
(未完待续……)DataX3.0部署、演示Demo
1、部署
拉取代码,自己编译(不用全量包,也不需要全量包)
github源码:
https://github.com/alibaba/DataX
打包好了的:
https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202309/datax.tar.gz
需要的运行环境
Linux
JDK(1.8以上,推荐1.8)
Python(2或3都可以)
Apache Maven 3.x (Compile DataX)
使用源码Maven打包
- 嫌麻烦的,可以直接下打包好了的
- 这一步,可以去除自己不要Reader和Writer,实际不需要的去除后,可以减小包的大小
- 步奏
1、datax-all的pom.xml中注释不要的Reader和Writer
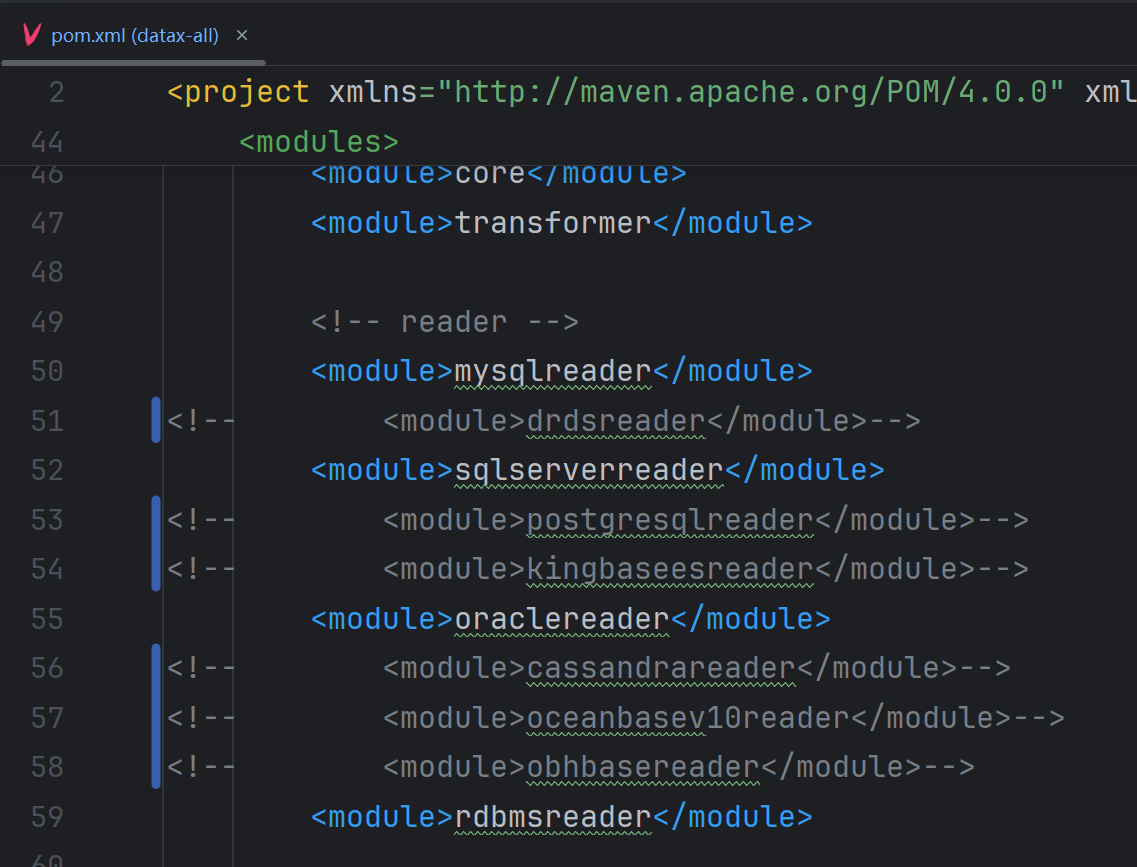
2、修改达梦数据库为达梦8(默认是7)
rdbmsreader、rdbmswriter的pom.xml修改
<!-- dm7 dm8 driver -->
<!-- <dependency>-->
<!-- <groupId>com.dameng</groupId>-->
<!-- <artifactId>Dm7JdbcDriver17</artifactId>-->
<!-- <version>7.6.0.142</version>-->
<!-- </dependency>-->
<dependency>
<groupId>com.dameng</groupId>
<artifactId>Dm8JdbcDriver18</artifactId>
<version>8.1.1.49</version>
</dependency>
3、打包
- 可以在Linux服务器(需要安Maven)
cd {DataX_source_code_home}
//打包命令
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
-
也可以在本地idea中打包(我用的):
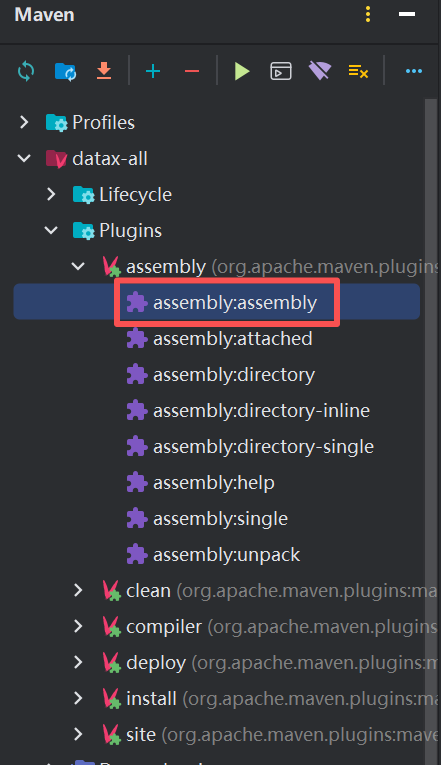
-
打包完成
-
项目地址下:
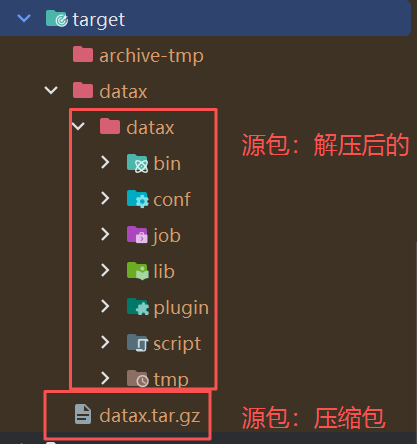
-
上传“解压后的”到服务器即可
2、数据准备、datax核心组件介绍
数据准备(mysql)
- 建表
CREATE TABLE cs1.`t_8_100w` (
`id` bigint NOT NULL COMMENT '主键',
`name` varchar(2000) NULL COMMENT '名字',
`sex` int null COMMENT '性别:1男;2女',
`decimal_f` decimal(32, 6) NULL COMMENT '大数字',
`phone_number` varchar(20) DEFAULT '13456780000' COMMENT '电话',
`age` varchar(255) NULL COMMENT '字符串年龄转数字',
`create_time` timestamp DEFAULT CURRENT_TIMESTAMP COMMENT '新增时间',
`description` longtext NULL COMMENT '大文本',
`address` varchar(2000) NULL COMMENT '空地址转默认值:未知',
PRIMARY KEY (`id`)
);
- 数据准备1(存储过程)——会很卡(别用)
DELIMITER $$
CREATE PROCEDURE InsertMultipleRows2()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE batch_size INT DEFAULT 1000;
DECLARE description_text LONGTEXT;
DECLARE address_text VARCHAR(255);
START TRANSACTION;
WHILE i < 1000000 DO
-- 生成10KB的大文本描述
SET description_text = REPEAT(CONCAT('DataX测试大文本字段_编号', i, '_重复内容_'), 400);
-- 根据i%2生成地址:等于0生成"地址X",不等于0为NULL
IF i % 2 = 0 THEN
SET address_text = CONCAT('地址', i);
ELSE
SET address_text = NULL;
END IF;
INSERT INTO t_8_100w (`id`, `name`, `decimal_f`, `age`, `description`, `address`)
VALUES (
i,
CONCAT('名字', i),
i + 0.000001,
ROUND((RAND() * 12) + 18),
description_text,
address_text
);
SET i = i + 1;
-- 批量提交
IF i % batch_size = 0 THEN
COMMIT;
START TRANSACTION;
SELECT CONCAT('已插入: ', i, ' 条记录') AS progress;
END IF;
END WHILE;
COMMIT;
SELECT '数据插入完成,总计100万条记录' AS final_result;
END$$
DELIMITER ;
CALL InsertMultipleRows2();
- 数据准备2(批量提交,减小文本大小)
-- 先生成存储过程
DELIMITER $$
CREATE PROCEDURE InsertMultipleRows_Batch(
IN start_id INT, -- 起始ID
IN end_id INT, -- 结束ID
