[AI/LLM] 解读 Qwen 系列大模型
1 Qwen 系列模型解读
Qwen 系列模型在架构、性能、多语言支持等方面不断演进,不同版本特性差异明显,且不同参数规模的模型对硬件需求也有所不同。以下是 Qwen1.x、2.x、2.5、3 系列模型的特性及差异,以及其硬件需求的相关介绍:
模型清单
- 通义千问 (Qwen):语言模型
- Qwen: 1.8B、7B、14B 及 72B 模型
- Qwen1.5: 0.5B、1.8B、4B、14BA2.7B、7B、14B、32B、72B 及 110B 模型
- Qwen2.0: 0.5B、1.5B、7B、57A14B 及 72B 模型
- Qwen2.5: 0.5B、1.5B、3B、7B、14B、32B 及 72B 模型
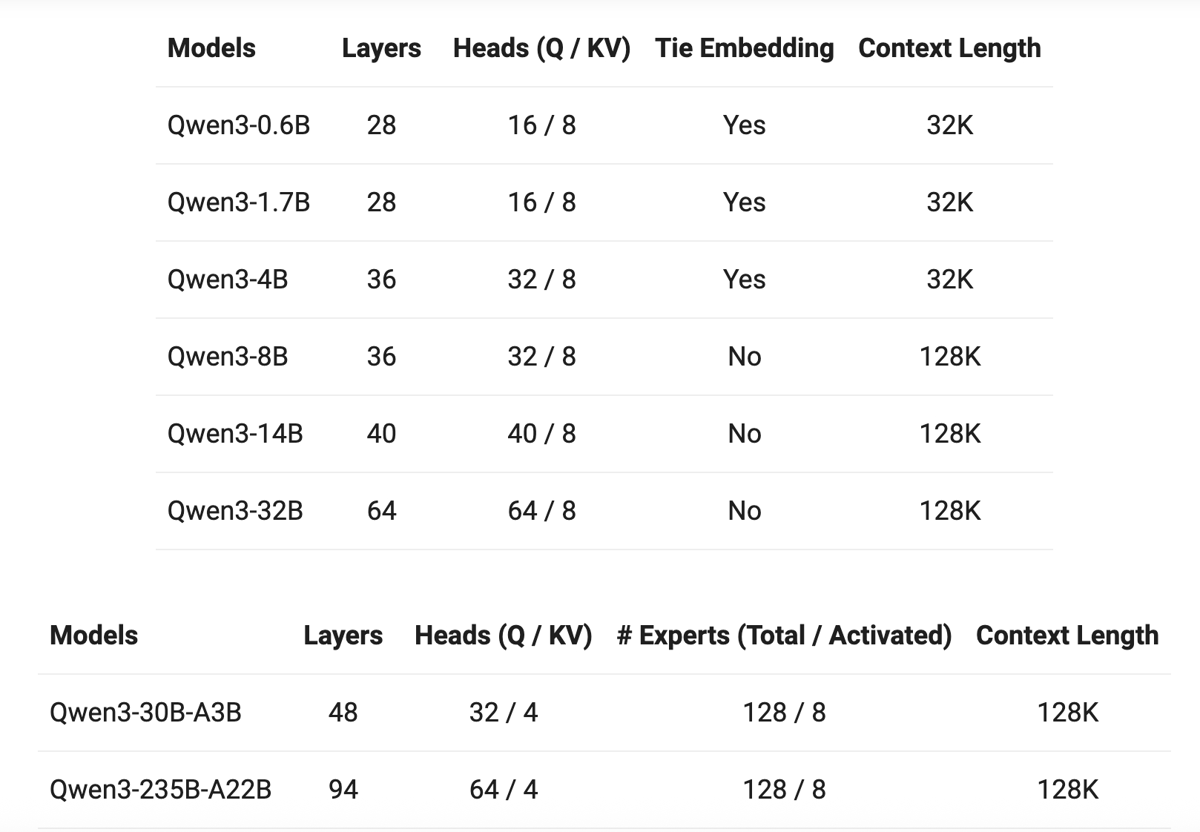
- Qwen3 : 0.6b / 1.7b / 4b / 8b / 14b / 30b / 32b / 235b
- 通义千问 VL (Qwen-VL): 视觉语言模型
- Qwen-VL: 基于 7B 的模型
- Qwen-VL: 基于 2B、7B 和 72B 的模型
- 通义千问 Audio: 音频语言模型
- Qwen-Audio: 基于 7B 的模型
- Qwen2-Audio: 基于 7B 的模型
- Code通义千问 / 通义千问Coder: 代码语言模型
- CodeQwen1.5: 7B 模型
- Qwen2.5-Coder: 7B 模型
- 通义千问 Math: 数学语言模型
- Qwen2-Math: 1.5B、7B 及 72B 模型
- Qwen2.5-Math: 1.5B、7B 及 72B 模型
特性/差异
- Qwen1.x 系列:采用经典 Transformer 解码器架构,使用旋转位置编码 RoPE 和分组查询注意力 GQA,如 Qwen1.5-110B 模型使用 GQA 优化了推理速度。该系列涵盖多种参数规模,如 Qwen-7B 有 32 层 Transformer、每层隐藏尺寸 4096,Qwen-14B 使用 40 层、隐藏尺寸 5120。Qwen1.5 全系列模型支持最长 32768 个 token 的上下文,Qwen-Long 可将上下文扩展到百万级别。
2023年8月,阿里首次开源通义千问第一代模型Qwen-7B,这是一个有70亿参数的通用语言模型。在此基础上,Qwen扩展了更多的参数版本,比如0.5B、14B、32B、72B等。与此同时, Qwen也在不断扩展能力,可以支持更多的模态输入,比如先后开源了Qwen-VL视觉语言模型和Qwen-Audio音频语言模型。
