

python面向对象编程
不知道啥是面向对象的看:https://www.cnblogs.com/kuxingseng95/p/9482922.html,这里就不重复写了。
类和实例
类和实例都是面向对象最重要的概念。
在python中定义一个类:
class 类名: pass
不同于定义方法,类名后面可以不带括号,如果定义方法的话,必须带括号,比如:
def 方法名(): pass
定义一个类及实例化:
class People: pass laowang = People() # laowang是People的实例化
关于类的基本知识


class People: name = "laowang" age = 12 sex = "nan" laowang = People() laowang.eye_color = "black" laowang.skin_color = "yellow" laowang.sex = "nv" print(People.name) # laowang print(People.age) # 12 print(People.sex) # nan print(laowang.name) # laowang print(laowang.age) # 12 print(laowang.eye_color) # black print(laowang.sex) # nv print(People.eye_color) # 报错 # 由此可见实例可以使用类属性,而类无法使用实例属性 # 类的属性分为:数据属性和函数属性 # 1.类的数据属性是所有对象共有的 # 2.类的函数属性是绑定给对象用的,有兴趣的可以在类中写一个方法,再实例化两个对象,打印一下地址看看是不是不一样。
# -------------------------静态属性---------------------------------------- # 静态方法就是让我们用调用实例化对象的属性的方式,调用类的函数。 # 方法是用"@property"来装饰函数。 # 比如: class Dog: def __init__(self, name): self.name = name @property def jiao(self): print("%s:汪汪汪" % self.name) wangcai = Dog("旺财") print(wangcai.name) # 旺财 wangcai.jiao # 汪汪汪 # 使用静态方法的好处就是隐藏了背后的逻辑。 # -------------------------类方法----------------------------------------- # 到目前位置的类中函数都要和实例化后的类对象进行捆绑,而一些时候我们不想创建实例化对象,直接用“类.函数名”调用。 # 这个时候就需要类属性了。它需要用@classmethod进行装饰。这样就不需要self了, # 它有一个新的参数cls,它用来接收类,然后我们可以调用类的属性了。 # 当然了我们也可以往里加入一些参数,实例化后也能传值调用,但是这样,我们定义类属性有什么意义呢,所以不要做无意义的事情。 # 例如: class Dog: name = "旺财" @classmethod def jiao(cls): print("%s:汪汪汪" % cls.name) Dog.jiao() # 旺财:汪汪汪 # 类方法可以在不实例化的时候用"类名.方法名"调用,而且可以访问类属性。 # -------------------------静态方法----------------------------------------- # 类方法是用“@staticmethod”装饰 # 到目前位置,类中的普通函数和静态属性需要self,而类方法需要cls。 # 被它装饰了之后又可以称为类的工具包,因为它既不需要self,又不需要cls,也就是说既不跟实例对象绑定,又不跟类绑定。 # 那么问题来了,它和在类中直接定义一个函数,比如 # def test(x, y): # print(x, y) # 有什么区别呢?例子中说明 class Dog: @staticmethod def jiao(): print("汪汪汪" ) def test(x, y): print(x, y) Dog.jiao() # 汪汪汪 wangcai = Dog() wangcai.jiao() # 汪汪汪 Dog.test(10 ,20) # 10 20 dahuang = Dog() dahuang.test(10, 20) # 报错,报错内容是需要两个参数,但是给了三个,至于为什么给了三个,之前讲self的时候说过了。不懂回去看看。 # 总结:静态属性只是名义上的归属类管理,但是不能使用类变量和实例变量,是类的工具包。
类名.__name__ # 类的名字(字符串) 类名.__doc__ # 类的文档字符串(就是类中用三括号包裹的说明内容) 类名.__base__ # 类的第一个父类(在讲继承时会讲) 类名.__bases__ # 类所有父类构成的元组(在讲继承时会讲) 类名.__dict__ # 类的字典属性,键为属性名,对应的值为属性本身 类名.__module__ # 类定义所在的模块 类名.__class__ # 实例对应的类(仅新式类中)
