

Numpy

Numpy(Numerical Python)是一个开源的Python科学计算库。
在使用之前我们需要引入库。
import numpy
这个库的功能通过它的图标我们就可以看出一二来,就是用来进行矩阵运算的。矩阵我们常见的形式是一维数组(比如:[1, 2, 3])和二维数组(比如:[[1, 2, 3], [4, 5, 6], [7, 8, 9]])。我们可以通过Numpy中的array函数来将列表转换为Numpy中使用的矩阵,比如:
import numpy as np
num = [[1, 2, 3],
[4, 5, 6]]
print(num)
print(type(num))
arr_num = np.array(num)
print(arr_num)
print(type(arr_num))
"""
运行结果:
[[1, 2, 3], [4, 5, 6]]
<class 'list'>
[[1 2 3]
[4 5 6]]
<class 'numpy.ndarray'>
"""
让我们从上面的运行结果来分析一下:
- 列表中元素显示分隔符有逗号,转换之后就是空格了。
- 转换之前数据类型是list,转换之后就变成了ndarray。
那么分析的结果呢,就是转换之后数据确实发生了改变,具体发生了什么改变,后面会进行介绍。
这里我们要认识到numpy的两个特点:
- 使用Numpy对同样的数值进行计算,Numpy比直接使用Python要简洁和快速。
- Numpy的核心是ndarray对象,它是一个快速而灵活的大数据容器。
ndarray
ndarray介绍
我们说过ndarray对象是Numpy的核心。那么它的好处有哪些呢?
(1)底层处理
首先,它最大的特点就是与Python底层处理方式的区别。在数据存储中,有两种为人熟知的存储结构,一个是数组,一个是链式。它们两者都有各自的好处,因为数组是连续空间所以在数据读写上很快,而在插入和删除时就很慢了;链式因为指针的原因可以很方便的找到上下关系,这让插入和删除变得简单很多。ndarray和Python的底层就很像这种关系。
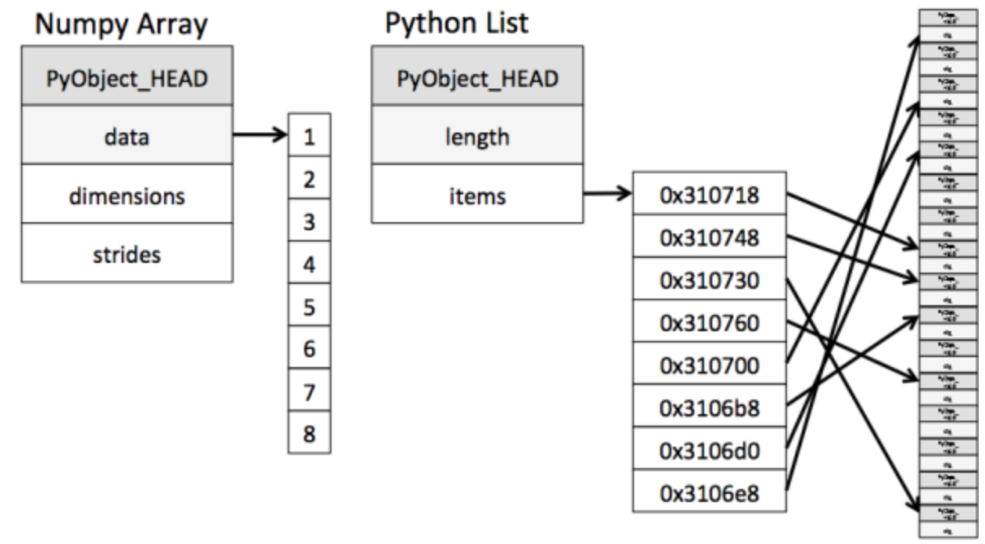
当我们用ndarray存储数据的时候,所有的元素都是相同数据类型,地址也是连续的。
在Python中,是通过寻址找到下一个元素的位置的。
在编程领域中,简单的代价就是效率的提高。ndarray虽然在通用性上比Python差,但是随之带来的是性能的提升。Numpy是用于科学计算的库,所以它会面临大量的数值计算,这样的设计可以让我们用更短的时间计算出我们需要的结果。
下面是一个例子,分别用Python和Numpy计算一段数据的和。

从上面两个数据我们就可以看出两者的计算速度对比了,如果数据量再提升,我们就更能够看到两者的速度差异了,这里就不再做实验。
(2)ndarray支持并行化运行
学习Python的人应该知道,在Python中有GIL锁这个东西,它让我们在一个进程中无论开多少个线程在当前时刻都只能有一个线程访问CPU。Numpy底层使用C语言编写,内部解除了这个限制,让它的效率远高于纯Python代码。
ndarray的类型
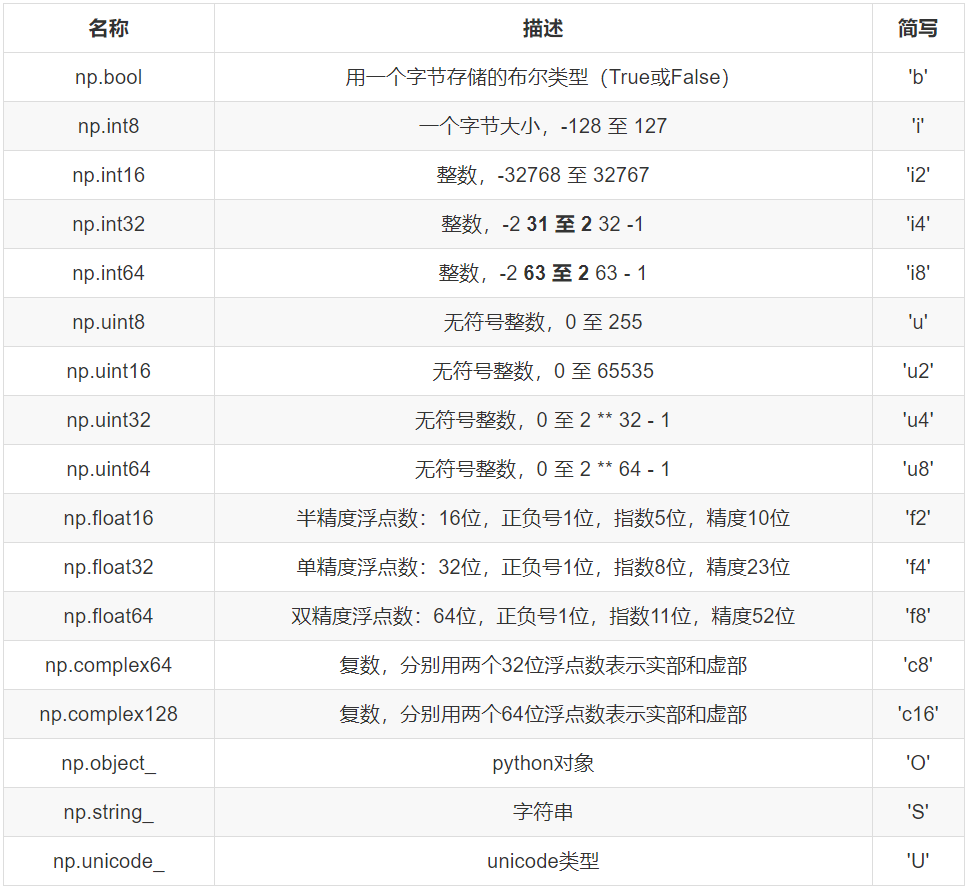
我们在创建矩阵的时候,可以指定数据的类型。比如:

