秒杀接口设计的基本思路和问题
1 应用技术栈
step1: springboot框架以及thymeleaf模板。
step2:集成ORM框架mybatis-springboot-start依赖,MySQL客户端(MySQL-connector依赖)以及druid连接池依赖。
step3:集成redis,包括jedis依赖以及fastjson依赖,对象序列化的工具fastjson是json格式,是可读的。
step4:集成org.apache.commons提供的工具包实现MD5加密
step5:引入spring-boot-starter-validation依赖,该工具提供了JSR303参数校验,是一个运行时的数据验证框架,在验证之后验证的错误信息会被马上返回。
(简单的讲借助这个工具可以减少自己去校验参数的工作量)
=====================================================================================
1)用户数据库设计
2)明文密码两次MD5校验
3)JSR303参数校验+全局异常处理器
4)分布式session
===================================================================
抢购功能实现:
1)数据库设计
2)商品列表页
3)商品详情页
4)订单详情页
常见的对象序列化工具(实现深拷贝的方式之一)
实际项目中,我们经常需要使用序列化工具来存储和传输对象。目前用得比较多的序列化工具有:jackson、fastjson、kryo、protostuff、fst 等
2 springboot中常用的注解
@Component: Marks a constructor, field, setter method or config method as to be autowired by Spring's dependency injection facilities(标记构造器,属性,设置/配置方法,sprign提供的依赖注入工具会自动加标记的东西autowired到指定的地方)
@Bean:Indicates that a method produces a bean to be managed by the Spring container(表明被注解的方法会提供一个bean给spring容器管理)
@ResponseBody:Annotation that indicates a method return value should be bound to the web response body. Supported for annotated handler methods.(方法的返回值与web的response body进行绑定,即让返回值在web网页显示)
@Service:Indicates that an annotated class is a "Service", originally defined by Domain-Driven Design (Evans, 2003) asan operation offered as an interface that stands alone in the model, with no encapsulated state.(@Service是把spring容器中的bean进行实例化,也就是等同于new操作,只有实现类是可以进行new实例化的,而接口则不能,所以是加在实现类上的)
@ControllerAdvice:是一个增强的 Controller。使用这个 Controller ,可以实现三个方面的功能:全局异常处理,全局数据绑定,全局数据预处理
@ExceptionHandler(value=Exception.class):用来统一处理方法抛出的异常,在异常的处理方法上加上@ExceptionHandler,该方法会统一处理其他方法抛出的异常。
=
@Bean与@Configuration: @Configuration用于定义配置类,可替换xml配置文件,被注解的类内部包含有一个或多个被@Bean注解的方法,这些方法将会被AnnotationConfigApplicationContext或AnnotationConfigWebApplicationContext类进行扫描,并用于构建bean定义,初始化Spring容器。
@Bean与@Componet在使用上的区别?
想要将第三方库中的组件装配到你的应用中,在这种情况下,是没有办法在它的类上添加@Component注解的,因此就不能使用自动化装配的方案了,但是我们可以使用@Bean,当然也可以使用XML配置。
Controller是线程安全的吗?
在Springmvc中,所有的bean实例都是交给ioc容器去管理,默认Scope是单例模式,所以他是线程不安全的.
解决方法
1将创建的Controller的Scope设置成为多例prototype.但这样会消耗很多资源,并且这种方式只对于该Controller中非静态成员变量有用,如果是静态资源他还是会线程不安全.
2单例模式下需要线程安全的话必须使用ThreadLocal来封装变量ThreadLocal tl = new ThreadLocal<>(); 才能保证线程安全.
Spring 是如何解决并发访问的线程安全性问题的?
3 用户登录功能与分布式session设计
3-1 redis数据库中的key的名称该如何设计?
策略:
1)对key的命名进行约定
2)key的实现遵循模板模式(Template Pattern)
比如:采用 类的名臣+表的属性名称+表的属性值作为key()
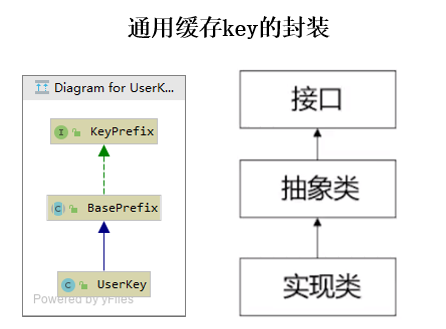
/*接口,对相关行为进行了封装包括1)获取key的超时时间 2)获取key的前缀*/
public interface KeyPrefix {
public int expireSeconds();
public String getPrefix();
}
// 遵循tempate pattern设计redis数据库key的名称,通过接口抽象公共的类的行为,抽象类通常是对设计对象的抽象。
// getName() 获取包名+类名; getSimpleName() 获取类名
public abstract class BasePrefix implements KeyPrefix{
private int expireSeconds;
private String prefix;
BasePrefix(int expireSeconds,String prefix){
this.expireSeconds = expireSeconds;
this.prefix = prefix;
}
// 这个构造函数用于定义永不过期的key,这里0表示key永远不过期
public BasePrefix(String prefix){
this(0,prefix);
}
@Override
public int expireSeconds() {
return 0;
}
@Override
public String getPrefix() {
String className = this.getClass().getSimpleName();
return className+":"+prefix;
}
}
public class UserKey extends BasePrefix {
UserKey(String prefix) {
super(prefix);
}
public static UserKey getById = new UserKey("id");
public static UserKey getByName = new UserKey("name");
}
总结:上述的设计方法,使得不同的模块的key可以通过实现不同的子类来获得,比如上面用户对象对应key的子类是UserKey,如果我们要另外定义一个订单对象,可以通过Orderkey来实现。
意图:定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。=
主要解决:一些方法通用,却在每一个子类都重新写了这一方法。
何时使用:有一些通用的方法。
如何解决:将这些通用算法抽象出来。
关键代码:在抽象类实现,其他步骤在子类实现。
应用实例: 1、在造房子的时候,地基、走线、水管都一样,只有在建筑的后期才有加壁橱加栅栏等差异。 2、西游记里面菩萨定好的 81 难,这就是一个顶层的逻辑骨架。 3、spring 中对 Hibernate 的支持,将一些已经定好的方法封装起来,比如开启事务、获取 Session、关闭 Session 等,程序员不重复写那些已经规范好的代码,直接丢一个实体就可以保存。
优点: 1、封装不变部分,扩展可变部分。 2、提取公共代码,便于维护。 3、行为由父类控制,子类实现。
缺点:每一个不同的实现都需要一个子类来实现,导致类的个数增加,使得系统更加庞大。
使用场景: 1、有多个子类共有的方法,且逻辑相同。 2、重要的、复杂的方法,可以考虑作为模板方法。
注意事项:为防止恶意操作,一般模板方法都加上 final 关键词。
关于redis的key的约定:redis的key的实例设置
3-2 用户密码进行两次MD5的意义以及实现方式?
具体加密流程
用户端加密: 明文密码+固定salt 进行第一次 MD5加密。
服务端加密: 首次MD5加密结果+随机salt 进行第二次MD5加密
salt作用:目前现有的方法能够通过MD5码直接查表得到加密的内容,加入salt相当于在明文上再加保险(虽然很弱)。
二次加密的动机
用户端加密(第一次):避免用户密码在网络上进行明文传输
服务端加密(第二次):防止数据库被盗窃造成的密码外传
message[ˈmesɪdʒ] digest[daɪˈdʒest,ˈdaɪdʒest] algorithm[ˈælgərɪðəm] utility [juːˈtɪləti]
MD5信息摘要算法(英语:MD5 Message-Digest Algorithm):一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。

