
海豚调度_DolphinScheduler(3.3.2)+ Datax_3.0 + SeaTunnel_2.3.12 + DEMO演示
一、海豚调度(DolphinScheduler_3.3.2)的使用
- DAG --有向无环图,有顺序,但是不会形成环的图表。
- 海豚调度的API接口:http://YOURID:12345/dolphinscheduler/swagger-ui/index.html
- 参考
- 需要先自行安装DataX和SeaTunnel
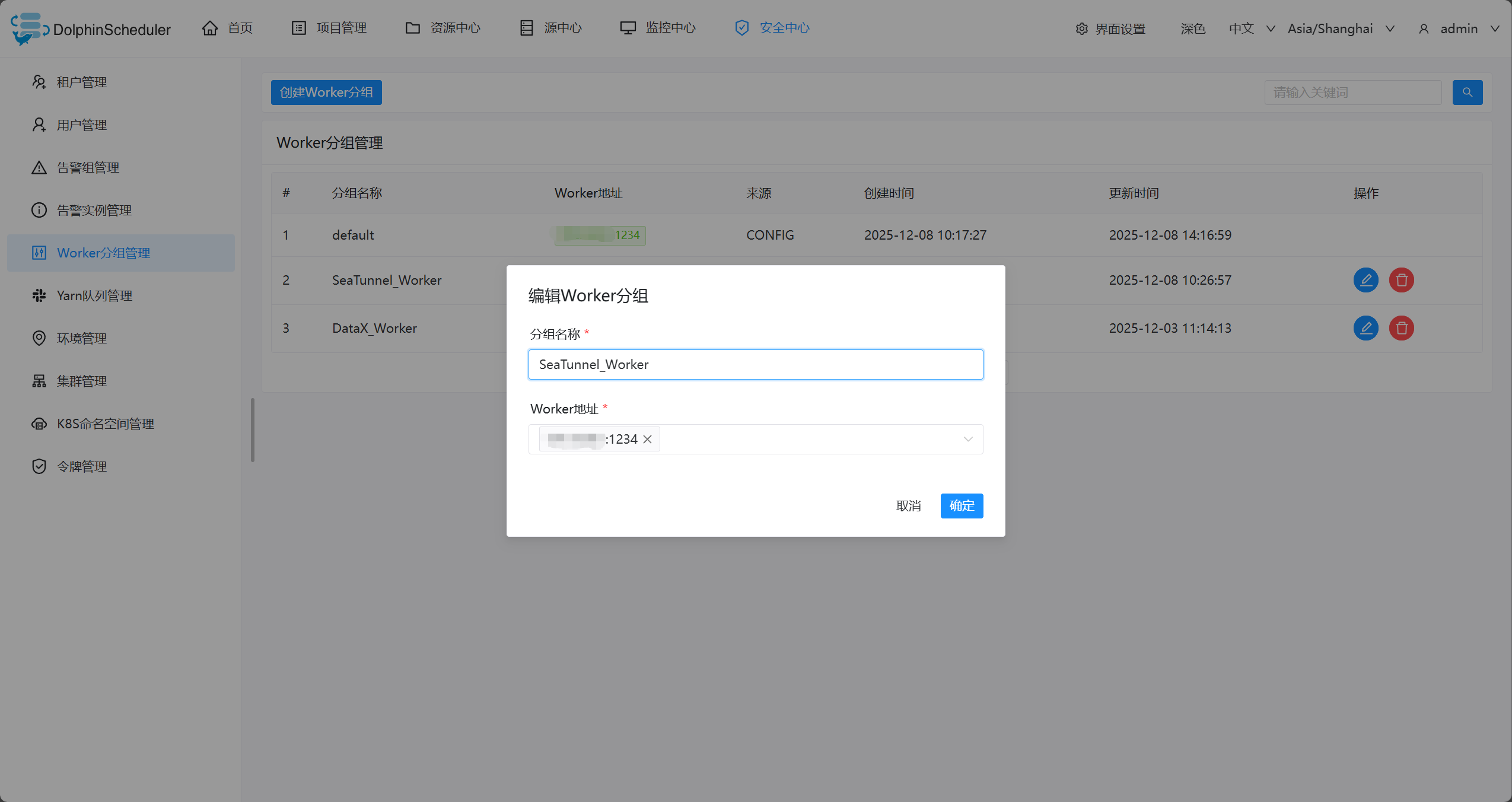
1、安全中心-Worker分组管理

- 创建Worker分组管理
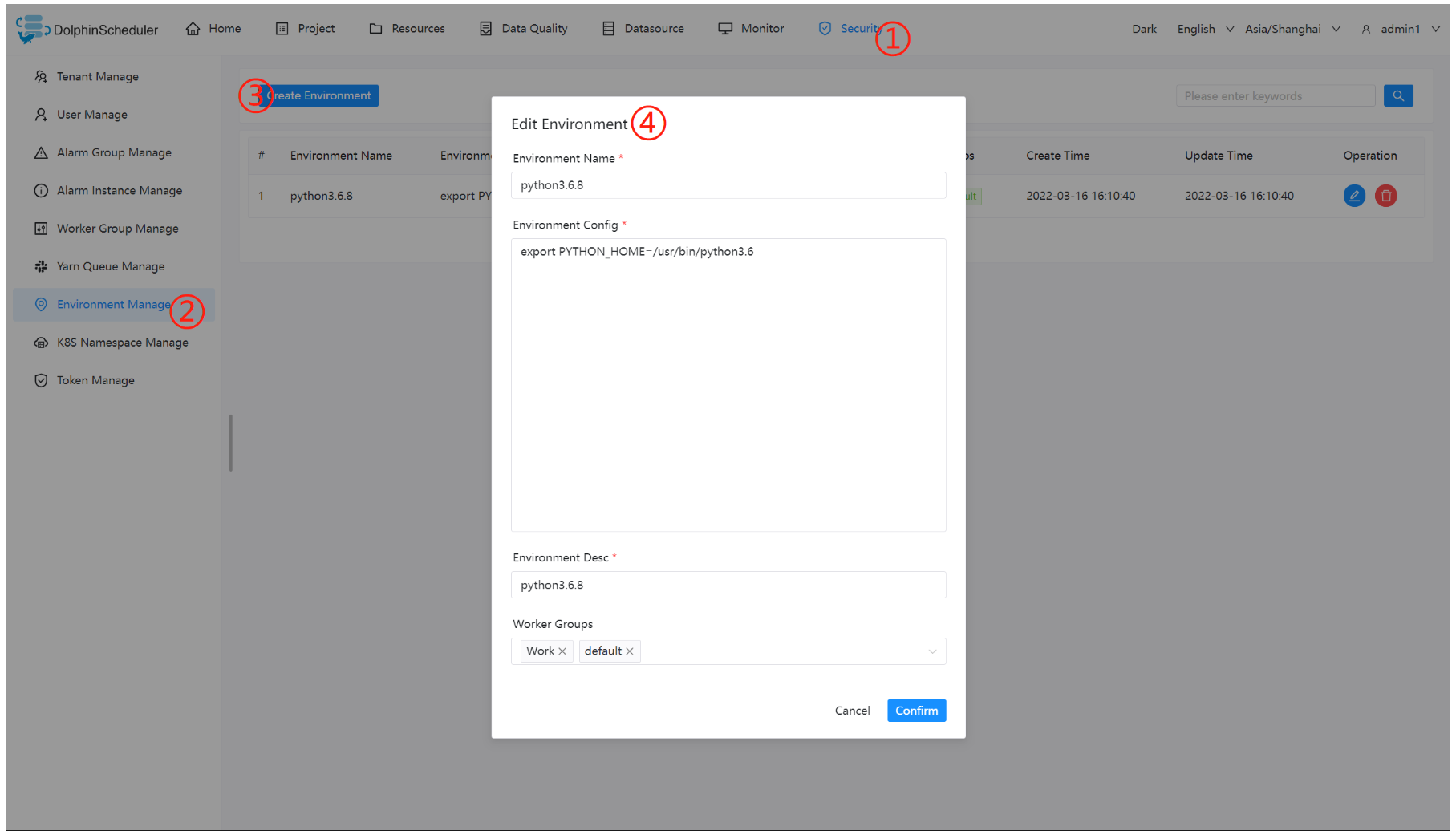
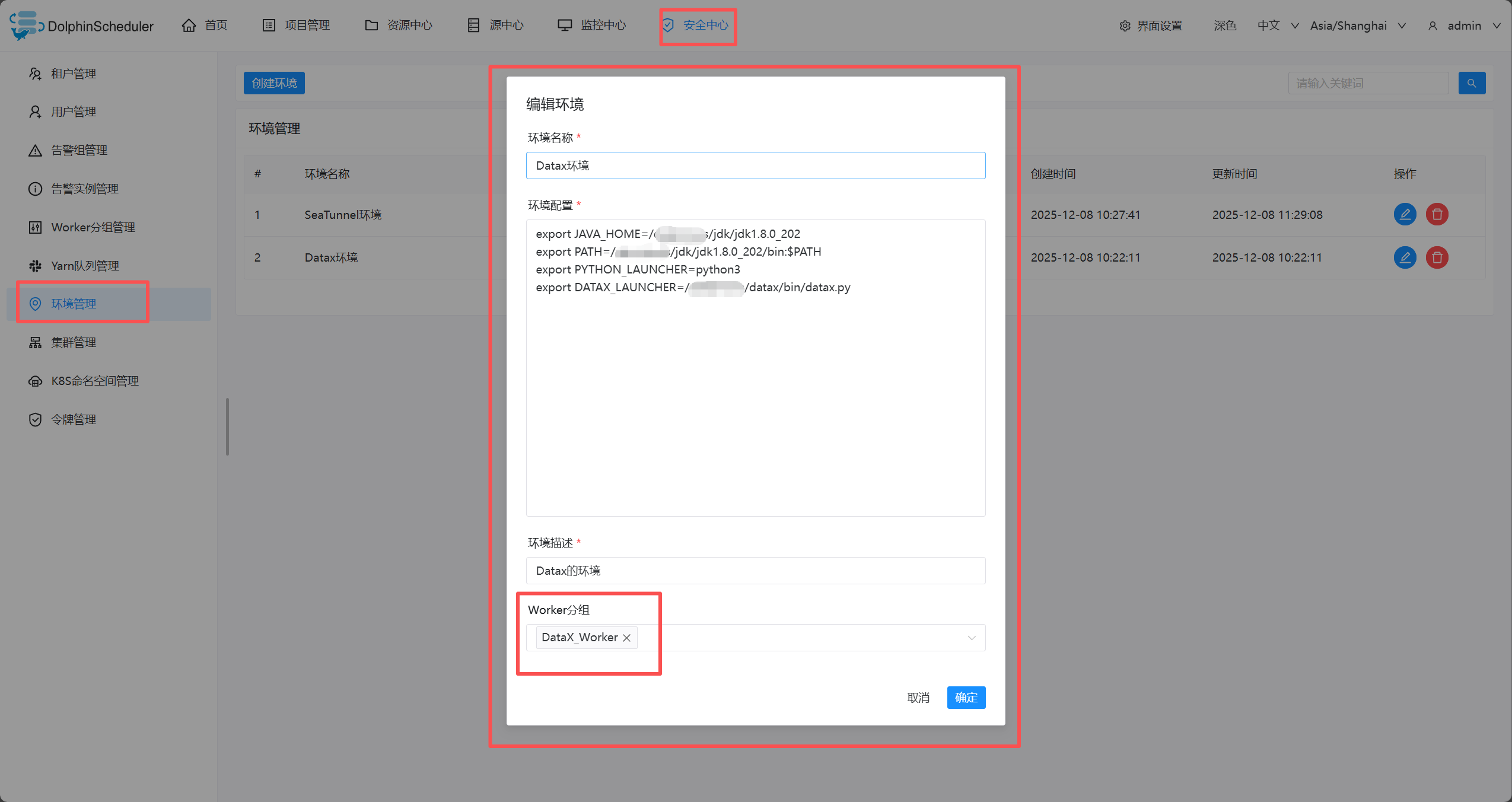
2、安全中心-环境管理
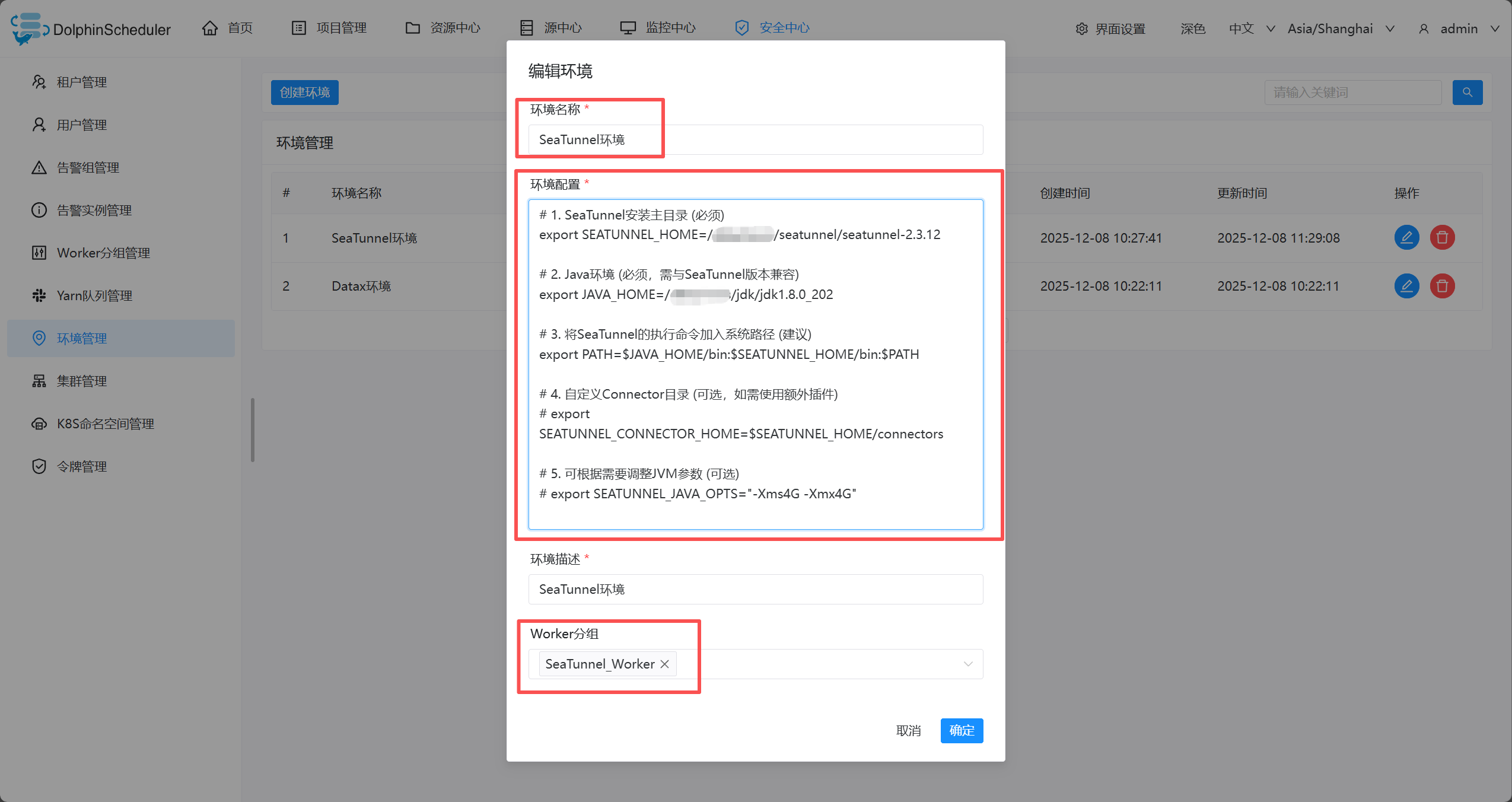
在线配置 worker 运行环境,一个 worker 可以指定多个环境,每个环境等价于 dolphinscheduler_env.sh 文件.
默认环境为dolphinscheduler_env.sh文件.