如果我们没有指定数据类型,整数默认int64,小数默认float64。
ndarray的常用属性
ndarray.shape # 数组维度的元组
ndarray.ndim # 数组维数
ndarray.size # 数组中的元素数量
ndarray.itemsize # 一个数组元素的长度(字节)
ndarray.dtype # 数组元素的类型
示例:

Numpy常见的使用方式
(1)创建矩阵
numpy.linspace() # 在一个范围取平均分布的值,比如:numpy.linspace(2, 50, 100),在范围为2到50的闭区间中生成100个平均分布的值。
import numpy as np
# 方式1:使用genfromtxt函数读取文件
f = np.genfromtxt("file.csv", delimiter="数据的分隔符", dtype=str) # 第一个参数是读取的文件名,第二个参数是读取文件中数据分隔符,第三个参数表示以什么类型读入数据。
# 方式2:使用array函数将列表转换为矩阵
arr_num1 = np.array([[1, 2, 3], [4, 5, 6]])
# 方式3:使用zeros函数创建一个初始化矩阵
arr_num2 = np.zeros((3, 4)) # 生成一个三行四列的矩阵,初始值为0
# 方式4:使用ones函数创建一个初始化矩阵
arr_num3 = np.ones((3, 4)) # 生成一个三行四列的矩阵,初始值为1
# 方式5:使用empty函数创建一个初始化矩阵
arr_num4 = np.empty((3, 4), dtype=np.float16) # 生成一个三行四列的矩阵,初始值为为一些接近于0的数字。
# 方式6:使用arange函数创建参数范围内的矩阵。
arr_num5 = np.arange(10, 20, 2) # 生成区间为[10, 20),步长为2的列表:[10 12 14 16 18]
arr_num6 = np.arange(10) # 生成:[0 1 2 3 4 5 6 7 8 9]
# 方式7:将给定范围分成多少段,然后生成矩阵。
arr_num7 = np.linspace(1, 10, 20) # 将范围为[1, 10]的数字分为20段。
# 方式8:使用random.random函数生成一个矩阵,值的范围为0到1之间的数字。
arr_num8 = np.random.random((100, 200))
当我们使用numpy.array()创建的时候,里面数据格式必须是一致的。如果数组中有整数和浮点数的话,为了满足浮点数的存储要求,所有的整数也都会转成浮点数来进行存储。
(2)矩阵间的运算
算数运算
import numpy as np
num1 = np.array([10, 20, 30, 40])
num2 = np.arange(4)
print(num1, num2)
num3 = num1 - num2
print("运行结果为:", num3)
"""
运行结果
[10 20 30 40] [0 1 2 3]
运行结果为: [10 19 28 37]
"""
如上面例子中所示,
当我们对矩阵进行算数运算的时候,都是对整个矩阵中的元素逐个计算;多个矩阵运算时,对应矩阵元素进行计算。
这里还需要知道,如果不是一维矩阵的计算,而是二维的计算,是什么情况?