- Qwen2.x 系列:包含 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B 和 Qwen2-72B 等模型,所有尺寸模型都使用了 GQA 机制。在中英文之外,增加了 27 种语言相关的高质量数据,提升了多语言能力。Qwen2-72B-Instruct 能够完美处理 128k 上下文长度内的信息抽取任务。
2024年9⽉发布了 Qwen2.5系列,涵盖了多种尺⼨的⼤语⾔模型、多模态模型、数学模型以及代码模型,能够为不同领域的应⽤提供强有⼒的⽀持。不论是在⾃然语⾔处理任务中的⽂本⽣成与问答,还是在编程领域的代码⽣成与辅助,或是数学问题的求解,Qwen2.5 都能展现出⾊的表现。每种尺⼨的模型均包含基础版本、以及量化版本的指令微调模型,充分满⾜了⽤⼾在各类应⽤场景中的多样化需求。具体版本内容如下: • Qwen2.5: 0.5B, 1.5B, 3B, 7B, 14B, 32B, 以及72B; • Qwen2.5-Coder: 1.5B, 7B, 以及即将推出的32B; • Qwen2.5-Math: 1.5B, 7B, 以及72B • Qwen2.5-VL: 3B, 7B, 以及72B。
- Qwen2.5 系列:全系列涵盖了多个尺寸的大语言模型、多模态模型、数学模型和代码模型,在 18 万亿 tokens 数据上进行预训练,整体性能比 Qwen2 提升了 18% 以上。其在知识能力、数学能力方面都有显著改进,指令跟随与结构化数据处理能力也增强,支持高达 128k 的上下文长度,可生成最多 8k 内容,并且支持 29 种以上语言。
Qwen2.5系列是基于Transformer架构的语言模型,包括密集模型和MoE模型。
密集模型采用了Grouped Query Attention(GQA)、SwiGLU激活函数、Rotary Positional Embeddings(RoPE)以及QKV bias等技术来提高模型性能。
MoE模型则使用了专门的MoE层替换标准的feed-forward网络层,并通过细粒度专家分割和共享专家路由等策略提高了模型能力。
- Qwen3 系列:提供从 0.6B 到超大规模的 235B-A22B 多种模型,涵盖 Dense 和 MoE 架构。Qwen3 的 MoE 模型通过全局批处理负载均衡和稀疏激活,在性能和效率之间取得平衡。训练数据超过 36 万亿 token,覆盖 119 种语言。Qwen3 首创「思考模式」与「普通模式」双形态切换,复杂推理场景下启用思考模式,普通问答场景则切换至普通模式,响应速度提升 3 倍。
