一 前言
截止目前,笔者在博客园上面已经发表了3篇关于网络下载的文章,这三篇博客实现了基于socket的http多线程远程断点下载实用程序。笔者打算在此基础上开发出一款分布式文件管理实用程序,截止目前,已经实现了 服务端/客户端 的上传、下载部分的功能逻辑。涉及到的知识点包括线程池技术、linux epoll并发技术、上传、下载等。JDFS的下载功能的逻辑部分与笔者前几篇关于JWebFileTrans(JDownload)比较类似。如果读者对socket网络下载不熟悉或者是只对下载功能感兴趣,请移步笔者的另外三篇博客,本文对下载功能不会详细描述,将主要集中于线程池、epoll和上传。那三篇博客的地址为:
- JWebFileTrans: 一款可以从网络上下载文件的小程序(一) 链接地址请点我
- JWebFileTrans(JDownload): 一款可以从网络上下载文件的小程序(二) 链接地址请点我
- JWebFileTrans(JDownload): 一款可以从网络上下载文件的小程序(三),多线程断点下载 链接地址请点我
JDFS的github地址请点击我
PS: 本篇博客是博客园用户“cs小学生”的原创作品,转载请注明原作者和原文链接,谢谢。
按照管理,下一节将先展示一下JDFS的上传下载功能。
二 JDFS上传、下载功能展示
笔者是在两台虚拟的Ubuntu上做的测试,使用的是vmware player安装的ubuntu linux系统。在做实验之前我们需要首先确保两台虚拟Ubuntu之间的网络是通的,使用ping命令就可以检测之,笔者检测的截图如下:

如上图所示,登录Ubuntu系统后现在shell里面执行ifconfig命令来查看本机的ip是多少,图中的蓝色线标识的便分别是两者的ip地址。

如上图所示,两个虚拟ubuntu互相ping,结果显示网络是通的,那么这个是本实验的基础。

如上图所示是实验之前server端、client端的目录情况,左边的是server端,目录里有一本《Unix环境高级编程》英文版,这个当时候客户端会请求下载这本电子书。右边的是client端的目录情况,其中有一本《算法导论》英文版,实验的时候,客户端会请求向服务端上传这本电子书。
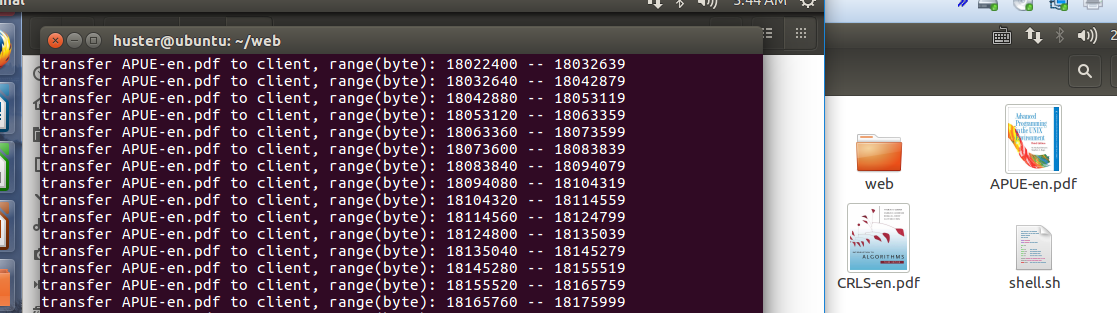
如上图所示,是客户端向服务端请求下载APUE-en.pdf的过程截图,左边是服务端,从shell的打印信息可以看出server在分段向client传送电子书,右边是客户端下载完毕后的截图。可以看出原本客户端目录中只有算法导论一本书,现在多了一本unix环境高级编程这本书。
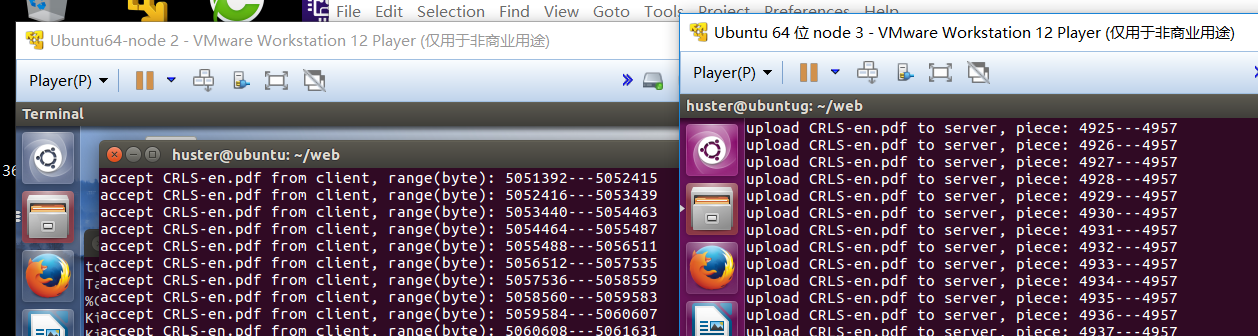
上图所示的是客户端请求向服务端上传算法导论电子书的截图。右边是客户端上传过程中打印的信息,可以看出是分片上传的,而左边是服务端接收过程中shell打印的信息。
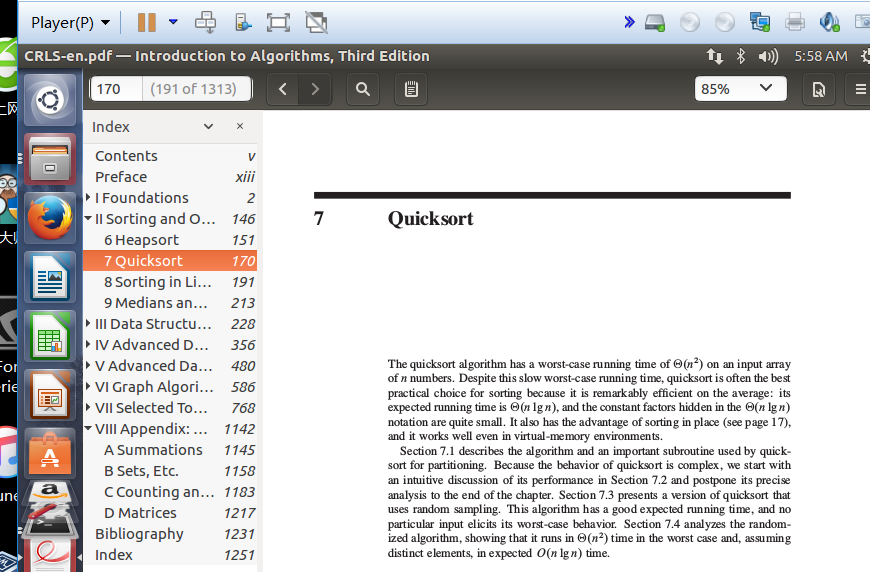
上图是客户端上传算法导论完毕后,在server端的ubuntu系统中打开算法导论的截图,可以看出,上传过程正确,电子书可以正常打开浏览。
三 基本思路
本文是在前言中的三篇博客的基础上构思出来的,而且JDFS的客户端部分下载功能的逻辑与JWebFileTrans(JDownload)几乎一模一样,在后续的详细介绍部分将不会客户端的下载功能做过多介绍,主要集中在上传功能、epoll和线程池部分。因此如果读者之前没有阅读过JWebFileTrans(JDownload)相关的博客,请先到前言部分阅读之,否则在阅读本文的过程中可能会碰到一些障碍。
本文的核心部分是上传、下载,需要在服务端、客户端分别实现对应的逻辑,客户端与服务端遵循相同的协议,或者换句话说,服务端需要与客户端约定好一些规则,然后客户端按照规则发送请求,服务端按照规则响应请求。比如我们定义一个数据结构,里面包含了[请求类型,文件起始位置,文件名等]。服务端接收到客户端的数据后,先把数据的头部按照事先定义好的数据结构来解析之,如果请求类型是上传,则做好接收头部描述的起始位置的那段数据,并写入到磁盘文件。如果请求类型是下载,则根据文件名在服务端的目录里查找该文件,若找到则将对应区段的文件内容发送给客户端。发送、接收分别是通过send() recv()函数来实现的。