3-3 项目的数据库如何设计?
用户表
CREATE TABLE `miaosha_user` (
`id` bigint(20) NOT NULL COMMENT '用户ID,手机号码',
`nickname` varchar(255) NOT NULL,
`password` varchar(32) DEFAULT NULL COMMENT 'MD5(MD5(pass明文+固定salt) + salt)',
`salt` varchar(10) DEFAULT NULL,
`head` varchar(128) DEFAULT NULL COMMENT '头像,云存储的ID',
`register_date` datetime DEFAULT NULL COMMENT '注册时间',
`last_login_date` datetime DEFAULT NULL COMMENT '上次登录时间',
`login_count` int(11) DEFAULT '0' COMMENT '登录次数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
3-4 项目中如何对从前端传递过来的vo(view object)进行参数校验?
view object:通常是view层即网页用于展示的信息都是存储在view object中,比如用户的登录就是将用户表单中的信息存储到view object中然后传递给服务端处理。
参数校验:从前端传递过来的信息未必是合法的信息,比如用户的登录信息(手机号/密码),对于这两类信息必须进行非空校验,手机号格式校验以及密码长度校验。
参数校验的方式:
1)最朴实的方法,在每个方法中写相同的代码对同一个对线的进行参数校验。
2)实际开发中通常利用JSR303参数校验+全局异常处理器来实现参数校验,这种方式能够避免大量冗余的代码,只需要对需要校验的对象添加注释即可。
3-5 项目业务的处理逻辑中,如果由于传入了异常参数(参数为空)或者,业务逻辑无法正常进行该如何处理?
需求:对于非正常的业务逻辑需要返回错误信息给网页前台。
处理策略:自定义异常以及全局的异常处理函数,当出现问题时,通过异常将错误信息给抛出,然后在全局异常处理函数中处理抛出的异常并返回错误信息给前台。
好处:通过JSR303参数校验+全局异常处理器使得写出的代码更加便于维护,不需要在业务代码中东一块,西一块处理这些代码。
3-6 分布式session该如何设置与处理?
需求:实际业务场景下,需要多台应用服务器面对用户的访问,此时用户的session信息维护非常关键。
策略1:各个应用服务器之间session信息进行同步,性能存在问题,实现比较复杂,实际中应用很少。
策略2:将session信息存储在redis数据库中,redis数据库实现信息的同步,从而多台应用服务器可以获取到session信息。
关于用户的session信息在redis数据库中的存活时间更新问题?‘
策略1:用户每次访问要更新数据库中对应session信息的存活时间(每次访问都更新存活时间对redis服务器压力太大了)
策略2:定时更新存活时间。
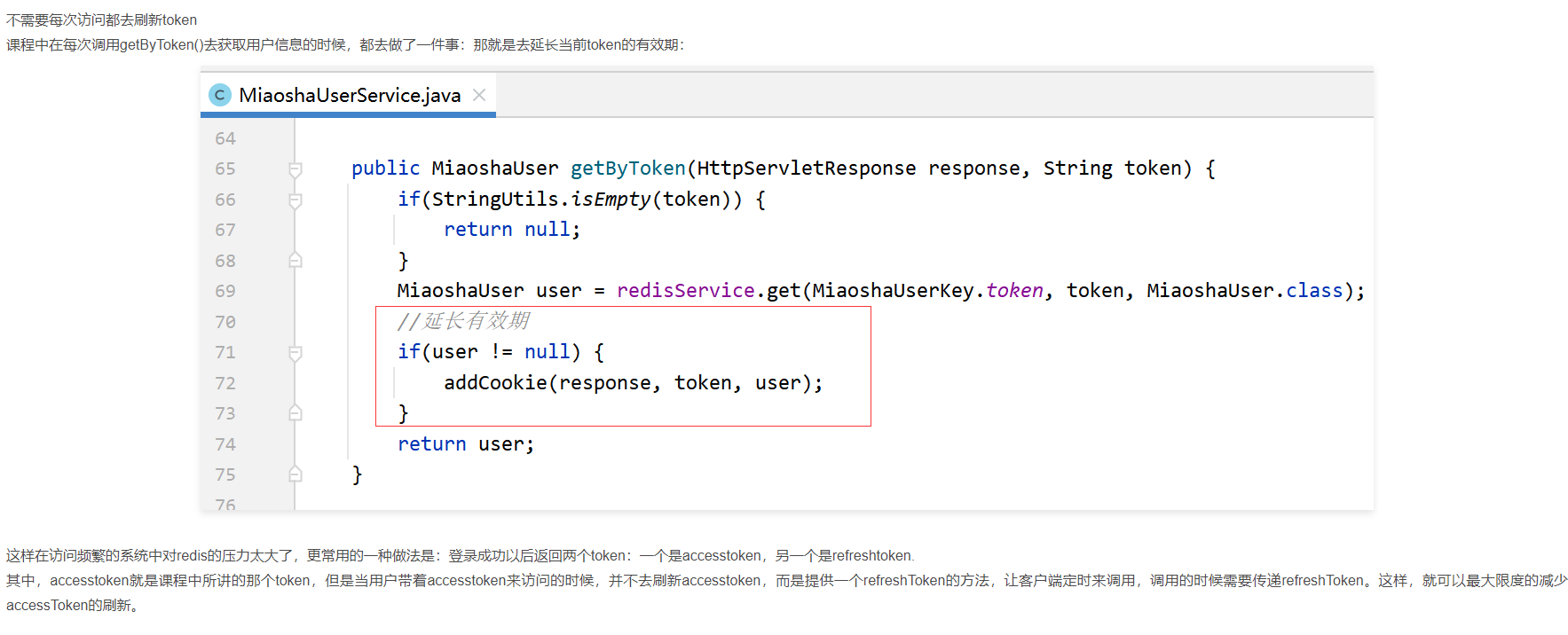
3-7 一些信息比如用户信息需要在很多controller中被使用,如果同一对用户信息进行校验?
实现方式:自定义用户参数解析器HandlerMethodArgumentResolver并addArgumentResolvers中
- 在参数解析器内通过对前台的token进行校验并返回用户对象到controller中,这样controller中的代码会更加简洁。
public interface HandlerMethodArgumentResolver {
boolean supportsParameter(MethodParameter parameter);
@Nullable
Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception;
}
3-8 如何利用token获取用户的session信息(重要)
用户登录流程:
1)利用post的方式提交用户账号和密码
2)客户端对密码采用固定的salt进行MDK5加密
3)服务端接受到账户名与第一次加密后的密码
4)检验账户名,并从数据库中获取第二次加密后的密码以及所使用的salt
5) 检验密码:利用数据库的salt结合客户端传递过来的密码获取第二次加密后的密码,并于数据库中密码比对
6)用户名与密码均正确则为当前登录用户生成UUID作为token加入到http响应的信息中,并生成用户的session信息放入到缓存中
用户后续:
每次用户访问都需携带分配的token信息,服务端或根据token信息从缓存中获取用户的session信息
3-9 底层原理
问题:对登陆的用户对象的进行校验的参数解析器是如何工作的?
1) SpringMVC初始化时,RequestMappingHandlerAdapter类会把一些默认的参数解析器添加到argumentResolvers中。当SpringMVC接收到请求后首先根据url查找对应的HandlerMethod。
2)遍历HandlerMethod的MethodParameter数组
3)根据MethodParameter的类型来查找确认使用哪个HandlerMethodArgumentResolver,遍历所有的argumentResolvers的supportsParameter(MethodParameter parameter)方法。。如果返回true,则表示查找成功,当前MethodParameter,使用该HandlerMethodArgumentResolver。这里确认大多都是根据参数的注解已经参数的Type来确认。
4)解析参数,从request中解析出MethodParameter对应的参数,这里解析出来的结果都是String类型。
5) 转换参数,把对应String转换成具体方法所需要的类型,这里就包括了基本类型、对象、List、Set、Map。
4 抢购功能实现
数据库设计
订单表 ====> 秒杀订单表
商品表 ====> 秒杀商品表
页面设计
1)秒杀商品显示页面
2)秒杀商品详情页面
3)
实际开发中商品的id如何设置?
通常不会采用自增的id,而是采用snowflake算法。
4-0 秒杀系统的商品表该如何设计?
用于秒杀的商品表应该单独建立一个表,这个表中存储与秒杀相关的信息。
比如下面的秒杀商品表中就包含有秒杀价格,秒杀商品的数量,开始秒杀时间,结束秒杀时间。

