【第2次会议记录_2018.5.27】—— [ 算法原理 ]:手工特征提取的概念问题。(by_wanghao)
1、提取 特征点 、特征描述子 与 提取特征向量 之间的区别:
(1)、特征点:指的是一张图片上比较有代表性的‘位置’,提取特征点就是把图片中这些有代表性的位置给标出来。

(2)、特征描述子:当提取出特征点之后,由于特征点是图片的某个位置,为了能够进行数学计算,我们需要给这些“位置”用一个数学方法来描述,于是可以用一个向量v来表示每一个位置。而这个向量就叫做 特征描述子。
(3)、特征向量:指的是通过对图片在像素层面上做一些变换(LBP、颜色特征、Sift、surf)之后,生成一个向量V,用这个向量就可以表示整张图片,这个向量就称为特征向量。
2、理解SIFT图像检索与聚类算法的关系。
(1)SIFT特征提取的流程:
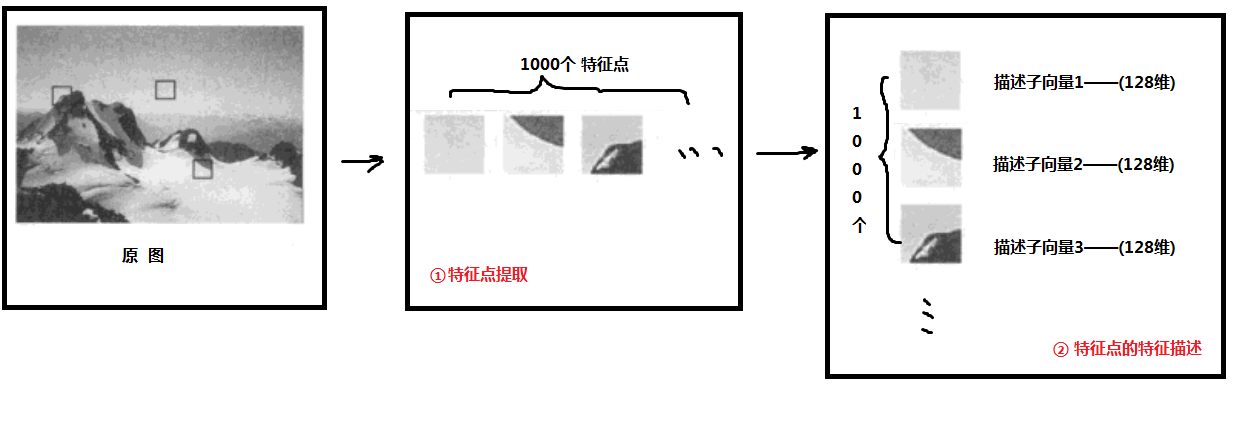
①图片描述子建立:对一张图片进行特征点的提取(找到图片中有代表性的位置),并分别对这张图片中的每个特征点用特征描述子描述来描述(设这张图片有1000个特征点,每个描述子是128维向量)。
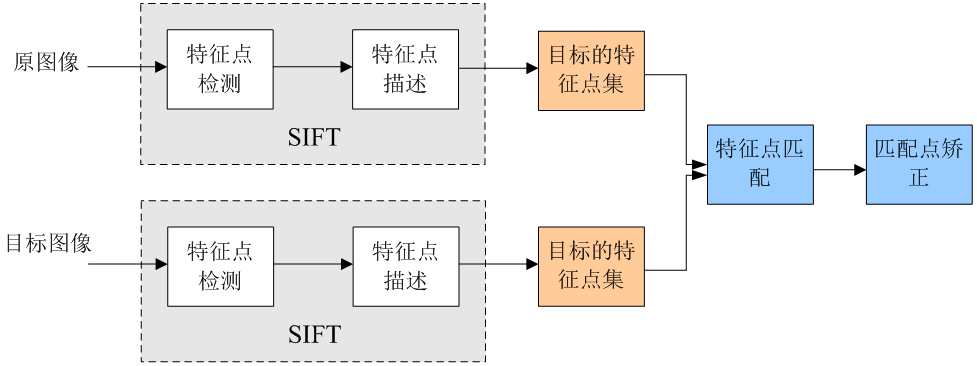
算法核心思想:https://blog.csdn.net/weixin_38404120/article/details/73740612
https://blog.csdn.net/dcrmg/article/details/52577555
②引入词袋模型:https://blog.csdn.net/garfielder007/article/details/51475550