那么服务端需要一直在特定的[ip,端口]上监听,服务端的逻辑怎么实现呢?大部分人会想到用一个while死循环来一直监听,网上也有相当多的一部分博客也是这么描述的。这样做的缺点是服务端cpu资源占用率较高,甚至可能接近100%cpu占用率。也就是说大部分情况下cpu被浪费了,即使没有客户端连接。
在linux中有一种高效的实现服务端并发的方案:epoll,使用epoll后,当没有客户端连接请求的时候,用top命令可以看到服务端程序甚至没有显示,这是因为被内核挂起了,一旦有客户端的下载请求,在笔者的实验过程中发现cpu占用率基本在5%左右。可见cpu被很好的利用而没有浪费。有请求则服务,没请求则被内核挂起,一点都不会浪费系统资源。而epoll又分为水平触发和边缘触发,边缘触发需要服务端使用异步IO,逻辑稍微复杂点,而水平触发可以使用异步也可以使用非异步。关于水平触发、边缘触发的概念,请读者自行在网上搜索相关技术博客,此文不在对此赘述,而是集中于JDFS的业务逻辑部分。
那么使用epoll的话还有一个问题,客户端每来一个请求怎么办,是服务端亲自处理吗,如果是的话,那么假设同一时间有100个客户端请求,那岂不是服务端挨个满足服务请求,这就变成了串行处理了,效率肯定不高,毕竟epoll是专门为服务端大规模并发处理而生的。所以,使用pthread?每来一个请求就创建一个线程来服务之,这样就可以达到服务端并行处理的目的。但是问题是,假设有100万个请求,难道要创建100万个线程?且不说系统所支持创建的线程数目是否有上限,光是这么多的线程的创建和销毁就要销毁大量系统资源。那么除此之外还有什么办法呢?没错,就是线程池。
线程池可以形象的理解为一个池塘,这个池塘中有一定数量的事先创建好的线程,池塘里面还有一个队列,这个队列是专门存储客户端请求数据用的。线程不断地从队列中取任务并执行之。
综上,本文服务端的模型是使用epoll来监听客户端的请求,一旦有请求,并不执行,而是将该请求加入到线程池的作业队列中,然后服务端继续监听客户端的请求,而完全不用关心线程池如何满足客户端请求,也不会被线程池阻塞。这样服务端主要逻辑负责监听,而线程池负责执行的逻辑便跃然纸上。
四 JDFS个部件详细介绍
1. 线程池
在前文我们提到线程池的时候说了两个关键词:线程池、作业队列。那么我们首先来定义一下数据结构,笔者本科时清晰的记得课本中有句名言:数据结构+算法=程序,由此可见数据结构的重要性。作业队列是一个链表,每一个链表节点存储的是客户端的请求,我们在此称之为一个Job吧,这个Job要做什么事情只有服务端知道,服务端当初接收到客户端的请求后,会创建一个Job节点插入线程池的作业队列中,并在节点中记录要做的事情,也就是传进来一个函数指针。线程池中的线程直接每服务一个Job节点,便调用对应的函数指针,像这种通过函数指针的方式来调用函数的做法就是回调函数。说到这,我们大致可猜出一个Job节点要记录:回调函数、回调函数的参数、指向下一个Job节点的指针:
1 typedef struct job 2 { 3 void * (*call_back_func)(void *arg); 4 void *arg; 5 int job_kind; 6 struct job *next; 7 }job;
相应的作业队列数据结构的定义如下:
1 typedef struct task_queue 2 { 3 int is_queue_alive; 4 int max_num_of_jobs_of_this_task_queue; 5 int current_num_of_jobs_of_this_task_queue; 6 job *task_queue_head; 7 job *task_queue_tail; 8 9 pthread_cond_t task_queue_empty; 10 pthread_cond_t task_queue_not_empty; 11 pthread_cond_t task_queue_not_full; 12 13 }task_queue;
