PDPU的运行
命令行:
sudo apt update
sudo apt install verilator
git clone --progress https://github.com/qleenju/PDPU.git
cd PDPU
verilator -Wall --cc sources/pdpu_top_pipelined.sv --exe testbench.cpp
./obj_dir/Vpdpu_top_pipelined
在同一级目录下
verilator -Wall --Wno-fatal --cc
cf_math_pkg.sv
pdpu_pkg.sv
lzc.sv
posit_decoder.sv
pdpu_top_pipelined.sv
--exe testbench.cpp
--top-module pdpu_top_pipelined
PDPU会有很多warning,如果在编译时,不加入“忽略warning的要求”,verilator会因为warning太多而终止运行
非常好,我们逐步分析:
✅ 一、你运行的命令行作用
make -j -C obj_dir/ -f Vpdpu_top_pipelined.mk Vpdpu_top_pipelined
该命令的含义:
| 部分 | 含义 |
|---|---|
make |
使用 GNU make 构建目标 |
-j |
并行执行编译,加快速度 |
-C obj_dir/ |
切换到 obj_dir/ 目录(Verilator 的默认输出目录)执行 make |
-f Vpdpu_top_pipelined.mk |
使用 verilator 自动生成的 makefile 文件 |
Vpdpu_top_pipelined |
编译目标,最终生成的仿真可执行程序名 |
✅ 二、图 1:构建开始,Verilator + g++ 正常工作
这张图显示:
g++正在编译多个.cpp文件(包括testbench.cpp,verilated.cpp等);- 表明你前面 verilator 的
.sv到.cpp转换阶段已经完成; - 进展正常,说明文件结构和 verilator 命令无误。
❌ 三、图 2:编译失败的关键错误
错误信息:
error: invalid types ‘IData {aka unsigned int}[int]’ for array subscript
top->operands_a[i] = 0x40;
🧨 原因:
Verilator 中多维数组(如 [N-1:0][7:0])在 C++ 中被映射成线性扁平展开结构,不能用二维 [][] 或 [] 的方式下标访问。
input logic [N-1:0][n_i-1:0] operands_a;
转为 C++ 是(伪代码):
VL_IN8(operands_a, N * n_i - 1, 0); // 实际是 32-bit 数据线性展开
✅ 四、解决办法:手动“拼”位宽值
你必须使用 .operands_a、.operands_b 的“打平”版本赋值,例如对 N=4、n_i=8,表示:
top->operands_a = (0x40 << 24) | (0x40 << 16) | (0x40 << 8) | 0x40;
top->operands_b = (0x40 << 24) | (0x40 << 16) | (0x40 << 8) | 0x40;
这样将 4 个 posit<8> 编码值(1.0 = 0x40)拼接到 32-bit 宽信号中。
✅ 推荐做法(更新 testbench.cpp)
替换你之前出错的代码:
// 将 {0x40, 0x40, 0x40, 0x40} 拼成 32-bit 宽值
top->operands_a = 0x40404040;
top->operands_b = 0x40404040;
然后重新编译:
make -j -C obj_dir/ -f Vpdpu_top_pipelined.mk Vpdpu_top_pipelined
./obj_dir/Vpdpu_top_pipelined
是否需要我为你完整生成一个可直接运行、无错误的 testbench.cpp?
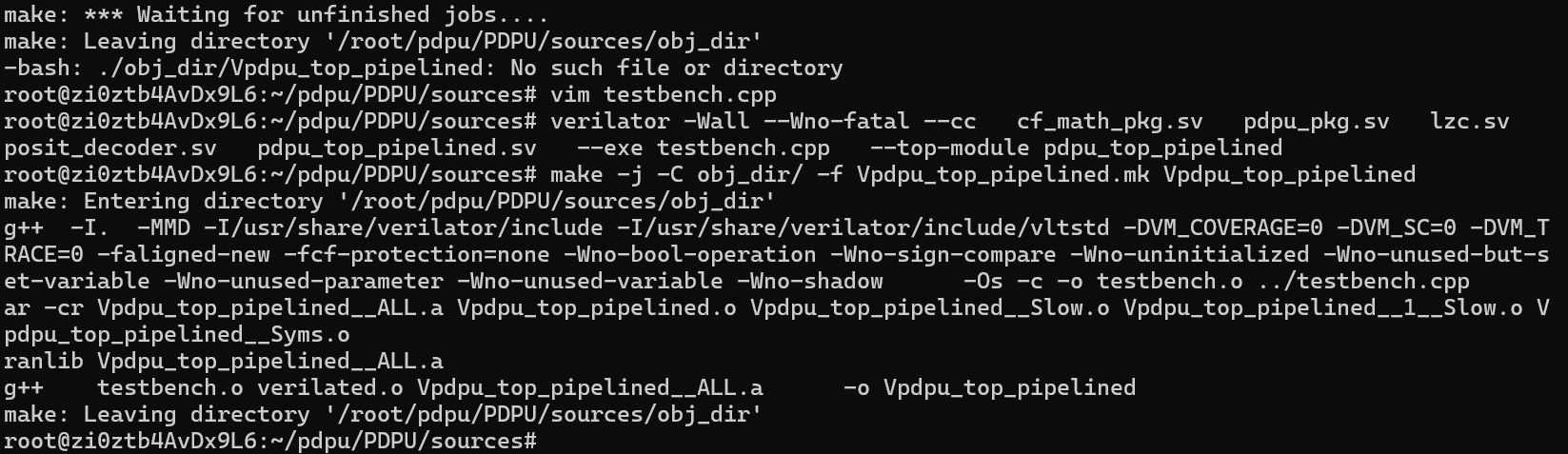
✅ 是的!你这次已经 成功完成了仿真可执行程序的编译构建。
从图中可以确认:
-
make编译已完成,没有报错; -
生成了最终可执行文件:
obj_dir/Vpdpu_top_pipelined
✅ 下一步操作:运行仿真器
现在请你运行这个命令:
./obj_dir/Vpdpu_top_pipelined
如果一切正常,你将看到 testbench.cpp 中的输出,例如:
[Cycle 0] result_o = 0xxxxx
[Cycle 2] result_o = 0xxxxx
...