| 维度 | Qwen1.x 系列 | Qwen2.x/2.5 系列 | Qwen3 系列(核心优势) |
|---|---|---|---|
| 架构基础 | 经典 Transformer(GQA) | 增强型 Transformer + 视觉模块 | 混合专家(MoE)架构,支持 “思考 / 非思考” 双模式切换,算力效率提升 3 倍以上 |
| 核心能力 | 文本理解与生成,基础对话 | 多模态(图文 / 音视频)+ 文档解析 | 全模态 “不降智”(19 种语言输入 + 10 种输出)、视觉 Agent(GUI 操作)、256K 超长上下文(可扩至 1M) |
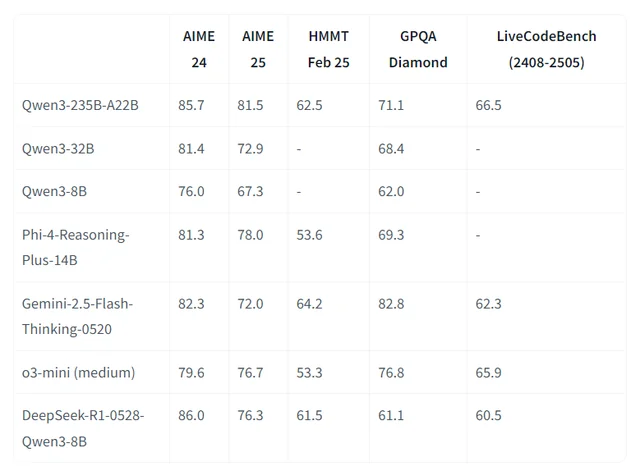
| 性能天花板 | 72B 参数,数学 / 代码能力一般 | 72B 参数,视觉理解精度 95% 左右 | 235B MoE / 万亿参数 Qwen MAX,数学推理(AIME25 满分)、代码生成(SWE-Bench 69.6 分)达国际顶尖 |
| 商用友好性 | 开源但商用需单独授权 | 部分开源,商用受限 | 全系 Apache 2.0 协议,0 元免费商用,支持裁剪 / 二次训练,无场景限制 |
| 部署成本 | 7B 模型需 12GB 显存,成本中等 | 14B 模型需 24GB 显存,成本较高 | 支持 4-bit 量化 + 动态上下文,480B 模型可在单张 RTX 4090(24GB)运行,日均成本低至 $72 |
重要模型
Qwen3-8B
Qwen3-8B是阿里巴巴于 2025 年 4 月发布的通义千问第三代大模型系列中的 80 亿参数的密集模型,采用 Apache 2.0 开源协议,可自由用于商业与研究场景。
- 总参数量:80 亿
- 架构类型:Dense(纯稠密结构)
- 上下文长度:128K tokens
- 支持多语言:覆盖 119 种语言和方言
- 尽管体积小巧,Qwen3-8B 在推理、代码、数学和 Agent 能力方面表现稳定,性能媲美前代更大的模型,在实际应用中展现出极高的实用性。
强大训练基础,小模型也有大智慧
Qwen3-8B基于 约 36 万亿 token 的高质量多语言数据完成预训练,涵盖网页文本、技术文档、代码库与专业领域合成数据,知识覆盖面广。
其后训练阶段引入了四阶段强化流程,特别优化了以下能力:
- ✅ 自然语言理解与生成
- ✅ 数学推理与逻辑分析
- ✅ 多语言翻译与表达
- ✅ 工具调用与任务规划
- 得益于训练体系的全面升级,
Qwen3-8B的实际表现接近甚至超越Qwen2.5-14B,实现显著的参数效率跃迁。
混合推理模式:思考 or 快速响应?