这其中有三个condition变量,task_queue_empty:销毁线程池的函数会在该变量上等待,只有作业队列空的时候才可以销毁线程池。task_queue_not_empty: 从作业队列取数据的函数可能会在该变量上等待,只有作业队列不空的时候才可以从中取Job. task_queue_not_full:服务端在接收到客户端的请求后,会把该请求打包放入线程池中的作业队列中,但是只有队列不满的时候才可以加入,如果满则服务端会在该变量上面阻塞直到队列不满的时候被唤醒。
线程池的数据结构定义如下:
1 typedef struct threadpool 2 { 3 int thread_num; 4 pthread_t *thread_id_array; 5 int is_threadpool_alive; 6 7 pthread_mutex_t mutex_of_threadpool; 8 task_queue tq; 9 10 }threadpool;
因为本数据结构的字段都是根据其功能命名的,很好理解,其中有一个mutex变量,这个mutex是保护整个线程池的,不论是从线程池中取数据还是往线程池中添加数据都需要首先对线程池的mutex加锁,然后再做相应的操作。另外作业队列中有一个表明作业队列当前是否还活着的变量:is_queue_alive,同样线程池中有一个表明线程池是否还活着的变量:is_threadpool_alive. 它们的功能是这样的:
- 往线程池中的作业队列添加作业:只有线程池活着才可以添加作业
- 从线程池中取作业:只有作业队列还活着,才可以从中取作业。
- 销毁线程池:只有线程池和作业队列都不处于活着的状态时才可以销毁。
需要指出的是:当线程池被设置为not alive的时候,此时作业队列中可能仍然有作业,因此需要等待作业队列中的作业都被执行完毕的时候,把作业队列设置为not alive,此时才可以销毁线程池。
在线程池中大量使用了pthread_cond_wait()和pthread_cond_broadcast()函数。在这两个函数的使用过程中需要注意一点,应该这样使用:
pthread_mutex_lock();
while(condition is not ok){ ........... pthread_cond_wait(); ........... }
没错,一定要用while循环,为什么呢?笔者曾在网上搜索了大量关于这个问题的解答,但是感觉大部分说的不是太清楚。但是至少有一种理由支持我们关于while的用法。我们假设condition是线程等待队列不满,从而可以添加作业到队列中。如果不用while循环而是仅仅用if判断如果队列不满的状态不满足,pthread_cond_wait函数会首先unlock mutex然后进入睡眠等待条件满足是被唤醒(关于pthread_cond_wait()内部的加锁解锁,请读者自行查阅相关资料).unlock mutex后,其他线程就会同样成功加锁,然后进入等待。假设共有N个这样的线程等待该条件变量。再假设这时候有一个从作业队列中取作业的线程取走了一个作业,导致作业队列恰好有一个空位出来,这时候该线程会调用pthread_cond_broadcast()唤醒所有等待该条件变量的线程。这个时候N个线程同时被唤醒,pthread_cond_wait()内部会再次加锁,这时候只有一个线程成功加锁,然后往作业队列中添加一个作业,这时候作业队列又满了,紧接着该线程释放muex,其他N-1个线程中会有一个线程再次有机会获得锁,并且从pthread_cond_wait()中返回。如果是if判断语句,该线程就以为队列已经不满可以添加作业了(实际上作业队列再一次满了),而如果用while循环,则会再一次判断作业队列是处于满的状态,于是再一次调用pthread_cond_wait()进行睡眠。
以上便是线程池背景相关知识的介绍。线程池定义了一组函数接口,如下:
1 int threadpool_create(threadpool *pool, int num_of_thread, int max_num_of_jobs_of_one_task_queue); 2 int threadpool_add_jobs_to_taskqueue(threadpool *pool, void * (*call_back_func)(void *arg), void *arg, int job_kind); 3 int destory_threadpool(threadpool *pool); 4 5 void *thread_func(void *arg); 6 int threadpool_fetch_jobs_from_taskqueue(threadpool *pool, job **job_fetched);