IN batch_size INT -- 批次大小
)
BEGIN
DECLARE i INT DEFAULT start_id;
DECLARE description_text LONGTEXT;
DECLARE address_text VARCHAR(255);
DECLARE sex_text INT;
DECLARE total_to_insert INT;
SET total_to_insert = end_id - start_id;
-- 开始事务
START TRANSACTION;
WHILE i < end_id DO
-- 生成精确的1KB文本
SET description_text = REPEAT(CONCAT('DataX_Test_Text_', i, '_ABCDEFGHIJKLMN_'), 41);
-- 根据i%2生成地址
IF i % 2 = 0 THEN
SET address_text = CONCAT('地址', i);
SET sex_text = 1;
ELSE
SET address_text = NULL;
SET sex_text = 2;
END IF;
-- 插入数据
INSERT INTO t_8_100w (`id`, `name`, `sex`, `decimal_f`, `age`, `description`, `address`)
VALUES (
i,
CONCAT('名字', i),
sex_text,
i + 0.000001,
ROUND((RAND() * 12) + 18),
description_text,
address_text
);
SET i = i + 1;
-- 每batch_size条提交一次
IF i % batch_size = 0 OR i = end_id THEN
COMMIT;
IF i < end_id THEN
START TRANSACTION;
END IF;
-- 显示进度
IF i % 50000 = 0 OR i = end_id THEN
SELECT CONCAT('批次 ', start_id, '-', end_id, ': 已插入 ', i - start_id, ' / ', total_to_insert, ' 条记录') AS progress;
END IF;
END IF;
END WHILE;
SELECT CONCAT('批次完成! ID范围: ', start_id, ' 到 ', end_id - 1, ' (共', total_to_insert, '条)') AS batch_complete;
END$$
DELIMITER ;
-- 再分批次执行
-- 测试1万条(如果能执行,再分批执行后面的)
CALL InsertMultipleRows_Batch(0, 10000, 500);
-- 每10万条创建一次,分批执行
CALL InsertMultipleRows_Batch(10000, 100000, 500);
CALL InsertMultipleRows_Batch(100000, 200000, 500);
CALL InsertMultipleRows_Batch(200000, 300000, 500);
CALL InsertMultipleRows_Batch(300000, 400000, 500);
CALL InsertMultipleRows_Batch(400000, 500000, 500);
CALL InsertMultipleRows_Batch(500000, 600000, 500);
CALL InsertMultipleRows_Batch(600000, 700000, 500);
CALL InsertMultipleRows_Batch(700000, 800000, 500);
CALL InsertMultipleRows_Batch(800000, 900000, 500);
CALL InsertMultipleRows_Batch(900000, 1000000, 500);
- 数据准备3:连表用sql采集
-- 建表
CREATE TABLE cs1.`t_8_join_100w` (
`id` bigint NOT NULL COMMENT '主键',
`name` varchar(2000) NULL COMMENT '名字',
`sex` int null COMMENT '性别:1男;2女',
`decimal_f` decimal(32, 6) NULL COMMENT '大数字',
`phone_number` varchar(20) DEFAULT '13456780000' COMMENT '电话',
`age` varchar(255) NULL COMMENT '字符串年龄转数字',
`create_time` timestamp DEFAULT CURRENT_TIMESTAMP COMMENT '新增时间',
`description` longtext NULL COMMENT '大文本',
`address` varchar(2000) NULL COMMENT '空地址转默认值:未知',
PRIMARY KEY (`id`)
);
-- 新增存储过程
DELIMITER $$
CREATE PROCEDURE InsertMultipleRows_Batch_Join(
IN start_id INT, -- 起始ID
IN end_id INT, -- 结束ID
IN batch_size INT -- 批次大小
)
BEGIN
DECLARE i INT DEFAULT start_id;
DECLARE description_text LONGTEXT;
DECLARE address_text VARCHAR(255);
DECLARE sex_text INT;
DECLARE total_to_insert INT;