Qwen3-8B支持 “思考模式”与“非思考模式” 的灵活切换,用户可根据任务复杂度自主选择响应方式。
通过以下方式控制模式:
- API 参数设置:
enable_thinking=True/False- 提示词指令:在输入中添加
/think或/no_think
| 模式 | 适用场景 | 示例 |
|---|---|---|
| 思考模式 | 复杂推理、数学题、规划类任务 | - 求解几何问题 - 编写完整项目架构 |
| 非思考模式 | 快速问答、翻译、摘要 | - 查询天气 - 中英文互译 |
该设计让用户在响应速度与推理深度之间自由权衡,提升使用体验。
原生支持 Agent 能力,赋能智能应用
- Qwen3-8B 具备出色的 Agent 化能力,可轻松集成到各类自动化系统中:
🔹 函数调用(Function Calling):支持结构化工具调用
🔹 MCP 协议兼容:原生支持模型上下文协议,便于扩展外部能力
🔹 多工具协同:可接入搜索、计算器、代码执行等插件
- 推荐结合 Qwen-Agent 框架 使用,快速构建具备记忆、规划与执行能力的智能助手。
广泛语言支持,面向全球应用
- Qwen3-8B 支持包括中文、英文、阿拉伯语、西班牙语、日语、韩语、印尼语等在内的 119 种语言和方言,适用于国际化产品开发、跨语言客服、多语种内容生成等场景。
对中文理解尤为出色,支持简体、繁体及粤语表达,适用于港澳台及海外华人市场。
实用能力强,场景覆盖广
- Qwen3-8B 在多个高频应用场景中表现优异:
- ✅ 代码生成:支持 Python、JavaScript、Java 等主流语言,能根据需求生成可运行代码
- ✅ 数学推理:在 GSM8K 等基准中表现稳定,适合教育类应用
- ✅ 内容创作:撰写邮件、报告、文案,结构清晰、语言自然
- ✅ 智能助手:可构建个人知识库问答、日程管理、信息提取等轻量级 AI 助手
硬件需求
- 内存:≥16GB(8B)、≥24GB(14B)、≥64GB(32B)。
- GPU:推荐RTX 3090/4090或消费级H20卡(32B需4张H20,显存占用仅为同类模型的1/3)。
部署和微调
Qwen3-8B模型,对硬件的需求取决于你是【仅部署推理】,还是进行【微调】(如LoRA、QLoRA),以及是否使用【量化】优化。以下是基于2025年最新资料的详细建议:
- 部署(推理)的硬件需求
| 场景 | 显存需求 | 推荐硬件配置 |
|---|---|---|
| FP16 精度推理 | ~16 GB | 单张 RTX 4090(24GB) 或 A100(40GB) |
| 4-bit 量化推理 | ~7 GB | 单张 RTX 3060(12GB) 或 A10(24GB) |
| 长上下文(RoPE 缩放) | 需额外显存 | 建议使用 48GB 显存(如 A6000 或 A100 80GB) |
总结:RTX 4090 是本地部署 Qwen3-8B 的性价比首选,支持 FP16 推理无压力;若使用量化,RTX 3060 也能跑。
- 微调(Fine-tuning)硬件需求
| 微调方式 | 显存需求 | 推荐配置 |
|---|---|---|
| LoRA(FP16) | ~20 GB | 单张 RTX 4090(24GB) 足够 |
| QLoRA(4-bit 量化) | ~10–12 GB | 单张 RTX 3090(24GB) 或 4090 可胜任 |
| 全参数微调(Full Fine-tune) | >80 GB | 需 A100 80GB 或多卡并行,不推荐本地尝试 |
- 其他硬件的建议
| 组件 | 建议配置 |
|---|---|
| CPU | ≥ 8 核,推荐 Intel i7 / AMD Ryzen 7 以上 |
| 内存 | ≥ 32 GB(建议 64GB,尤其微调时) |
| 存储 | ≥ 500GB NVMe SSD(模型文件约 16GB,数据集可能更大) |
| 系统 | Ubuntu 20.04+,CUDA 12.5+,PyTorch 2.1+ |
- 推荐部署/微调组合
| 目标 | 推荐配置 |
|---|---|
| 本地推理(FP16) | RTX 4090 + 32GB RAM + Ubuntu |
| 本地微调(LoRA) | RTX 4090 + 64GB RAM + CUDA 12.8 + DeepSpeed |