前三个接口是外部接口,供调用者:创建线程池、添加作业到线程池的作业队列中、任务完成后销毁线程池。后面两个函数是内部接口,仅供线程池内部使用,线程池在创建的时候就会启动N个线程,这N个线程都会执行thread_func()函数,在该函数内部,线程会不断调用threadpool_fetch_jobs_from_taskqueue()来获取作业,并执行之。
以上便是线程池主要逻辑,关于逻辑细节,请读者移步笔者的github代码。
2 下载功能
2.1 客户端下载功能
在JDFS中,客户端的下载功能和笔者前几篇关于JWebFileTrans的逻辑几乎一样,只有些许差异,这个差异主要体现在协议上。在一个遵循Http协议标准的下载程序里,程序通过GET命令向服务端发送请求,而服务端会根据http协议解析客户端的请求,根据解析结果来执行之,比如解析的结果是客户端请求文件A的第n到第m个字节,则发送[n,m]区段的A文件内容给客户端。而在JDFS中,客户端、服务端都是笔者自己设计,为了简化编程,我们不使用http协议,而是自己定义一套规则,并按照这个规则来执行。简言之,这个规则其实是用一个数据结构来表示的:
1 typedef struct http_request_buffer 2 { 3 int request_kind; 4 long num1; 5 long num2; 6 char file_name[100]; 7 }http_request_buffer;
其中request_kind表示请求类型:0表示查询文件长度,服务端接收到此种请求会把文件的大小写入到num1字段,然后调用send函数返回给客户端。1表示客户端要上传文件到服务端,num1,num2表示上传的是文件file_name的第num1到第num2个字节,此时服务端就要调用recv来接收客户端的数据,并写入到本地磁盘中。2表示下载,即客户端请求下载文件file_name的第num1到第num2个字节的数据。
以上便是客户端下载逻辑与JWebFileTrans的不同之处,仅仅是遵从的规则发生了变化而已,下载功能的业务逻辑基本是没有变化的,读者可以参考前言中列出的那几篇博客,此处不再赘述。
2.2 服务端下载功能
下面是服务端的下载功能的逻辑部分,这是一个回调函数,服务端再接收到请求后添加到作业队列,线程池中的线程会调用该回调函数来满足客户端的下载请求。服务端采用的是epoll,会在后续部分介绍。
1 void *Http_server_callback_download(void *arg){ 2 3 callback_arg_download *cb_arg_download=(callback_arg_download *)arg; 4 char *file_name=cb_arg_download->file_name; 5 int client_socket_fd=cb_arg_download->socket_fd; 6 long range_begin=cb_arg_download->range_begin; 7 long range_end=cb_arg_download->range_end; 8 unsigned char *server_buffer=cb_arg_download->server_buffer; 9 FILE *fp=fopen(file_name, "r"); 10 if(fp==NULL){ 11 perror("Http_server_callback_download,fopen\n"); 12 close(client_socket_fd); 13 return (void *)1; 14 } 15 16 17 http_request_buffer *hrb=(http_request_buffer *)server_buffer; 18 hrb->num1=range_begin; 19 hrb->num2=range_end; 20 21 fseek(fp, range_begin, SEEK_SET); 22 long