在任务执行时,可以将任务分配给指定 worker 分组,根据 worker 分组选择对应的环境,最终由该组中的 worker 节点执行环境后执行该任务.
创建/更新 环境
环境配置等价于dolphinscheduler_env.sh文件内配置
使用环境
在工作流定义中创建任务节点选择 worker 分组和 worker 分组对应的环境,任务执行时 worker 会先执行环境在执行任务.
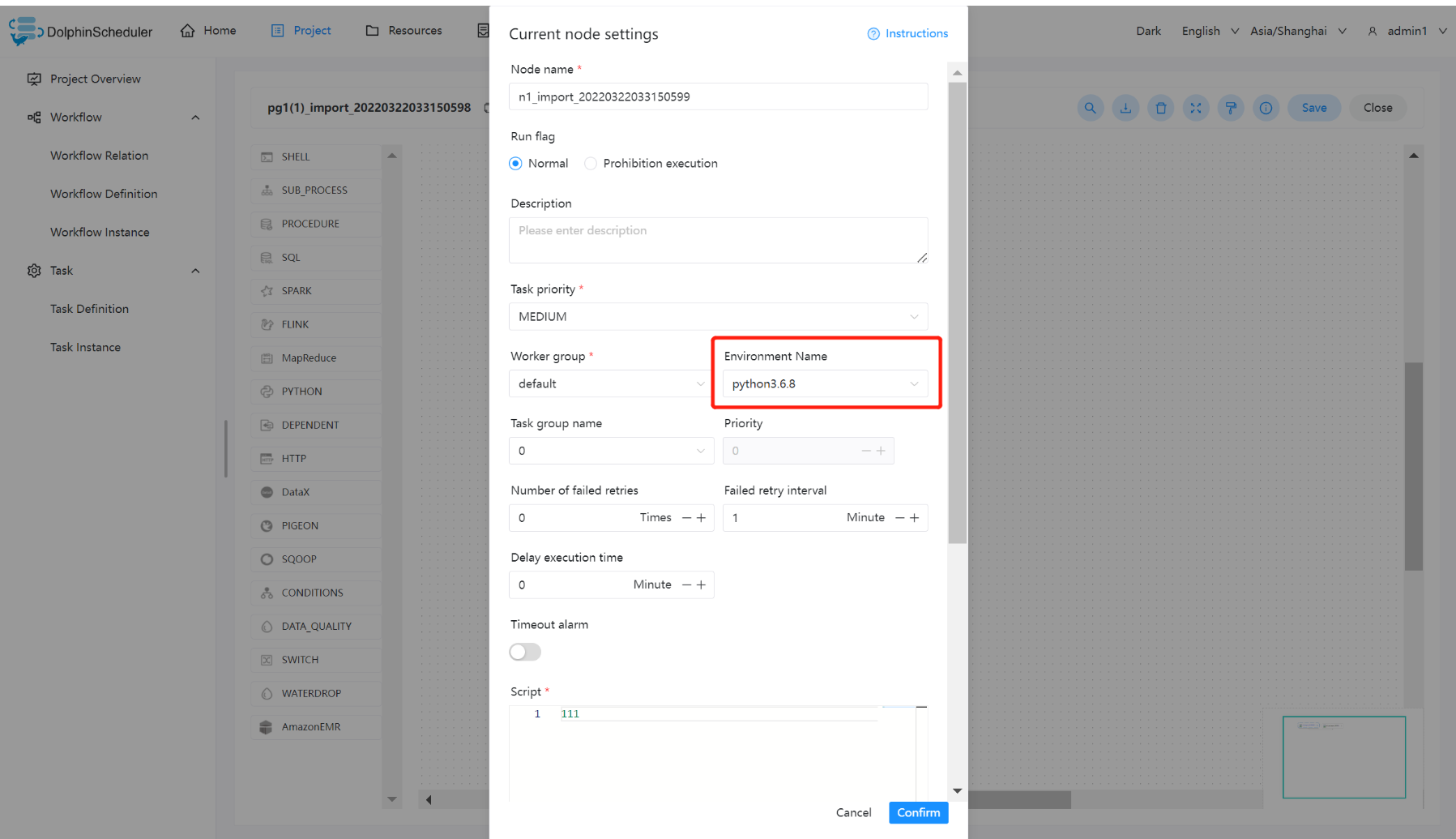
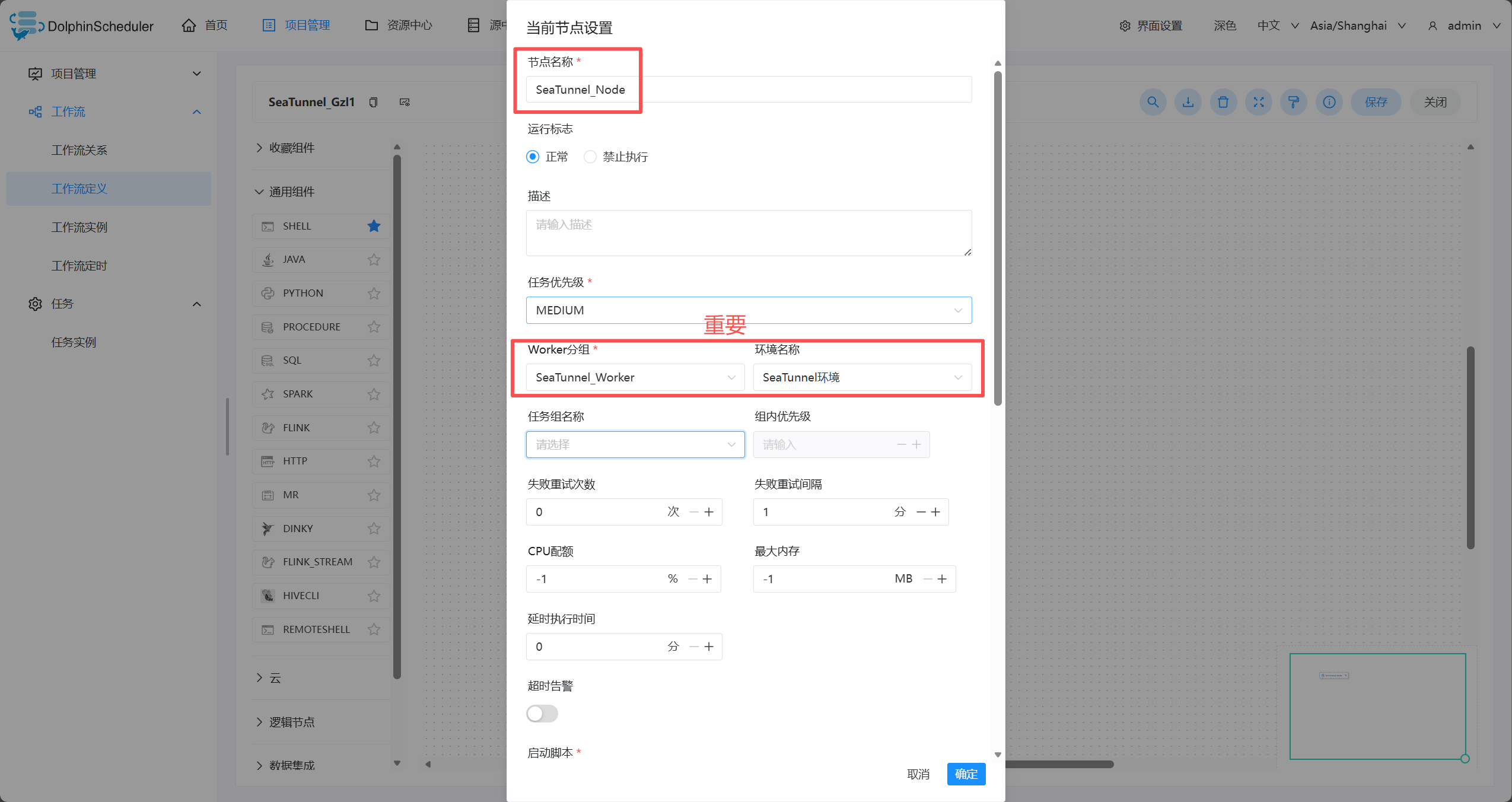
注意: 当无法在任务定义或工作流运行对话框中使用你想要使用的环境时,请检查您已经选择worker,并且您要使用的环境已经关联到您选择的worker中
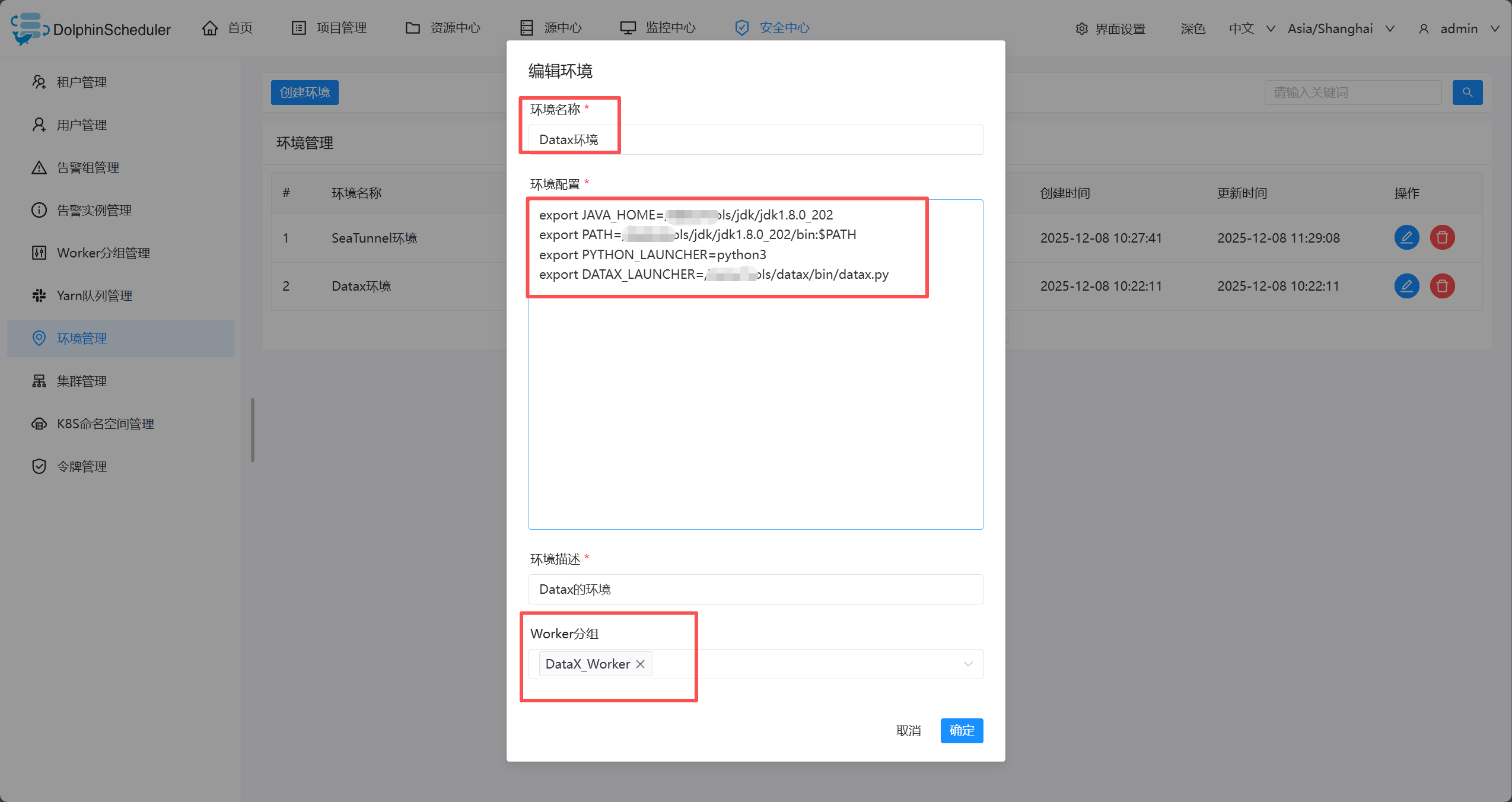
- 创建环境
- 需要关联worker分组
3、项目管理(创建项目)
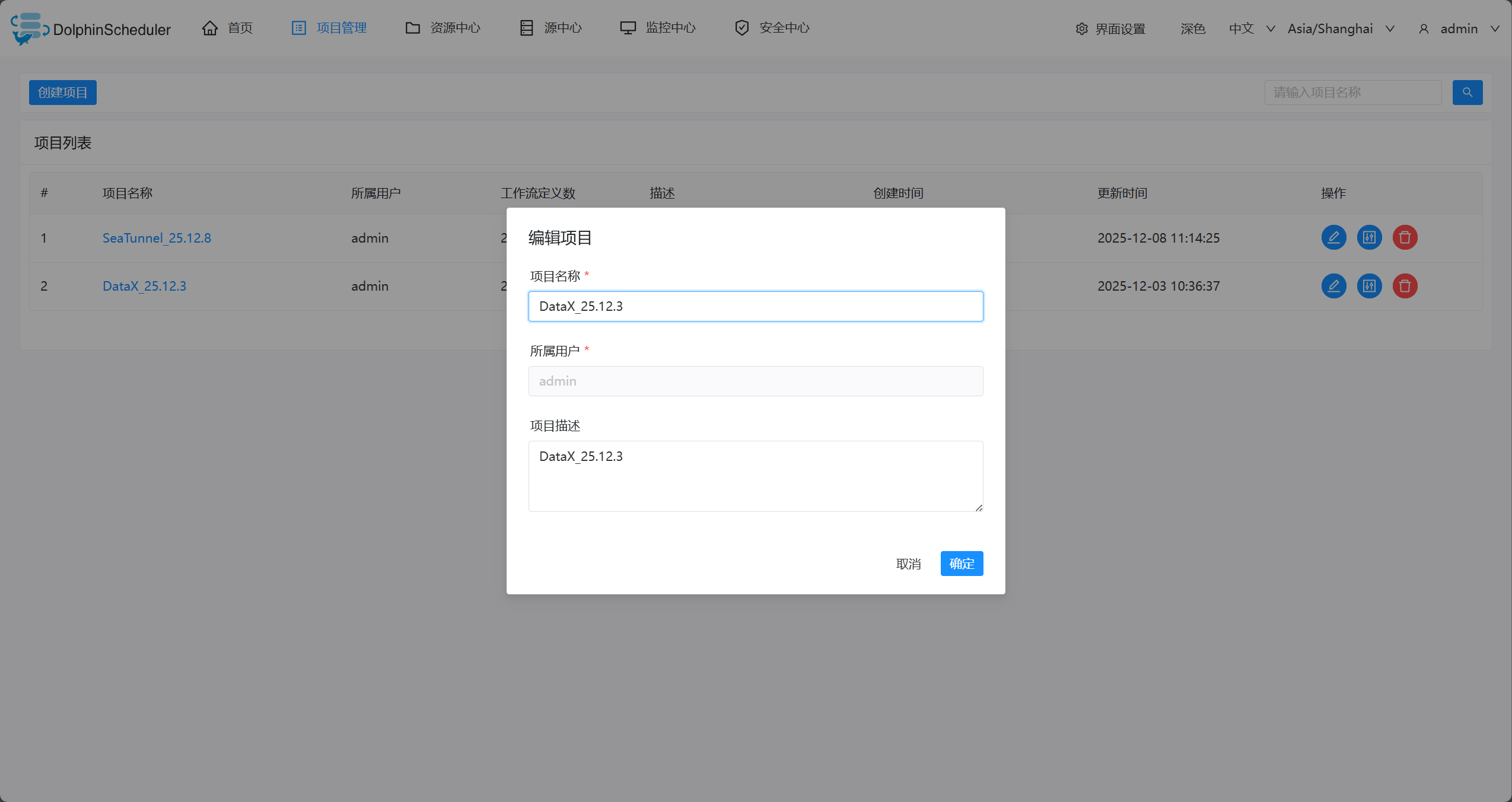
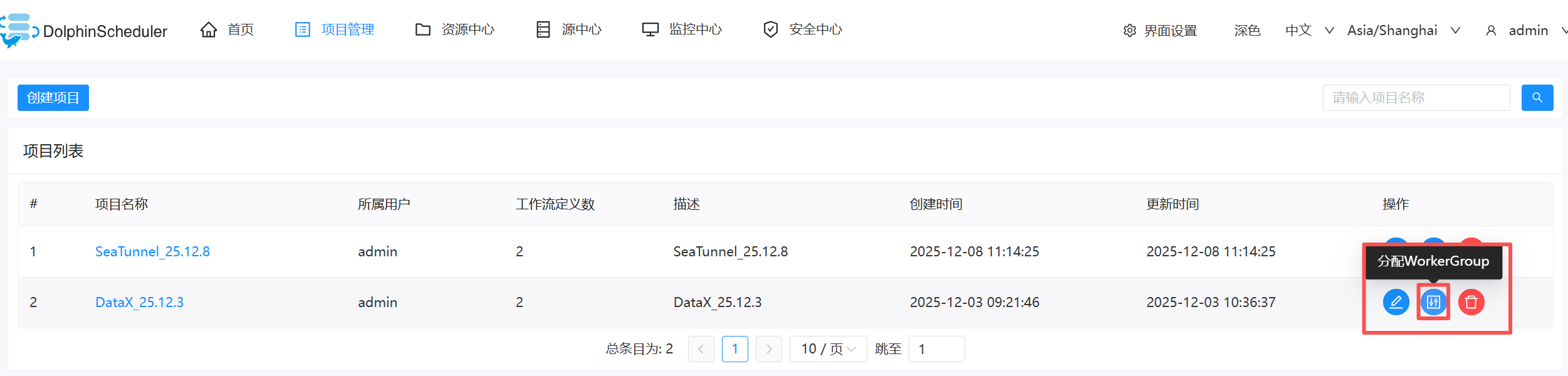
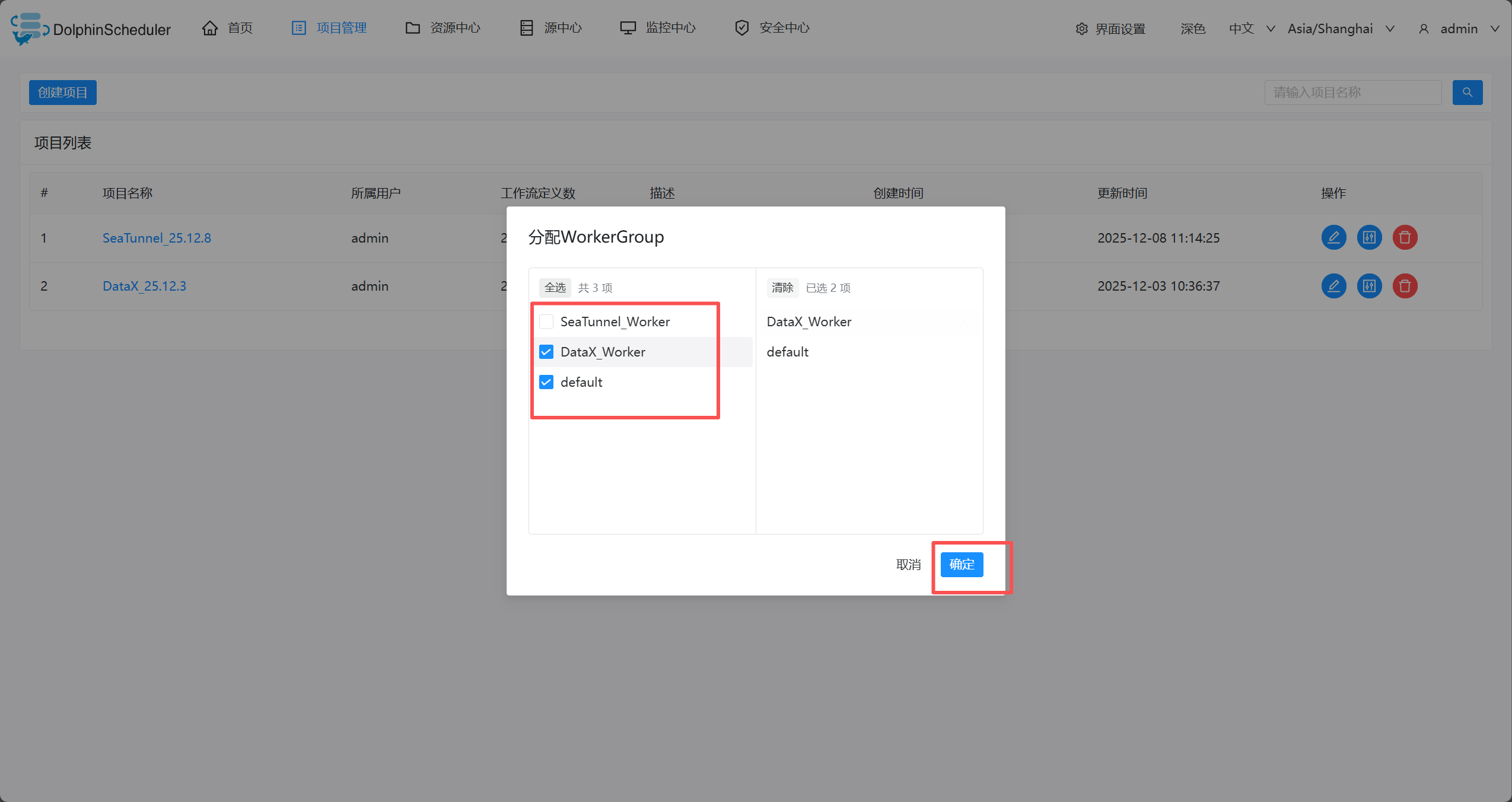