比如:
import numpy as np
num = np.arange(4).reshape(2, 2)
print("-------num-------")
print(num)
print("-------num*2-----")
print(2*num)
print("-------矩阵*矩阵------")
print("num1:")
num1 = np.arange(5, 9).reshape(2, 2)
print(num1)
print("-----")
print(num*num1)
print("-----使用dot函数-------")
print(np.dot(num, num1))
"""
运行结果为:
-------num-------
[[0 1]
[2 3]]
-------num*2-----
[[0 2]
[4 6]]
-------矩阵*矩阵------
num1:
[[5 6]
[7 8]]
-----
[[ 0 6]
[14 24]]
-----使用dot函数-------
[[ 7 8]
[31 36]]
"""
在上面例子中,矩阵*矩阵很容易看出来,就是两个矩阵对应位置数据进行乘法然后放到对应的位置。当我们使用dot函数的时候,最简单理解就是:矩阵中,该数据所在行的数据和该数据所在列的数据对应位置相乘结果再把结果相加,最后放到这个数据的位置就可以了,比如上面例子中:0*5+1*7=7;0*6+1*8=8;2*5+3*7=31;2*6+3*8=36。
上面np.dot(a, b)还可以写成a.dot(b)这样的形式。
科学计算
import numpy as np
num = np.arange(4)
print(np.sin(num))
print(np.cos(num))
print(np.tan(num))
print(np.exp(num)) # 表示e的多少次幂
print(np.sqrt(num)) # 表示参数的平方根得数
print(np.floor(num)) # 元素向下取整
比较运算
import numpy as np
num = np.arange(4)
print(num) # [0 1 2 3]
print(num > 2) # [False False False True]
print(num == 3) # [False False False True]
(3)其他
- 强转数据类型
- ndarray.astype(要强转类型)
- 判断两个变量指向的是同一个空间
- is,比如:b is a
- 查看矩阵的数据类型
- type(矩阵)
- 查看帮助文档
- help(函数)
常见的统计函数
- np.sum() # 求和
- np.min() # 求最小值
- np.max() # 求最大值
- np.argmin() # 求最小值的索引位置
- np.argmax() # 求最大值的索引位置
- np.mean() 或者 np.average() # 求矩阵的平均值
- np.median() # 求中位数
- np.cumsum() # 将矩阵参数顺序以斐波那契形式相加。
- np.diff() # 当前参数减去下一个参数的差,这里注意比如一行有n个数据,这样运行完,返回列表中只有n-1个数据。
