
一 前言
本篇博客是《JWebFileTrans(JDownload):一款可以从网络上下载文件的小程序》系列博客的第三篇,本篇博客的内容主要是在前两篇的基础上增加多线程的功能。简言之,本篇博客截止目前所达到的功能是:基于HTTP协议的多线程断点远程下载小程序。在阅读本篇博客之前,读者应该先阅读笔者的前两篇博客:
自从本系列第二篇博客以来,这个小程序从JWebFileTrans更名为JDownload,以后会增加诸如ftp下载功能等,以学习为目的,也给对网络感兴趣的读者们一个参考。第一篇博客中给出的若干实验链接现在已经不可用,关于用于实验的http下载链接请参考第二篇博客的说明,截止笔者写这篇博客,快车官网的http下载链接依然有效可以用来做实验。华中科大的hbase的镜像站点也可以用来做实验,但是华中科大的个别hbase链接实际上会重定向到真实的下载链接,但是本程序目前尚不支持从重定向的链接下载文件。此篇博客所述的功能已经更新到github代码:JDownload链接请点我 。如果您觉得JDownlaod源代码对您有用的话,不妨赏赐作者的github一个小星星star.
PS: 本篇博客是博客园用户“cs小学生”的原创作品,转载请注明原作者和原文链接,谢谢。
接下来,按照惯例,下一节仍然是功能展示部分。
二 多线程断点续传功能演示
本次的实验平台依然是vmware player的虚拟ubuntu系统,测试链接是http://mirrors.hust.edu.cn/apache/hbase/1.2.5/hbase-1.2.5-src.tar.gz 。
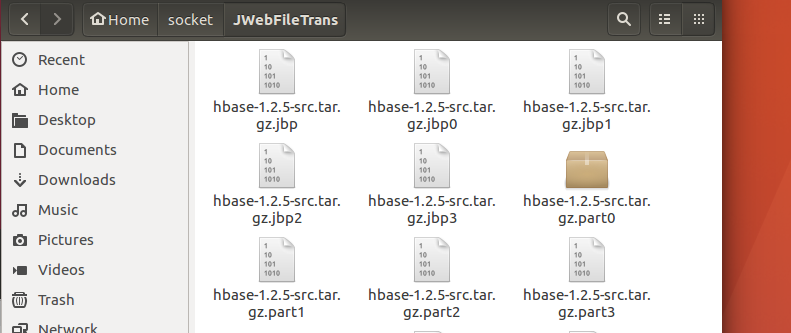

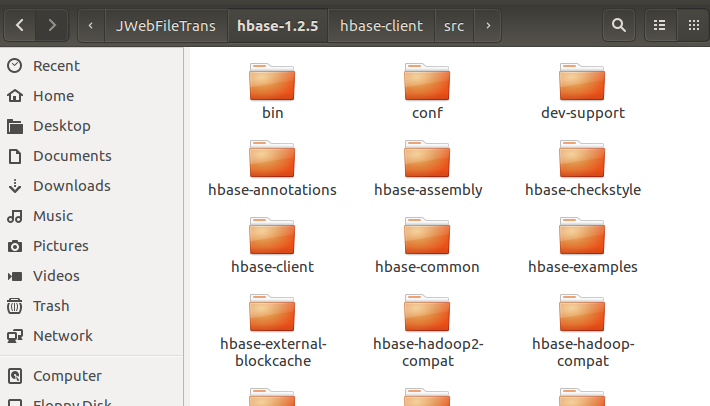
第一张图是下载过程中的截图,第二张是下载完毕后的截图,第三张是hbase下载完毕后解压后的进入主目录的截图。PS:笔者发现要想打开源代码,需要点击打开N层目录,真是别具一格啊,对于docker,基本上也就嵌套一两层目录就能找到源代码。好像Java代码都是这种风格,目录下嵌套子目录,子目录下再嵌套子目录,真是子子孙孙无穷尽也啊。
三 基本思路
在前两篇的基础上加入多线程的支持其实是相当直观的,从上一节的第一幅图就能看出来,有一个.jbp文件,还有四个.jbp0, .jbp1, .jbp2, .jbp3文件,这5个都是记录断点信息的文件。另外还有4个.part文件:.part0, .part1, .part2, .part3,这4个.part文件就是目标下载文件被分为了4段来下载,这四段可以由4个线程同时下载。首先说下.jbp文件,这个描述的是一般性信息,主要是目标文件被分为了几个分段来下载,分片信息,文件大小等等。而.jbp0,1,2,3则记录的是每一个.part0,1,2,3文件已经下载的情况,比如这个.part文件对应目标文件的起始分片,结束分片,已经下载了多少分片等。关于.jbp文件的具体记录内容,可以参考源代码JWebFileTrans.h中的数据结构break_point和break_point_of_part,此处不再赘述。