SET total_to_insert = end_id - start_id;
-- 开始事务
START TRANSACTION;
WHILE i < end_id DO
-- 生成精确的1KB文本
SET description_text = REPEAT(CONCAT('JOIN_JOIN_DataX_Test_Text_', i, '_ABCDEFGHIJKLMN_'), 41);
-- 根据i%2生成地址
IF i % 2 = 0 THEN
SET address_text = CONCAT('JOIN_地址', i);
SET sex_text = 1;
ELSE
SET address_text = NULL;
SET sex_text = 2;
END IF;
-- 插入数据
INSERT INTO t_8_join_100w (`id`, `name`, `sex`, `decimal_f`, `age`, `description`, `address`)
VALUES (
i,
CONCAT('JOIN名字', i),
sex_text,
i + 0.000001,
ROUND((RAND() * 12) + 18),
description_text,
address_text
);
SET i = i + 1;
-- 每batch_size条提交一次
IF i % batch_size = 0 OR i = end_id THEN
COMMIT;
IF i < end_id THEN
START TRANSACTION;
END IF;
-- 显示进度
IF i % 50000 = 0 OR i = end_id THEN
SELECT CONCAT('批次 ', start_id, '-', end_id, ': 已插入 ', i - start_id, ' / ', total_to_insert, ' 条记录') AS progress;
END IF;
END IF;
END WHILE;
SELECT CONCAT('批次完成! ID范围: ', start_id, ' 到 ', end_id - 1, ' (共', total_to_insert, '条)') AS batch_complete;
END$$
DELIMITER ;
-- 测试1万条
CALL InsertMultipleRows_Batch_Join(0, 10000, 500);
-- 每10万条创建一次,分批执行
CALL InsertMultipleRows_Batch_Join(10000, 100000, 1000);
CALL InsertMultipleRows_Batch_Join(100000, 200000, 1000);
CALL InsertMultipleRows_Batch_Join(200000, 300000, 1000);
CALL InsertMultipleRows_Batch_Join(300000, 400000, 1000);
CALL InsertMultipleRows_Batch_Join(400000, 500000, 1000);
CALL InsertMultipleRows_Batch_Join(500000, 600000, 1000);
CALL InsertMultipleRows_Batch_Join(600000, 700000, 1000);
CALL InsertMultipleRows_Batch_Join(700000, 800000, 1000);
CALL InsertMultipleRows_Batch_Join(800000, 900000, 1000);
CALL InsertMultipleRows_Batch_Join(900000, 1000000, 1000);
采集模式说明
1Reader的querySql和table+column配置
- querySql和table+column互斥,不能同时存在
在 DataX 的 Reader 配置中:
使用 querySql 时:无需配置 column。DataX 会自动识别 SQL 查询结果的列信息。
使用 table + column 时:不能配置 querySql。你需要通过 column 数组明确指定要读取的列。
这是两种互斥的配置模式,选择一种即可。querySql 方式更灵活,可以自由编写带条件、关联查询的 SQL 来实现增量采集。
2writer模块,多种写入模式:writeMode
DataX Writer支持多种写入模式,具体包括Insert、Replace和Update三种模式,适用于不同场景的数据同步需求。
-
支持通用 writeMode (insert/replace/update) 的主要是 MySQL 及其协议兼容的数据库(如 TiDB、PolarDB)。
-
不支持或原生不支持 writeMode的数据
SqlServer、Oracle、PostgreSQL、DB2
大多数NoSQL数据库 (如 MongoDB、HBase 等的写入插件)
各类文件系统 (如 HDFS、FTP 等 Writer) -
writeMode 的本质,是 DataX 将“更新还是插入”的逻辑翻译成对应数据库的 SQL 方言,然后交由数据库自身去执行和处理冲突。
-
DataX 目前仅支持replace,update 或 insert 方式

插入模式(insert)
特点:直接插入新记录,若目标表存在主键或唯一索引冲突则插入失败。
对应SQL:INSERT INTO ...
适用场景:确保数据唯一性时使用,适合初次导入全新数据。
替换模式(replace)
特点:若目标表存在主键或唯一索引冲突,用新数据完全替换旧数据;否则直接插入。
对应SQL:REPLACE INTO ...
适用场景:需要覆盖旧数据的全量同步,避免手动清空表。
更新模式(update)
特点:仅在MySQL等支持ON DUPLICATE KEY UPDATE的数据库中生效,遇到重复键时更新字段。