- 关联workGroup
4、工作流定义:见二、三点
二、海豚调度(DolphinScheduler)+ Datax_3.0 的DEMO
1、创建项目、环境变量
-
创建项目:见一、3、
-
环境变量
export JAVA_HOME=/……/jdk/jdk1.8.0_202
export PATH=/……/jdk/jdk1.8.0_202/bin:$PATH
export PYTHON_LAUNCHER=python3
export DATAX_LAUNCHER=/……/datax/bin/datax.py
2、进入项目-工作流定义
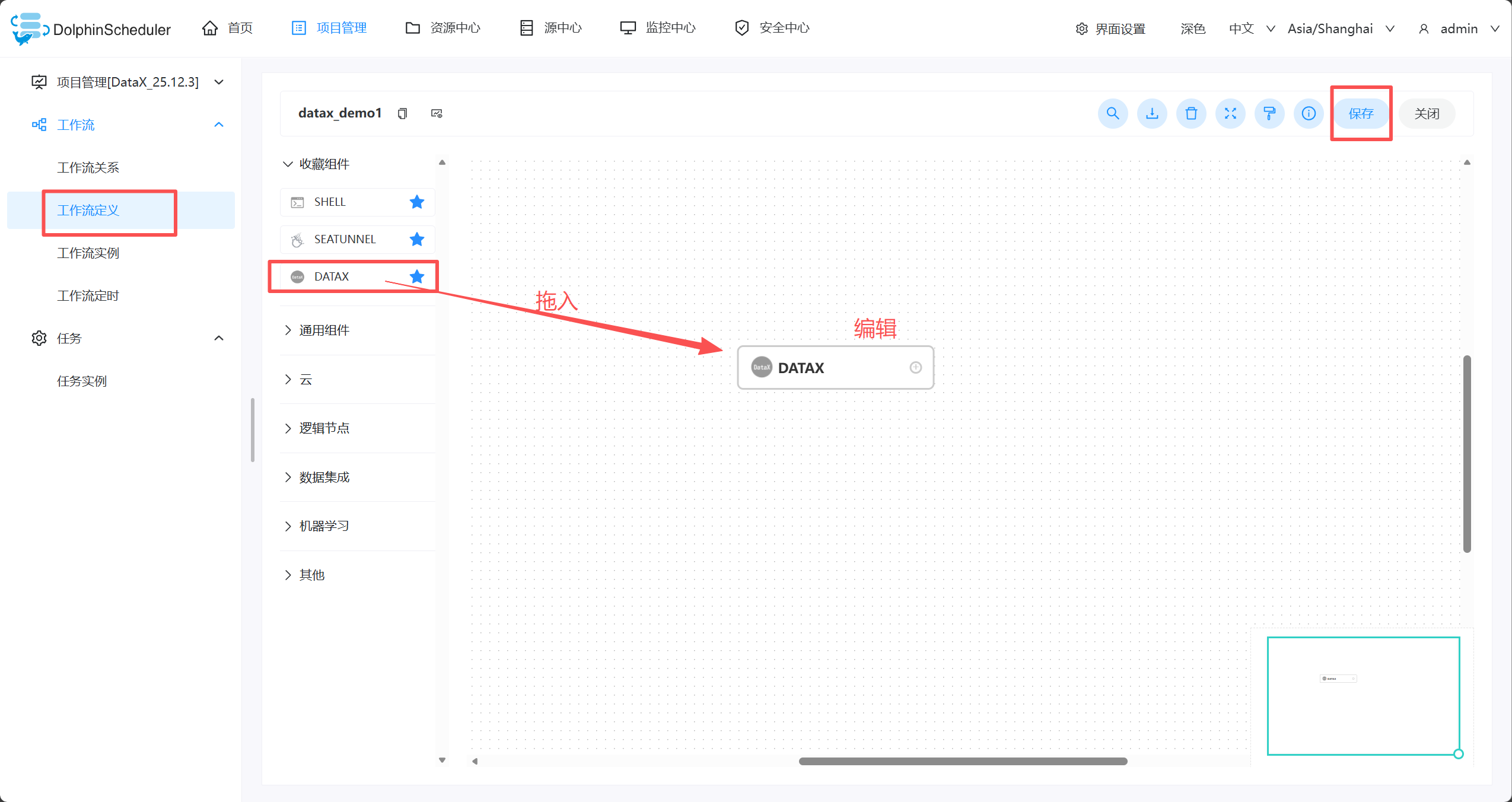
- 编辑datax的节点
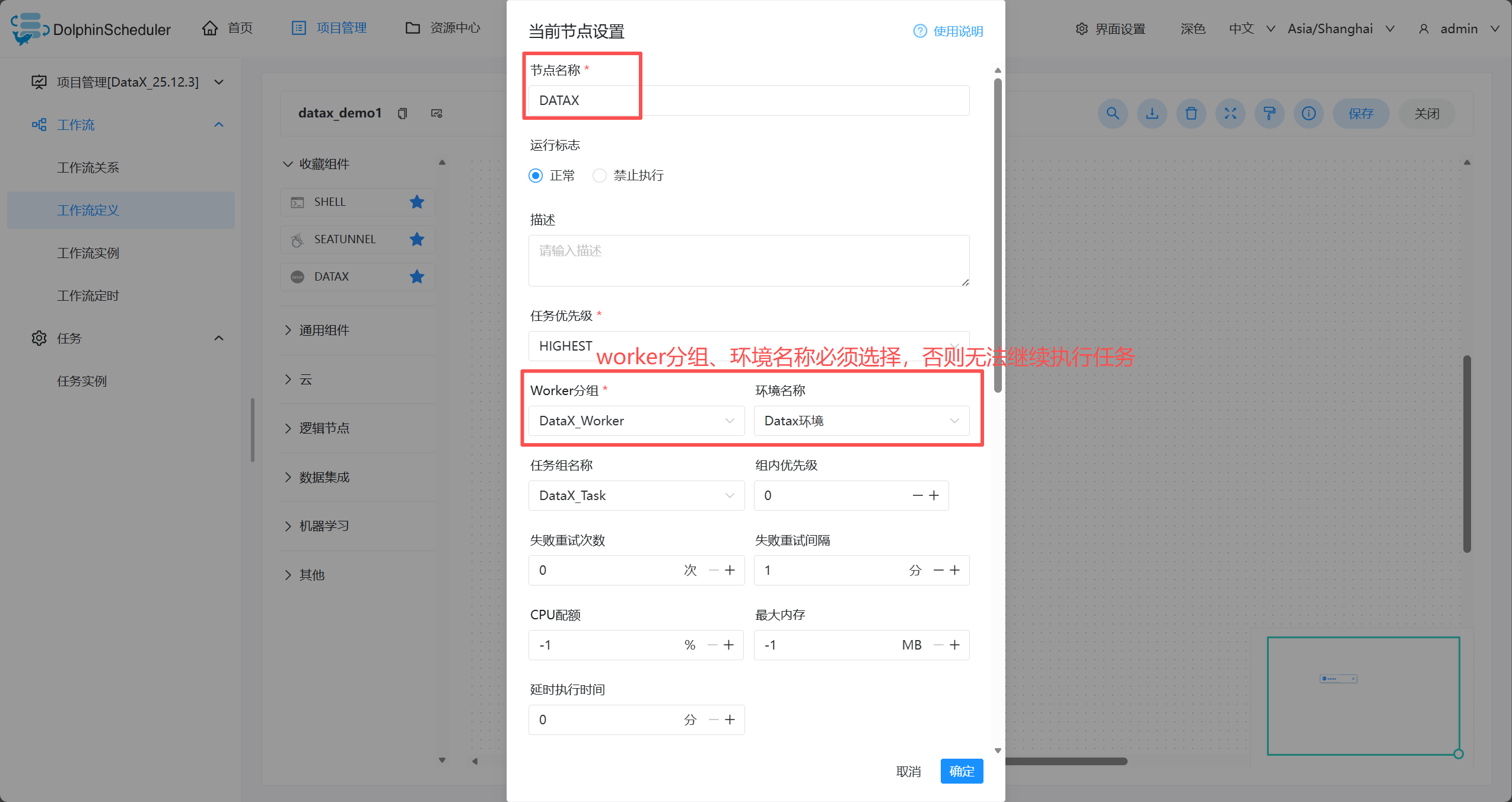
- 上图的后半截
- 写入datax的job.json
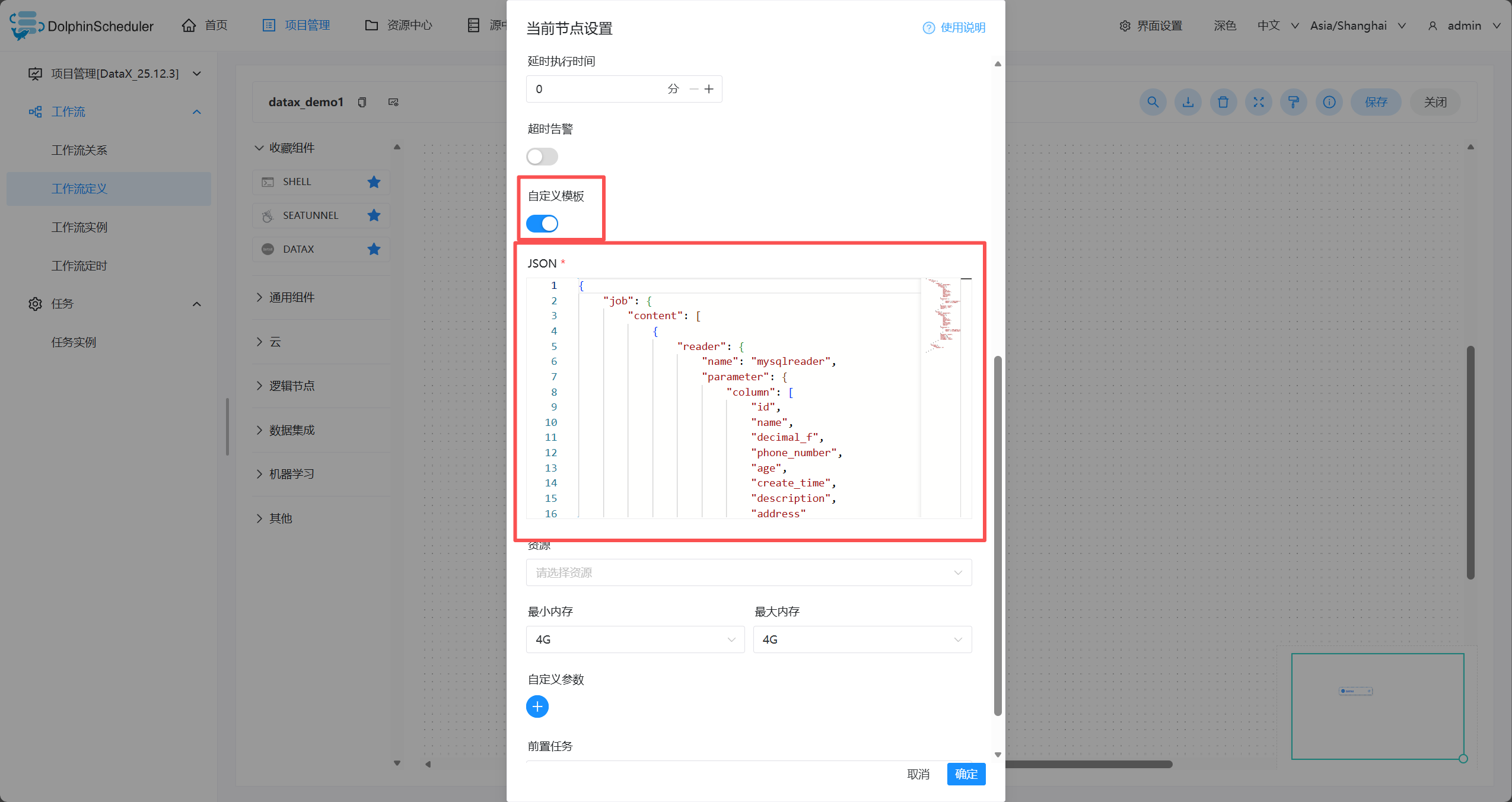
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name",
"decimal_f",
"phone_number",
"age",
