双向广搜-BiDirectional BFS
双向广搜
前言
复习acwing、洛谷算法,提高课的内容,本篇为讲解算法:双向广搜
一、双向广搜
双向广搜其实就是两个bfs,我们知道bfs是一种暴力的做题方法,搜索树长下图所示:
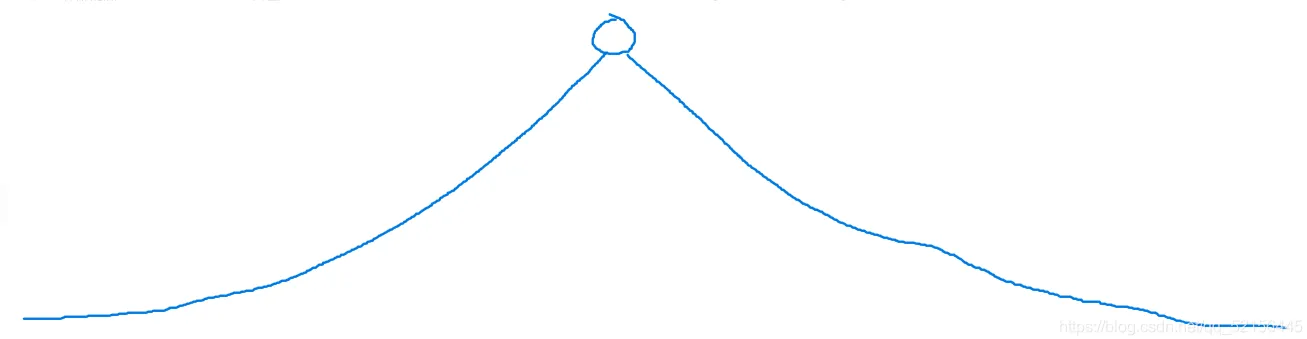
我们会发现搜索树越来越宽,每一层的搜索量增加,如果数据范围很大的话,显然是会TLE的,那么为了避免TLE,我们可以采用双向广搜,即两个bfs,如下图所示:
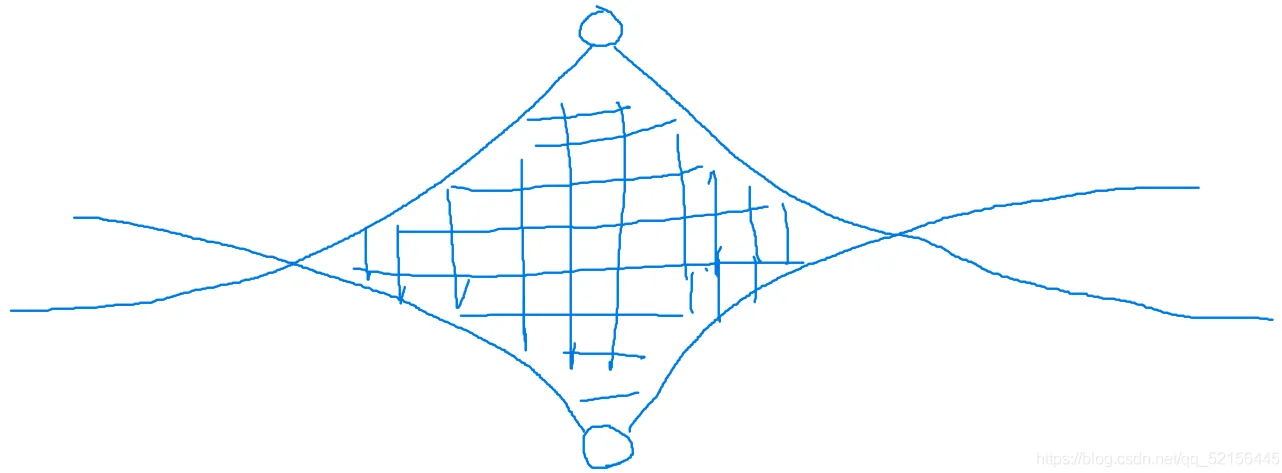
这个样子就可以省去很多不必要的搜索量,我们在这个基础上可以再次优化,每次只bfs一次,每次bfs那个队列容量少的部分。
二、AcWing 190(洛谷P1032). 字串变换
本题链接:AcWing 190. 字串变换 洛谷P1032. 字串变换
本博客提供本题截图:

本题分析
定义两个队列,分别表示开始和末尾,进行双向广搜,我们每次挑出来含元素少的队列进行bfs,qa表示从起始位置开始的bfs,qb表示的是从结尾开始的bfs,da表示的距离是从起始到当前的距离,db表示的距离是从结尾到当前的距离,extend表示的是扩展的过程,这里需要注意的话如果是对qb执行extend操作的话,是把b变成a
对于extend操作:
if (da.count(state)) continue;
if (db.count(state)) return da[t] + 1 + db[state];如果state出现在da,那么证明被更新过,直接continue这种情况
如果state出现在db,那么证明已经找到了最后的结果,即双向光搜碰头了,那么就把距离返回给main
AC代码
#include <cstring>
#include <iostream>
#include <algorithm>
#include <unordered_map>
#include <queue>
using namespace std;
const int N = 6;
int n;
string a[N], b[N];
int extend(queue<string>& q, unordered_map<string, int>& da, unordered_map<string, int>& db, string a[], string b[])
{
for (int k = 0, sk = q.size(); k < sk; k ++ )
{
string t = q.front();
q.pop();
for (int i = 0; i < t.size(); i ++ )
for (int j = 0; j < n; j ++ )
if (t.substr(i, a[j].size()) == a[j])
{
string state = t.substr(0, i) + b[j] + t.substr(i + a[j].size());
if (da.count(state)) continue;
if (db.count(state)) return da[t] + 1 + db[state];
da[state] = da[t] + 1;
q.push(state);
}
}
return 11;
}
int bfs(string A, string B)
{
queue<string> qa, qb;
unordered_map<string, int> da, db;
qa.push(A), da[A] = 0;
qb.push(B), db[B] = 0;
while (qa.size() && qb.size())
{
int t;
if (qa.size() <= qb.size()) t = extend(qa, da, db, a, b);
else t= extend(qb, db, da, b, a);
if (t <= 10) return t;
}
return 11;
}
int main()
{
string A, B;
cin >> A >> B;
while (cin >> a[n] >> b[n]) n ++ ;
int step = bfs(A, B);
if (step > 10) puts("NO ANSWER!");
else printf("%d\n", step);
return 0;
}三、洛谷P1379. 八数码难题