| 云端推理/微调 | A100 40G/80G(如阿里云 PAI、AutoDL、Compshare) |
- 注意事项
- 使用 vLLM 或 SGLang 可显著提升推理速度与并发能力。
- 微调时建议用 LLaMA-Factory 或 ms-swift 框架,已集成 LoRA、DeepSpeed、量化等优化。
- 若用 RoPE 缩放(支持长文本),显存需求会显著增加,建议 48GB 显存起步
Qwen3-8B本地部署+微调,单张 RTX 4090(24GB)是当前最具性价比的选择,支持 FP16 推理和 LoRA 微调。若预算充足,A100 80GB 可支持更长文本和更高并发。
- 补充:仅部署推理场景下,Qwen3-8B:RTX 5070 Ti / 5070 Ti Super / A10G 可行性 & 性价比对比
| 项目 | RTX 5070 Ti | RTX 5070 Ti Super (传闻:2026年上半年发布) |
NVIDIA A10G |
|---|---|---|---|
| 显存容量 | 16 GB GDDR7 | 24 GB GDDR7 | 24 GB GDDR6 |
| 显存带宽 | ~1 TB/s | ~1 TB/s | 600 GB/s |
| FP16 算力 | ~80 TFLOPS | ~90 TFLOPS | ~31 TFLOPS |
| 是否支持 INT8/GPTQ | ✅ | ✅ | ✅ |
| 单卡 FP16 推理 Qwen3-8B | ❌ 显存不足(需 16~18 GB) | ✅ 足够 | ✅ 足够 |
| 单卡 4-bit 量化推理 | ✅ 显存充足 | ✅ 更宽裕 | ✅ 显存充足 |
| 长上下文(≥32K) | ⚠️ 受限 | ✅ 支持 | ✅ 支持 |
| 并发能力 | 中等 | 高 | 高 |
| 功耗(TDP) | ~300W | ~350W | 150W |
| 价格(2025Q4) | 799(美元) | 999(美元) | 1500(美元)(云) |
| 可采购性 | 消费级,易购买 | 消费级,易购买 | 云/数据中心为主 |
显卡对比:
| 维度 | A10G | RTX 3080 | RTX 3090 | RTX 4070 | 备注 |
|---|---|---|---|---|---|
| 定位 | 数据中心推理卡 | 消费级游戏卡 | 消费级旗舰卡 | 消费级能效卡 | 根本差异 |
| 显存 | 24 GB GDDR6 | 10/12 GB GDDR6X | 24 GB GDDR6X | 12 GB GDDR6X | A10G 大且稳 |
| 显存带宽 | 600 GB/s | 760 GB/s | 936 GB/s | 504 GB/s | RTX 更高频 |
| FP32 算力 | ≈31 TFLOPS | ≈30 TFLOPS | ≈36 TFLOPS | ≈29 TFLOPS | 纸面接近 |
| Tensor Core | 288 个(三代) | 272 个 | 328 个 | 184 个(四代) | 数量≠性能 |
| RT Core | 72 个 | 68 个 | 82 个 | 46 个 | 游戏光追差别大 |
| TDP 功耗 | 150 W | 320 W | 350 W | 200 W | A10G 能效翻倍 |
| 输出接口 | 无显示口 | 3×DP+1×HDMI | 同上 | 同上 | A10G 纯计算卡 |
| 虚拟化 | vGPU/SR-IOV | ❌ | ❌ | ❌ | 云必备 |
| 驱动分支 | NVIDIA Tesla/数据中心分支 | Game Ready | Game Ready | Game Ready | 驱动策略不同 |
| 价格/可得性 | 云实例(≈1.3美元/h) |
已停产二手≈400美元 | 二手≈700美元 | 新卡≈499美元 | A10G 不零售 |
A10G:为 云推理、虚拟化、CV/NLP 推理 优化,强调 7×24 稳定、低功耗、多租户隔离。
RTX:为 游戏、创作、本地训练 优化,强调 峰值性能、超频、显示输出。
A10G 不零售,只能通过 云实例/整机 OEM 获得,三年质保+ECC+24×7 支持。
RTX 零售渠道丰富,个人易购买,质保通常三年但无 ECC,矿卡/翻新风险高。
应用场景及硬件需求
| 模型参数规模 | 行业应用场景 | GPU 需求 | 内存需求 | CPU 需求 |
|---|---|---|---|---|
