Qwen3-VL + LLaMA-Factory 怎么玩?手把手教你做一个会打分会挑错的作文批改助手
Qwen3-VL + LLaMA-Factory 怎么玩?手把手教你做一个会打分会挑错的作文批改助手
在K12 和高等教育阶段,作文批改一直是教学反馈中最费时、最主观、最难标准化的一环。
核心痛点集中在教师批改压力巨大、评分主观性强难以统一以及反馈滞后难以形成写作闭环。

随着大语言模型的发展,我们终于迎来了一个新选项:让大模型真正学会“像语文老师一样”看作文、打分数、写评语。
今天,我们就通过一个在Lab4AI 上可一键复现的完整项目,拆解这条路径:如何利用LLaMA-Factory + Qwen3-VL-30B-Instruct, 在仅有300 篇高中作文 的小样本条件下,完成一个 “能打分 + 会写评语” 的中文作文智能批改助手,非常适合老师、教研员和教育 AI 开发者快速验证效果。
选用AES-Dataset高中作文数据集
要让模型学会“像老师一样评分”,离不开一个真实、垂直的训练数据集。本项目选用了面向中国高中阶段的中文作文数据集:AES-Dataset。
这个数据集小而精,聚焦高中场景
- 学生群体: 全部来自中国高中生,话题接近高考/模拟考作文;
- 文体类型: 以议论文、记叙文为主,需要一定逻辑推理与表达能力;
- 数据规模: 共300 篇作文,编号从 A-0001 至 A-0300。
虽然数量不大,却非常适合做:小样本微调(Few-shot Fine-tuning)、LoRA / QLoRA 轻量化实验、验证“教育垂直领域精调”的效果上限。
数据结构标准化设计,方便工程接入。AES-Dataset 主要由两部分组成:
- 元数据文件scores.txt: 记录作文ID、标题、人工评分;相当于模型要拟合的“老师打分参考答案”。
- 作文文本/essays 文件夹: 每篇作文一个txt;首行为标题,后续为正文段落,天然保留文章结构信息;个别文件末行有空行,需在预处理阶段清洗。