对应SQL:INSERT INTO ... ON DUPLICATE KEY UPDATE ...
这意味着,DataX会生成类似 UPDATE target_table SET ... WHERE pk=? 的语句。只有当目标表中主键已存在时,数据才会被更新;如果主键不存在,这条记录会被静默丢弃。
==这种方式会更新表中已存在的数据。==
==不能用来做增量==
限制:Hive等不支持此模式,直接写文件。
其他注意事项
Hive写入:不支持上述模式,仅通过文件写入。
需要抽取的json的job准备
示例
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader", # 读取端
"parameter": {
"column": [], # 需要同步的列 (* 表示所有的列)
"connection": [
{
"jdbcUrl": [], # 连接信息
"table": [] # 连接表
}
],
"password": "", # 连接用户
"username": "", # 连接密码
"where": "" # 描述筛选条件
}
},
"writer": {
"name": "mysqlwriter", # 写入端
"parameter": {
"column": [], # 需要同步的列
"connection": [
{
"jdbcUrl": "", # 连接信息
"table": [] # 连接表
}
],
"password": "", # 连接密码
"preSql": [], # 同步前. 要做的事
"session": [],
"username": "", # 连接用户
"writeMode": "" # 操作类型
}
},
"transformer":[]
}
],
"setting": {
"speed": {
"channel": "" # 指定并发数
}
}
}
}
实例采集
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","name"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://ip:端口/数据库"],
"table": ["t_01"]
}
],
"password": "密码",
"username": "root",
"where": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["id2","name2"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://ip:端口/数据库",
"table": ["t_02"]
}
],
"password": "密码",
"preSql": [],
"session": [],
"username": "root",
"writeMode": "insert"
}
},
"transformer":[] //值转换、清洗工具:用于在数据传输过程中对数据进行中间处理和转换
}
],
"setting": {
"speed": {
"channel": "6"
}
}
}
}
执行job
- python2:python。python3要加3:python3
python3 /data/datax/bin/datax.py /data/datax/job/one.json
python3 /data/datax/bin/datax.py /data/datax/job/my-demo1-mysql2mysql.json
Transformer介绍
- 用于在数据传输过程中对数据进行中间处理和转换
- 不同DataX版本的差异
DataX 3.0+
组件名称带dx_前缀:dx_filter、dx_replace、dx_groovy
参数格式更加严格
DataX 2.0及以下
组件名称无前缀:filter、replace、groovy
参数相对宽松
1. FilterTransformer (dx_filter) - 数据过滤器
作用:根据条件过滤数据记录
正确用法:
{
"name": "dx_filter",
"parameter": {
"columnIndex": 5, // 要过滤的字段索引
"paras": ["<=", "25"] // [操作符, 比较值]
}
}
支持的操作符:
>、>=、<、<=、==、!=
注意:符合条件的数据会被保留,不符合的被丢弃
示例:
// 保留age>25的记录
{"name": "dx_filter", "parameter": {"columnIndex": 5, "paras": [">", "25"]}}
// 保留gender=="男"的记录
{"name": "dx_filter", "parameter": {"columnIndex": 2, "paras": ["==", "男"]}}
2. ReplaceTransformer (dx_replace) - 字符串替换器
作用:按位置替换字符串内容
用法:
{
"name": "dx_replace",
"parameter": {
"columnIndex": 4, // 要替换的字段索引
"paras": ["3", "4", "****"] // [开始位置, 替换长度, 替换内容]
}
}
示例:
// 手机号脱敏:从第3位开始替换4个字符为****
{"name": "dx_replace", "parameter": {"columnIndex": 4, "paras": ["3", "4", "****"]}}
// 身份证号脱敏:保留前6后4
{"name": "dx_replace", "parameter": {"columnIndex": 3, "paras": ["6", "8", "********"]}}
3. SubstrTransformer (dx_substr) - 字符串截取器
作用:截取字符串的指定部分
用法:
{
"name": "dx_substr",
