
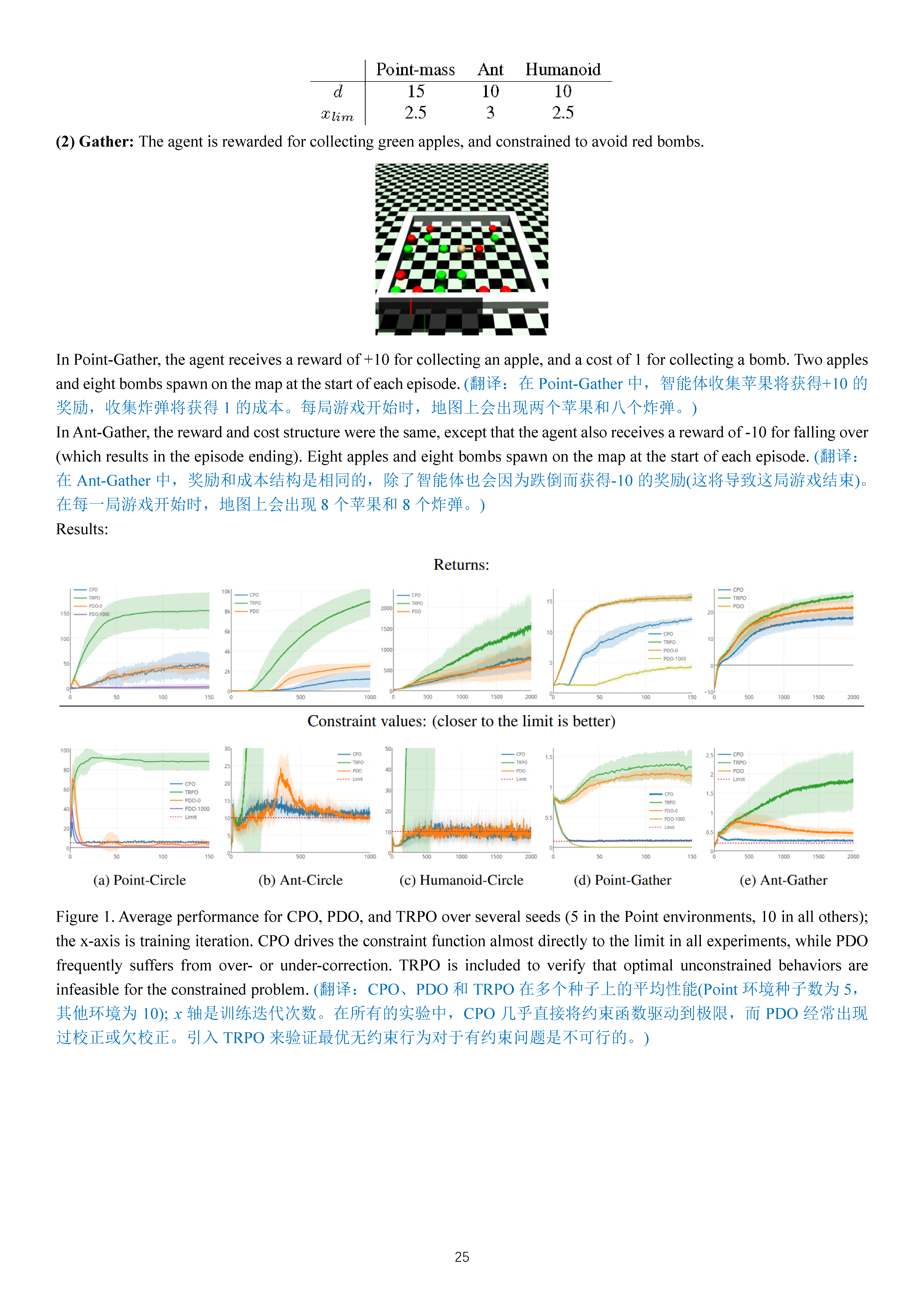
Safe RL——Constrained Policy Optimization (CPO)
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
这篇文章详细讲解Constrained Policy Optimization (CPO)的公式推导,文献来自于:Joshua Achiam, David Held, Aviv Tamar, Pieter Abbeel. Constrained Policy Optimization. Proceedings of the 34th International Conference on Machine Learning, PMLR 70:22-31, 2017.
























参考:
[1] Joshua Achiam, David Held, Aviv Tamar, Pieter Abbeel. Constrained Policy Optimization. Proceedings of the 34th International Conference on Machine Learning, PMLR 70:22-31, 2017. http://proceedings.mlr.press/v70/achiam17a/achiam17a.pdf
[2] 最优化——无约束最优化方法(Unconstrained Optimization Algorithms) -2.1 Armijo准则 -凯鲁嘎吉 - 博客园 https://www.cnblogs.com/kailugaji/p/16567557.html#_label3_0_1_0
[3] Safe RL(2): Constrained Policy Optimization - 南山张学有 https://zhuanlan.zhihu.com/p/408925264

 浙公网安备 33010602011771号
浙公网安备 33010602011771号