这套结构非常适合作为LLaMA-Factory 的上游数据源,方便自动对齐为:Instruction(指令)- Input(作文内容)- Output(分数+评语)
模型批改作文验证效果
Lab4AI.cn提供实验平台,提供一站式科研工具链!
👉一键直达
你可以在Lab4AI 项目页中,通过 project_reproduce.ipynb 的「快速体验 demo」章节,直接对比:基线模型(未微调的 Qwen3-VL-30B-Instruct)VS微调后作文批改模型,即可立刻看到两者的差异。
在这个项目中,我们对同一篇《拒绝平庸之思》,两者都能读懂文章、给出评价,但风格和“老师味儿”差异非常明显:
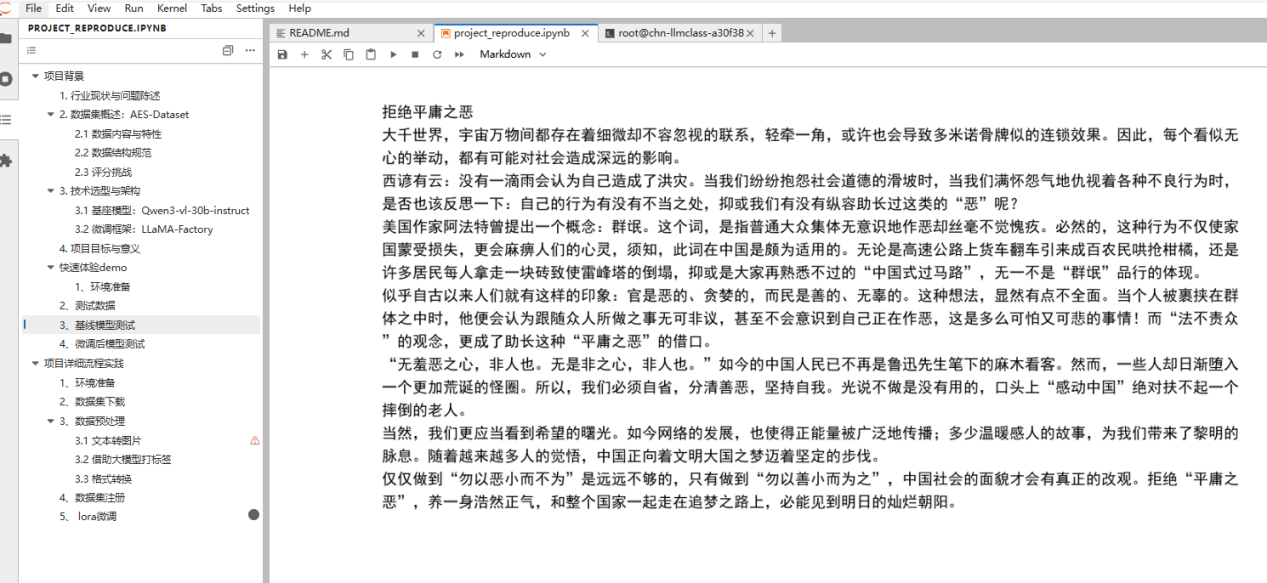
基线模型更像一位学术型评论家:讲得多、很细致,会从哲学概念、论证逻辑、语言修辞等多个角度做深度解析;
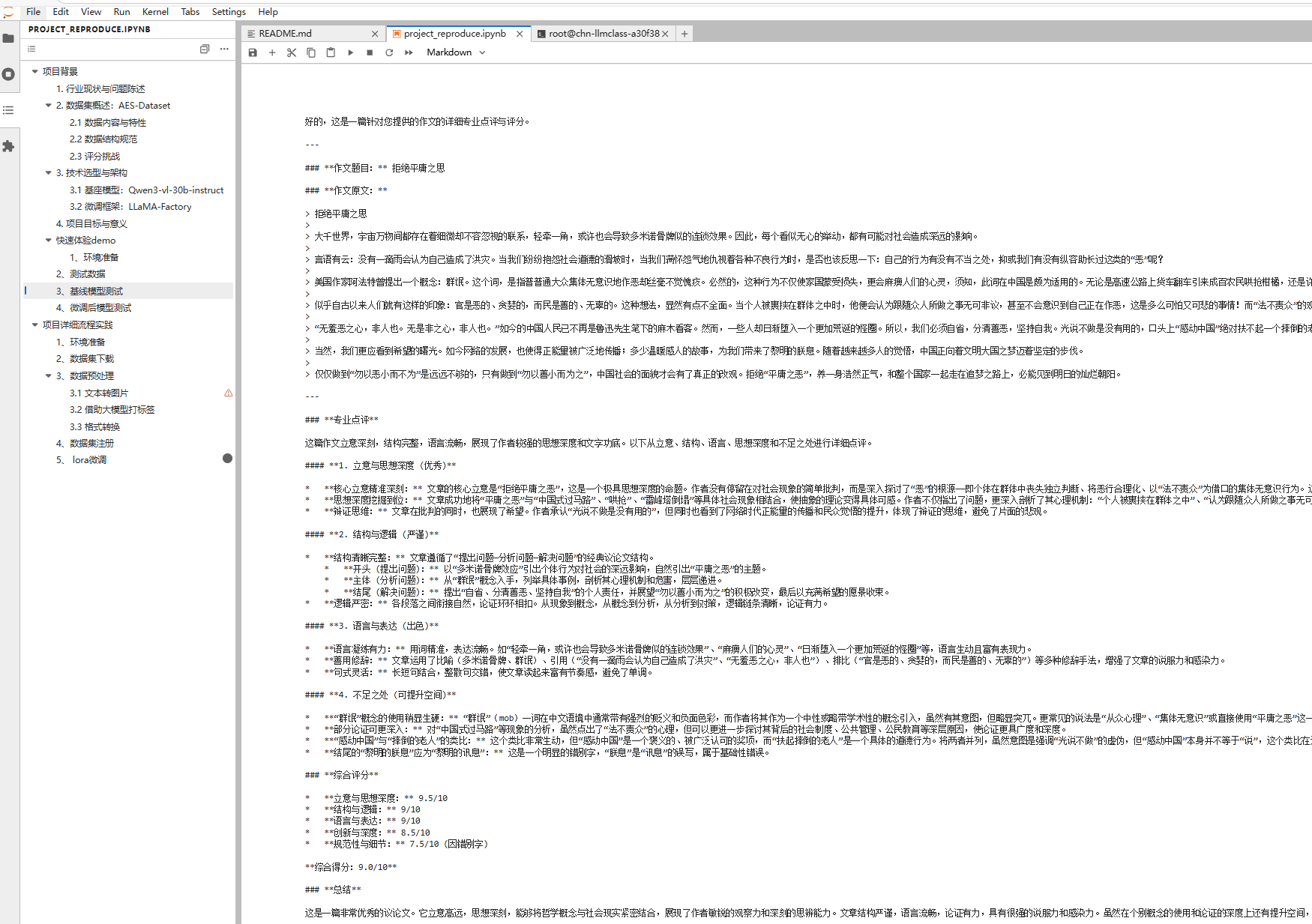
微调后模型更接近一位真实语文老师:用的是百分制评分,结构是“总体评价 + 优点 + 改进建议”,语言自然、建议具体,学生一看就知道该怎么改。
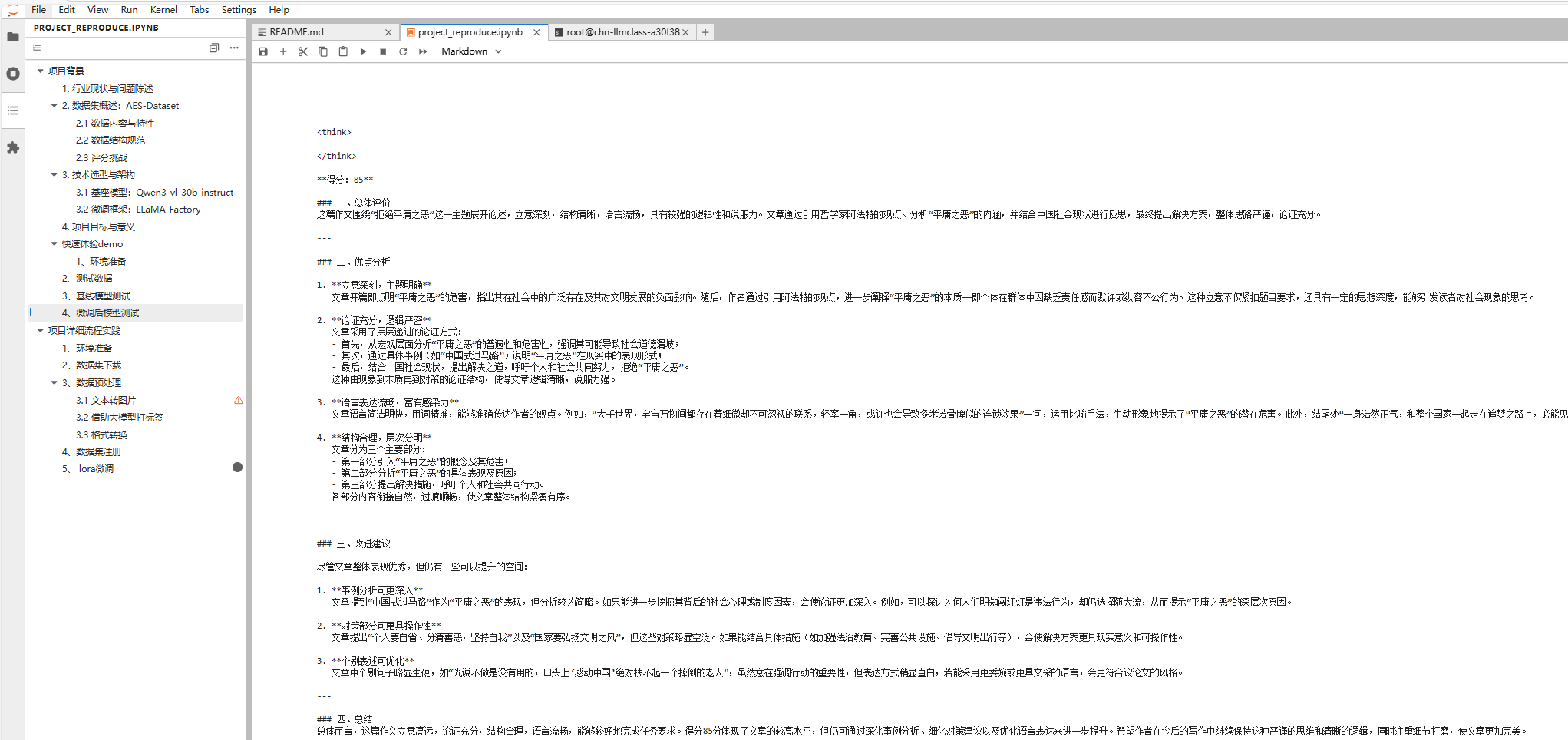
下面这张表就是两者在关键维度上的对比,可以非常直观地看到差别:
| 对比维度 | 基线模型效果 | 微调后模型效果 |
|---|---|---|
| 评分形式 | 10 分制,多维度打分后给出综合分(9.0/10) | 百分制,直接给出总分(85分),贴近考试习惯 |
| 评语结构 | 专业点评 + 多维拆解 + 不足 + 总结,偏学术评论 | 总体评价 + 优点分析 + 改进建议 + 总结,像语文老师批改 |
| 语言风格 | 用词严谨、偏“专家评审”,理论感强 | 语言自然朴实,更像给学生看的作文本评语 |
| 关注重点 | 概念严谨性、逻辑细节、用词甚至错别字都细致指出 | 强调优点与问题方向,突出如何改进写作表现 |