"parameter": {
"columnIndex": 1,
"paras": ["0", "5"] // [开始位置, 截取长度]
}
}
示例:
// 截取前5个字符
{"name": "dx_substr", "parameter": {"columnIndex": 1, "paras": ["0", "5"]}}
// 截取第2到第6个字符
{"name": "dx_substr", "parameter": {"columnIndex": 1, "paras": ["1", "5"]}}
4. PadTransformer (dx_pad) - 字符串填充器
作用:对字符串进行左填充或右填充
用法:
{
"name": "dx_pad",
"parameter": {
"columnIndex": 1,
"paras": ["0", "10", "l"] // [填充字符, 目标长度, 方向(l-左/r-右)]
}
}
示例:
// 左填充0到10位
{"name": "dx_pad", "parameter": {"columnIndex": 1, "paras": ["0", "10", "l"]}}
// 右填充空格到20位
{"name": "dx_pad", "parameter": {"columnIndex": 1, "paras": [" ", "20", "r"]}}
5. GroovyTransformer (dx_groovy) - Groovy脚本处理器
作用:执行自定义Groovy脚本,功能最强大
用法:
{
"name": "dx_groovy",
"parameter": {
"code": "// Groovy脚本代码\nif (record.getColumn(2) != null) {\n String sex = record.getColumn(2).asString();\n if (\"1\".equals(sex)) {\n record.setColumn(2, new StringColumn(\"男\"));\n } else if (\"2\".equals(sex)) {\n record.setColumn(2, new StringColumn(\"女\"));\n }\n}\nreturn record;"
}
}
常用场景:
复杂条件判断
多字段关联处理
数据类型转换
业务规则验证
6. DigestTransformer - 数据摘要生成器
作用:生成数据的摘要信息(如MD5、SHA等)
用法:
{
"name": "dx_digest",
"parameter": {
"columnIndex": 1,
"paras": ["MD5"] // 摘要算法:MD5, SHA-1, SHA-256等
}
}
示例:
// 对姓名字段生成MD5摘要
{"name": "dx_digest", "parameter": {"columnIndex": 1, "paras": ["MD5"]}}
// 对多个字段组合生成摘要
{
"name": "dx_groovy",
"parameter": {
"code": "String combined = record.getColumn(1).asString() + record.getColumn(2).asString();\nString md5 = org.apache.commons.codec.digest.DigestUtils.md5Hex(combined);\nrecord.setColumn(6, new StringColumn(md5));\nreturn record;"
}
}
完整的transformer
"transformer": [
// 1. 数据过滤:只保留age>25的记录
{
"name": "dx_filter",
"parameter": {"columnIndex": 5, "paras": [">", "25"]}
},
// 2. 手机号脱敏
{
"name": "dx_replace",
"parameter": {"columnIndex": 4, "paras": ["3", "4", "****"]}
},
// 3. 姓名截取前10位
{
"name": "dx_substr",
"parameter": {"columnIndex": 1, "paras": ["0", "10"]}
},
// 4. 用户ID左补0到8位
{
"name": "dx_pad",
"parameter": {"columnIndex": 0, "paras": ["0", "8", "l"]}
},
// 5. 复杂业务逻辑:性别转换 + 地址默认值
{
"name": "dx_groovy",
"parameter": {
"code": "// 性别转换\nString sex = record.getColumn(2)?.asString();\nif (\"1\".equals(sex)) record.setColumn(2, new StringColumn(\"男\"));\nelse if (\"2\".equals(sex)) record.setColumn(2, new StringColumn(\"女\"));\n\n// 地址默认值\nif (record.getColumn(8) == null || record.getColumn(8).asString()?.trim()?.isEmpty()) {\n record.setColumn(8, new StringColumn(\"未知\"));\n}\nreturn record;"
}
},
// 6. 生成数据MD5指纹
{
"name": "dx_digest",
"parameter": {"columnIndex": 1, "paras": ["MD5"]}
}
]