4-1 秒杀的开始,进行,结束,客户端与后台应该承担哪些工作?
服务端:
提供秒杀商品的信息,特别是秒杀开始的时间信息,本项目中后台还返回了当前商品的状态(未开始/正在进行/已结束)以及秒杀开始剩余时间(具体值/0/-1)。
客户端:倒计时的操作必须在客户端完成。
客户端页面需要根据后台传递过来的时间信息,在页面上完成秒杀的倒计时
4-2 秒杀的订单该如何设计?
订单至少要包含以下信息:
private Long id; // 订单id
private Long userId; // 用户id
private Long goodsId; // 商品id
private Long deliveryAddrId; // 发货地址
private String goodsName; // 商品名称
private Integer goodsCount; // 商品数量
private Double goodsPrice; // 商品价格
private Integer orderChannel;
private Integer status;
private Date createDate; // 订单创建日期
private Date payDate; // 订单支付日期
5 系统测试
5-0 系统测试概述
[Jmeter官网](https://jmeter.apache.org/)
1)Jmeter的命令行使用使用
2)自定义变量模拟多用户
3)Redis的压测工具
测试目标(常用的指标介绍)
响应时间(RT): 响应时间是指系统对请求作出响应的时间
吞吐量(Throughput):吞吐量是指系统在单位时间内处理请求的数量
并发用户数: 系统可以同时承载的正常使用系统功能的用户的数量
QPS(Query Per Second): 每秒查询率,每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,每秒的响应请求数
TPS(Transactions Per Second):事务数/秒
注意点:QPS数据通常结合用户并发数才有意义
严谨说法:并发用户数为多少的时候,QPS的值是多少?
5-1 Jmeter不带参数的页面请求访问
Jmeter压力测试
商品列表测试页面:http://localhost:8080/goods/to_list
配置流程:
step1:配置请求默认的IP与端口号(IP地址+端口)
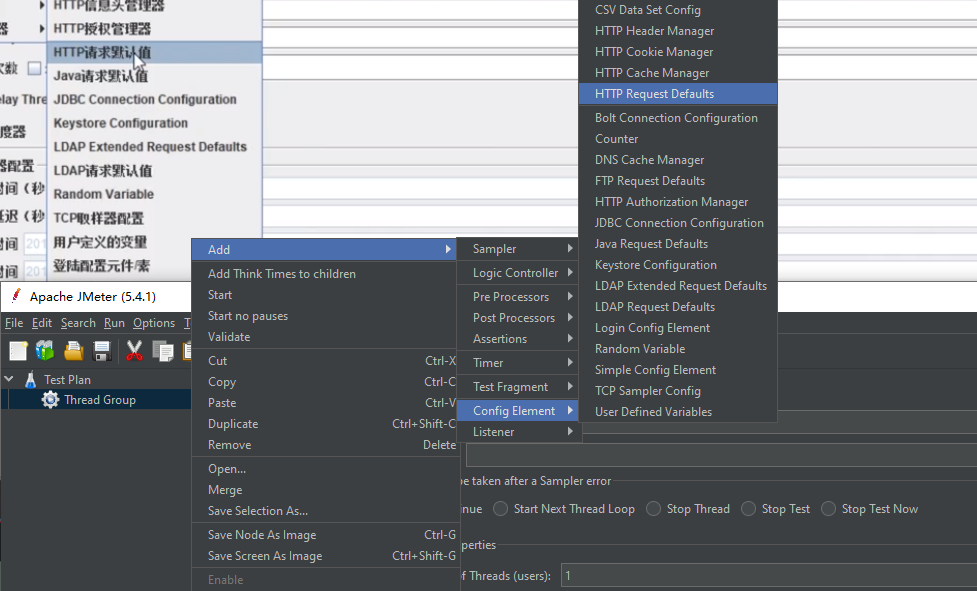
step2:配置网页请求的具体路径(/goods/to_list)
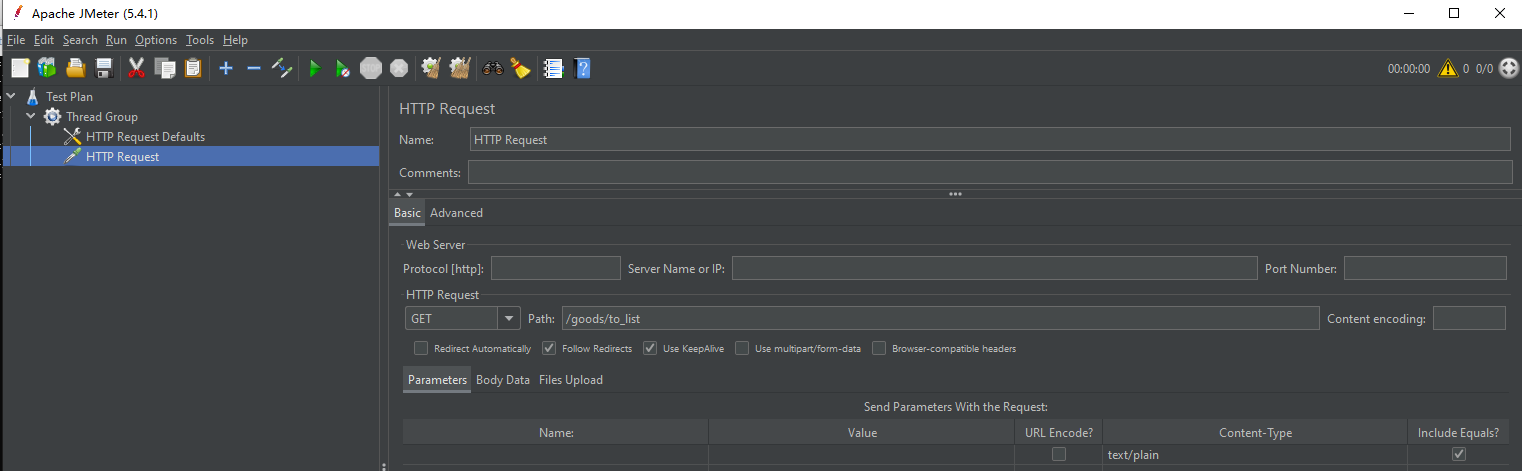
step3:配置结果的展示项(Summary Report)
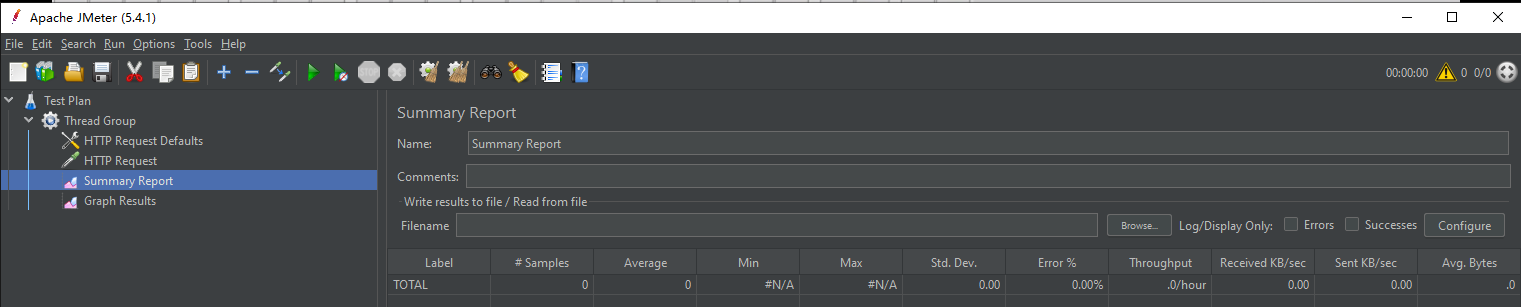
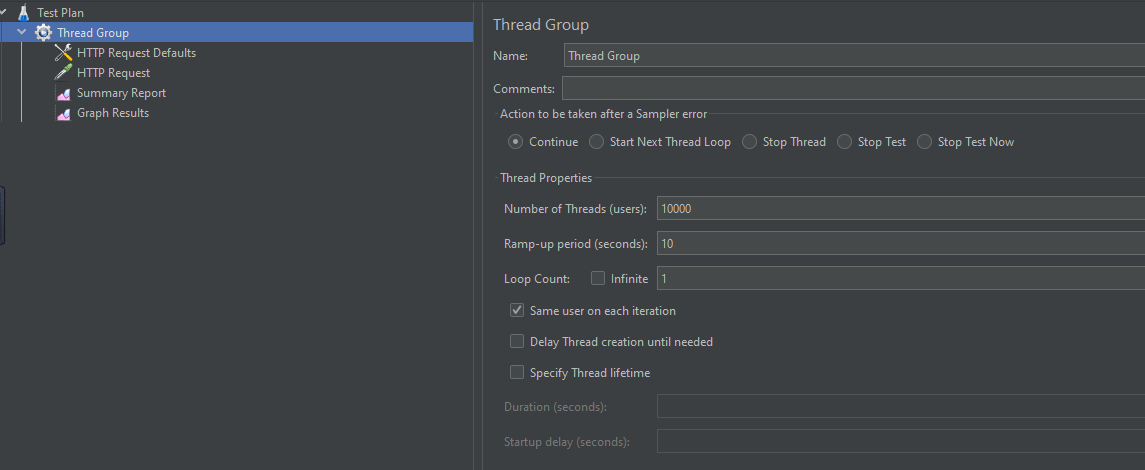
step4:设置用于压力测试的线程总数以及时间跨度
5-2 Jmeter带参数的页面请求访问
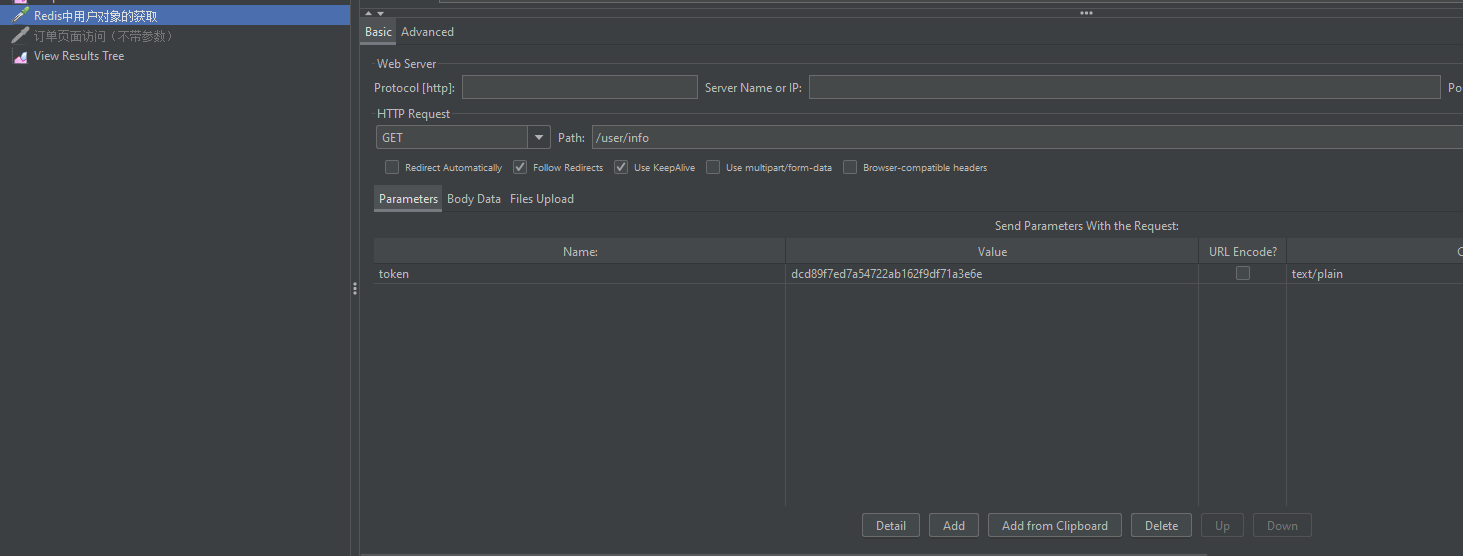
目标:测试redis缓存中用户对象的获取速度
方法:需要在http的header中用token参数或者通过cookie将token发送给服务端
下图中通过设置parameter将token信息传递过去从而获取用户对象
5-3 Linux中如何进行jmeter压测