http_request_buffer_len=sizeof(http_request_buffer); 23 memcpy(server_buffer+http_request_buffer_len,"JDFS",4); 24 25 fread(server_buffer+http_request_buffer_len+4, range_end-range_begin+1, 1, fp); 26 int send_num=0; 27 int ret=send(client_socket_fd,server_buffer+send_num,http_request_buffer_len+4+range_end-range_begin+1-send_num,0); 28 if(ret==-1){ 29 perror("Http_server_body,send"); 30 close(client_socket_fd); 31 } 32 33 if(fclose(fp)!=0){ 34 perror("Http_server_callback_download,fclose"); 35 } 36 }
以上便是服务端下载功能的回调函数,由于笔者对函数名和变量名严格按照功能来取名的,因此代码很直观,很容易理解。需要注意的是结尾处的flcose(fp),这个很重要,回调函数会被调用很多次,如果不在结尾处关闭文件描述符,会出现打开文件太多的错误提示。
3 上传功能
3.1 客户端上传功能
下面是客户端下载功能的部分逻辑
1 for(int i=0;i<upload_loop_num;i++){ 2 3 printf("upload %s to server, piece: %d---%d\n",file_name, i,upload_loop_num); 4 5 long offset=i*upload_one_piece_size; 6 fseek(fp, offset, SEEK_SET); 7 hrb->num1=offset; 8 hrb->num2=offset+upload_one_piece_size-1; 9 10 int ret=fread(upload_buffer+sizeof(http_request_buffer)+4, upload_one_piece_size, 1, fp); 11 if(ret!=1){ 12 printf("JDFS_http_upload,fread failed\n"); 13 exit(0); 14 } 15 16 while(1){ 17 int ret=send(socket_fd, upload_buffer, upload_buffer_len+4, 0); 18 if(ret==(upload_buffer_len+4)){ 19 break; 20 }else{ 21 int ret=close(socket_fd); 22 if(ret==0){ 23 Http_connect_to_server(server_ip, server_port, &socket_fd); 24 continue; 25 }else{ 26 perror("JDFS_http_upload, close"); 27 exit(0); 28 } 29 } 30 } 31 32 }
3.2 服务端上传功能
下面是服务端上传功能的代码,该处代码与下载功能不同之处在于此处并不是回调函数,而是服务端主程序自己来处理,为什么不是线程池调回调函数呢?这源于服务端当初设计的一个缺陷,原因后面会讲。
1 else if(hrb->request_kind==1){ 2 printf("accept %s from client, range(byte): %ld---%ld\n",hrb->file_name,hrb->num1,hrb->num2); 3 FILE *fp=NULL; 4 char *file_name=hrb->file_name; 5 if(hrb->num1==0){ 6 fp=fopen(file_name, "w+"); 7 }else{ 8 fp=fopen(file_name,"r+"); 9 } 10 11 12 if(fp==NULL){ 13 perror("Http_server_body,fopen"); 14 close(client_socket_fd); 15 }else{ 16 17 long offset=hrb->num1; 18 fseek(fp, offset, SEEK_SET); 19 20 int ret=fwrite(server_buffer+sizeof(http_request_buffer)+4, hrb->num2-hrb->num1+1, 1, fp); 21 if(ret!