2025-11-29 16:44:11.744 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 1 | 1 | 0 | 0.026s | 0.026s | 0.000s
PS Scavenge | 123 | 5 | 0 | 0.453s | 0.030s | 0.000s
2025-11-29 16:44:11.744 [job-0] INFO JobContainer - PerfTrace not enable!
2025-11-29 16:44:11.744 [job-0] INFO StandAloneJobContainerCommunicator - Total 1000000 records, 1606055605 bytes | Speed 156.53KB/s, 99 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 7,759.714s | All Task WaitReaderTime 786.048s | Percentage 100.00%
2025-11-29 16:44:11.745 [job-0] INFO JobContainer -
任务启动时刻 : 2025-11-29 13:57:10
任务结束时刻 : 2025-11-29 16:44:11
任务总计耗时 : 10021s
任务平均流量 : 156.53KB/s
记录写入速度 : 99rec/s
读出记录总数 : 1000000
读写失败总数 : 0
3、DEMO
3.1、demo1:
3.5、demo:全量采集
全量采集定义
我理解的:
我理解的全量采集,比如数据是:
id name
1 11
2 22
第一次全量采集两条
第二次全量采集还是两条
目标数据变成
id name
1 11
2 22
1 11
2 22
在实际的数据中台或ETL工具中,这样是错的。这说明同步逻辑出现了严重的错误,通常被称为“数据重复”或“数据爆炸”,是必须避免的。
正确的全量采集(业界标准)
全量采集的目标是 “使目标端成为源端在某个时刻的精确副本”。基于上述例子,正确过程应该是:
源表数据始终为:
| id | name |
|---|---|
| 1 | 11 |
| 2 | 22 |
目标表的正确变化:
- 第一次全量同步后:目标表与源表完全一致。
id name 1 11 2 22 - 第二次全量同步后:目标表仍然与源表完全一致,数据没有变化,也没有翻倍。
id name 1 11 2 22
常见方案对比
| 方案 | 核心逻辑 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 1. 清空重灌 (Truncate & Insert) | TRUNCATE 目标表 → 全量 INSERT |
数据强一致、逻辑简单、性能好(全量新数据) | 无版本回溯、操作风险高(中断则数据为空) | 维度表、码表、静态表、可接受短暂空窗的业务 |
| 2. 覆盖更新 (Replace / Overwrite) | 使用 REPLACE INTO 或 MERGE 语句 |
数据强一致、可中断恢复(保留旧版本直至完成) | 需要数据库支持、可能产生锁影响查询 | 核心业务表、对一致性要求高的场景 |
| 3. 快照对比 (Snapshot & Sync) | 与目标表当前快照对比,只 INSERT 新、UPDATE 变、DELETE 删 |
保留历史、可追溯、对在线业务影响最小 | 逻辑最复杂、实现成本高、性能开销大(需对比) | 有审计或历史追溯要求的场景、大型事实表 |
-
全量采集方案对比与选择2
方案 核心配置 优点 缺点 / 注意事项 推荐场景 清空重灌 ”preSql”: [“TRUNCATE TABLE …”]逻辑绝对简单,结果强一致。 同步期间目标表为空,查询会失败,风险高。 静态维度表、测试环境、可接受停机维护的业务。 覆盖更新 ”writeMode”: “replace”通常单次操作完成,效率高。 依赖数据库支持(如MySQL)。SQL Server等数据库不支持此参数,需用 preSql/postSql模拟。生产环境首选(MySQL等支持时)。需要目标表有主键/唯一键。 原子切换 使用 preSql和postSql操作临时表,最后原子切换(如RENAME)。同步过程数据始终可用,安全性最高。 实现稍复杂,需要数据库支持原子操作。 对数据可用性要求极高的核心生产表。 结论:对于你的中台,可以优先实现“覆盖更新”(
replace),并为不支持该模式的数据库(如SQL Server)自动降级到“清空重灌”或“原子切换”模式。
行业内主流设计倾向
在主流的数据中台或数据同步产品(如阿里的DataWorks、AWS的DMS、开源SeaTunnel的某些模式)中,方案2(覆盖更新)通常是全量同步的推荐或默认选择,因为它兼顾了一致性、安全性和通用性。
- 首次运行:通常是全量插入。
- 后续全量运行:通过创建临时表/中间表(
_tmp后缀)来接收全量数据,数据就绪后,通过一个原子性的RENAME操作(或DELETE+INSERT在一个事务中)切换表,确保对下游查询的影响最小,且任务失败时原有数据不被破坏。
一个典型的原子化操作SQL示意如下:
BEGIN TRANSACTION;
-- 1. 将全量数据写入临时表
-- (此步骤由DataX完成,写入 `target_table_tmp`)
-- 2. 原子化切换:删除旧表数据,从临时表插入
TRUNCATE TABLE target_table;
INSERT INTO target_table SELECT * FROM target_table_tmp;
COMMIT;
DROP TABLE target_table_tmp;
- 直接建议
- 在设计中台系统时,全量同步的默认逻辑必须是 “覆盖” 。
- 如果追求简单和高效,且业务能接受同步期间表被清空的风险,选择 方案1(清空重灌)。
- 如果追求稳定和安全(这是生产环境的普遍需求),务必实现 方案2(覆盖更新) 的原子化版本,即 “写入临时表 → 原子切换” 模式。