dir([object]) # 会返回object所有有效的属性列表。 vars([object]) # 返回object对象的__dict__属性,其中object对象可以是模块,类,实例,或任何其他有__dict__属性的对象。所以,其与直接访问__dict__属性等价。 help([object]) # 调用内置帮助系统。 type(object) # 回对象object的类型。 hasattr(object, name) # 用来判断name(字符串类型)是否是object对象的属性,若是返回True,否则,返回False callable(object) # 若object对象是可调用的,则返回True,否则返回False。注意,即使返回True也可能调用失败,但返回False调用一定失败。
__init__(self,…):初始化对象,在创建新对象时调用 __del__(self):释放对象,在对象被删除之前调用 __new__(cls,*args,**kwd):实例的生成操作 __str__(self):在使用print语句时被调用 __getitem__(self,key):获取序列的索引key对应的值,等价于seq[key] __len__(self):在调用内联函数len()时被调用 __cmp__(stc,dst):比较两个对象src和dst __getattr__(s,name):获取属性的值(s.name) __setattr__(s,name,value):设置属性的值(s.name=value) __delattr__(s,name) 删除name属性(del s.name) __getattribute__():getattribute()功能与getattr()类似 __gt__(self,other):判断self对象是否大于other对象 __lt__(slef,other):判断self对象是否小于other对象 __ge__(slef,other):判断self对象是否大于或者等于other对象 __le__(slef,other):判断self对象是否小于或者等于other对象 __eq__(slef,other):判断self对象是否等于other对象 __call__(self,*args):把实例对象作为函数调用
# __init__方法是在实例化对象之后才会执行,只用来对对象进行初始化操作。 class school: def __init__(self, name, addr, type): self.name = name self.addr = addr self.type = type s1 = school('清华', '北京', '公立大学') # 先调用类产生空对象s1,然后调用school.__init__('清华', '北京', '公立大学') # 注:__init__中默认有return了,再写return就冲突了。
# 在理解这个self的时候,我看到了一个很好的说明方法,就是用方法实现类的作用 def school(name, addr, type): def init(name, addr, type): sch = { 'name': name, 'addr': addr, 'type': type, 'kao_shi': kao_shi, 'zhao_sheng': zhao_sheng, } return sch def kao_shi(school): print('%s 学校正在考试' % school['name']) def zhao_sheng(school): print('%s %s 正在招生' % (school['type'], school['name'])) return init(name, addr, type) s1 = school('哈佛', '美国', '私立大学') print(s1['name']) s1['zhao_sheng'](s1) s2 = school('清华', '北京', '公立大学') print(s2['name'], s2['addr'], s2['type']) s2['zhao_sheng'](s2) # 可以看到,当我们调用school类中的方法需要将实例化的对象作为参数传入 # 类其实也是这搞的,我们可以做个试验 class school: def __init__(self, name, addr, type): self.name = name self.addr = addr self.type = type def kao_shi(self): print('%s 学校正在考试' % self.name) def zhao_sheng(): print('%s %s 正在招生' % (self.type, self.name)) s1 = school('哈佛', '美国', '私立大学') print(s1.name) # 哈佛 s1.kao_shi() # 哈佛 学校正在考试 s2 = school('清华', '北京', '公立大学') print(s2.name) s2.zhao_sheng() # 报错,提示要获取0个参数,但是给了1个 # 到这里就应该看出来,当我们用实例化对象调用类的方法的时候,会自动传一个参数,而这个参数就是这个实例化的对象了。 # 到这里应该就知道self是个什么东西了吧
# 方式一 class People: country = 'China' x = 1 def run(self): print('----->', self) # 实例化出三个空对象 obj1 = People() obj2 = People() obj3 = People() # 为对象定制自己独有的特征 obj1.name = 'egon' obj1.age = 18 obj1.sex = 'male' obj2.name = 'lxx' obj2.age = 38 obj2.sex = 'female' obj3.name = 'alex' obj3.age = 38 obj3.sex = 'female' # 方式二 class People: country = 'China' x = 1 def run(self): print('----->', self) # 实例化出三个空对象 obj1 = People() obj2 = People() obj3 = People() # 为对象定制自己独有的特征 def chu_shi_hua(obj, x, y, z): obj.name = x obj.age = y obj.sex = z chu_shi_hua(obj1, 'egon', 18, 'male') chu_shi_hua(obj2, 'lxx', 38, 'female') chu_shi_hua(obj3, 'alex', 38, 'female') # 方式三 class People: country = 'China' x = 1 def chu_shi_hua(obj, x, y, z): obj.name = x obj.age = y obj.sex = z def run(self): print('----->', self) obj1 = People() # print(People.chu_shi_hua) People.chu_shi_hua(obj1, 'egon', 18, 'male') obj2 = People() People.chu_shi_hua(obj2, 'lxx', 38, 'female') obj3 = People() People.chu_shi_hua(obj3, 'alex', 38, 'female') # 方式四 class People: country = 'China' x = 1 def __init__(obj, x, y, z): obj.name = x obj.age = y obj.sex = z def run(self): print('----->', self) obj1 = People('egon', 18, 'male') # People.__init__(obj1,'egon',18,'male') obj2 = People('lxx', 38, 'female') # People.__init__(obj2,'lxx',38,'female') obj3 = People('alex', 38, 'female') # People.__init__(obj3,'alex',38,'female')
# @property可以将python定义的函数“当做”属性访问,从而提供更加友好访问方式,但是有时候setter/deleter也是需要的。 # 1》只有@property表示只读。 # 2》同时有@property和@x.setter表示可读可写。 # 3》同时有@property和@x.setter和@x.deleter表示可读可写可删除。 # # 为什么要使用property # 将一个类的函数定义成特性以后,对象再去使用的时候obj.name,根本无法察觉自己的name是执行 # 了一个函数然后计算出来的,这种特性的使用方式遵循了统一访问的原则 # -------------------------例子一----------------------------------------- import math class Circle: def __init__(self, radius): # 圆的半径radius self.radius = radius @property def area(self): return math.pi * self.radius ** 2 # 计算面积 @property def perimeter(self): return 2 * math.pi * self.radius # 计算周长 c = Circle(10) print(c.radius) print(c.area) # 可以向访问数据属性一样去访问area,会触发一个函数的执行,动态计算出一个值 print(c.perimeter) # 同上 # 输出 # 10 # 314.1592653589793 # 62.83185307179586 # 注意:此时的特性arear和perimeter不能被赋值 c.area = 3 # 为特性area赋值 ''' 抛出异常: AttributeError: can't set attribute ''' # -------------------------例子二----------------------------------------- class A(object): # 要求继承object def __init__(self): self.__name = None # 下面开始定义属性,3个函数的名字要一样! @property # 读 def name(self): return self.__name @name.setter # 写 def name(self, value): self.__name = value @name.deleter # 删除 def name(self): del self.__name a = A() print(a.name) # 读 a.name = 'python' # 写 print(a.name) # 读 del a.name # 删除 print(a.name) # 报错,AttributeError: 'A' object has no attribute '_A__name'
# 组合是指,在一个类中以另一个类的对象作为数据属性,称为类的组合。 