linux查看CPU信息
cat /proc/cpuinfo | grep processor
5-4 redis进行压测
更多参考:redis的性能监控指标

-c: 并发的数目
-n: 请求的数目
-h: ip地址
-p: 端口号

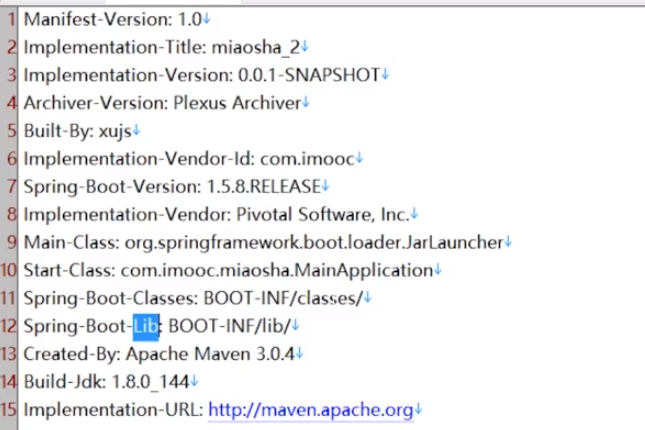
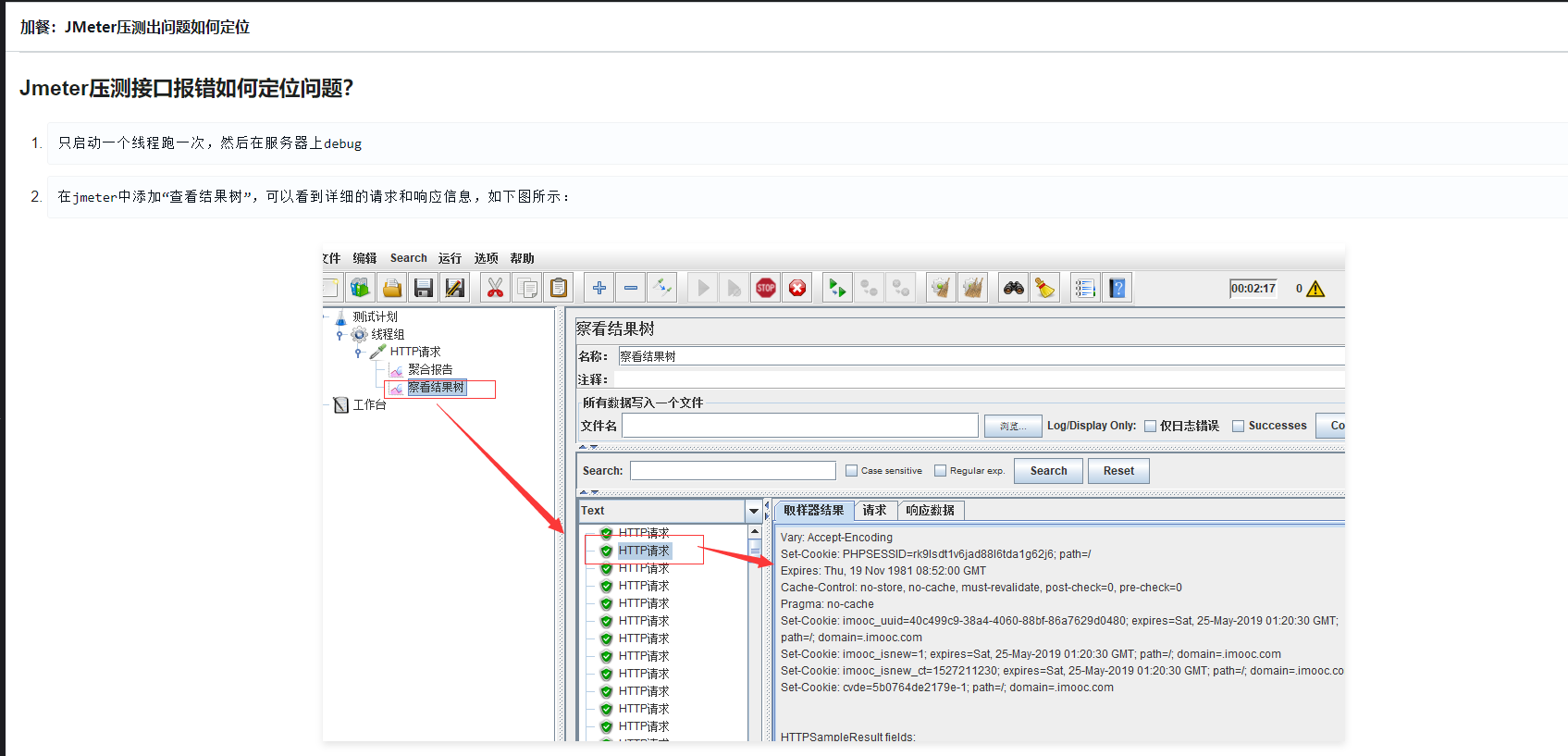
5-5 Jmeter压测出问题该如何定位?
5-6 系统并发的瓶颈问题
系统的并发瓶颈通常在于数据库,只要数据库能够抗的住,对于web应用程序服务器的横向扩展是较为容易的,但是数据库的横向扩展即分库,分表却较为麻烦,需要考虑很多的问题,特别是分库分表的系统的代码设计与不是分库分表的设计是完全不一样的。
5-7 该项目压力测试的三个页面介绍
1)秒杀商品列表页面
2)用户对象获取(redis)
3)商品详情页面
6 系统性能提高策略-页面级优化技术
6-1 页面优化主要策略:
| 策略 | 动机 | 说明 | 所属层次 |
|---|---|---|---|
| 页面缓存+URL缓存+对象缓存 | 系统访问的瓶颈在数据库,缓存的目的是减少对数据库的访问 | 页面(URL缓存):将渲染好的html源码放在redis缓存中,不用每次都获取数据渲染页面,页面缓存的 | 应用服务器缓存 |
| 页面静态化(也叫前后端分离) | 只向服务端请求数据,客户端不重复下载页面数据 | 让页面都是纯粹的html,然后ajax向服务端请求数据到客户端渲染页面 | 客户端缓存 |
| 静态资源的优化 | |||
| CDN优化 |
前后端分离本质:客户端通过ajax提交和请求页面的数据,客户端不需要频繁的下载整个html静态源码、
6-2 页面缓存的定义,该如何利用?
页面缓存定义:应用服务器在接受客户端页面请求时,先从缓存中查找是否存在已经渲染好的页面,找到的话则直接返回,没有找到才会将页面返回。
页面缓存相关的基本步骤:
1)取缓存
2)手动渲染模板
3)结果输出
页面(URL)缓存的特点:
- 将用户请求的路径作为key,将渲染好的页面(html文本)存储在redis数据库中
- 页面缓存的有效期通常比较短,其有效期根据具体的业务确定,比如说允许用户看到30s之前的页面,那么则可以设置页面有效期为30s
页面缓存的目标:
- 防止峰值流量过大造成服务器宕机,需要严格把握缓存的有效期
该抢购系统的页面缓存特点:
1)对秒杀商品的列表页面进行了页面缓存,实际场景下商品列表可能有很多页,只需要缓存几页就行
2)对商品的详情信息进行了URL缓存。(存在的问题:缓存的页面中无法利用用户的session信息)
6-3 对象缓存的定义,该如何使用?
本项目中需要缓存的对象?
1)抢购系统的登录用户对象
2)用户秒杀成功后,生成的订单对象的缓存
对象缓存与url(页面缓存)的区别?
对象缓存在相关记录进行更新时,需要考虑缓存一致性问题,如果相关记录修改,那么对应的缓存信息也需要修改,这是对象缓存与url缓存最大的区别。URL缓存通常有效期非常短,不需要进行缓存信息的维护,直接放弃旧的缓存信息,重新生成即可。
此外对象缓存可以看作细粒度的页面缓存,因为一个页面缓存中包含大量对象。
缓存的关联问题?
- 每个函数只能调用自己的dao以及别人的service,不能调用dao,其中一个重要原因就是别人的service可能对数据访问做了额外处理,比如缓存的控制。
6-4 页面(url)缓存与对象缓存压测结果
6-4 商品详情页面静态化(前后端分离)
目的:利用客户端的浏览器缓存,将用户页面缓存到本地,页面中数据从服务端获取
方法:AngularJS,Vue.js
优点:客户端无需每次向服务端请求页面,只需要更新数据即可
具体流程:
商品详情页静态化流程: 客户端请求商品详情页 => 服务端返回静态页面(包含有ajax数据请求)=> 客户端解析也面的过程中采用ajax向服务端请求数据 => 服务端返回页面所需的数据 => 客户端获取数据渲染页面并显示
注意点:服务端要将静态页面与数据分别传输
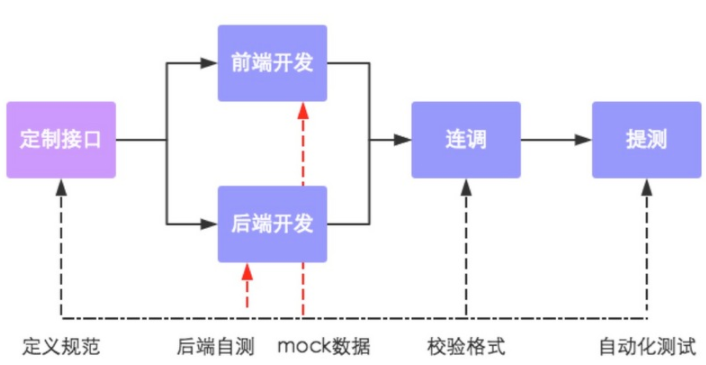
- 前后端分离也有助于前后端工程师合作开发,只需要约定好数据交互接口即可
ajax的基本介绍
ajax的全称是AsynchronousJavascript+XML。
ajax的基本流程可以概括为:页面上js脚本实例化一个XMLHttpRequest对象,设置好服务器端的url、必要的查询参数、回调函数之后,向服务器发出请求,服务器在处理请求之后将处理结果返回给页面,触发事先绑定的回调函数。这样,页面脚本如果想要改变一个区域的内容,只需要通过ajax向服务器获取与该区域有关的少量数据,在回调函数中将该区域的内容替换掉即可,不需要刷新整个页面。
XMLHttpRequest在发送请求的时候,有两种方式:同步与异步。同步方式是请求发出后,一直到收到服务器返回的数据为止,浏览器进程被阻塞,页面上什么事也做不了。而异步方式则不会阻塞浏览器进程,在服务端返回数据并触发回调函数之前,用户依然可以在该页面上进行其他操作。ajax的核心是异步方式,而同步方式只有在极其特殊的情况下才会被用到。
在ajax刚出现的时候,绝大多数应用都是采用XML格式,也有少数使用纯文本的。但是XML格式有一个缺点,就是文档构造复杂,需要传输比较多的字节数。在这种情况下,JSON的轻便性逐渐得到重视,后来替代XML成为ajax最主要的数据传输格式。
Node.js是Ryan Dahl在2009年发布的、主要用于服务器端的Javascript运行环境
6-4-1 问题:为什么秒杀按钮采用post方式提交(get与post区别)?
原因:点击秒杀按钮会对服务端数据产生影响、
幂等性:就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用
- get方式具有幂等性,通常用于从服务端获取数据,调用多次其产生的结果是一致的,不会对服务端数据产生影响。
- Post不是幂等的,会对服务端数据产生影响,因此如果数据的提交会引发服务端数据的修改应该使用post。
注意:get/post方式传递参数的多少是浏览器限定的,其参数多少并没有在http协议中进行约定。
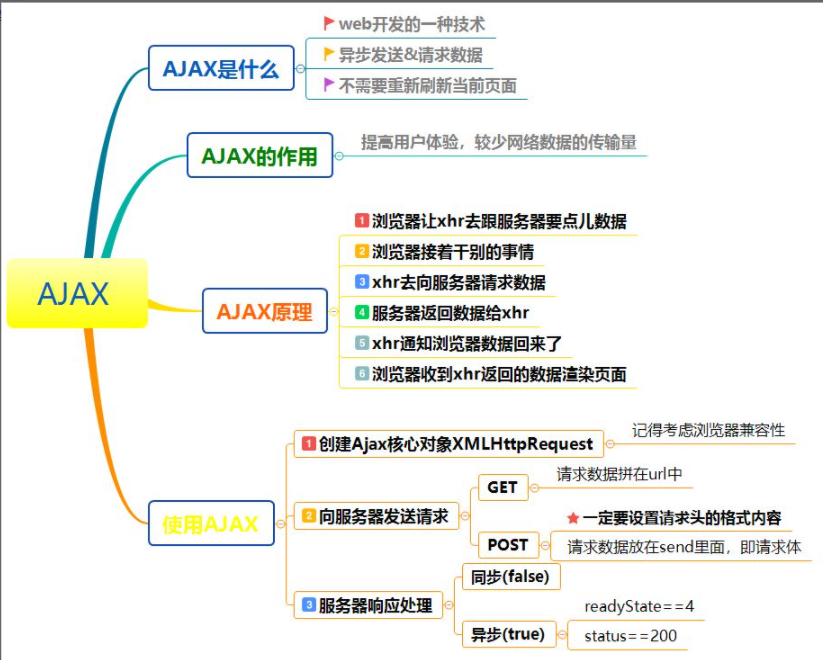
6-4-2 问题:客户端缓与304代码的关系?
- 客户端在向服务端请求页面的时候,在头部中包含了参数(If-modified-Since:时间信息),服务端收到参数后会检查页面是否发生变化,如果没有发生变化则会返回304
- 304状态并非浏览器缓存利用的最理想的状态,仅仅利用了部分缓存,304状态下客户端为了确认缓存是否过期依旧会请求一次服务端,我们希望只有缓存没有过期,客户端不会去请求服务端。
服务端提供缓存过期时间来高效利用缓存的策略:
让服务端第一次返回页面的时候,设置页面的有效期为一定时间,客户端根据有效期判断当前页面是否已经失效,没有失效则不会去请求
6-4-3 html头部与客户端缓存相关参数
| 参数(key) | value | 协议版本 | 动机 |
|---|---|---|---|
| Pragma | http1.0 | ||
| Expire | 格林乔治时间 | http1.1 | |
| Cache-Control | 时间(s) | http1.1 | 相比Expire参数,另外考虑了服务端与客户端可能出现的时间不一致问题 |
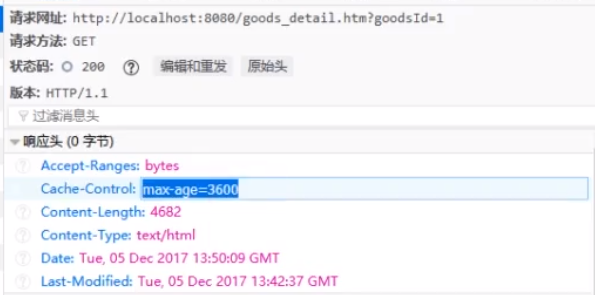
- 上图中Cache-Control:max-age=3600表示返回的页面有效期为3600s
6-7 订单详情页面前后端分离(点击立即秒杀按钮后)