本题链接: 洛谷P1379. 八数码难题 这道题是acwing-179. 八数码的低配版
#include <iostream> #include <queue> #include <unordered_map> #include <string> #include <algorithm> using namespace std; // 目标状态 const string target = "123804765"; // 定义四个方向:上、下、左、右 const int dx[4] = {-1, 1, 0, 0}; const int dy[4] = {0, 0, -1, 1}; // 扩展队列的函数,用于从当前队列中取出状态并进行扩展 // q 是要扩展的队列,dist 存储从起点到当前状态的步数,other_dist 存储从另一个方向到当前状态的步数 int extend(queue<string>& q, unordered_map<string, int>& dist, unordered_map<string, int>& other_dist) { int size = q.size(); // 遍历当前队列中的所有状态 for (int i = 0; i < size; i++) { string state = q.front(); q.pop(); // 找到空格(0)的位置 int idx = state.find('0'); int x = idx / 3, y = idx % 3; // 尝试向四个方向移动空格 for (int j = 0; j < 4; j++) { int nx = x + dx[j], ny = y + dy[j]; // 判断新位置是否合法 if (nx >= 0 && nx < 3 && ny >= 0 && ny < 3) { string next_state = state; // 交换空格和相邻棋子的位置 swap(next_state[idx], next_state[nx * 3 + ny]); // 如果新状态已经在 dist 中出现过,跳过 if (dist.count(next_state)) continue; // 如果新状态已经在 other_dist 中出现过,说明找到了从起点到终点的路径 if (other_dist.count(next_state)) return dist[state] + 1 + other_dist[next_state]; // 记录新状态到 dist 中,并更新步数 dist[next_state] = dist[state] + 1; // 将新状态加入队列 q.push(next_state); } } } // 如果没有找到从起点到终点的路径,返回 -1 return -1; } // 双向广度优先搜索函数,用于寻找从初始状态到目标状态的最短转换步数 int bfs(string start) { // 定义两个队列,分别用于从起点和终点开始搜索 queue<string> q1, q2; // 定义两个哈希表,分别记录从起点和终点到每个状态的步数 unordered_map<string, int> dist1, dist2; // 将起点加入队列,并初始化步数为 0 q1.push(start); dist1[start] = 0; // 将终点加入队列,并初始化步数为 0 q2.push(target); dist2[target] = 0; // 当两个队列都不为空时,继续搜索 while (q1.size() && q2.size()) { int t; // 选择队列元素较少的那个进行扩展 if (q1.size() <= q2.size()) t = extend(q1, dist1, dist2); else t = extend(q2, dist2, dist1); // 如果找到了从起点到终点的路径,返回步数 if (t != -1) return t; } // 如果没有找到从起点到终点的路径,返回 -1 return -1; } int main() { string start; cin >> start; // 调用双向广度优先搜索函数,计算最短转换步数 int step = bfs(start); cout << step << endl; return 0; }
四、相关总结:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号