- 如果业务要求追踪每一次变化,才需要考虑复杂的 方案3(快照对比)。
结论:在严谨的数据中台设计中,直接清空目标表再插入(无保护措施)是危险的。更稳健的做法是通过 临时表或原子操作 来确保在同步过程中,目标表始终有可用的数据(无论是旧版本还是新版本),实现平滑、安全的覆盖更新。
全量方式1:writer.preSql(“清空重灌”)
- 采集数据前执行了手工清空表:TRUNCATE TABLE t_8_100w_import_qxzh_ql
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": ["jdbc:mysql://ip:port/cs1"]
"querySql": ["select id,name as user_name,sex,decimal_f,phone_number,age,create_time,description,address from t_8_100w;"]
}
],
"password": "zysoft",
"username": "root",
"where": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"connection": [
{
"jdbcUrl": "jdbc:mysql://ip:port/cs2",
"table": ["t_8_100w_import_qxzh_ql"]
}
],
"column": [
"id",
"user_name",
"sex",
"decimal_f",
"phone_number",
"age",
"create_time",
"description",
"address"
],
"preSql": [
"TRUNCATE TABLE t_8_100w_import_qxzh_ql"
],
"password": "zysoft",
"session": [],
"username": "root",
"writeMode": "insert"
}
},
"transformer": [
{
"name": "dx_filter",
"parameter": {
"columnIndex": 5,
"paras": ["<=","25"]
}
},
{
"name": "dx_replace",
"parameter": {
"columnIndex": 4,
"paras": ["3", "4", "****"]
}
},
{
"name": "dx_groovy",
"parameter": {
"code": "// 性别转换\nif (record.getColumn(2) != null) {\n String sex = record.getColumn(2).asString();\n if (\"1\".equals(sex)) record.setColumn(2, new StringColumn(\"男\"));\n else if (\"2\".equals(sex)) record.setColumn(2, new StringColumn(\"女\"));\n}\n\n// 地址空值处理\nif (record.getColumn(8) == null || record.getColumn(8).asString() == null || record.getColumn(8).asString().trim().isEmpty()) {\n record.setColumn(8, new StringColumn(\"未知\"));\n}\n\nreturn record;"
}
}
]
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
全量方式2:writer.writeMode=replace (效率比全量方式1高)(覆盖更新)
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://ip:port/cs1"
],
"querySql": [
"select id,name as user_name,sex,decimal_f,phone_number,age,create_time,description,address from t_8_100w;"
]
}
],
"password": "zysoft",
"username": "root",
"where": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"connection": [
{
"jdbcUrl": "jdbc:mysql://ip:port/cs2",
"table": [
"t_8_100w_import_qxzh_ql"
]
}
],
"column": [
"id",
"user_name",
"sex",
"decimal_f",
"phone_number",
"age",
"create_time",
"description",
"address"
],
"preSql": [
],
"password": "zysoft",
"session": [
],
"username": "root",
"writeMode": "replace"
}
},
"transformer": [
{
"name": "dx_filter",
"parameter": {
"columnIndex": 5,
"paras": [
"<=",
"25"
]
}
},
{
"name": "dx_replace",
"parameter": {
"columnIndex": 4,
"paras": [
"3",
"4",
"****"
]
}
},
{
"name": "dx_groovy",
"parameter": {
