Flink执行计划第一层——StreamTransformation
前一篇博客 《入门Flink的第一个程序——WordCount》 介绍了一个 Socket Stream 实时计算统计单词出现数量的 Demo,但是在源码的分析上比较笼统,本文将对 Flink 执行计划的四层结构的第一层 Stream API 的源码做一个简单的分析。
一、学会查看执行计划
首先,当一个应用程序需求比较简单的情况下,数据转换涉及的 operator(算子)可能不多,但是当应用的需求变得越来越复杂时,可能在一个 Job 里面算子的个数会达到几十个、甚至上百个,在如此多算子的情况下,整个应用程序就会变得非常复杂,所以在编写 Flink Job 的时候要是能够随时知道 Job 的执行计划那就很方便了。
首先用 StreamExecutionEnvironment#getExecutionPlan() 打印出一段 JSON 字符串,这段字符串包含可视化的必要信息。
只需要在Flink任务的Main方法中添加一行代码即可:
System.out.println(env.getExecutionPlan());
比如,我的Demo程序得到了一串 JSON 字符串:
{"nodes":[{"id":1,"type":"Source: Socket Stream","pact":"Data Source","contents":"Source: Socket Stream","parallelism":1},{"id":2,"type":"Flat Map","pact":"Operator","contents":"Flat Map","parallelism":1,"predecessors":[{"id":1,"ship_strategy":"FORWARD","side":"second"}]},{"id":4,"type":"Keyed Aggregation","pact":"Operator","contents":"Keyed Aggregation","parallelism":1,"predecessors":[{"id":2,"ship_strategy":"HASH","side":"second"}]},{"id":5,"type":"Sink: Print to Std. Out","pact":"Data Sink","contents":"Sink: Print to Std. Out","parallelism":4,"predecessors":[{"id":4,"ship_strategy":"REBALANCE","side":"second"}]}]}
通过打开 https://flink.apache.org/visualizer/,输入 JSON 字符串,点击 DRAW 就可以查看:
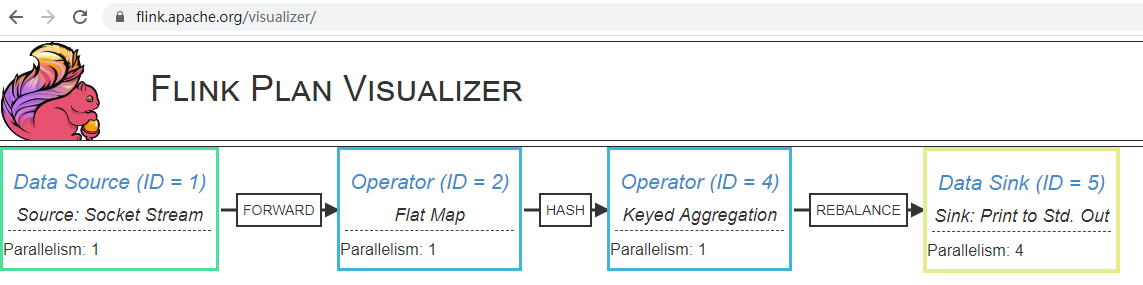
参考自 《Flink 查看作业执行计划》。
二、Stream API 流程图
通过观察 Flink 执行计划图,我可以发现:
- 数据经由 数据源(Data Source)=> 操作器 (Operator)=> 数据接收器(Data Sink)
2.1 添加数据源 addSource
跟踪 env.socketTextStream("localhost", 8888) 的源码,我们可以跟踪到 StreamExecutionEnvironment#addSource 方法:

以下是源码:
/**
* Ads a data source with a custom type information thus opening a
* {@link DataStream}. Only in very special cases does the user need to
* support type information. Otherwise use
* {@link #addSource(org.apache.flink.streaming.api.functions.source.SourceFunction)}
*
* @param function
* the user defined function
* @param sourceName
* Name of the data source
* @param <OUT>
* type of the returned stream
* @param typeInfo
* the user defined type information for the stream
* @return the data stream constructed
*/
@SuppressWarnings("unchecked")
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function, String sourceName, TypeInformation<OUT> typeInfo) {
// 这一步主要获取输出类型的信息
if (typeInfo == null) {
if (function instanceof ResultTypeQueryable) {
typeInfo = ((ResultTypeQueryable<OUT>) function).getProducedType();
} else {
try {
typeInfo = TypeExtractor.createTypeInfo(
SourceFunction.class,
function.getClass(), 0, null, null);
} catch (final InvalidTypesException e) {
typeInfo = (TypeInformation<OUT>) new MissingTypeInfo(sourceName, e);
}
}
}
boolean isParallel = function instanceof ParallelSourceFunction;
clean(function);
StreamSource<OUT, ?> sourceOperator;
// StreamSource 用于流数据源的 StreamOperator
// StreamSource 扩展了用户定义的 SourceFunction