=1){ 22 close(client_socket_fd); 23 } 24 } 25 26 fclose(fp); 27 28 }else if(hrb->request_kind==2){
3.3 上传功能的缺陷
当前JDFS的上传功能是有缺陷的,原因主要在于服务端,当初笔者调试上传功能的时候,老是失败,在不断减小客户端调用send()函数一次发送的数据量的过程中,当数据量小到一定的程度时,上传就成功了。分析原因在于:当客户端发送数据量较大的时候,比如客户端发送了一段字符“header华中科技大学的计算机专业是全国十强”这句话的时候,服务端是调用recv()来接收数据的,由于网络的原因并不保证一次就能接收完毕,假设分两次传送完毕,服务端接收到的数据有可能是这样的:“header华中科技大学的计算机” “专业是全国十强”。这样就会引发错误,这时候服务端每次调用recv()函数的时候必须判断该段数据是否真的接收完毕,如果不这样做,就有可能把"专业是全国十强”这段数据当成是客户端另一个完整的send()调用发送过来的数据,于是把前几个字节当做header来解析,而实际上这段文字只是客户端上次send()的数据的一部分。
除此之外,服务端的设计也导致了上传功能无法使用线程池来并行处理,具体原因参见下一节。
4 基于epoll的服务端框架
前面说过,服务端设计的时候最直观的就是用一个while循环不断查询是否有客户端连接过来。这样导致效率不高,而针对服务端大并发,linux提供了epoll来支持。什么是epoll呢?网上有大量详细的文章介绍,这里为了方便读者理解,我们可以这样简要的理解:epoll就是当有数据请求的时候才会激活服务端来处理,其他时间都会使得服务端处于睡眠状态,不占用系统资源。当然epoll的功能远不止笔者的描述,这里描述的只是其中的一个点而已。关于epoll笔者也是用到的时候现学的。
epoll主要有三个函数接口:epoll_create()创建一个epoll并返回对应的epoll描述符,epoll_ctl()主要是添加一些感兴趣的事件,比如对socket监听描述符fd上的数据输入感兴趣。epoll_wait():一旦感兴趣的那个文件描述符(比如socket监听描述符)上有感兴趣的事情(数据读、数据写),则返回这些事情的个数,并可以根据这个‘个数’来遍历epoll_wait()的第二个参数,来获取具体的请求(比如客户端连接请求、客户端有数据发送)。关于这三个函数的具体使用也请读者自行查阅相关资料,此处不再赘述。
JDFS服务端的epoll框架部分缩略版代码如下:
1 int epoll_fd=epoll_create(20); 2 if(epoll_fd==-1){ 3 perror("Http_server_body,epoll_create"); 4 exit(0); 5 } 6 7 int ret=epoll_ctl(epoll_fd,EPOLL_CTL_ADD,*server_listen_fd,&event_for_epoll_ctl); 8 if(ret==-1){ 9 perror("Http_server_body,epoll_ctl"); 10 exit(0); 11 } 12 13 int num_of_events_to_happen=0; 14 while(1){ 15 16 num_of_events_to_happen=epoll_wait(epoll_fd,event_for_epoll_wait,event_for_epoll_wait_num,-1); 17 if(num_of_events_to_happen==-1){ 18 perror("Http_server_body,epoll_wait"); 19 exit(0); 20 } 21 22 for(int