游领域:自动生成景区宣传视频的解说文案,精准提炼景点特色;
- 安防领域:精准识别监控视频中的异常行为,适配不同场景(校园、商圈、工地)的监控需求;
- 在线教育:解读专业课程中的实验视频、操作流程视频,辅助提炼知识点;
- 工业质检:看懂生产线的操作视频,及时发现流程中的不规范环节。
通过进一步的领域微调,Qwen-Video-8B有望成为各行业视频理解领域的重要工具,推动更多应用场景的创新与突破。
该项目依托Lab4AI平台,充分发挥平台的强大算力和数据支持,为视频理解技术的快速发展提供了坚实的基础。

创作者招募中!Lab4AIxLLaMA-Factory邀你共创实战资源
想解锁大模型微调实战,却愁无算力、缺平台?现在机会来了!Lab4AI 联合 LLaMA-Factory 启动创作者招募,诚邀 AI 开发者、学生及技术爱好者提交微调实战案例,通过审核即享算力补贴与官方证书等,共创AI实践新生态。
大模型实验室Lab4AI实现算力与实践场景无缝衔接,具备充足的H卡算力,支持模型复现、训练、推理全流程使用,且具备灵活弹性、按需计费、低价高效的特点,解决用户缺高端算力、算力成本高的核心痛点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号