"code": "// 性别转换\nif (record.getColumn(2) != null) {\n String sex = record.getColumn(2).asString();\n if (\"1\".equals(sex)) record.setColumn(2, new StringColumn(\"男\"));\n else if (\"2\".equals(sex)) record.setColumn(2, new StringColumn(\"女\"));\n}\n\n// 地址空值处理\nif (record.getColumn(8) == null || record.getColumn(8).asString() == null || record.getColumn(8).asString().trim().isEmpty()) {\n record.setColumn(8, new StringColumn(\"未知\"));\n}\n\nreturn record;"
}
}
]
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
、demo:增量采集
- 增量采集核心:在读取阶段就只读取增量部分,而不是读取全部数据后再过滤。
- 增量采集:transformer的dx_filter是用来过滤数据的,它是在读取数据之后,根据条件决定保留还是丢弃记录。但请注意,增量采集的核心是在读取阶段就只读取增量部分,而不是读取全部数据后再过滤。因为如果数据量很大,读取全部数据再过滤会导致性能问题。
- 增量方式:(核心:选择的字段,其核心是要求该字段的值具有可比较性和单调递增性)——(这个交给用户自己判断,数据中台不参与判断)
- 1有自增主键ID;让用户选择一个自增主键字段;
- 2无自增主键,时间戳增量;让用户选择一个时间戳字段;
- 3无自增主键,根据用户选择的具有可比较性和单调递增性字段进行增量采集。
- 增量能选择的字段类型:数值类型、日期时间类型
- 如果源表没有可做增量采集的字段:为源表增加一个时间戳字段(如
create_time、update_time),这是增量同步的黄金标准。- 基于时间戳(或严格递增的字段)的增量方式,是生产环境下唯一可靠、可扩展的方案。
demo:增量1:主键自增、时间戳、自增主键+时间戳混合方式
- 首先从目标库选择对于的字段的值查询出:max(主键)、max(时间)
- 再在sql中使用where条件过滤数据(不能用:reader.where:限制比较多)
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://ip:port/cs1"
],
"querySql": [
"select id,name as user_name,sex,decimal_f,phone_number,age,create_time,description,address from t_8_100w where id > 1000000 and create_time > '2025-12-01 13:28:51' order by id asc,create_time asc;"
]
}
],
"password": "zysoft",
"username": "root",
"where": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"connection": [
{
"jdbcUrl": "jdbc:mysql://ip:port/cs2",
"table": [
"t_8_100w_import_qxzh_zl"
]
}
],
"column": [
"id",
"user_name",
"sex",
"decimal_f",
"phone_number",
"age",
"create_time",
"description",
"address"
],
"preSql": [
],
"password": "zysoft",
"session": [
],
"username": "root",
"writeMode": "insert"
}
},
"transformer": [
{
"name": "dx_filter",
"parameter": {
"columnIndex": 5,
"paras": [
"<=",
"25"
]
}
},
{
"name": "dx_replace",
"parameter": {
"columnIndex": 4,
"paras": [
"3",
"4",
"****"
]
}
},
{
"name": "dx_groovy",
"parameter": {
"code": "// 性别转换\nif (record.getColumn(2) != null) {\n String sex = record.getColumn(2).asString();\n if (\"1\".equals(sex)) record.setColumn(2, new StringColumn(\"男\"));\n else if (\"2\".equals(sex)) record.setColumn(2, new StringColumn(\"女\"));\n}\n\n// 地址空值处理\nif (record.getColumn(8) == null || record.getColumn(8).asString() == null || record.getColumn(8).asString().trim().isEmpty()) {\n record.setColumn(8, new StringColumn(\"未知\"));\n}\n\nreturn record;"
}
}
]
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
demo、增量方式2:根据用户选择的具有 可比较性和单调递增性 字段进行增量采集
- 本质和第一种方式一样,不再演示


 浙公网安备 33010602011771号
浙公网安备 33010602011771号