- np.nonzero() # 返回两个array,一个顺序存放行坐标,一个顺序存放列坐标。 np.sort() # 矩阵中,逐行排序,默认升序。
- axis=0axis=0,按行排列;axis=1axis=1,按列排列
-
数组排序时使用的方法,其中: kind=′quicksort′kind=′quicksort′为快排;kind=′mergesort′kind=′mergesort′为混排;kind=′heapsort′kind=′heapsort′为堆排;
- 一个字符串或列表,可以设置按照某个属性进行排序,比如:np.sort(a, order=['Age', 'Height']),先按照属性Age排序,如果Age相等,再按照Height排序,此时参数为列表。
- A.T # 反向,行变列。列变行
- np.clip() # 它有三个参数,第一个参数为矩阵,第二个和第三个参数都是为一个值,当矩阵中的元素小于第二个参数,用第二个参数替换它;当矩阵中的元素大于第三个元素,就用第三个参数替换它。
- np.ravel() # 将多维矩阵变成一维矩阵
在使用的时候,我们还可以进行不同维度的求和。设置的方法是使用参数axis,当它的值为0的时候,对每一行的数字进行统计,当它的值为1的时候,对每一列的数据进行统计,比如:
import numpy as np
num = np.arange(12).reshape(3, 4)
print(num)
print("--------")
print("矩阵中最小值:", np.min(num))
print("矩阵中每列最大值:", np.max(num, axis=0))
print("矩阵中每行最小值", np.min(num, axis=1))
print("矩阵参数的平均值(方式1)", np.mean(num))
print("矩阵参数的平均值(方式2)", np.average(num, axis=0))
print("矩阵中最大值索引位置:", np.argmax(num))
print("矩阵中每列最大值索引位置:", np.argmax(num, axis=1))
print("矩阵中中间数据是多少:", np.median(num, axis=1)) # 同上,如果忽略axis参数,则为整个矩阵的中间数字。
print("矩阵数据斐波那契数列方式相加:", np.cumsum(num))
print("返回两个array,一个存放行坐标,一个存放列坐标:", np.nonzero(num)) # 可以用切片分别取出array。
print("矩阵中,逐行降序排列:")
print(-1*np.sort(-num)) # 默认升序排列,也可以用这种方式变成降序排列。
print("矩阵反向")
print(num.T)
print("指定参数的替换:")
print(np.clip(num, 3, 6.5))
print("将多维矩阵变成一维矩阵:", np.ravel(num))
"""
运行结果:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
--------
矩阵中最小值: 0
矩阵中每列最大值: [ 8 9 10 11]
矩阵中每行最小值 [0 4 8]
矩阵参数的平均值(方式1) 5.5
矩阵参数的平均值(方式2) [4. 5. 6. 7.]