"create_time",
"description",
"address"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://ip:port/cs1"
],
"table": [
"t_8_100w"
]
}
],
"password": "zysoft",
"username": "root",
"where": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name",
"decimal_f",
"phone_number",
"age",
"create_time",
"description",
"address"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://ip:port/cs2",
"table": [
"t_8_100w_import_dolphin_dx"
]
}
],
"password": "zysoft",
"preSql": [
],
"session": [
],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
- 配置完毕,保存。然后上线
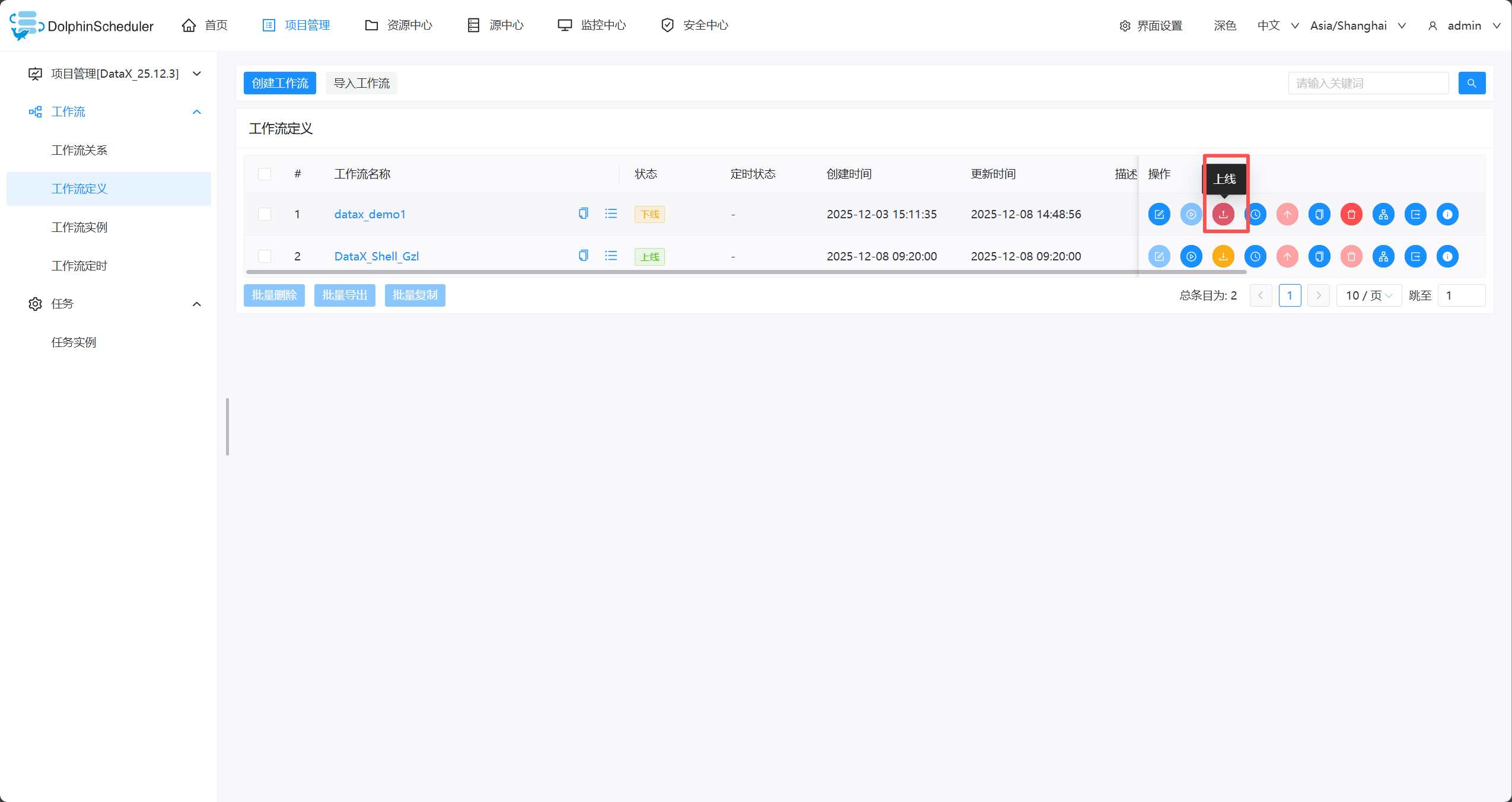
3、运行
- 环境变量的配置很重要。不然跑不了任务
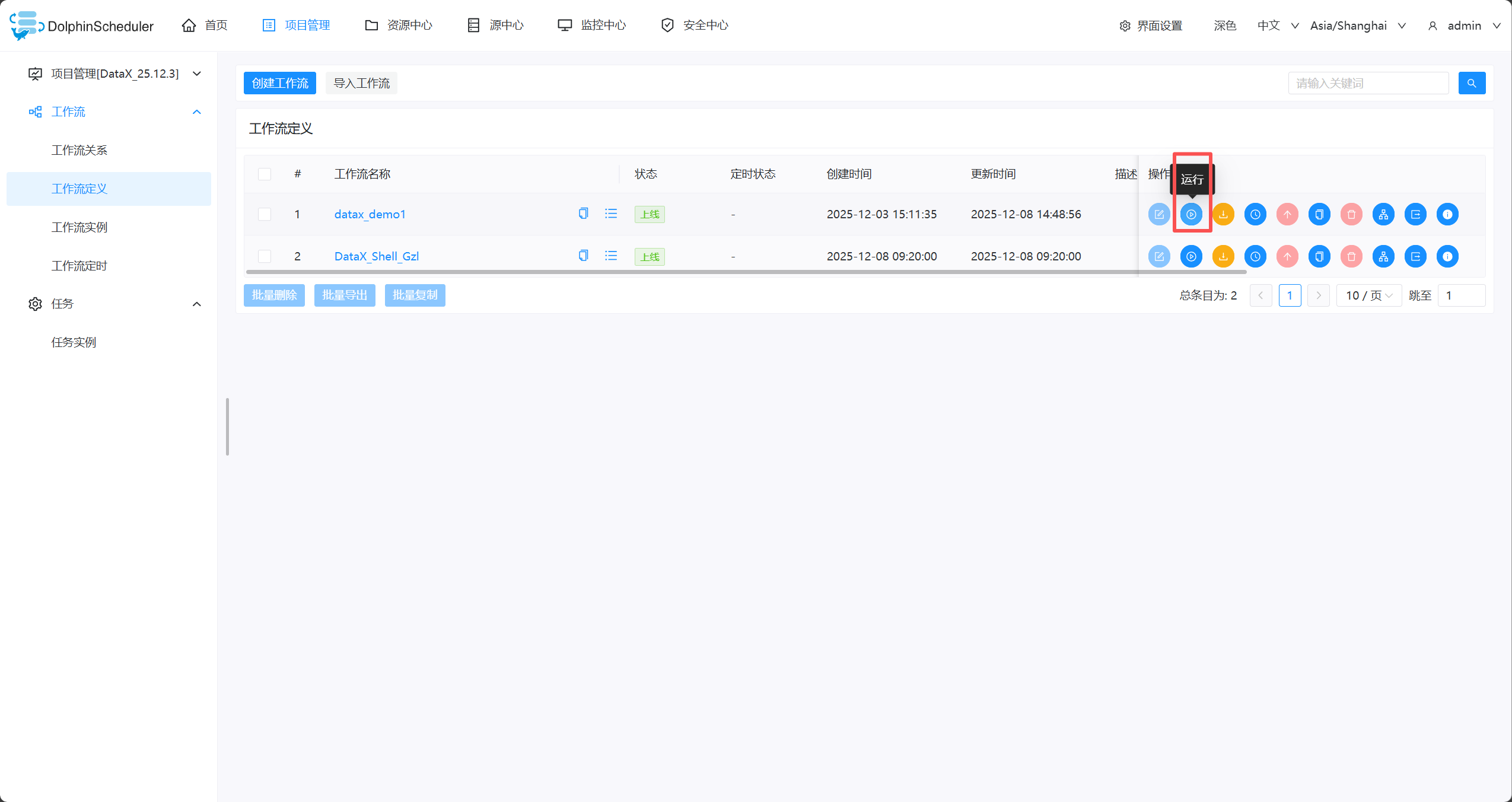
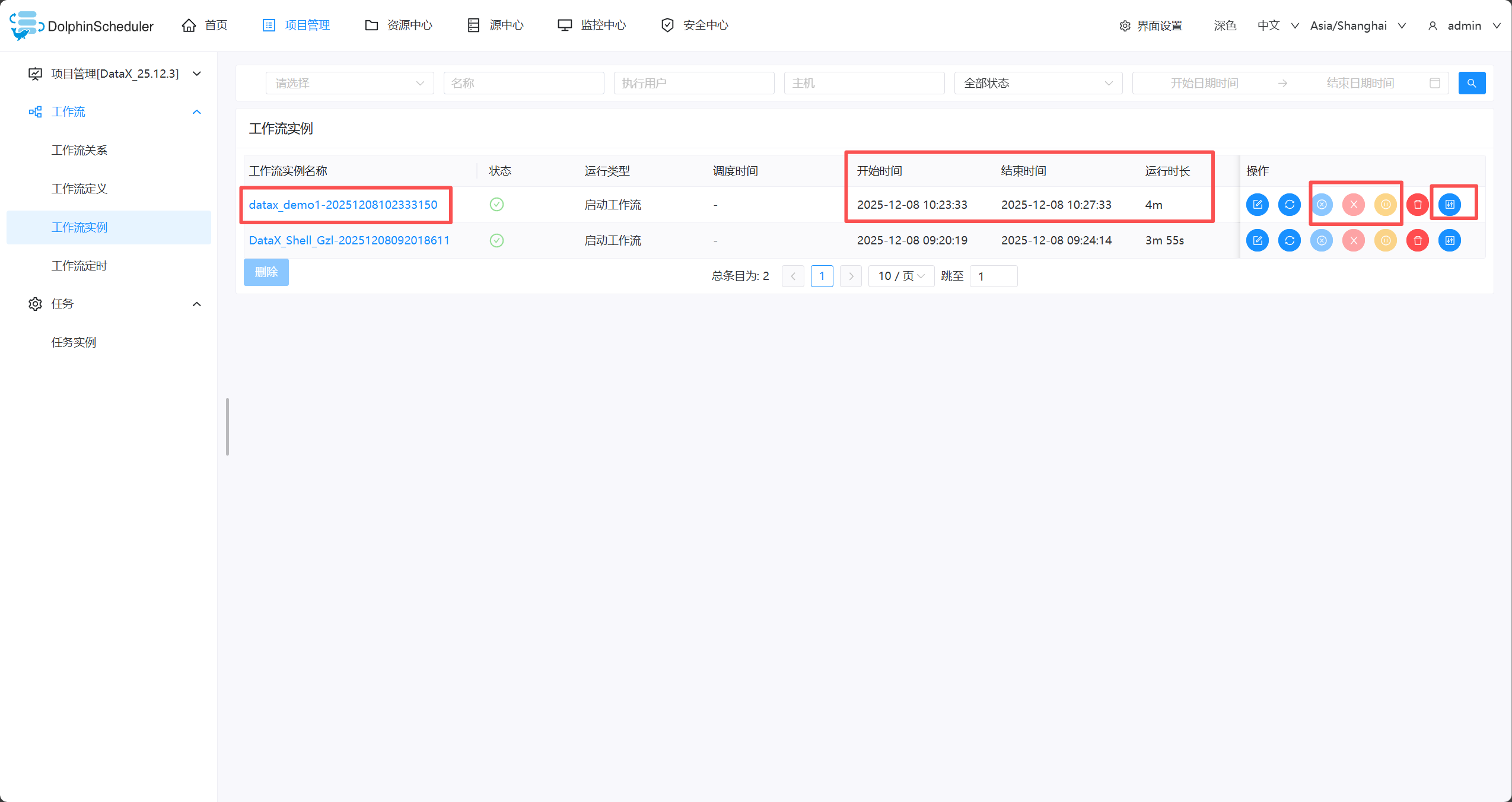
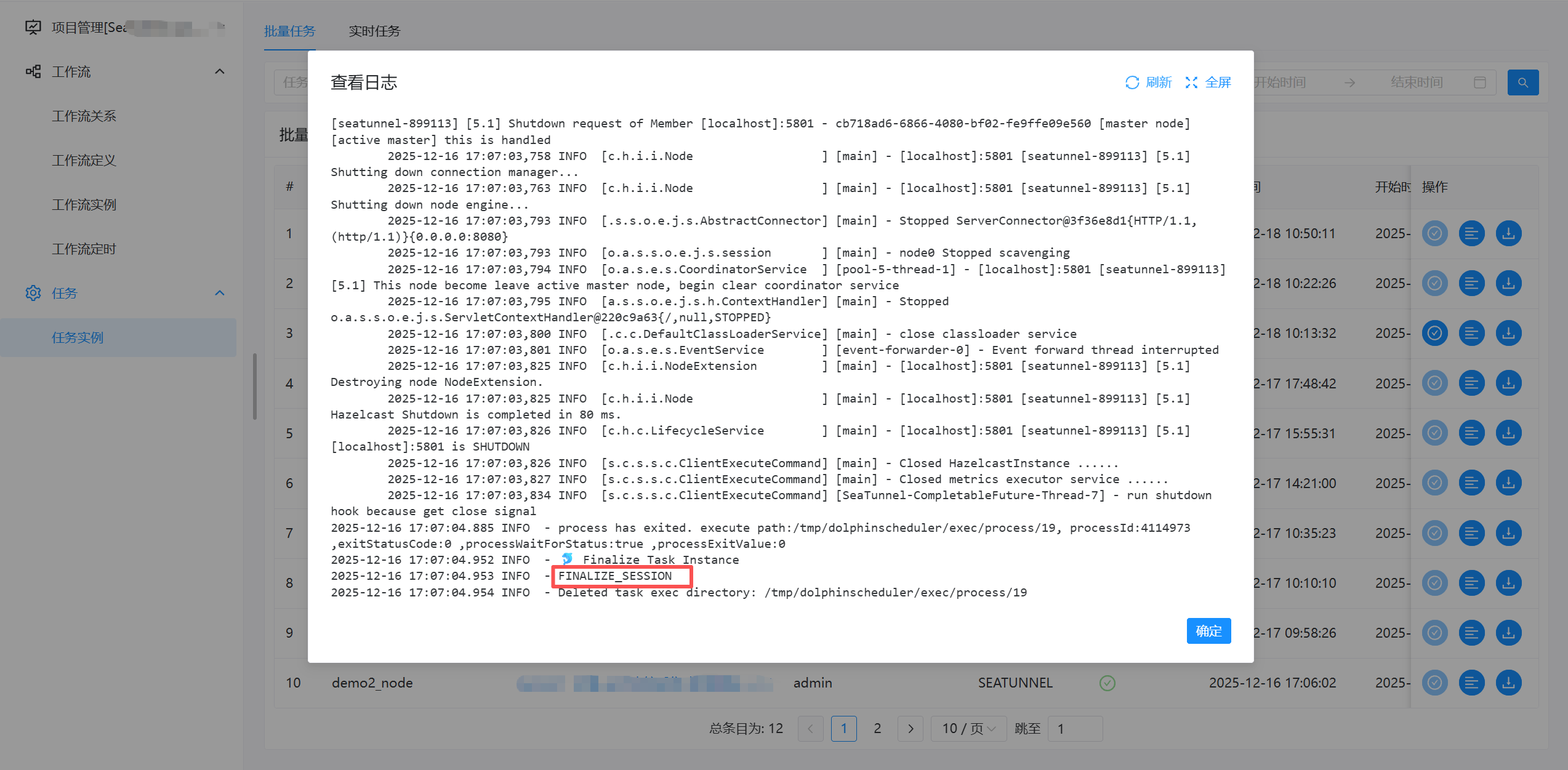
- 查看任务、日志
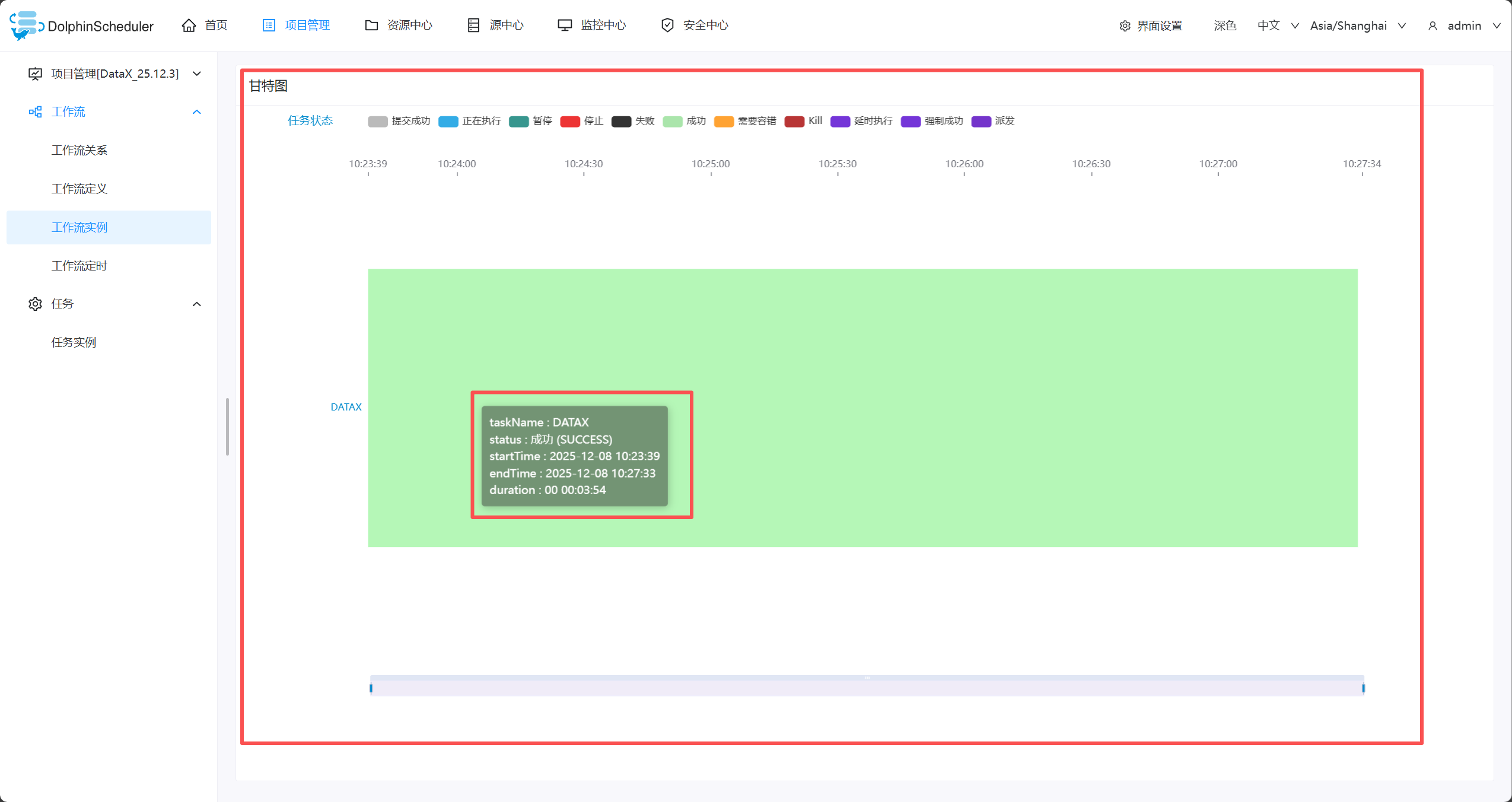
- 点击“甘特图”,查看简单的执行日志
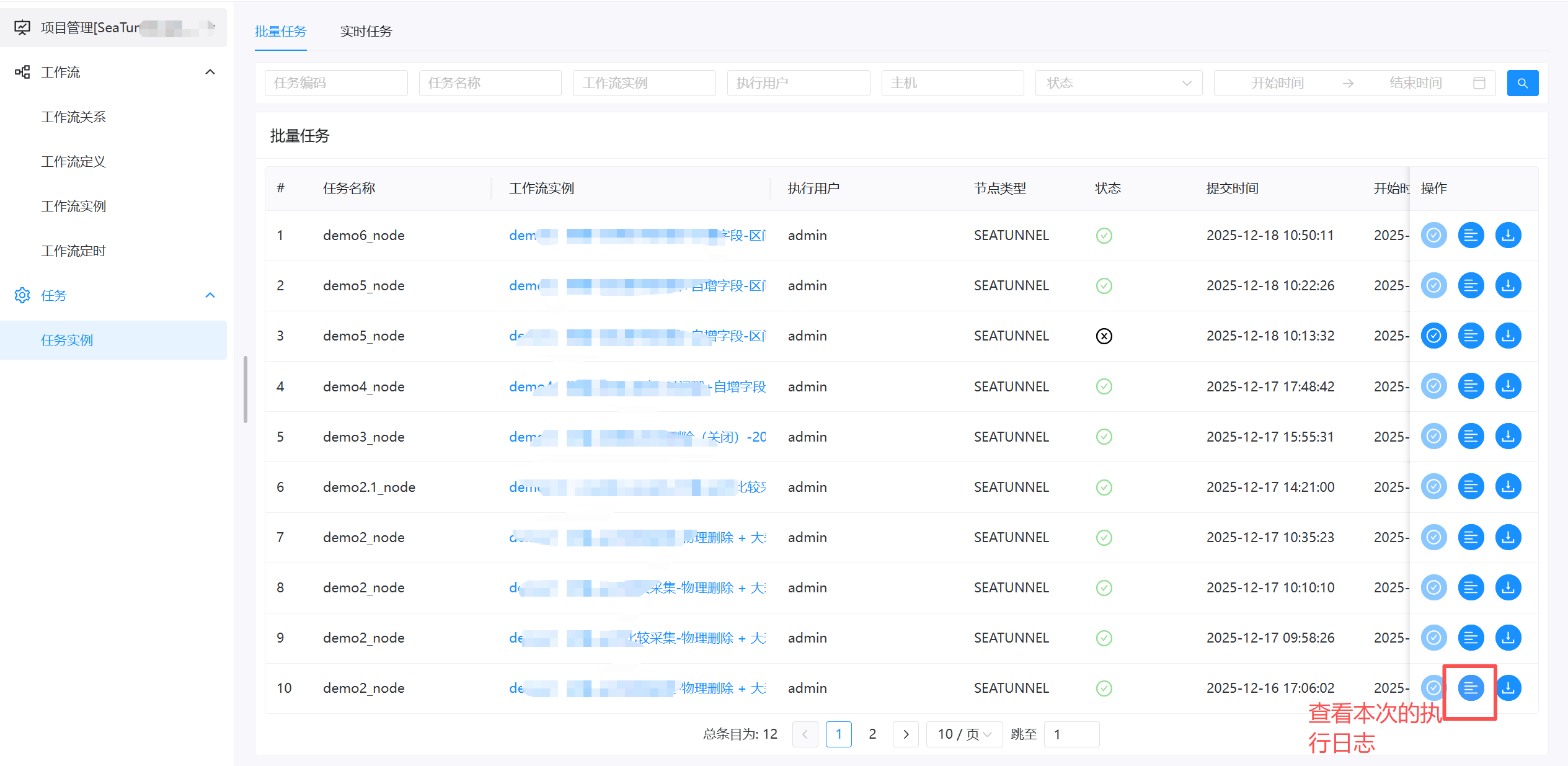
- 最后查看dolphin的日志、或者目标表是否抽取成功
三、海豚调度(DolphinScheduler)+ SeaTunnel_2.3.12 的DEMO
1、创建项目、环境变量
-
创建项目:见一、3、
-
环境变量
# 1. SeaTunnel安装主目录 (必须)
export SEATUNNEL_HOME=/……/seatunnel/seatunnel-2.3.12
# 2. Java环境 (必须,需与SeaTunnel版本兼容)
export JAVA_HOME=/……/jdk/jdk1.8.0_202