if (function instanceof StoppableFunction) {
// StoppableStreamSource 是 StreamSource 的子类
sourceOperator = new StoppableStreamSource<>(cast2StoppableSourceFunction(function));
} else {
sourceOperator = new StreamSource<>(function);
}
// DataStreamSource 是 DataStream 的子类
// DataStreamSource 拓展了 StreamSource,提供了流式操作
return new DataStreamSource<>(this, typeInfo, sourceOperator, isParallel, sourceName);
}
2.2 添加“运算符” addOperator
跟踪 src.flatMap(new LineSplitter()),可以看一下 DataStream#flatMap 的源码:
/**
* Applies a FlatMap transformation on a {@link DataStream}. The
* transformation calls a {@link FlatMapFunction} for each element of the
* DataStream. Each FlatMapFunction call can return any number of elements
* including none. The user can also extend {@link RichFlatMapFunction} to
* gain access to other features provided by the
* {@link org.apache.flink.api.common.functions.RichFunction} interface.
*
* @param flatMapper
* The FlatMapFunction that is called for each element of the
* DataStream
*
* @param <R>
* output type
* @return The transformed {@link DataStream}.
*/
public <R> SingleOutputStreamOperator<R> flatMap(FlatMapFunction<T, R> flatMapper) {
TypeInformation<R> outType = TypeExtractor.getFlatMapReturnTypes(clean(flatMapper),
getType(), Utils.getCallLocationName(), true);
// 把用户定义的 FlatMapFunction 作为构造函数参数传递给 StreamFlatMap
// StreamFlatMap 实现了 StreamOperator 接口
return transform("Flat Map", outType, new StreamFlatMap<>(clean(flatMapper)));
}
接着再看 DataStream#transform 的源码:
/**
* Method for passing user defined operators along with the type
* information that will transform the DataStream.
*
* @param operatorName
* name of the operator, for logging purposes
* @param outTypeInfo
* the output type of the operator
* @param operator
* the object containing the transformation logic
* @param <R>
* type of the return stream
* @return the data stream constructed
*/
@PublicEvolving
public <R> SingleOutputStreamOperator<R> transform(String operatorName, TypeInformation<R> outTypeInfo, OneInputStreamOperator<T, R> operator) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
// this.transformation 将赋值给 OneInputTransformation 的成员变量 input,用于寻找前一个 Transformation
// operator 是包裹了用户定义的函数,实现了 StreamOperator 接口的 “流运算符”
// new 创建出 OneInputTransformation
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operator,
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({ "unchecked", "rawtypes" })
// SingleOutputStreamOperator 是 DataStream 的子类,把这个对象返回出去,就可以继续进行“链式”编程了
SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform);
// 把 Transformation 添加到 StreamExecutionEnvironment 的成员变量 transformations 中。
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
2.3 添加数据接收者 addSink
跟踪 .print() 的代码,DataStream#print源码如下:
/**
* Writes a DataStream to the standard output stream (stdout).