i=0;i<num_of_events_to_happen;i++){ 23 struct sockaddr_in client_socket; 24 int client_socket_len=sizeof(client_socket); 25 if(*server_listen_fd==event_for_epoll_wait[i].data.fd){ 26 int client_socket_fd=accept(*server_listen_fd,(struct sockaddr *)&client_socket,&client_socket_len); 27 if(client_socket_fd==-1){ 28 continue; 29 } 30 31 event_for_epoll_ctl.data.fd=client_socket_fd; 32 event_for_epoll_ctl.events=EPOLLIN; 33 34 epoll_ctl(epoll_fd,EPOLL_CTL_ADD,client_socket_fd,&event_for_epoll_ctl); 35 36 }else if(event_for_epoll_wait[i].events & EPOLLIN){ 37 int client_socket_fd=event_for_epoll_wait[i].data.fd; 38 if(client_socket_fd<0){ 39 continue; 40 } 41 42 memset(server_buffer,0,sizeof(server_buffer)); 43 int ret=recv(client_socket_fd,server_buffer,sizeof(http_request_buffer)+4+upload_one_piece_size,0); 44 if(ret<=0){ 45 close(client_socket_fd); 46 continue; 47 } 48 49 http_request_buffer *hrb=(http_request_buffer *)server_buffer; 50 51 if(hrb->request_kind==0){ 52 53 54 55 }else if(hrb->request_kind==1){ 56 57 58 }else if(hrb->request_kind==2){ 59 60 61 }else{ 62 63 } 64 65 66 } 67 } 68 69 }
如上述代码,在用epoll注册完感兴趣的事情后,接着就是一个while循环来检测是否有新的客户端请求。epoll_wait返回的就是当前请求的个数,接着便是一个for循环挨个遍历这些请求。在for循环里面最外层的if-else语句,首先判断是不是有新的客户端请求,如果是的话,则调用accept接收之,然后紧接着把这个客户端连接的socket fd加入到epoll中,并设置为对此socket fd的数据输入感兴趣。在else分支里,如果是有数据待读入,则调用recv()函数接收之,并解析读到的数据头,根据hrb->request_kind来分别处理。如果hrb->request_kind=0,2则代表着客户端分别有查询、下载请求,因此将该请求加入线程池,如果该值是1,则表示客户端有数据上传,因为此处的逻辑是先recv(),再解析头部,然后分别处理,所以一旦是上传数据请求,那么此处的recv()函数已经接收了客户端的上传数据,无法再将该请求加入线程池,来并行处理。因为服务端主程序已经做了recv操作,这正是前文提到的由于服务端框架的设计导致了上传数据无法并行处理。
在下一篇博客中,将对JDFS进行改进,一方面使得上传部分也能并行处理,另一方面修改服务端上传部分的逻辑,使得无论一次客户端send()的数据有多大,服务端上传功能都能够正确接收数据。
五 结束语
至此本文就结束了,总结来说,本文基于socket实现了一个具有上传、下载功能的实用程序。后续会继续完善JDFS,期望最终开发出一个分布式文件管理实用程序。
联系方式:https://github.com/junhuster/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号