前后端分离基本思路:
点击按钮POST商品id信息=>服务端返回信息 => 秒杀成功,则通过ajax请求订单详情页面的静态html => 静态html中通过ajax获取订单数据
点击按钮后的ajax异步调用流程:
function doMiaosha(){
$.ajax({
url:"/miaosha/do_miaosha",
type:"POST",
data:{
goodsId:$("#goodsId").val()
},
success:function(data){
if(data.code == 0){
// 服务端返回的对象信息的code属性为0表示秒杀成功,则去请求订单的静态页面
window.location.href="/order_detail.htm?orderId="+data.data.id;
// getMiaoshaResult($("#goodsId").val());
}else{
layer.msg(data.msg);
}
},
error:function(){
layer.msg("客户端请求有误");
}
});
}
linux的vm.overcommit_memory的内存分配参数详解
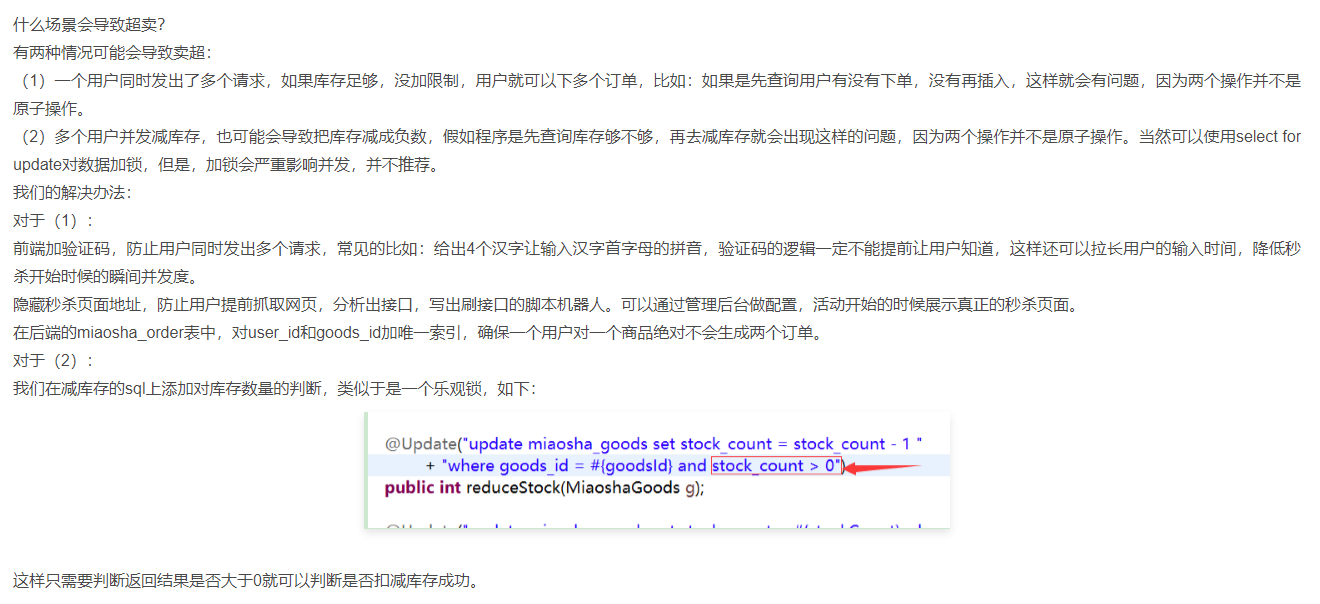
6-9 秒杀系统中的超卖问题该如何解决?
场景:秒杀活动中,系统会提供一个秒杀商品列表供用户去秒杀商品,要求每个用户对于每种类型的商品只能秒杀到一个?
卖超问题的细化
问题1:当前某种型号显卡数量为1,多个用户并发秒杀显卡并下订单造成数据库中显卡库存数量为负该如何处理?
问题2:某个用户通过秒杀软件,发出某种型号显卡的多个秒杀请求,如何保证该用户最多只能秒杀到1张显卡(不会产生同种商品的多张订单)?
上面问题产生的原因在于下面的代码在多线程环境的下的安全问题:
// 当库存小于0,返回秒杀失败的信息
if(stock <= 0){
return Result.error(CodeMsg.MIAO_SHA_OVER); // 货物销售完毕,秒杀活动已经结束
}
// 判断是否已经秒杀到
MiaoshaOrder order = orderService.getMiaoshaOrderByUserIdGoodsId(user.getId(),goodsId);
if(order != null){
return Result.error(CodeMsg.REPEATE_MIAOSHA);
}
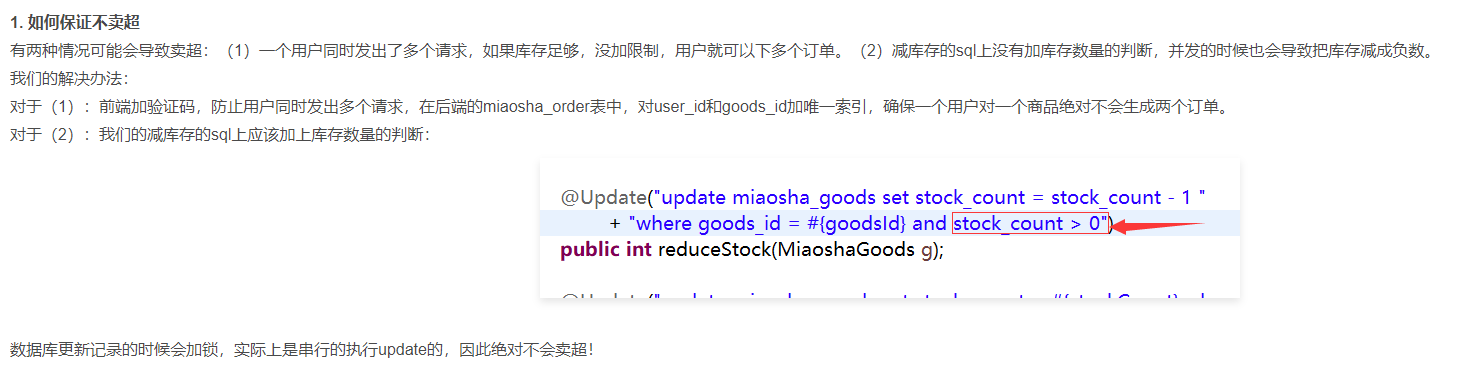
问题1的解决策略
方式1:利用MySQL写锁的排斥性
- 对库存的数量进行检查,在执行update操作的时候,这一行是一个事务(默认加了排他锁)。这一行不能被任何其他线程修改和读写
@Update("update miaosha_goods set stock_count = stock_count - 1 where goods_id = #{goodsId} and stock_count > 0")
public int reduceStock(MiaoshaGoods g);
问题2的解决策略
- 通过对数据库建立唯一索引确保单个用户同种类型的商品不会产生多个订单
- 本项目中通过对秒杀订单表中的用户id与商品id建立唯一索引去确保该用户最多只能秒杀到某种类型商品的1个商品
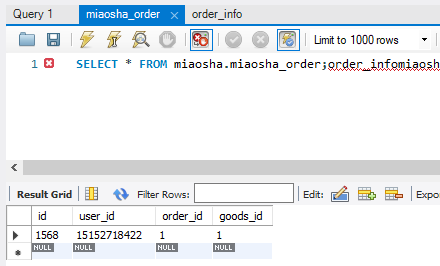
CREATE UNIQUE INDEX user_good_index ON miaosha_order(user_id,goods_id); // 对用户id列与商品列建立唯一复合索引
总结:这里超卖问题的解决主要依赖于数据库。
6-10 静态资源的常用优化策略
常见的策略:
- webpack工具
1)js/css文件压缩
2)服务器将多个css/js组合变为一个请求,减少连接数(服务器提供功能)
3)CDN(content delivery Network)优化(本质上也是缓存),就近访问,解决网络拥堵,提供网络效率。
注意:上述的策略通常与代码没啥关系,通常买别人的服务。
7 服务级高并发秒杀优化:接口的优化
1)redis预减库存减少数据库的访问
2)应用服务器通过内存标记减少redis访问
3)请求先入队缓存,异步下单,增强用户体验
4)RabbitMQ安装与springboot集成
5)Nginx的水平扩展
6)压测
分库分表,现有的分库分表的中间件包括shardingsphere 与 mycat
思路:减少数据库的访问
1)系统初始化,把商品库存数量加载到redis
2) 收到请求,redis预减库存,库存不足,直接返回,否则进入3)
预减库存的好处:提前让多余的请求返回,减少数据库的压力
3)请求入队,立即返回排队中(12306买票就需要排队)
4)请求出队,生成订单,减少库存
5)客户端轮询是否秒杀成功
centos中安装rabbitMQ