*
* <p>For each element of the DataStream the result of {@link Object#toString()} is written.
*
* <p>NOTE: This will print to stdout on the machine where the code is executed, i.e. the Flink
* worker.
*
* @return The closed DataStream.
*/
@PublicEvolving
public DataStreamSink<T> print() {
// PrintSinkFunction 是 SinkFunction 接口的实现类
PrintSinkFunction<T> printFunction = new PrintSinkFunction<>();
return addSink(printFunction).name("Print to Std. Out");
}
继续跟踪源码 DataStream#addSink:
/**
* Adds the given sink to this DataStream. Only streams with sinks added
* will be executed once the {@link StreamExecutionEnvironment#execute()}
* method is called.
*
* @param sinkFunction
* The object containing the sink's invoke function.
* @return The closed DataStream.
*/
public DataStreamSink<T> addSink(SinkFunction<T> sinkFunction) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
// configure the type if needed
if (sinkFunction instanceof InputTypeConfigurable) {
((InputTypeConfigurable) sinkFunction).setInputType(getType(), getExecutionConfig());
}
// sinkFunction 是用户定义的 Function 实现类
// 把 sinkFunction 通过构造函数参数传递给 StreamSink,就是 StreamOperator 了
StreamSink<T> sinkOperator = new StreamSink<>(clean(sinkFunction));
// 再把 StreamSink 传递给 DataStreamSink,但是 DataStreamSink 不是 DataStream 的子类
// 这就类似于 Java8 Lambda 表达式中的“终结函数”,不能再做别的“运算”了
DataStreamSink<T> sink = new DataStreamSink<>(this, sinkOperator);
// 把 SinkTransformation 对象返回
getExecutionEnvironment().addOperator(sink.getTransformation());