| 学生阅读门槛 | 信息密集,理解成本略高 | 结构清晰,一眼能看出亮点和需要改的地方 |
| 教学场景适配度 | 适合教研、范文深度解析 | 适合作为日常“智能批改反馈”,可直接用于教学与训练 |
依托LLaMA-Factory的LoRA微调流程
本项目依托LLaMA-Factory,在Lab4AI上完成了从数据到模型的完整闭环:
数据清洗 → 指令格式构造 → LoRA 微调 → 评分与评语验证。
如果你也想亲手体验一次 “大模型 × 作文批改” 实战,可以在 project_reproduce.ipynb 中的「项目详细流程实践」模块按以下步骤来。
Step 1 数据集准备
本项目选用AES-Dataset 作为核心训练数据。这是一个专注于中国高中阶段的中文作文数据集,具有鲜明的教育领域特征。该数据集包含包含编号从A-0001 至 A-0300 共300篇精选作文样本,已保存在../dataset/AES-Dataset下。
Step 2 数据预处理
把AES-Dataset 转成 LLaMA-Factory 支持的 ShareGPT格式:首先将文本转为图片,再借助大模型打标签,将base_url和api_key替换成可用的大模型API,最后进行格式转换。
可以修改code/data目录下的dataset_info.json文件,增加自定义数据集。
Step 3 lora微调
在LLaMA-Factory 中,我们采用 LoRA/QLoRA 对 Qwen3-VL-30B-Instruct 进行指令微调:固定大部分原始参数,只对少量低秩矩阵进行更新;显著降低显存占用和训练成本,非常适合在 Lab4AI 环境下复现。
你可以在Notebook 中:指定 LoRA 权重保存路径;通过配置文件调整;学习率 / batch size / epoch 数;LoRA rank / target modules 等超参数;观察 Loss 曲线变化,防止在 300 篇小数据上过拟合。