yum install ncurses-devel
// 安装erlang
// 安装rabbitMQ
netstat -nap | grep 5672 // 查看是否启动成功
export PATH=$PATH:/usr/local/erlang24.0/bin
export PATH=$PATH:/usr/local/rabbitmq/sbin
source /etc/profile
rabbitmq-server -detached
7-1 springboot集成RabbitMQ的流程
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制.
1)添加依赖
2)创建消息接受者
3)创建消息发送者
类似的消息队列中间件
ActiveMQ: Apache开源的消息队列
RocketMQ: 阿里开源的消息队列
消息队列选型
1)如果消息队列不是将要构建系统的重点,对消息队列功能和性能没有很高的要求,只需要一个快速上手易于维护的消息队列,建议使用 RabbitMQ。
2)如果系统使用消息队列主要场景是处理在线业务,比如在交易系统中用消息队列传递订单,需要低延迟和高稳定性,建议使用 RocketMQ。
3)如果需要处理海量的消息,像收集日志、监控信息或是埋点这类数据,或是你的应用场景大量使用了大数据、流计算相关的开源产品,那 Kafka 是最适合的消息队列。
每一个消息队列都有自己的优劣势,需要根据现有系统的情况,选择最适合的消息队列,更多细节和原理性的东西,还需在实践中见真知!
7-2 如何使用rabbitMQ对秒杀接口进行优化
同步下单的秒杀流程
1)用户点击秒杀按钮,先对用户对象进行校验
2)检查秒杀商品是否还有库存,则返回秒杀失败信息(访问数据库获取当前商品的库存信息)
3)检查该用户是否已经秒杀过这个商品,如果秒杀过则返回不能重复秒杀信息(秒杀场景下,每个用户只能秒杀一件商品)(查询该用户的订单信息,通过将用户的订单西信息放入到缓存中减少对数据库的访问)
4)生成待支付的订单并减去商品库存(访问数据库减少商品库存,访问数据库插入新的秒杀订单记录)
5)返回秒杀成功的信息
============================================================================================================
注意点:实际场景下可能需要更多的数据库访问以及业务逻辑,比如说对商品地址信息的判断等
总结:
- 秒杀过程所对应的业务代码包含多次对数据库的访问
- 上述采用的是同步下单的模式
优化思路
1)系统初始化,把商品库存数量加载到redis
2) 收到请求,redis预减库存,库存不足,直接返回,否则进入3)
预减库存的好处:提前让多余的请求返回,减少数据库的压力
3)请求入队,立即返回排队中(12306买票就需要排队)
4)请求出队,生成订单,减少库存
5)客户端轮询是否秒杀成功
7-3 商品数量预加载该如何实现?
策略:通过实现InitializingBean接口来进行商品预加载
spring初始化bean有两种方式:
第一:实现InitializingBean接口,继而实现afterPropertiesSet的方法
第二:反射原理,配置文件使用init-method标签直接注入bean
InitializingBean接口为bean提供了初始化方法的方式,它只包括afterPropertiesSet方法,凡是继承该接口的类,在初始化bean的时候都会执行该方法。
7-4 使用本地标识减少redis请求?
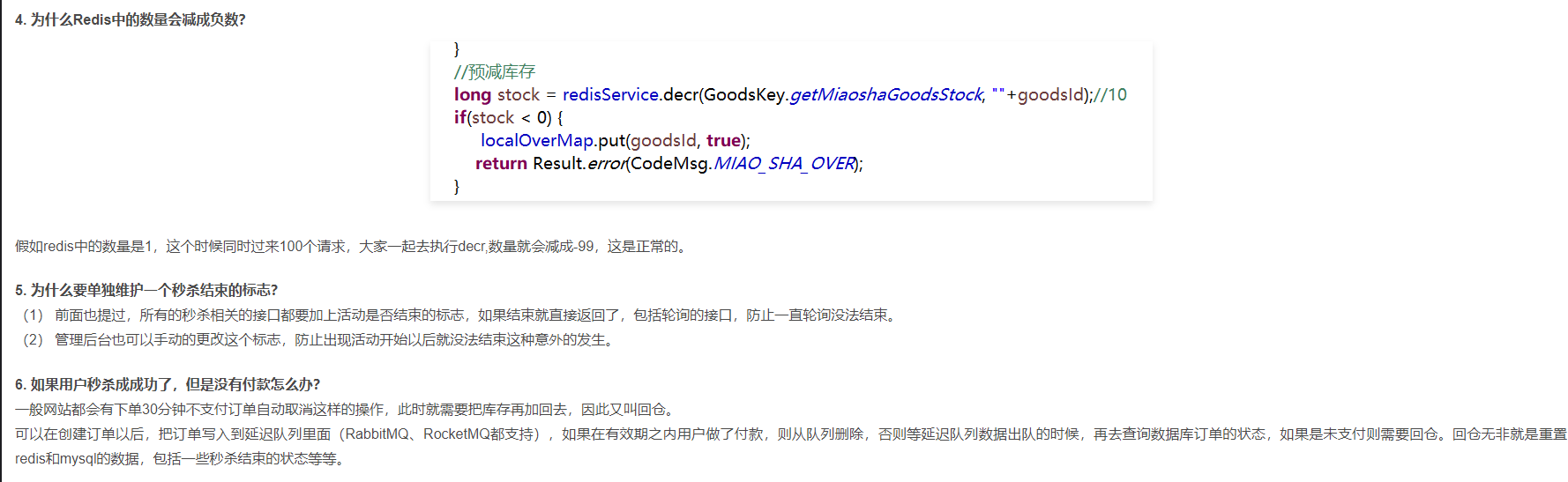
问题位置:项目中将所有商品的库存数量在秒杀活动开始前加载到redis缓存中,用户通过秒杀接口秒杀商品时采用库存预减的策略,当redis中商品的库存数量为负数的时候,则后续的请求直接返回秒杀失败。这个过程中如何在商品库存数量为负的时候,避免对redis的访问?
策略:项目启动时创建一个hashmap,key是商品id,value是boolean变量用于标记商品是否已经卖完。
-
访问redis缓存前则先访问内存标记,从而避免冗余的redis数据库访问
-
当redis中缓存的商品数量<=0的时候,则设置对应内存标记
7-5 rabbitMQ融合后的压测
- 需要好硬件服务器进行测试
7-6 使用Ngnix进行横向扩展
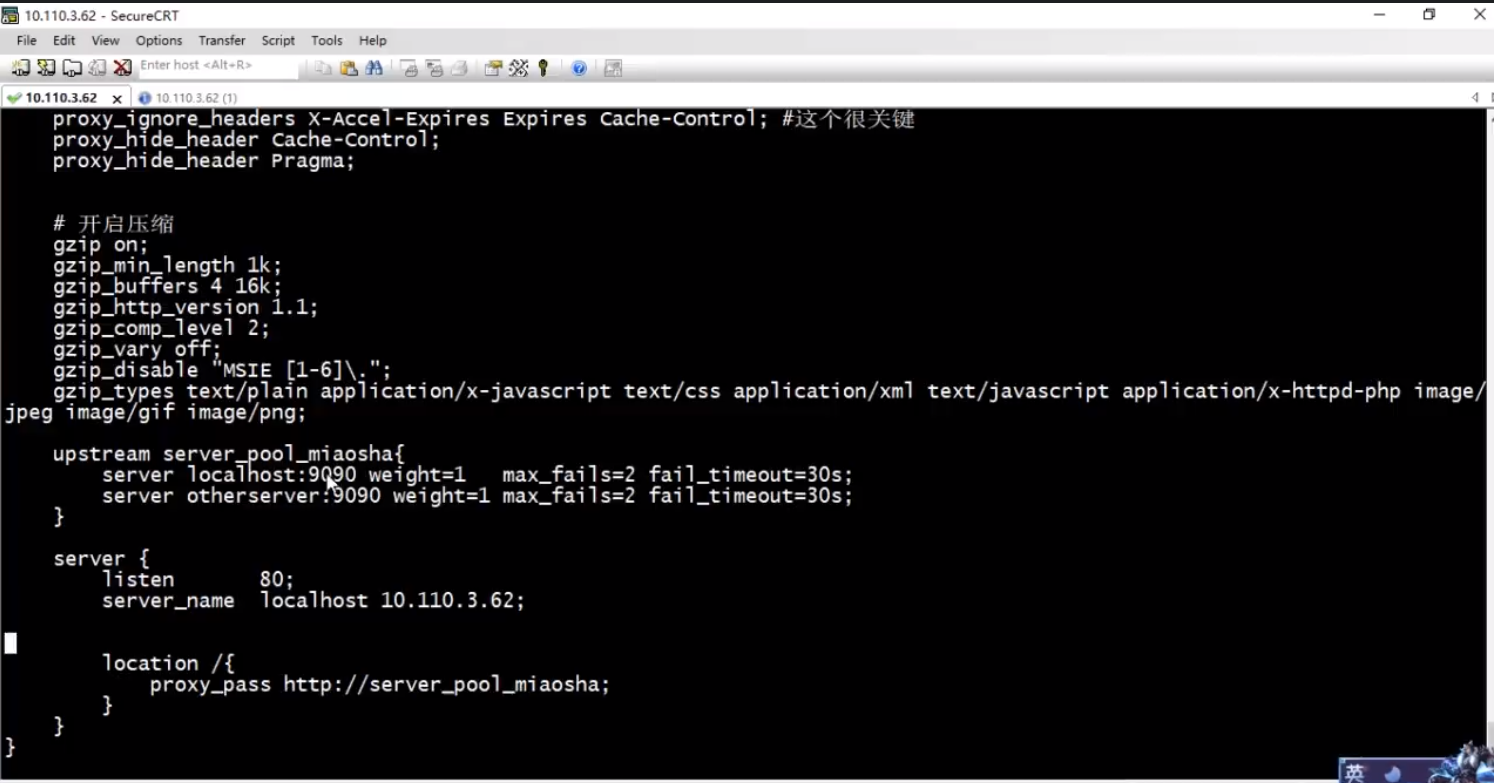
1)ngnix具有探活机制,自动探测后端服务器是否存活。
2)ngnix也可以配置缓存
-LVS(流量特别大):linux内核集合
带有LVS的架构
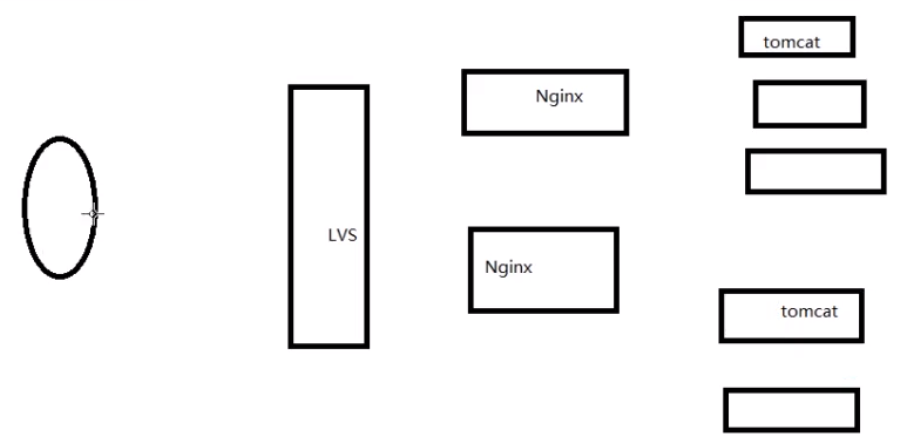
百万流量级别:浏览器一般直接访问nginx服务器
更高的流量级别:需要LVS结合多个nginx服务器
7-7 一些问题的补充