class People: def __init__(self, name, age, sex): self.name = name self.age = age self.sex = sex class Course: def __init__(self, name, school_hour): self.name = name self.school_hour = school_hour def tell_info(self): print('课程%s, 课时:%s>' % (self.name, self.school_hour)) class Teacher(People): def __init__(self, name, age, sex, job_title): People.__init__(self, name, age, sex) self.job_title = job_title self.course = [] self.students = [] class Student(People): def __init__(self, name, age, sex): People.__init__(self, name, age, sex) self.course = [] laowang = Teacher('老王', 30, '男', '语文老师') laoli = Student('老李', 18, '男') python = Course('python', 20) linux = Course('java', 10) laowang.course.append(python) laowang.course.append(linux) laoli.course.append(python) laowang.students.append(laoli) # 使用 for obj in laowang.course: obj.tell_info() # 说明: # 组合与继承都是有效地利用已有类的资源的重要方式。但是二者的概念和使用场景皆不同, # 1.继承的方式 # 通过继承建立了派生类与基类之间的关系,它是一种'是'的关系,比如白马是马,人是动物。 # 当类之间有很多相同的功能,提取这些共同的功能做成基类,用继承比较好,比如老师是人,学生是人 # 2.组合的方式 # 用组合的方式建立了类与组合的类之间的关系,它是一种‘有’的关系,比如教授有生日,教授教python和linux课程,教授有学生s1、s2、s3... # 当类之间有显著不同,并且较小的类是较大的类所需要的组件时,用组合比较好
类的三大特性
类的三大特性分别是封装,继承,多态
封装
# 封装就是把我们不想让人看到的东西隐藏起来。 # 反应到代码中就是让类中的属性和方法不被外面的访问。 # 而隐藏的方式就是用双下划线开头的方式将属性隐藏起来。 # 类中所有双下划线开头的名称如"__x"都会在类定义时自动变形成:_类名__x的形式。 # 而这种变形只有在类定义阶段发生变形。 class A: __N = 0 # 类的数据属性就应该是共享的,但是语法上是可以把类的数据属性设置成私有的如__N,会变形为_A__N def __init__(self): self.__x = 10 # 变形为self._A__X def __foo(self): # 变形为_A__foo print("from A") def bar(self): self.__foo() # 只有在类内部才可以通过__foo的形式访问 a = A() a.bar() # from A print(A._A__N) # 0 a._A__foo() # from A print(a.__dict__) # {'_A__x': 10} a.__foo() # 报错,AttributeError: 'A' object has no attribute '__foo' # 1.这种机制也并没有真正意义上限制我们从外部直接访问属性,知道了类名和属性名就可以拼出名字:_类名__属性, # 然后就可以访问了,如a._A__N,即这种操作并不是严格意义上的限制外部访问,仅仅只是一种语法意义上的变形, # 主要用来限制外部的直接访问。 # 2.变形的过程只在类的定义时发生一次,在定义后的赋值操作,不会变形 # 封装的真谛在于明确地区分内外,封装的属性可以直接在内部使用,而不能被外部直接使用,然而定义属性的目的终 # 归是要用,外部要想用类隐藏的属性,需要我们为其开辟接口,让外部能够间接地用到我们隐藏起来的属性,那这么 # 做的意义何在??? # 先给出一个简单但是经典的例子。 class Teacher: def __init__(self, name, age): # self.__name=name # self.__age=age self.set_info(name, age) def tell_info(self): print('姓名:%s,年龄:%s' % (self.__name, self.__age)) def set_info(self, name, age): if not isinstance(name, str): raise TypeError('姓名必须是字符串类型') if not isinstance(age, int): raise TypeError('年龄必须是整型') self.__name = name self.