| 0.5B-1.8B | 边缘设备部署、极轻量级对话 | 无(纯 CPU 可推理,但推荐 4GB 显存如 GTX 1650) | 8GB-16GB | 4 核 8 线程 - 8 核 16 线程 |
| 4B-7B | 个人聊天机器人、轻量级办公助手 | 6GB 显存(如 RTX 3060),推荐 12GB-16GB 显存(如 RTX 4080) | 16GB-32GB | 四核 8 线程 - 八核 16 线程 |
| 14B-32B | 专业领域助手、复杂代码生成 | 10GB-12GB 显存(如 RTX 4080),推荐 24GB 显存(如 RTX 6000 Ada) | 32GB-64GB | 八核 16 线程 - 十六核 32 线程 |
| 72B 及以上 | 大型企业级应用、复杂任务处理 | 24GB 及以上显存(如 H100) |
2 场景化模型推荐方案
-
要做出选择,首先需明确 Qwen3 相比 1.x/2.x 系列的本质突破,这直接决定了其适用边界:
-
结合最新行业落地案例(2025 年云栖大会及企业实践),不同场景的最优选择如下:
2.1 优先选 Qwen3 的核心场景
这些场景中,Qwen3 的技术突破能直接解决痛点,且成本可控:
企业级多模态应用
-
- 典型场景:工业质检(微米级缺陷检测)、视觉编程(UI 图转代码)、车载智能助手
-
- 推荐模型:Qwen3-VL(30B Dense 边缘版 / 235B MoE 云端版)
-
- 核心价值:检测精度 99.87%(超传统方案 4.5 个百分点),前端开发效率提升 70%,支持 AR 导航与 GUI 操作闭环
-
- 硬件参考:边缘用单张 RTX 4090,云端用 2×A100 80GB
高复杂度专业任务
-
- 典型场景:代码库重构(256K 上下文)、科学计算(公式推导)、跨国企业客服
-
- 推荐模型:Qwen3-Coder(480B)、Qwen3-Omni(全模态)
-
- 核心价值:TerminalBench 分数行业领先,支持 54 种语言翻译,100 万字代码一次性处理
-
- 硬件参考:混合部署(2×RTX 4090 + 云端 API),日均成本 $288
低成本商用落地
-
- 典型场景:创业公司智能客服、中小企业知识库、定制化 AI 助手
-
- 推荐模型:Qwen3-7B/14B(开源免费商用)
-
- 核心价值:Apache 2.0 协议无合规风险,相比 LLaMA 3 商用授权成本节省 100%,中文能力碾压同类开源模型
-
- 硬件参考:16GB 显存 GPU(如 RTX 3060),内存 32GB
2.2 可选其他系列的场景
当资源有限或需求简单时,1.x/2.x 系列更具性价比:
边缘轻量部署
-
- 典型场景:物联网设备本地推理、嵌入式 AI 交互(如智能音箱)
-
- 推荐模型:Qwen1.5-0.5B/1.8B(32K 上下文)
-
- 核心理由:纯 CPU 可运行(8GB 内存足够),推理延迟比 Qwen3-0.6B 低 30%,满足基础问答需求
单一文本任务
-
- 典型场景:日志分析、简单文案生成、内部聊天机器人
-
- 推荐模型:Qwen2-7B(文本专项优化)
-
- 核心理由:显存需求仅 8GB(Qwen3-7B 需 12GB),文本生成速度比 Qwen3 快 15%,无多模态冗余功能
预算极度有限的试点
-
- 典型场景:个人开发者实验、高校科研原型、小流量工具
-
- 推荐模型:Qwen1.5-4B(量化版)
-
- 核心理由:4GB 显存即可运行(如 GTX 1650),相比 Qwen3 轻量版部署成本降低 60%
M 决策 Checklist 与避坑指南
3 步快速决策
-
明确核心需求:是否需要多模态 / 超长上下文 / 代码能力?是→Qwen3;否→1.x/2.x
-
核对硬件预算:单卡 24GB 以上→Qwen3-VL/Coder;8GB 以下→Qwen1.5 轻量版
-
确认商用属性:需商业化落地→必选 Qwen3(Apache 2.0);非商用→可选 Qwen1.5
常见误区避坑
-
❌ 盲目追求大参数:Qwen3-7B 量化版在客服场景性能接近 14B,成本降低 40%
-
❌ 忽视部署优化:Qwen3-Coder 通过动态上下文调整,可节省 75% 显存(从 256K 缩至 8K)
-
❌ 混淆开源协议:Qwen1.x 商用需申请授权,Qwen3 全系免费商用(含企业级 72B 模型)
Z FAQ for Qwen
Q: 显卡对比