# 3. 将SeaTunnel的执行命令加入系统路径 (建议)
export PATH=$JAVA_HOME/bin:$SEATUNNEL_HOME/bin:$PATH
# 4. 自定义Connector目录 (可选,如需使用额外插件)
# export SEATUNNEL_CONNECTOR_HOME=$SEATUNNEL_HOME/connectors
# 5. 可根据需要调整JVM参数 (可选)
# export SEATUNNEL_JAVA_OPTS="-Xms4G -Xmx4G"
2、进入项目-工作流定义
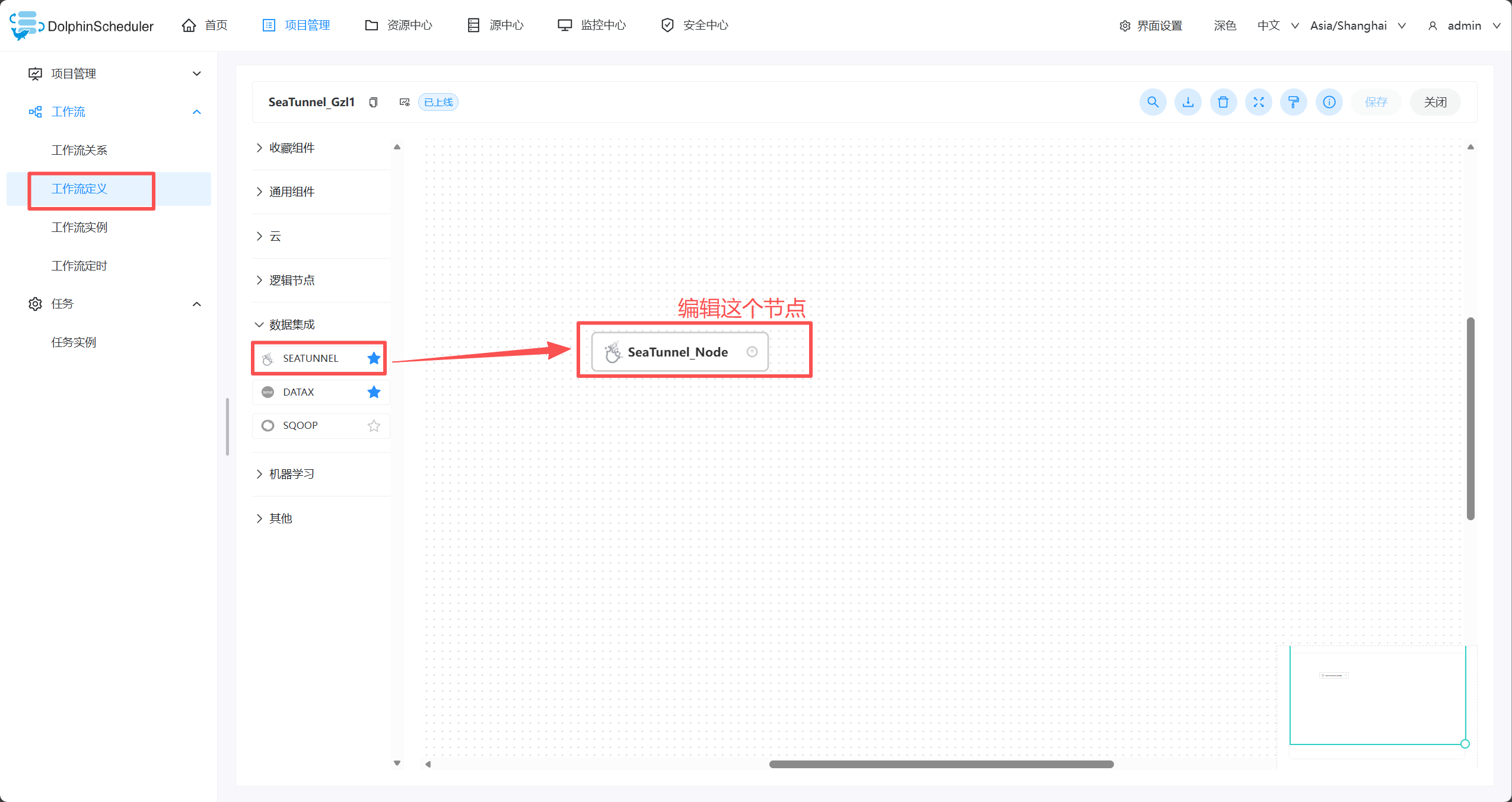
- 编辑seatunnel的节点
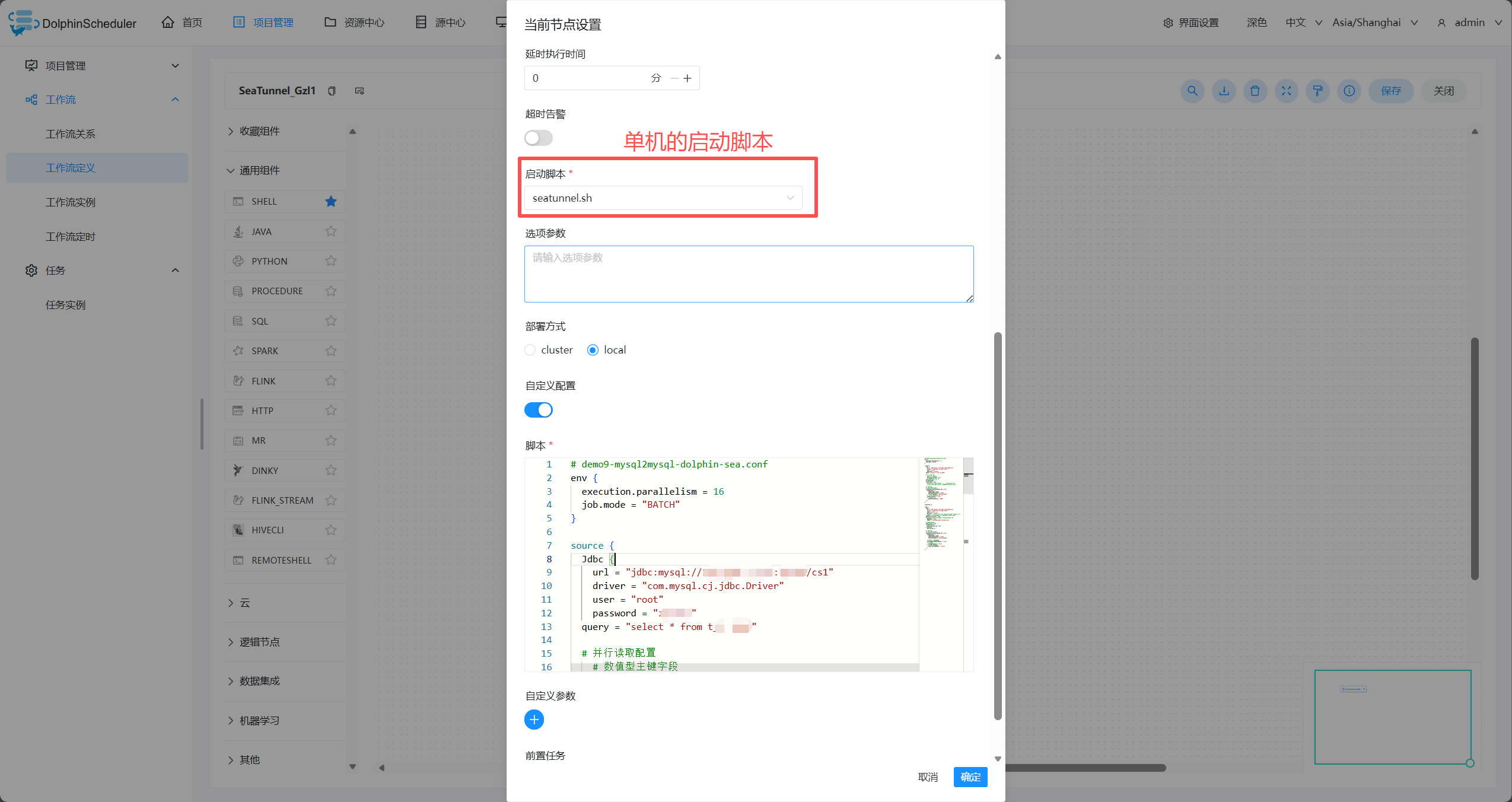
- seatunnel的conf
# demo9-mysql2mysql-dolphin-sea.conf
env {
execution.parallelism = 16
job.mode = "BATCH"
}
source {
Jdbc {