8 秒杀系统安全方面的问题
安全方面的策略:
1)秒杀接口地址隐藏()
2)数学公式验证码
---复杂的验证码防止机器人工具抢购
---复杂验证码起到限流的作用
3)接口限流访问
--限制每个用户访问接口的次数
- 前端(客户端)很难做到安全性,html是明文的。
唯一ID生成算法剖析
8-1 秒杀接口地址隐藏该如何实现?
思路:秒杀开始前,先去请求接口获取秒杀地址
1) 接口改造,带上PathVariable参数
2) 添加生成地址的接口
3) 秒杀收到请求,先验证PathVariable
8-2 隐藏秒杀接口地址还有其他哪些方法(为什么隐藏?)

8-3 如何设置图形验证码限制用于的秒杀流量?
思路:点击秒杀按钮之前,先输入用户码,分散用户的请求
1)添加生成验证码的接口
2)获取秒杀路径的时候,验证验证码
3)ScriptEngine使用(通过javascript的引擎来计算数学公式并将结果存入到redis数据库中)
验证码为什么能够限制访问?
1)对于正常用户,每个人计算验证码的时间有长有短,一定程度上能够分散访问请求
2)对于非正常用户来说,足够复杂的验证码能够有效的防止机器人
8-4 接口防刷如何设计(拦截器)?
目的:对接口进行限流
将用户访问的次数记录到缓存中并设置有效期(比如1分钟)。
粗糙实现
// 接口防刷限制,通过redis实现,5s内限制访问5次
String uri = request.getRequestURI();
String key = uri+"_"+user.getId();
Integer count = redisService.get(AccessKey.access,key,Integer.class);
if(count == null){
redisService.set(AccessKey.access,key,1);
}else if(count < 5){ // 当前时间窗口内,访问次数小于5次
redisService.incr(AccessKey.access,key);
}else{ // 当前窗口内,访问过于过于频繁,返回错误信息
return Result.error(CodeMsg.ACCESS_LIMIT_REACHED);
}
8-5 项目中接口防刷功能如何实现?
step1:自定义@AccessLimit(seconds=5,maxCount=5,needLogin=true)注解
step2:自定义拦截器,对有自定义注解的方法进行拦截。
step3:在拦截器内部
1)根据token获取用户对象并将用户对象存放到ThreadLocalMap中,后续的参数校验需要用到
2)校验属性参数,如果该接口必须登录后才能访问,则必须先进行判断是否登录,否则直接返回
3)通过redis缓存维护当前时间窗口内用户的访问次数,如果访问次数超过阈值,则在访问接口前直接返回。
8-6 常用的限流算法有哪些?

