入门Flink的第一个程序——WordCount
一、从WordCount开始
1.1 Maven依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.coderead</groupId>
<artifactId>flink-quick-start</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<encoding>UTF-8</encoding>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.11</scala.version>
<flink.version>1.8.1</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</project>
2.11表示 Flink 是使用 Scala 2.11 编译的;1.8.1表示的是 Flink 的版本号;截止撰写本文,Flink 已经有 1.14.0 版本了 Download Flink
1.2 Flink 代码
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class SocketTextWorkCountStream {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> src = env.socketTextStream("localhost", 8888);
src.flatMap(new LineSplitter()).setParallelism(1)
.keyBy(0)
.sum(1).setParallelism(1)
.print();
env.execute("Java WordCount from SocketTextStream Example");
}
private static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) {
// normalize and split the line
// \W 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2<>(token, 1));
}
}
}
}
}
1.3 服务端程序
在启动上面的程序之前,我们需要一个服务端程序:
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.net.InetSocketAddress;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Scanner;
public class TextServer {
public static void main(String[] args) throws IOException {
try (ServerSocket server = new ServerSocket()) {
// 监听 8888 端口
server.bind(new InetSocketAddress(8888));
Socket socket = server.accept();
// 命令行输出
Scanner in = new Scanner(System.in);
// 通过 Socket 输出
try (BufferedWriter out = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()))) {
while (in.hasNextLine()) {
String value = in.nextLine();
out.write(value);
out.write("\n");
out.flush();
}
}
}
}
}
这个程序可以为我们的 SocketTextWorkCountStream 提供数据。
那么,为什么我们用的是以下这段代码呢?
BufferedWriter out = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()))
原因是要和 env.socketTextStream("localhost", 8888) 底层代码保持一致————代码一直跟到 SocketTextStreamFunction 第 97 行:
try (BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream())))
当然, TextServer 也可以用另一种发送报文的方式:
try (PrintWriter out = new PrintWriter(socket.getOutputStream())) {
while (in.hasNextLine()) {
String value = in.nextLine();
out.println(value);
out.flush();
}
}
本质也是一样的,我们可以看一下 PrintWriter 的构造函数,也用到了 new BufferedWriter(new OutputStreamWriter(out)):
public PrintWriter(OutputStream out, boolean autoFlush) {
this(new BufferedWriter(new OutputStreamWriter(out)), autoFlush);
// save print stream for error propagation
if (out instanceof java.io.PrintStream) {
psOut = (PrintStream) out;
}
}
需要注意的是,为了提高数据传输的效率,Socket类并没有在每次调用write方法后都进行数据传输,而是将这些要传输的数据写到一个缓冲区里(默认是8192个字节),然后通过flush方法将这个缓冲区里的数据一起发送出去,因此,out.flush();是必须的。
二、源码解析
2.1 Flink执行环境
程序的启动,从这句开始。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
这行代码会返回一个可用的执行环境。执行环境是整个flink程序执行的上下文,记录了相关配置(如并行度等),并提供了一系列方法,如读取输入流的方法,以及真正开始运行整个代码的execute方法等。对于分布式流处理程序来说,我们在代码中定义的flatMap,keyBy等等操作,事实上可以理解为一种声明,告诉整个程序我们采用了什么样的算子,而真正开启计算的代码不在此处。由于我们是在本地运行flink程序,因此这行代码会返回一个LocalStreamEnvironment,最后我们要调用它的execute方法来开启真正的任务。我们先接着往下看。
2.2 算子(Operator)的注册(声明)
我们以org.apache.flink.streaming.api.datastream.DataStream#flatMap为例, 跟踪源码进去是这样的:
/**
* 在{@link DataStream}上应用FlatMap转换。
* 该转换为DataStream的每个元素调用一次{@link FlatMapFunction}。
* 每个FlatMapFunction调用可以返回任意数量的元素,包括none。
* 用户还可以扩展{@link RichFlatMapFunction},以访问{@link org.apache.flink.api.common.functions.RichFunction}接口提供的其他功能。
*
* @param flatMapper
* The FlatMapFunction that is called for each element of the
* DataStream
*
* @param <R>
* output type
* @return The transformed {@link DataStream}.
*/
public <R> SingleOutputStreamOperator<R> flatMap(FlatMapFunction<T, R> flatMapper) {
TypeInformation<R> outType = TypeExtractor.getFlatMapReturnTypes(clean(flatMapper),
getType(), Utils.getCallLocationName(), true);
return transform("Flat Map", outType, new StreamFlatMap<>(clean(flatMapper)));
}
里面完成了两件事,一是用反射拿到了flatMap算子的输出类型,二是生成了一个Operator。 flink流式计算的核心概念,就是将数据从输入流一个个传递给Operator进行链式处理,最后交给输出流的过程。对数据的每一次处理在逻辑上成为一个operator,并且为了本地化处理的 效率起见,operator之间也可以串成一个chain一起处理(可以参考责任链模式帮助理解)。
1.3 整体变换过程
下面这张图表明了flink是如何看待用户的处理流程的:抽象化为一系列operator,以source开始,以sink结尾,中间的operator做的操作叫做transform,并且可以把几个操作串在一起执行。
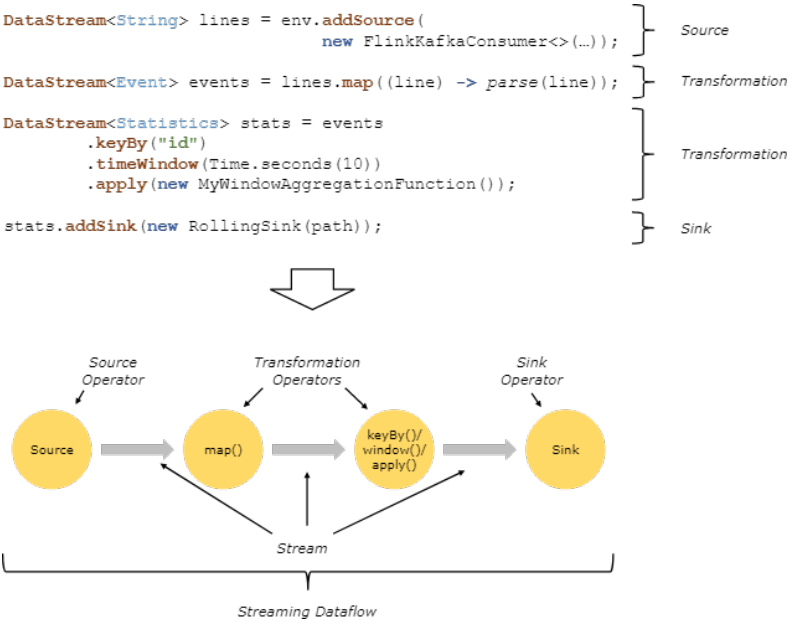
你可能要问 env.socketTextStream("localhost", 8888); 有没有调用 addSource 啊?我们稍微跟踪一下 StreamExecutionEnvironment 源码:
public DataStreamSource<String> socketTextStream(String hostname, int port, String delimiter, long maxRetry) {
// 还是调用的 addSource 添加数据源
return addSource(new SocketTextStreamFunction(hostname, port, delimiter, maxRetry),
"Socket Stream");
}
同理,print 作为输出函数,也调用了 addSink,跟踪一下 DataStream 源码:
public DataStreamSink<T> print() {
PrintSinkFunction<T> printFunction = new PrintSinkFunction<>();
// 还是调用了 addSink 输出结果
return addSink(printFunction).name("Print to Std. Out");
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号