一、数据库读书笔记
数据库包括很多种,SQLite,MYSQL等等,而我学习的是SQLite
1、导入数据库:import sqlite3
2、创建数据库:conn = sqlite3.connect('test.db') 其中是将数据库文件命名为text
3、创建一个Cursor(即游标):cursor = conn.cursor()
4、创建表(命名为user):cursor.execute('create table user (id varchar(20) primary key, name varchar(20))')
其中execute函数是执行一个SQL语句,括号内表示id和name为字符串类型,限制20个
执行结果:<sqlite3.Cursor object at 0x10f8aa260>(表示游标目前所在位置)
5、插入一条记录:cursor.execute('insert into user (id, name) values (\'1\', \'Michael\')')
insert表示插入,这条语句相当与在user表中插入一个id=1,name=Michael的数据
执行结果:<sqlite3.Cursor object at 0x10f8aa260>(游标依然停留在第一行)
6、通过rowcount获得插入的行数:cursor.rowcount
执行结果:1
rowcount会返回你所建user表中插入数据的行数
7、关闭Cursor:cursor.close()
8、提交事务:conn.commit()
9、关闭Connection:conn.close()
注意:数据库的使用中有写步骤是不可以改变的,如上述1,2,3,7,8,9。因为一个完整的程序连接数据库之后完成所需操作要关闭,否则数据可能会流失,例如连接conn = sqlite3.connect('test.db'),后面必定会有Connection:conn.close()。
接下来可以试试查询一下我们上面创建的数据库文件text.db
1 conn = sqlite3.connect('test.db')
2 cursor = conn.cursor()
3 # 执行查询语句:
4 cursor.execute('select * from user where id=?', ('1',))
5 #执行结果:<sqlite3.Cursor object at 0x10f8aa340>
6 # 获得查询结果集:
7 values = cursor.fetchall()
8 values
9 #执行结果:[('1', 'Michael')]
10 cursor.close()
11 conn.close()
同样的,这个程序依然有连接和关闭。cursor.fetchall()该例程获取查询结果集中所有(剩余)的行,返回一个列表。当没有可用的行时,则返回一个空的列表。同样的还有:
cursor.fetchone()该方法获取查询结果集中的下一行,返回一个单一的序列,当没有更多可用的数据时,则返回 None。
cursor.fetchmany([size=cursor.arraysize])该方法获取查询结果集中的下一行组,返回一个列表。当没有更多的可用的行时,则返回一个空的列表。该方法尝试获取由 size 参数指定的尽可能多的行。
select语句表示从user表中选出id为1的数据,可以看到在此之前我们已经把id=1,name=Michael的数据插入其中了,结果返回就是这个数据,说明我们的操作成功了。
除了我们上述的insert和select语句之外还有update( 更新数据)和delete(删除数据),对应SQL的基本语句增删查改。
二、使用目前学的sqlite3数据库知识,对一些数据进行增删查改的操作。将http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html中的数据爬取出来保存为csv文件,详细可见https://www.cnblogs.com/jxt666/p/12926441.html文章最后有介绍
1、把所得到的csv文件写入数据库并查询广东技术师范大学的数据
程序:
import pandas
import sqlite3
conn= sqlite3.connect("2018大学排名(17).db")
k = pandas.read_csv(r'C:\Users\Lenovo\Desktop\排名.csv',encoding='gbk')
k.to_sql('University', conn, if_exists='append', index=False)
conn.close()
conn = sqlite3.connect('2018大学排名(17).db')
cursor = conn.cursor()
cursor.execute('SELECT * FROM University')
li = cursor.fetchall()
i=0
for line in li:
i+=1
for item in line:
print(item, end=' ')
print()
if i==15:
break
for line in li:
if "广东技术师范大学" in line:
print(line)
break
else:
print("查无该校数据")
break
conn.close()
结果(只显示15行数据):

由于之前爬取网页数据的时候只爬取了300个学校,所以查询不到
接着我试图查询了清华大学
结果:

