
复杂部署退退退!DeepSeek-OCR 轻量化文档理解,3分钟私有部署搞定
3分钟,让AI真正“读懂”文档。
我们日常接触的PDF、扫描件里,不只有单纯的文字,还有多栏排版、复杂表格、科研公式、数据图表等多模态内容。但传统OCR的能力仅限于“看清文字”,却无法理解文档的层次与语义。而且,传统OCR处理一张图需要上千个视觉token,这会让模型计算卡顿、内容占用飙升、计算成本增加。
而DeepSeek-OCR解决传统OCR的低效问题:它不再执着于“把窗口做大”(扩展注意力窗口),而是选择“把内容变小”。它以更轻、更快、更懂的姿态登场——仅用3B参数,即可实现对文字、表格、图表等多模态内容的深度解析。
在Lab4AI平台,你只需3分钟即可私有部署,让系统从识字工具跃升为“文档理解专家”。
论文名称:DeepSeek-OCR: Contexts Optical Compression
DeepSeek-OCR技术突破
DeepSeek-OCR的颠覆之处,在于提出了一个全新思路:不逐字识别,而是先“压缩” 再“解压”。它把整张文档图像看作是“文本的光学压缩包”,先通过智能压缩提炼核心信息,再精准还原成结构化内容。
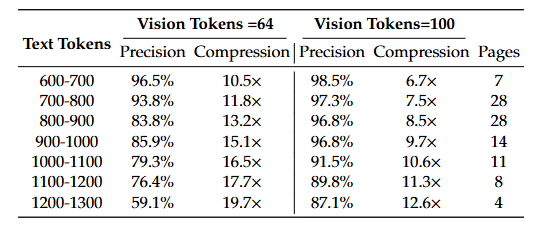
相比于传统OCR处理一张图需上千个视觉token,DeepSeek-OCR只需几十个,压缩比高达10-20倍。它能够在10 倍压缩时仍保持 96% 识别精度,几乎不损失信息。即使是在20 倍压缩的情况下,仍能够保持 60% 精度,并且显存占用大降低,推理速度翻倍。
DeepSeek-OCR架构拆解
DeepSeek-OCR 的强大性能源于“压缩 + 解码”的精妙架构设计,两大核心模块各司其职、高效配合:
1. DeepEncoder:双阶段视觉压缩引擎(AI光学压缩器)
它负责把复杂文档图像“压”成少量高价值视觉 token,兼顾细节与全局:
- 局部阶段(SAM-base):精准捕捉字符、线条等细节特征,不遗漏关键信息;
- 压缩阶段(16× 卷积):在双组件之间,通过2层卷积模块对视觉token进行16倍下采样;
- 全局阶段(CLIP-large):理解文档整体布局、语义关联,比如区分标题、正文、表格区域;
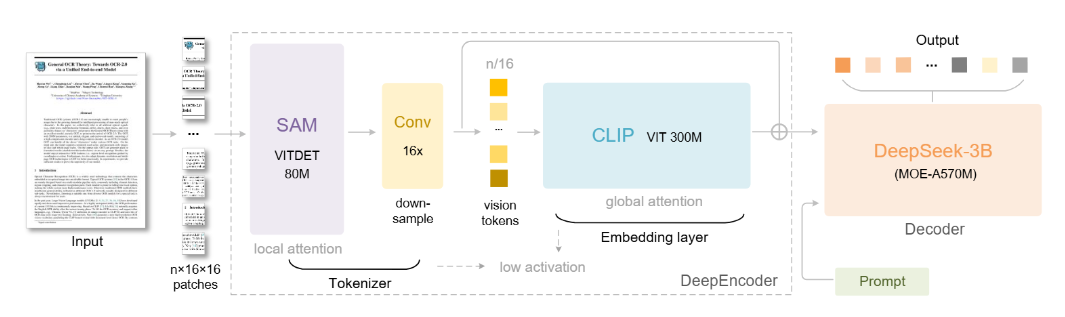
2.MoE 解码器:灵活应变的 “专家混合系统”
解码器用则于根据图像标记和提示生成所需结果,它采用DeepSeek 自研的 MoE(专家混合)结构,推理时仅激活 5 亿左右参数。
3分钟极速部署体验
Lab4AI.cn上已上架了此篇论文的部署,【登录平台】即可体验。
👉Lab4AI项目指路
Step1 启动项目
登录Lab4AI 平台,在“项目复现”中找到 DeepSeek-OCR轻量化复现方案,选择GPU资源进行项目复现,平台将自动创建运行环境,无需手动安装依赖。
Step2 模型部署
参考官方文档完成模型部署,系统完成推理服务上线,跳转链接即可体验。
Step3 应用体验
您可以可上传文档进行测试。本次实践支持从文字提取到表格解析再到图表与语义定位的全流程交互。同时支持生成Markdown、结构化表格、带坐标的检测框等结果,方便直接对接知识库或自动化处理系统。
下图中展示的是上传文件:

下图中展示的是生成过程。
下图中展示的是结果输出。

从复现到落地的全流程支撑
本方案验证了DeepSeek-OCR轻量化部署在企业与科研环境中的可行性。通借助DeepSeek-OCR的轻量化架构与高效推理能力,即便在单卡GPU环境下,也能支持大规模文档的批量处理与结构化解析,显著提升效率并降低部署门槛。
作为Lab4AI的复现项目,DeepSeek-OCR不仅提供完整的模型与工具链,还预装了适配环境,让用户轻松激活并直接部署,无需复杂配置与调试。Lab4AI通过“算力+实验平台+社区”的全链条支撑模式,为开发者和企业提供低门槛、高效率的实践体验,让文档智能化从实验走向落地。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号