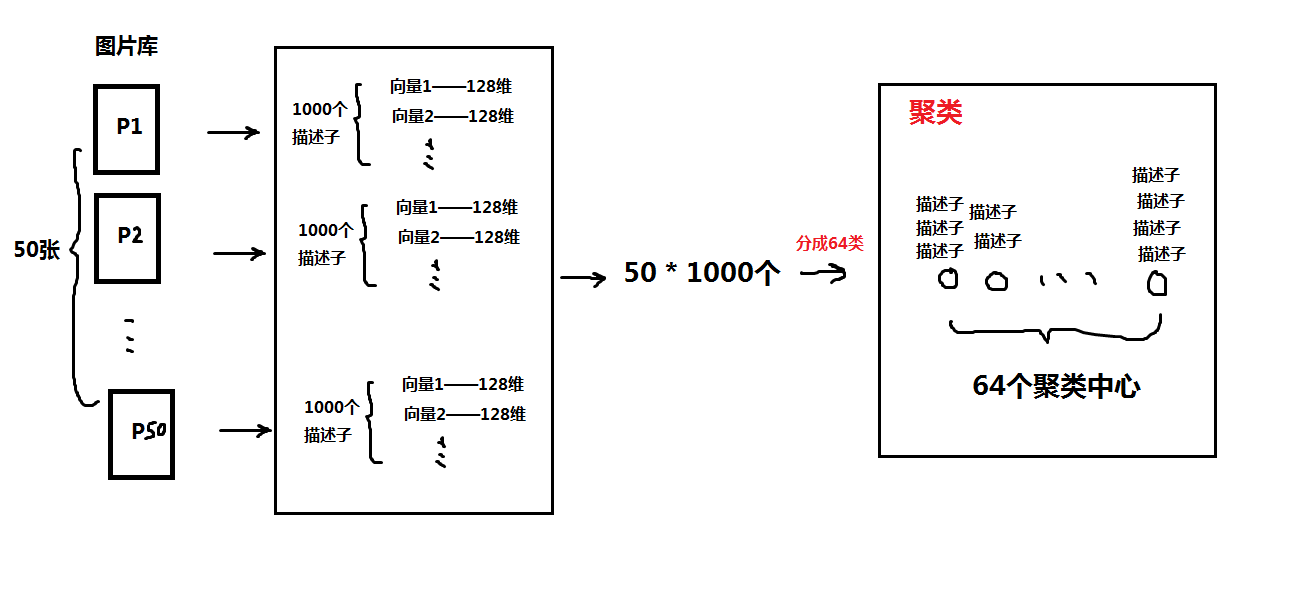
- 现在对图像库中所有图片(设有50张图片)的所有特征点(设每张图片特征点个数都为1000)进行提取并且建立描述子(这样总共有50 x 1000个描述子,且每个描述子维度为128)。而这50 x 1000 个描述子可以称为“词”
- 现在引入 K-means 聚类算法,给这50 x 1000个描述子分成64类,即设定聚类中心为64,然后通过学习得到这50 x 1000个描述子应该各自在哪一类下。
- 这样这64个类的每一类中都有 >不同个数;> 来自不同图片的描述子。
- 当完成聚类后,这样64维的每一维度就相当于一个描述子集合,把每一个维度的这样的描述子集合称为“词袋”
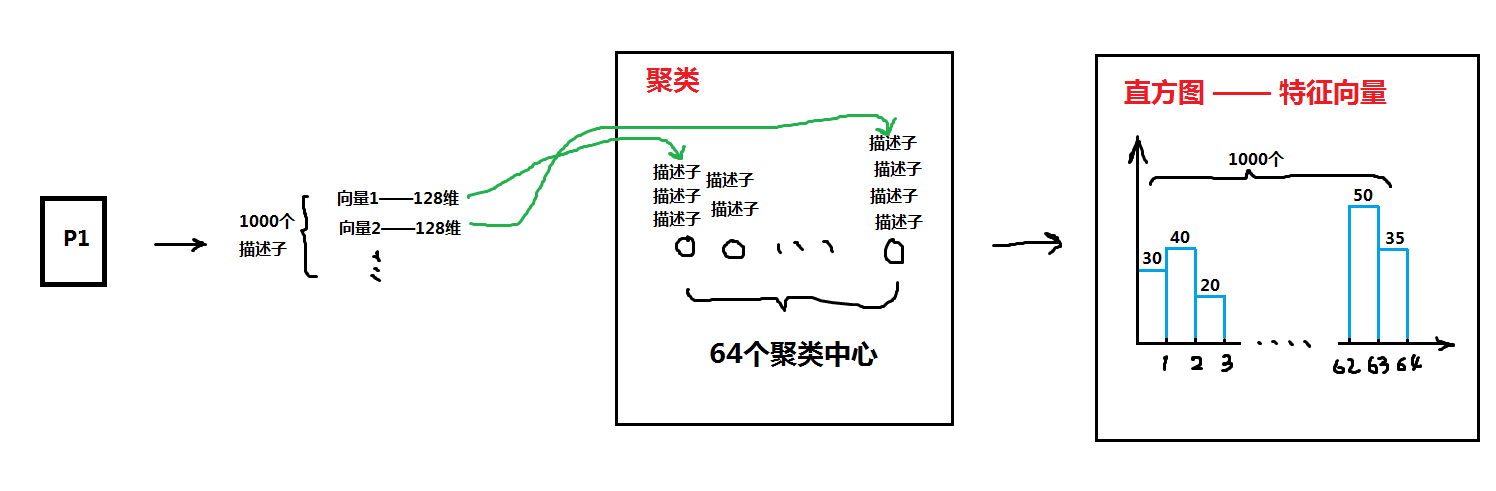
③特征向量的形成:
- 给这64为词袋建立一个对应的64维直方图。
- 再看看一张图片中的所有特征描述子都对应在64维词袋哪些词袋中,只要某一个维度的词袋包含图片的一个特征描述子,那么在直方图上的对应维度就加一,知道这一张图片中的所有特征点描述子都遍历完全。这样最终的64维直方图就是这张图片的特征向量。
(2)、图像检索:即比较 待检索 与 图片库中每张图片间 的特征向量距离,设定一个阈值,小于这个阈值的图片就检索出来。
by 小恶魔
———————————————————————————————————————————————————————————————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号