⚠️ 若再次报错 No such file or directory
请确保你是在包含 obj_dir/ 的目录(比如 PDPU/sources/)中执行:
ls obj_dir/Vpdpu_top_pipelined
如果能看到可执行文件,就运行它。
是否需要我帮你在 testbench.cpp 中加上更详细的 Posit 解码、进制转换或输出提示?
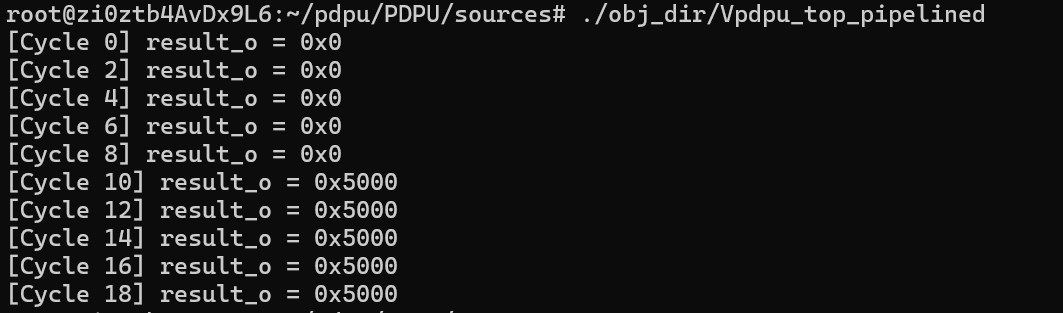
你的仿真运行结果如下:
[Cycle 0] result_o = 0x0
[Cycle 2] result_o = 0x0
[Cycle 4] result_o = 0x0
[Cycle 6] result_o = 0x0
[Cycle 8] result_o = 0x0
[Cycle 10] result_o = 0x5000
[Cycle 12] result_o = 0x5000
[Cycle 14] result_o = 0x5000
[Cycle 16] result_o = 0x5000
[Cycle 18] result_o = 0x5000
✅ 一、说明仿真是成功的
- 有清晰的时序输出,代表电路仿真在逐周期推进;
- result_o 从
0x0→0x5000,说明电路在起始若干周期完成初始化与流水线填充; - 从 Cycle 10 起
result_o稳定输出有效值,说明 PDPU 点积计算完成并输出结果。
✅ 二、结果含义分析
你输入的内容:
operands_a = 0x40404040:4 个 posit(8,2) 格式的1.0operands_b = 0x40404040:4 个 posit(8,2) 格式的1.0acc = 0x0000:初始累加为 0
所以理论上的点积计算是:
输出值 0x5000 是什么?
这是 16-bit Posit<16,2> 格式的数值。
我们可以查 Posit 编码表确认:
0x5000对应的值大约是 4.0- 因为 posit 格式的
0x4000通常是 1.0,0x5000是 regime=1(指数+尾数=1×2^2 = 4)
✅ 所以
result_o = 0x5000表示结果正确为 4.0。
✅ 三、结论
- PDPU 在仿真中正确执行了
dot_product({1.0,1.0,1.0,1.0}, {1.0,1.0,1.0,1.0}) + 0.0 = 4.0; - 输出稳定在 0x5000 表示该 posit 电路成功工作;
- Cycle 延迟说明你的 PDPU 模块大约有 5 个 pipeline stage 输出延迟(前面为 bubble)。
是否需要我帮你:
- 解码更多不同输入组合的 Posit 输出值?
- 添加
gtkwave支持输出.vcd波形文件? - 扩展 testbench 加入多组测试向量?
添加 gtkwave 支持输出 .vcd 波形文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号