2、查询广东省的排名和得分:
程序:
1 import sqlite3 2 conn= sqlite3.connect("2018大学排名(17).db") 3 cur = conn.cursor() 4 cur.execute('SELECT * FROM University') 5 li = cur.fetchall() 6 for line in li: 7 if "广东" in line: 8 print("{} {} {} {}".format(line[0],line[1],line[2],line[4])) 9 conn.close()
结果(数据较多,仅截取一部分):

3、对广东省内大学的排名
在上面,我们已经输出了广东省内大学的名单,但是它们的排序方式仍然是原始的综合排名,而我们想要让名单根据某一特定方式排序(即根据各项数据进行权重分配,权重大的优先排序,次者次排序以此类推),首先将得到的名单先输出为csv文件格式,再将它写入数据库的一个新表中。
代码(输出为csv格式文件)如下:
代码(将数据写入数据库的新表)如下:
效果如下:
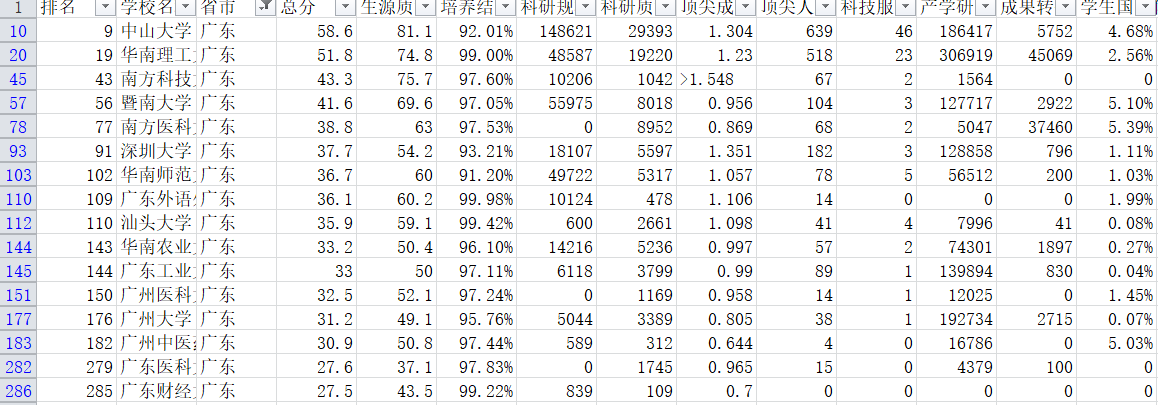
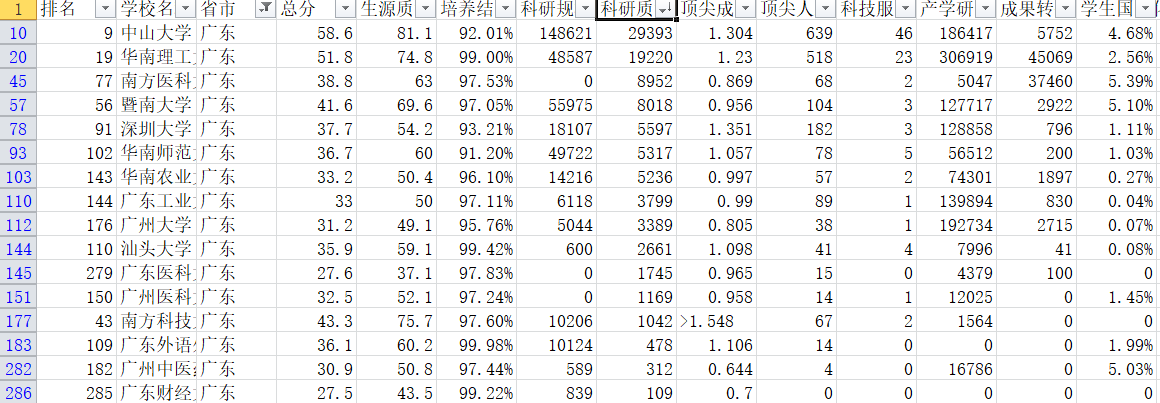
根据科研质量,从高到低排序结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号