矩阵中最大值索引位置: 11
矩阵中每列最大值索引位置: [3 3 3]
矩阵中中间数据是多少: [1.5 5.5 9.5]
矩阵数据斐波那契数列方式相加: [ 0 1 3 6 10 15 21 28 36 45 55 66]
返回两个array,一个存放行坐标,一个存放列坐标: (array([0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2], dtype=int64), array([1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3], dtype=int64))
矩阵中,逐行降序排列:
[[ 3 2 1 0]
[ 7 6 5 4]
[11 10 9 8]]
矩阵反向
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
指定参数的替换:
[[3. 3. 3. 3. ]
[4. 5. 6. 6.5]
[6.5 6.5 6.5 6.5]]
将多维矩阵变成一维矩阵: [ 0 1 2 3 4 5 6 7 8 9 10 11]
"""
numpy中的索引
在python的中,我们可以通过索引来读取列表中的数据。在ndarray中,我们也可以用索引来进行矩阵中数据的读取。
当我们使用索引取值的时候,也可以用切片的语法,numpy中的切片也和python一样,切片取值是左闭右开区间。比如:1:3取到的数据为[1, 3)区间。
import numpy as np
arr1 = np.arange(10)
print(arr1)
print("索引取一维数组中的数:")
print(arr1[3])
print("---------------")
arr2 = np.arange(12).reshape(3, 4)
print(arr2)
print("索引取二维数组中的数:")
print(arr2[1][2])
print(arr2[1, 2])
print(arr2[2, :]) # 打印第三行的所有数
print(arr2[:, 2]) # 打印第三列的所有数
print(arr2[1, 1:2]) # 打印第二行的第二个数
print("---------------")
print("迭代读取每一行:")
for row in arr2:
print(row)
print("---------------")
print("迭代读取每一列:")
for col in arr2.T:
print(col)
print("---------------")
print("迭代方式读取每一个元素:")
print(arr.flatten()) # flat返回的是一个迭代器,它的内容为我们可以用这个flatten函数来看。
for item in arr.flat:
print(item)
"""
运行结果为:
[0 1 2 3 4 5 6 7 8 9]
索引取一维数组中的数:
3
---------------
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
索引取二维数组中的数:
6
6
[ 8 9 10 11]
[ 2 6 10]
[5]
---------------
迭代读取每一行:
[0 1 2 3]
[4 5 6 7]
[ 8 9 10 11]
---------------
迭代读取每一列:
[0 4 8]
[1 5 9]
[ 2 6 10]
[ 3 7 11]
---------------
迭代方式读取每一个元素:
[ 0 1 2 3 4 5 6 7 8 9 10 11]
0
1
2
3
4
5
6
7
8
9
10
11
"""
矩阵的操作
合并
- np.vstack() # 纵向合并
- np.hstack() # 横向合并
import numpy as np
arr1 = np.arange(10, 20).reshape(2, 5)
arr2 = np.arange(20, 30).reshape(2, 5)
print("打印矩阵arr1:")
print(arr1)
print("打印矩阵arr2:")
print(arr2)
print()
print("----纵向合并------")
print(np.vstack((arr1, arr2)))
print("----横向合并------")
print(np.hstack((arr1, arr2)))
"""
运行结果:
打印矩阵arr1:
[[10 11 12 13 14]
[15 16 17 18 19]]
打印矩阵arr2:
[[20 21 22 23 24]
[25 26 27 28 29]]
----纵向合并------
[[10 11 12 13 14]
[15 16 17 18 19]
[20 21 22 23 24]
[25 26 27 28 29]]
----横向合并------
[[10 11 12 13 14 20 21 22 23 24]
[15 16 17 18 19 25 26 27 28 29]]
"""
分割
注意分割的时候,要保证逻辑上的正确,比如:我要分割行,一共有三行,我要分为两个部分,这个时候就会报错。
import numpy as np
arr = np.arange(8).reshape(2, 4)
print("打印矩阵arr1:")
print(arr)
print()
print("----横向分割------")
print(np.vsplit(arr, 2))
print("----纵向分割------")
print(np.hsplit(arr, 2))
print("----使用split进行数据分割-----")
print(np.split(arr, 2,axis=1))
"""
运行结果:
打印矩阵arr1:
[[0 1 2 3]
[4 5 6 7]]
----横向分割------
[array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]])]
----纵向分割------
[array([[0, 1],
[4, 5]]), array([[2, 3],
[6, 7]])]
----使用split进行数据分割-----
[array([[0, 1],
[4, 5]]), array([[2, 3],
[6, 7]])]
"""
矩阵的拷贝
矩阵的拷贝并不像python中一样,有深拷贝和浅拷贝之分,复制了之后,它们操作的都是一样的数据。那我们只想要复制怎么办呢?这就要用到专门的函数来copy了。
import numpy as np
arr1 = np.arange(10)
arr2 = arr1
print(arr1 is arr2)
arr3 = arr1.copy()
print(arr1 is arr3)
"""
运行结果:
True
False
"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号