url = "jdbc:mysql://ip:port/cs1"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "zysoft"
query = "select * from t_8_100w"
# 并行读取配置
# 数值型主键字段
partition_column = "id"
# 分片数,匹配并行度
partition_num = 16
# 批量提交数
fetch_size = 5000
# partition_lower_bound = 1 # 可选:起始ID
# partition_upper_bound = 1000000 # 可选:结束ID
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 使用游标提高大结果集性能
useCursorFetch = "true"
# 每次获取行数
defaultFetchSize = "5000"
}
}
}
transform {}
sink {
jdbc {
url = "jdbc:mysql://ip:port/cs2"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "zysoft"
# query = "insert into test_table(name,age) values(?,?)"
# 生成自动插入sql。如果目标库没有表,也会自动建表
generate_sink_sql = true
# generate_sink_sql=true。所以:database必须要
database = cs2
table = "t_8_100w_import_dolphin_sea"
# 批量写入条数
batch_size = 5000
# 批次提交间隔
batch_interval_ms = 500
# 重试次数
max_retries = 3
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 关键:启用批量重写
rewriteBatchedStatements = "true"
# 启用压缩
useCompression = "true"
# 禁用服务端预处理
useServerPrepStmts = "false"
}
}
}
-
运行、查看日志同datax
-
最后查看dolphin的日志、或者目标表是否抽取成功


 浙公网安备 33010602011771号
浙公网安备 33010602011771号