8-7 拦截器的实现原理,AOP的概念辨析(待补充)?
概念辨析:
- AOP是面向切面编程(Aspect-Oriented Programming,是一种编程思想
实现方式:
- AOP的实现有两种方式,一种是通过回调函数,另一种是代理。
9 服务端优化策略
9-0 关于tomcat的一些说明
- 单个tomcat运行多个web服务场景已经正在逐渐消失
内置的Tomcat和打包成War然后部署到独立的Tomcat有什么区别呢?
主要还是方便简单。独立的Tomcat可以部署多个War,这是优势。但是现在很少这样用了。因为现在主要的部署环境是微服务和云部署,Spring Boot就是面向微服务架构和云考虑的。在云上部署,往往是一个虚拟机一个Web应用,打成一个可执行Jar最方便。
如果用Docker部署,找一个JVM Image,然后加上自己的Jar就可以了。否则就需要用一个Tomcat Image加上你的Web应用。所以,不管是一个云虚拟主机,还是一个Dock容器,里面只会跑一个Web应用,没有一个Tomcat里部署多个Web应用的场景需求。
Tomcat对标Undertow
9-1 Tomcat的优化策略
- 基于tomcat 8.5.20
1)内存优化
2)并发优化
3)APR优化
9-1-1 tomcat如何进行内存优化?
查看bin目录下的Catalina.sh文件内容
#!/bin/sh
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# -----------------------------------------------------------------------------
# Control Script for the CATALINA Server
#
# Environment Variable Prerequisites
#
# Do not set the variables in this script. Instead put them into a script
# setenv.sh in CATALINA_BASE/bin to keep your customizations separate.
#
# CATALINA_HOME May point at your Catalina "build" directory.
#
# CATALINA_BASE (Optional) Base directory for resolving dynamic portions
# of a Catalina installation. If not present, resolves to
# the same directory that CATALINA_HOME points to.
#
# CATALINA_OUT (Optional) Full path to a file where stdout and stderr
# will be redirected.
# Default is $CATALINA_BASE/logs/catalina.out
#
# CATALINA_OPTS (Optional) Java runtime options used when the "start",
# "run" or "debug" command is executed.
# Include here and not in JAVA_OPTS all options, that should
# only be used by Tomcat itself, not by the stop process,
# the version command etc.
# Examples are heap size, GC logging, JMX ports etc.
#
# CATALINA_TMPDIR (Optional) Directory path location of temporary directory
# the JVM should use (java.io.tmpdir). Defaults to
# $CATALINA_BASE/temp.
#
# JAVA_HOME Must point at your Java Development Kit installation.
# Required to run the with the "debug" argument.
#
# JRE_HOME Must point at your Java Runtime installation.
# Defaults to JAVA_HOME if empty. If JRE_HOME and JAVA_HOME
# are both set, JRE_HOME is used.
#
# JAVA_OPTS (Optional) Java runtime options used when any command
# is executed.
# Include here and not in CATALINA_OPTS all options, that
# should be used by Tomcat and also by the stop process,
# the version command etc.
# Most options should go into CATALINA_OPTS.
#
# JPDA_TRANSPORT (Optional) JPDA transport used when the "jpda start"
# command is executed. The default is "dt_socket".
#
# JPDA_ADDRESS (Optional) Java runtime options used when the "jpda start"
# command is executed. The default is localhost:8000.
#
# JPDA_SUSPEND (Optional) Java runtime options used when the "jpda start"
# command is executed. Specifies whether JVM should suspend
# execution immediately after startup. Default is "n".
#
# JPDA_OPTS (Optional) Java runtime options used when the "jpda start"
# command is executed. If used, JPDA_TRANSPORT, JPDA_ADDRESS,
# and JPDA_SUSPEND are ignored. Thus, all required jpda
# options MUST be specified. The default is:
#
# -agentlib:jdwp=transport=$JPDA_TRANSPORT,
# address=$JPDA_ADDRESS,server=y,suspend=$JPDA_SUSPEND
#
# JSSE_OPTS (Optional) Java runtime options used to control the TLS
# implementation when JSSE is used. Default is:
# "-Djdk.tls.ephemeralDHKeySize=2048"
#
# CATALINA_PID (Optional) Path of the file which should contains the pid
# of the catalina startup java process, when start (fork) is
# used
#
# LOGGING_CONFIG (Optional) Override Tomcat's logging config file
# Example (all one line)
# LOGGING_CONFIG="-Djava.util.logging.config.file=$CATALINA_BASE/conf/logging.properties"
#
# LOGGING_MANAGER (Optional) Override Tomcat's logging manager
# Example (all one line)
# LOGGING_MANAGER="-Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager"
#
# UMASK (Optional) Override Tomcat's default UMASK of 0027
#
# USE_NOHUP (Optional) If set to the string true the start command will
# use nohup so that the Tomcat process will ignore any hangup
# signals. Default is "false" unless running on HP-UX in which
# case the default is "true"
# -----------------------------------------------------------------------------
...
# 此处用于设置tomact运行时的虚拟机参数,可以将"”进行替换
JAVA_OPTS="$JAVA_OPTS $JSSE_OPTS"
...
内存优化catalina
JAVA_OPTS="
-server
-Xms2048M
-Xmx2048M
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=5
-XX:+PrintGCDetails
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=$CATALINA_HOME/logs/heap.dump"
9-1-2 tomcat并发优化(线程池配置)
参考资料:${tomcat}/webapps/docs/config/http.html
maxConnections:The maximum number of connections that the server will accept and process at any given time
acceptCount:The maximum queue length for incoming connection requests when all possible request processing threads are in use.
maxThreads:工作线程,The maximum number of request processing threads to be created by this Connector
minSpareThreads:最小空闲的工作线程。The minimum number of threads always kept running
9-1-3 tomact的运行模式设置
APR(The Apache Portable Runtime:apahe轻便运行)的定义:
The Apache Portable Runtime is a highly portable library that is at the heart of Apache HTTP Server 2.x. APR has many uses, including access to advanced IO functionality (such as sendfile, epoll and OpenSSL), OS level functionality (random number generation, system status, etc), and native process handling (shared memory, NT pipes and Unix sockets).
These features allows making Tomcat a general purpose webserver, will enable much better integration with other native web technologies, and overall make Java much more viable as a full fledged webserver platform rather than simply a backend focused technology.
Tomcat-APR
Tomcat的四种模式

总结:
1)BIN与NIO与AIO都是采用Java语言本身提供的IO包实现IO,随着Java语言发展而发展来的
2)APR直接采用JNI(Java Native interface)的方式调用其他语言实现的http服务器库
补充知识:
1) JDK 7 引入了 Asynchronous I/O, 即 AIO。 在进行 I/O 编程中, 常用到两种模式: Reactor 和 Proactor。 Java 的NIO 就是 Reactor, 当有事件触发时, 服务器端得到通知, 进行相应的处理
2) AIO 即 NIO2.0, 叫做异步不阻塞的 IO。 AIO 引入异步通道的概念, 采用了 Proactor 模式, 简化了程序编写,有效的请求才启动线程, 它的特点是先由操作系统完成后才通知服务端程序启动线程去处理, 一般适用于连接
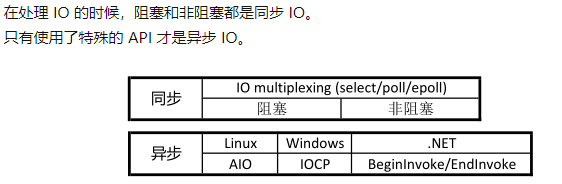
java nio的io模型是同步非阻塞,这里的同步异步指的是真正io操作(数据内核态用户态的拷贝)是否需要进程参与。而说java nio提供了异步处理,这个异步应该是指编程模型上的异步。基于reactor模式的事件驱动,事件处理器的注册和处理器的执行是异步的。
9-2 Ngnix(7)+LVS(4)的优化(配置文件设置)
1)并发优化
2)KeepLive优化
3)压缩优化(静态文件优化)
4) 缓存优化(有钱上CDN,没钱使用ngnix)
两个监测工具
1)ngnix_satus:
2)Ngxtop
9-2-1 LVS的四层负载均衡
四层负责均衡(LVS):也叫IP层负载均衡
七层负载均衡 (Ngnix):也叫应用层负责均衡
注意点:这里的四层与七层是指ISO的7层网络层次

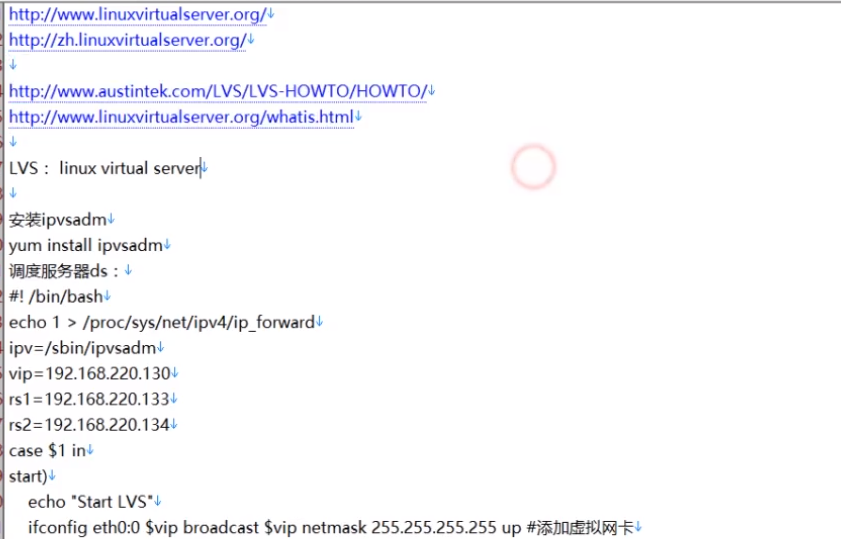
9-2-2 采用keepalived工具实现高可用

1)keepalive是使用C实现的路由软件,目的在于实现Linux服务器的负责均衡与高可用
2)keepalived框架的负载均衡依赖于广泛使用的Linux Virtual Server(IPVS)提供的四层复杂的均衡
3)keepalive的框架的高可用依赖于VRRP协议,即虚拟路由冗余协议(Virtual Router Redundancy Protocol
10 秒杀的扩展问题
问题1:一次性秒杀多个商品,该如何处理?

消息队列的出队逻辑:
transaction.start();
try{
//先查库存,加锁
select stock from goods where goods_id= #{goodsId} for update
if(stock < amout){
return "库存不足";
}
//查询用户已经买到的商品的数量
int sumGoodsCount = select sum(goodsCount) from miaosha_order where user_id = #{userId} and goods_id = #{goodsId} ;
if(sumGoodsCount >= 2){
return "超过最大数";
}
//用户还能购买的数量
int availbaleCount = Math.min(2-sumGoodsCount, amount);
//修改商品表的库存
update goods set stock = stock - availbaleCount;
//生成订单
insert into miaosha_order(user_id, goods_id, availbaleCount);
//事务提交
transaction.commit();
}catch(Exception e){
//事务回滚
transaction.rollback();
}

问题2:高并发场景下如何保证超卖不发生?
问题3:redis预减成功,但是db扣减失败,该如何处理?

问题4:秒杀过程中redis宕机怎么办?

问题5:用户秒杀成功,没有付款怎么办?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号