__age = age t = Teacher('老王', 18) t.tell_info() t.set_info('老李', 19) t.tell_info() # 1:封装数据:将数据隐藏起来这不是目的。隐藏起来然后对外提供操作该数据的接口,然后我们可以在接口附加上 # 对该数据操作的限制,以此完成对数据属性操作的严格控制。 # 2:封装方法:目的是隔离复杂度,在编程语言里,对外提供的接口(接口可理解为了一个入口),可以是函数,称 # 为接口函数,这与接口的概念还不一样,接口代表一组接口函数的集合体。比如说取款是功能,这个功能有很多功 # 能组成:插卡、密码认证、输入金额、打印账单、取钱对使用者来说,只需要知道取款这个功能即可,其余功能我们 # 都可以隐藏起来,很明显这么做隔离了复杂度,同时也提升了安全性 # 3:python并不会真的阻止你访问私有的属性,模块也遵循这种约定,如果你非要不遵守,那也没法,只能来个最终的 # 办法。python要想与其他编程语言一样,严格控制属性的访问权限,只能借助内置方法如__getattr__,详见面向 # 对象进阶 # 封装的好处 # 封装在于明确区分内外,使得类实现者可以修改封装内的东西而不影响外部调用者的代码;而外部使用用者只知道一个接 # 口(函数),只要接口(函数)名、参数不变,使用者的代码永远无需改变。这就提供一个良好的合作基础——或者说,只 # 要接口这个基础约定不变,则代码改变不足为虑。 # 例子: # 类的设计者 class Room: def __init__(self, name, owner, width, length, high): self.name = name self.owner = owner self.__width = width self.__length = length self.__high = high def tell_area(self): # 对外提供的接口,隐藏了内部的实现细节,此时我们想求的是面积 return self.__width * self.__length # 使用者 r1 = Room('卧室', 'egon', 20, 20, 20) print(r1.tell_area()) # 400, 使用者调用接口tell_area # 类的设计者,轻松的扩展了功能,而类的使用者完全不需要改变自己的代码 class Room: def __init__(self, name, owner, width, length, high): self.name = name self.owner = owner self.__width = width self.__length = length self.__high = high def tell_area(self): # 对外提供的接口,隐藏内部实现,此时我们想求的是体积,内部逻辑变了,只需求修该下列一行就可以很简答的实现,而且外部调用感知不到,仍然使用该方法,但是功能已经变了 return self.__width * self.__length * self.__high # 对于仍然在使用tell_area接口的人来说,根本无需改动自己的代码,就可以用上新功能 r1 = Room('卧室', 'egon', 20, 20, 20) print(r1.tell_area()) # 8000
继承
继承同时具有两种含义
- 继承基类的方法,并且做出自己的改变或者拓展(常用于代码重用)
- 声明某个子类兼容于某基类,定义一个接口类,子类继承接口类。并实现接口中定义的方法。
继承基类
# ------------------------继承由来及单继承和多继承---------------------------------------- # 例子说明继承的由来 # 猫:喵喵叫 吃 喝 睡 # 狗:汪汪叫 吃 喝 睡 # 可以看到猫和狗除了有自己特殊的能力,还有大量重复的部分,反应到代码中,这些就是重复的冗余代码。类的继承就是用来解决这个问题的。 # 我们可以把猫和狗的共有属性提取成一个动物类, # 动物类:吃 喝 睡 # 猫和狗只要继承这个动物类,就可以拥有继承的基类中的所有类属性,然后再实现自己特殊的属性就可以了。这个时候动物类可以称为是父类,猫和狗可以称为子类。 # 一个类可以继承一个或者多个类,父类又可称为基类或者超类,子类又称为派生类。 # 在提取基类找出共性的时候,我们可以称之为是抽象, # 例子: class Animal: def eat(self): print("%s 吃 " % self.name) def drink(self): print("%s 喝 " % self.name) def shit(self): print("%s 睡 " % self.name) class Cat(Animal): def __init__(self, name): self.name = name self.breed = '猫' def cry(self): print('喵喵叫') class Dog(Animal): def __init__(self, name): self.name = name self.breed = '狗' def cry(self): print('汪汪叫') c1 = Cat('小白家的小黑猫') c1.eat() c2 = Cat('小黑的小白猫') c2.drink() d1 = Dog('胖子家的小瘦狗') d1.eat() # -------------------------单继承与多继承----------------------------------------- class p1: pass class p2: pass class p3(p1): pass class p4(p1, p2): pass print(p3.