经过微调后,你可以重新加载模型,对同一作文进行对比测试,直观感受评分与评语的变化。
结论
本项目在Lab4AI 平台上,完成了基于LLaMA-Factory + Qwen3-VL-30B-Instruct的指令微调实践,并在AES-Dataset高中作文数据上验证了以下结论:
小样本 + LoRA,足以显著提升领域适配度,仅用 300 篇作文,就能让模型的打分更接近真实语文老师;
评语从“泛泛式鼓励”进化为“有维度、有细节、有建议”的教学反馈;
作文批改可以真正走向“标准化 + 规模化”,老师可以把重复性的批改工作交给模型,专注于教学设计与重点辅导;
学生可以获得更频繁、更即时的写作反馈,形成写作-反馈-改进的闭环。
多模态Qwen3-VL 为未来手写作文批改预留空间:
- 数据规模扩充: 引入更多年级、更多题型、更多地区的真实作文,进一步提升模型在不同学段与地区标准下的鲁棒性。
- 多维评分维度: 从单一综合分数,扩展到“立意分、结构分、语言分、创新分”等子维度评分,增强教学参考价值。
- 任务扩展: 将该模型接入到完整的教学系统中,用于日常随堂作文即时反馈、写作训练营/刷题任务自动打分、学生写作能力成长曲线分析等。
通过持续扩展数据与任务,本项目有潜力演进为:一套真正融入日常教学流程的“智能作文教学辅助系统”。
创作者招募中!Lab4AI x LLaMA-Factory 邀你共创实战资源
想解锁大模型微调实战,却愁无算力、缺平台?现在机会来了!
Lab4AI 联合 LLaMA-Factory 启动创作者招募,诚邀 AI 开发者、学生及技术爱好者提交微调实战案例,通过审核即享算力补贴与官方证书等,共创AI实践新生态。
大模型实验室Lab4AI实现算力与实践场景无缝衔接,具备充足的H卡算力,支持模型复现、训练、推理全流程使用,且具备灵活弹性、按需计费、低价高效的特点,解决用户缺高端算力、算力成本高的核心痛点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号