return sink;
}
SinkTransformation 对象是在 DataStreamSink 的构造函数中创建的对象:
protected DataStreamSink(DataStream<T> inputStream, StreamSink<T> operator) {
this.transformation = new SinkTransformation<T>(inputStream.getTransformation(), "Unnamed", operator, inputStream.getExecutionEnvironment().getParallelism());
}
2.4 继承关系图
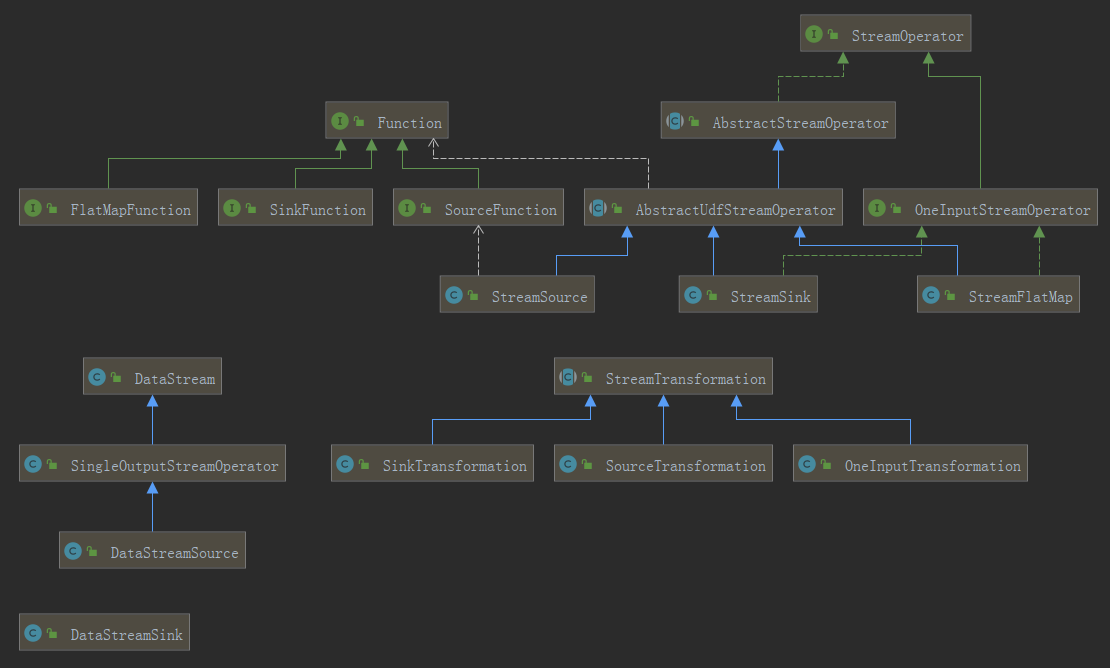
Function及其子类是 User-Defined Function;DataStream及其子类是我们 Stream API 中可以进行“链式”编程的对象;- 注意,
DataStreamSink不是DataStream的子类! StreamTransformation的每个子类在加载时,都会分配一个唯一的id;AbstractUdfStreamOperator有一个名为userFunction的成员变量 ,存放对应的 User-Defined Function 的对象引用;
2.5 Transformation 链

StreamTransformation 的子类通常都会有一个名为 input 的成员变量,用来保存“链表”上的前一个 StreamTransformation 的引用,注意 SourceTransformation 作为源数据,是没有 input 的。
2.6 StreamExecutionEnvironment 中保存的 transformations
我们回顾一下前面的代码,我们发现 DataStream#transform 和 DataStream#addSink 时调用了 getExecutionEnvironment().addOperator() 函数(注意,DataStream#addSource没有调用 addOperator!):
src.flatMap(new LineSplitter()).setParallelism(1)
.keyBy(0)
.sum(1).setParallelism(1)
.print();
上面这段代码执行完之后,我们再看一下 Flink 执行环境中保存的 transformations:
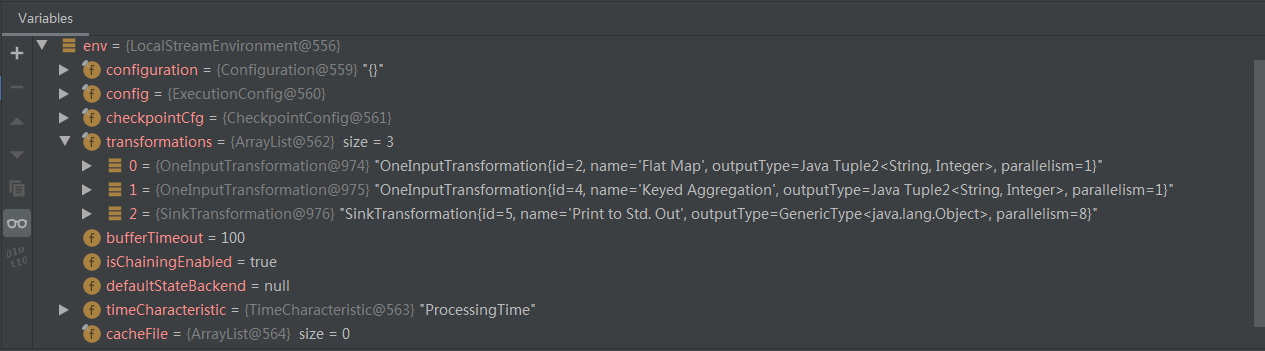
flatMap对应的OneInputTransformation被保存了;keyBy和sum合并为一个OneInputTransformation保存了,名为Keyed Aggregation(按键聚合);- 作为最终结果的
SinkTransformation保存了; SourceTransformation没有被保存在transformations列表中,但是可以通过成员变量input沿着“链”找到;
小结
本文介绍的是在执行 env.execute 之前,内存中保存的对象,有很多文章直接就开始讲 StreamGraph,我个人感觉不是很友好,就分析了一下这里的代码。接下来我就该分析 StreamGraph 的生成了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号