__bases__) # (<class '__main__.p1'>,) print((p4.__bases__)) # (<class '__main__.p1'>, <class '__main__.p2'>) # 一例看继承 class Foo: def f1(self): print('Foo.f1') def f2(self): print('Foo.f2') self.f1() class Bar(Foo): def f1(self): print('Bar.f1') b = Bar() b.f2() # 调用一个实例化对象的方法,它会先到自己的所属类中找,找不到再到父类的。 # 也就是说,当子类定义了自己的属性且与父类重名时,调用的时候以自己为准,所以不要认为是子类覆盖了父类的类属性。 # -------------------------经典类和新式类----------------------------------------- # 关于这个继承又要引出一个概念,就是经典类和新式类 # 1.只有在python2中才分新式类和经典类,python3中统一都是新式类 # 2.在python2中,没有显式的继承object类的类,以及该类的子类,都是经典类 # 3.在python2中,显式地声明继承object的类,以及该类的子类,都是新式类 # 3.在python3中,无论是否继承object,都默认继承object,即python3中所有类均为新式类 # 4.object是所有python类的基类,它实现了一些常见方法(如之前说明的类内置的特殊属性等。
继承顺序
- 当类是经典类时,多继承情况下,会按照深度优先方式查
- 当类是新式类时,多继承情况下,会按照广度优先方式查找
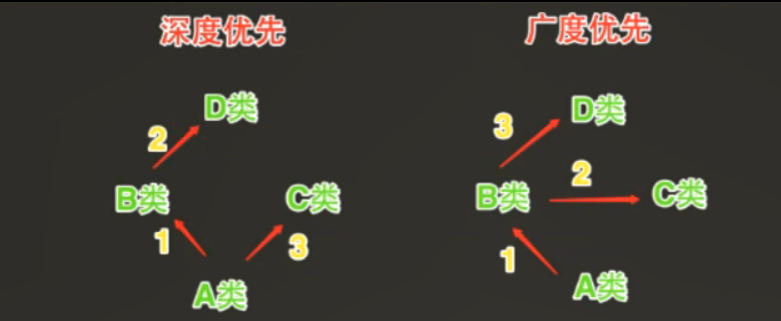
再说继承的时候说过经典类和新式类的概念,不清楚的可以去看看。
class A(object): def test(self): print('from A') class B(A): def test(self): print('from B') class C(A): def test(self): print('from C') class D(B): def test(self): print('from D') class E(C): def test(self): print('from E') class F(D,E): # def test(self): # print('from F') pass f1=F() f1.test() print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性 #新式类继承顺序:F->D->B->E->C->A #经典类继承顺序:F->D->B->A->E->C #python3中统一都是新式类 #pyhon2中才分新式类与经典类
对于定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个列表就是一个简单的所有基类的线性顺序表。
所有当我们想知道继承顺序的时候,不用拿着笔算,可以直接用“类名.__mro__ ”查看即可,需要注意的是python2中没有这个方法。
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1.子类会先于父类被检查
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,选择第一个父类
子类调用父类方法
# 子类调用父类的方法一共有两种方式 # 方法一:父类名.父类方法() class Animal: def __init__(self, name): self.name = name def eat(self): print("%s 吃 " % self.name) def drink(self): print("%s 喝 " % self.name) def shit(self): print("%s 睡 " % self.name) class Cat(Animal): def __init__(self, name): Animal.__init__(self, name) def jiao(self): print('%s喵喵叫'% self.name) xiaohua = Cat("小花") xiaohua.jiao() # 小花喵喵叫 # 方法二:super class Animal: def __init__(self, name): self.name = name def eat(self): print("%s 吃 " % self.name) def drink(self): print("%s 喝 " % self.name) def shit(self): print("%s 睡 " % self.name) class Cat(Animal): def __init__(self, name): # super().__init__(name) # 第一种写法 super(Cat, self).__init__(name) # 第二种写法,推荐 def jiao(self): print('%s喵喵叫'% self.name) xiaohua = Cat("小花") xiaohua.jiao() # 小花喵喵叫 # 需要注意的是,如果用的是super().属性去查找,它会基于Cat.mro()继续往后查找。
两种方式的区别:
#父类名.父类方法() class A: def __init__(self): print('A的构造方法') class B(A): def __init__(self): print('B的构造方法') A.__init__(self) class C(A): def __init__(self): print('C的构造方法') A.__init__(self) class D(B,C): def __init__(self): print('D的构造方法') B.__init__(self) C.__init__(self) pass f1=D() #A.__init__被重复调用 ''' D的构造方法 B的构造方法 A的构造方法 C的构造方法 A的构造方法 ''' #使用super() class A: def __init__(self): print('A的构造方法') class B(A): def __init__(self): print('B的构造方法') super(B,self).__init__() class C(A): def __init__(self): print('C的构造方法') super(C,self).__init__() class D(B,C): def __init__(self): print('D的构造方法') super(D,self).__init__() f1=D() #super()会基于mro列表,往后找 ''' D的构造方法 B的构造方法 C的构造方法 A的构造方法 '''
总结:
当你使用super()函数时,Python会在MRO列表上继续搜索下一个类。只要每个重定义的方法统一使用super()并只调用它一次,那么控制流最终会遍历完整个MRO列表,每个方法也只会被调用一次(注意注意注意:使用super调用的所有属性,都是从MRO列表当前的位置往后找,千万不要通过看代码去找继承关系,一定要看MRO列表)
接口
# 接口与抽象类 # -------------------------接口----------------------------------------- # 一开始接触接口,是我在java的学习中,而到了python中,则没有接口的概念了。在说在python中使用接口之前,先说明一下什么是接口。 # 接口是一个规范,它提取了一群共同的函数,可以把接口当作是一个函数的集合。然后让子类去实现接口中的函数。 # 遵守了接口的规范,我们就可以不加区分的处理所有接口兼容的对象集合。 # 比如:我们有一个汽车接口,里面定义了汽车所有的功能,然后由本田汽车的类,奥迪汽车的类,大众汽车的类,他们都实现了汽车接口, # 这样就好办了,大家只需要学会了怎么开汽车,那么无论是本田,还是奥迪,还是大众我们都会开了, # 开的时候根本无需关心我开的是哪一类车,操作手法(函数调用)都一样 # 总结一下: # 按照接口规范进行方法调用,就能获得所期望的功能 # 按照接口规范实现接口的的方法,就能提供所期望的功能 # 在一开始的时候,我就说过了,python中没有接口的概念。如果我们想用的话需要借助第三方的模块。 # http://pypi.python.org/pypi/zope.interface # twisted的twisted\internet\interface.py里使用zope.interface # 文档https://zopeinterface.readthedocs.io/en/latest/ # 设计模式:https://github.com/faif/python-patterns # 当然了,我们也可以使用继承。 class Interface: # 定义接口Interface类来模仿接口的概念,python中压根就没有interface关键字来定义一个接口。 def read(self): # 定接口函数read pass def write(self): # 定义接口函数write pass class Txt(Interface): # 文本,具体实现read和write def read(self): print('文本数据的读取方法') def write(self): print('文本数据的读取方法') class Sata(Interface): # 磁盘,具体实现read和write def read(self): print('硬盘数据的读取方法') def write(self): print('硬盘数据的读取方法') class Process(Interface): def read(self): print('进程数据的读取方法') def write(self): print('进程数据的读取方法') # 虽然上面的代码只是看起来像接口,其实并没有起到接口的作用,子类完全可以不用去实现接口 ,这就用到了抽象类 # -------------------------抽象类----------------------------------------- # 与java一样,python也有抽象类的概念但是同样需要借助模块实现,抽象类是一个特殊的类,它的特殊之处在于只能被继承,不能被实例化 # 如果说类是从一堆对象中抽取相同的内容而来的,那么抽象类就是从一堆类中抽取相同的内容而来的,内容包括数据属性和函数属性。 # 比如:我们有香蕉的类,有苹果的类,有桃子的类,从这些类抽取相同的内容就是水果这个抽象的类,你吃水果时,要么是吃一个具体的香蕉, # 要么是吃一个具体的桃子。。。。。。你永远无法吃到一个叫做水果的东西。 # 从设计角度去看,如果类是从现实对象抽象而来的,那么抽象类就是基于类抽象而来的。 # 从实现角度来看,抽象类与普通类的不同之处在于:抽象类中只能有抽象方法(没有实现功能),该类不能被实例化,只能被继承,且子类必须实现抽象方法。 # 这一点与接口有点类似,但其实是不同的 # 例如: import abc # 利用abc模块实现抽象类 class All_file(metaclass=abc.ABCMeta): all_type = 'file' @abc.abstractmethod # 定义抽象方法,无需实现功能 def read(self): '子类必须定义读功能' pass @abc.abstractmethod # 定义抽象方法,无需实现功能 def write(self): '子类必须定义写功能' pass # class Txt(All_file): # pass # # t1=Txt() #报错,子类没有定义抽象方法 class Txt(All_file): # 子类继承抽象类,但是必须定义read和write方法 def read(self): print('文本数据的读取方法') def write(self): print('文本数据的读取方法') class Sata(All_file): # 子类继承抽象类,但是必须定义read和write方法 def read(self): print('硬盘数据的读取方法') def write(self): print('硬盘数据的读取方法') class Process(All_file): # 子类继承抽象类,但是必须定义read和write方法 def read(self): print('进程数据的读取方法') def write(self): print('进程数据的读取方法') wenbenwenjian = Txt() yingpanwenjian = Sata() jinchengwenjian = Process() # 这样大家都是被归一化了,也就是一切皆文件的思想 wenbenwenjian.read() yingpanwenjian.write() jinchengwenjian.read() print(wenbenwenjian.all_type) print(yingpanwenjian.all_type) print(jinchengwenjian.all_type) # 总结: # 抽象类的本质还是类,指的是一组类的相似性,包括数据属性(如all_type)和函数属性(如read、write),而接口只强调函数属性的相似性。 # 抽象类是一个介于类和接口直接的一个概念,同时具备类和接口的部分特性,可以用来实现归一化设计
总结:
实践中继承的第一种含义感觉不是很大,因为它让子类和基类出现了强耦合。
接口继承实质上是要求做出一个良好的抽象,这个抽象规定了一个兼容接口,使得外部调用者无需关心具体的细节,可以一视同仁处理实现了特定接口的所有对象,在程序设计上,叫做归一化。
多态
# 在面向对象方法中一般是这样表述多态性:向不同的对象发送同一条消息(!!!obj.func():是调用了obj的方法func,又称为向obj发送了一条消息func), # 不同的对象在接收时会产生不同的行为(即方法)。也就是说,每个对象可以用自己的方式去响应共同的消息。 # 所谓消息,就是调用函数,不同的行为就是指不同的实现,即执行不同的函数。 # 比如:老师.下课铃响了(),学生.下课铃响了(),老师执行的是下班操作,学生执行的是放学操作,虽然二者消息一样,但是执行的效果不同 # 那么多态的好处是什么呢? # 1.增加了程序的灵活性 # 以不变应万变,不论对象千变万化,使用者都是同一种形式去调用,如func(animal) # 2.增加了程序的可拓展性 # 通过继承animal类创建了一个新的类,使用者无需更改自己的代码,还是用func(animal)去调用 # 多态的例子如下: import abc class Animal(metaclass=abc.ABCMeta): # 同一类事物:动物 @abc.abstractmethod def talk(self): pass class People(Animal): # 动物的形态之一:人 def talk(self): print('say hello') class Dog(Animal): # 动物的形态之二:狗 def talk(self): print('say wangwang') class Pig(Animal): # 动物的形态之三:猪 def talk(self): print('say aoao') def func(animal): animal.talk() laowang = People() wangcai = Dog() peiqi = Pig() func(laowang) # say hello func(wangcai) # say wangwang func(peiqi) # say aoao # 常见的使用: # str,list,tuple都是序列类型 s = str('hello') l = list([1, 2, 3]) t = tuple((4, 5, 6)) # 我们可以在不考虑三者类型的前提下使用s,l,t s.__len__() l.__len__() t.__len__() print(len(s)) print(len(l)) print(len(t))
欢迎转载,但请写明出处,谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号