| 显卡产品代号 | 显卡厂商 | 显存类型 | 显存容量 | 显存位宽 | 显存频率 | 显存带宽 (GB/s) | 架构 | 支持 PCIe 5.0 | CUDA 核心数 | Tensor 核心数 | 显卡总功耗 (W) | 建议系统功率 (W) | 可部署开源 LLM 模型(示例) | 参考价格(人民币) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RTX 5070 Ti | NVIDIA | GDDR7 | 16GB | 256bit | 28Gbps | 896 | Blackwell | 是 | 8960 | 12 Ultimate | 300 | 850 | LLaMA 等 | 未明确公布,可参考同系列定价推测 | |
| RTX 5070 Ti Super | NVIDIA | GDDR7 | 16GB | 256bit | 28Gbps | 896 | Blackwell 2.0 | 是 | 8960 | 280 | 350 | 750 | LLaMA 等 | 未明确公布 | |
| RTX 4090 | NVIDIA | GDDR6X | 24GB | 384bit | 21Gbps | 1008 | Ada Lovelace | 否 | 16384 | 512 | 450 | 750 | LLaMA 等 | 已停产,原价约 12999 | |
| RTX 5090 | NVIDIA | GDDR7 | 32GB | 512bit | — | 1792 | Blackwell | 是 | 21760 | 3352 | — | — | LLaMA 等 | 约 71990 新台币起,折合人民币约 16000 元 | |
| RTX 5080 | NVIDIA | GDDR7 | 16GB | — | — | — | Blackwell | 是 | 7680 | — | — | — | — | LLaMA 等 | 约 999 美元,折合人民币约 7300 元 |
| RTX 4080 Super | NVIDIA | GDDR6X | 16GB | 256bit | — | — | Ada Lovelace | 否 | 10240 | 256 | — | — | LLaMA 等 | 8099 起 | |
| A10G | NVIDIA | GDDR6 | 12GB | 384bit | 1563MHz | 600.2 | Ampere | 否 | 9216 | 288 | 150 | 450 | LLaMA 等 | 未明确公布 |
Q:部署 Qwen3-8B, CPU选择 i7 还是 i9?
-
推荐
i7芯片,在你的服务器应用场景中性价比更高,与 i9 的性能差距微乎其微。 -
核心维度差异
| 维度 | i7-14700KF | i9-14900KF |
|---|---|---|
| 核心数 | 20 核 | 24 核 |
| 线程数 | 28 线程 | 32 线程 |
| 睿频 | 5.4GHz | 6.0GHz |
| L3 缓存 | 30MB | 36MB |
| 电商参考价 | 约 2400 元 | 约 3100 元 |
- 性能差距分析
实际应用测试显示,i7 与 i9 在游戏中的性能差距仅为3%,在 2K/4K 分辨率下差距更小,因为显卡成为性能瓶颈。对于你的应用场景:
- AI 应用开发:两者性能表现相近,i7 已足够支持 Ollama、Dify 等平台
- 大数据处理:i7 的 20 核 28 线程完全满足 Hadoop、Flink 的运算需求
- LLM 大模型部署:Qwen3-8B 对 CPU 要求并非极端苛刻,i7 性能已足够
-
推荐理由
- 性价比突出:i9 价格贵约 700 元,但性能提升不明显
- 功耗优势:i7 发热量相对较低,更适合家庭服务器长时间运行
- 游戏表现:在你的应用中,i7 与 i9 游戏性能基本一致
-
选购建议
- 首选 i7-14700KF:满足所有应用需求,性价比最佳
- 考虑 i9:预算充足且追求极致多核性能,差价在 300 元以内可考虑
- 主板选择:两者都支持 LGA1700 接口,可共用同一款主板
对于家庭服务器的 AI 应用和大数据实践,i7-14700KF 提供了最佳的性能价格比。
Y 推荐文献
-
显卡天体图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号