有了以上信息后,下载过程可以随时停止,再次启动下载程序的时候,只需要读入这些断点文件,进行简要的分析,就可以继续下载。当然4个.part文件不一定非得4个线程来下载,两个线程也行,每一个线程下载其中的两个分段,这体现出一定的灵活性,也就是说每一次下载启动的线程数是可以灵活调整的。下载完毕后,需要有一个合并函数来把这些.part文件合并成一个文件,并且删除所有断点文件,以及不需要的.part文件。
有一个问题需要注意,在此种方案下,分part多线程下载的内容写入到对应的part的时候,offset要设置好。比如之前单线程下载的时候,下载目标文件的第[m,n]个区间,则写入本地文件也要写入[m,n]区间,而多线程分段下载后,下载目标文件的区间[m,n]写入到对应的.partn里面就不一定是[m,n]了,要做一定的修正。由于思维惯性,笔者就犯了这个错误,导致调试了很长时间。
还有一个需要注意的点是,在更新断点文件的时候最好fflush一下,否则下载异常退出后,断点文件没有正确保存到磁盘,下次再运行的时候可能会出错。
多线程部分使用的是pthread线程库,关于如何使用pthread,读者可以参见网上的大量教程,此处也不再赘述。另外最好每一个线程创建一个自己的socket fd,最好不要所有线程共享一个socket fd,那样的话如果其中一个线程把socket fd关闭了,而另一个线程还在使用这个socket fd跟服务端请求数据,则就会出错。笔者在更新代码的时候也犯了这个错误,也花费了一些调试时间找出原因。
四 一点小的改进
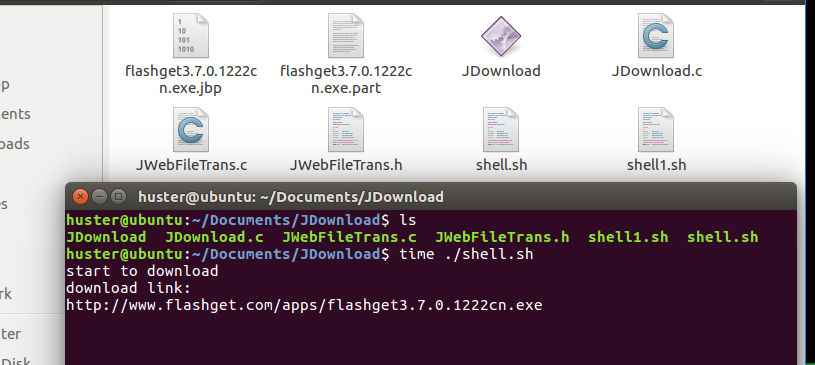
笔者后来用不同的线程数量来测试的时候,发现一个很不美观的问题,随着线程数目的增加,本地下载目录里会产生大量的.jbp 和.part文件,一大堆东西乱轰轰的,很不美观。于是就想着尽量减少断点文件和.part文件的数量,那就把所有断点文件合并到一个文件里吧,所有的.part文件也合并到一个文件里吧。在多线程环境下,这么做安不安全呢?实际上是安全的,大家想一下,每一个线程下载的那段.part文件在目标文件中的区间与其他线程都是不同的,并不会产生冲突,可以并行的写入。比如线程1想要写入区间[m,n],那就用fseek把文件指针移动到偏移量m处,线程2想要写入区间[x,y],就移动文件指针到偏移量x处,然后写入。而由程序的逻辑可知,区间[m,n]和区间[x,y]是没有交集的。这样不仅解决了美观的问题,而且也省去了合并.part文件的步骤,提高了效率。改进后的下载功能演示如下,此次用的是快车下载链接来测试的:
五 多线程环境下的断点功能演示
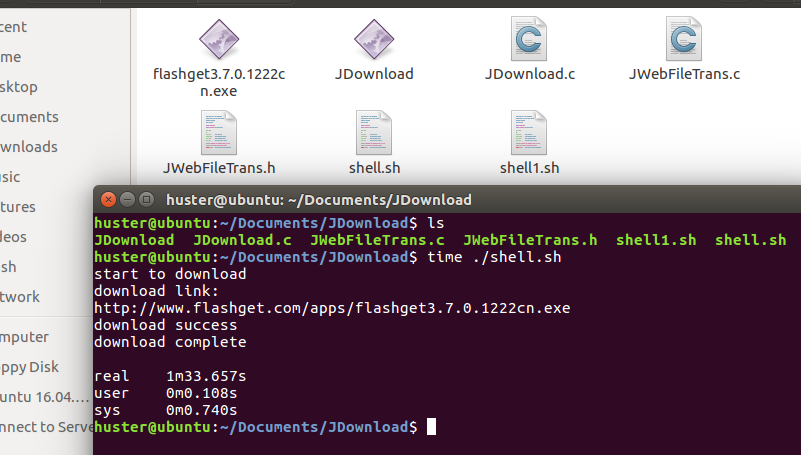
上一节经过改进后的演示截图,这里演示一下多线程环境下的断点功能。截图如下:
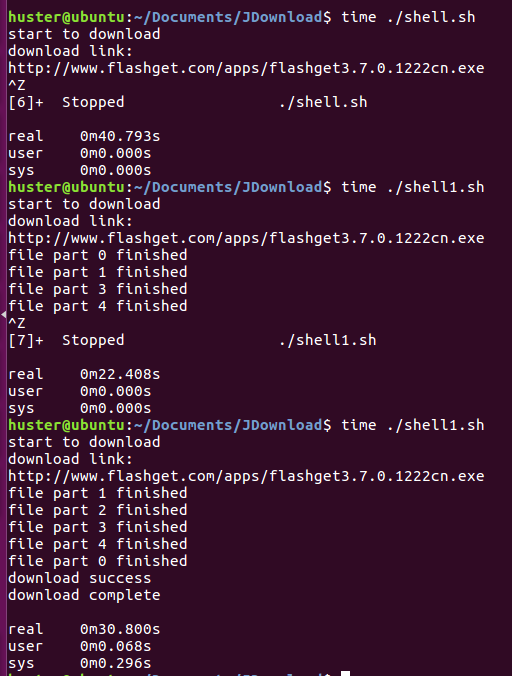
由截图可以看出,在下载过程中笔者两次中断了下载,在第一个中断后重新下载时,程序提示part 0,1,3,4已经下载完毕,这个是在中断前的那一步骤中下载完毕的,在读入断点文件解析后发现并打印出来的。在第二次中断后再次执行的时候,提示part1,2,3,4,0已经下载完毕,说明在第二次中断前part 2被下载完毕。最后直到shell提示downlaod success, download complete,则全部下载完毕。下载完毕的快车运行截图,这里就不在演示了,笔者可以自行测试之。
六 一些调试问题
之前在写博客的时候,调试代码方面也遇到了挺多问题,但是都没有被记录下来,打算未来把遇到的问题都记录一下,来提醒自己。本次遇到的问题如下:
- 指针的分离导致malloc失败。有时候一个指针在其中一个函数里面定义,经过重重传递到达另一个函数,再加上代码数量比较多,有时候会忘记这个指针其实不是malloc分配而来的,这个时候free它,肯定是会出错的。
- fopen文件太多导致的错误。这个具体是在哪个步骤导致的,我现在已经记不太清楚了,看来还是好记性不如烂笔头啊
- 前文提到的每一个.part文件保存时偏移量的修正问题,当然改进后,这个问题就不存在了
- 文件分片余数问题。文件不一定被分片整除,因此会有余数,笔者之前下载文件老是失败,经过调试,发现每一次下载的文件都少了一部分,进一步分析这个少的部分就是这个余数的大小,于是迅速定位解决了问题。
还有一个很难重现的问题,只出现过一次:有一天晚上笔者又拿JDownlaod下载快车来测试,却发现程序老是提示http_recv_file, bad file descriptor,由于笔者的程序在打印错误信息的时候会带上出错的函数名字,因此一下就定位到http_recv_file这个函数,经查明是http_recv_file这个函数里调用send函数失败导致的,网上查了下,说原因可能是:It could be that you are closing the client socket before the thread,gets a chance to run, or it could be that your thread is improperly setup. 但是我的代码里每一个线程有自己的socket fd,不会被其他线程影响到啊。于是只能暂时在调用send的时候加上一个while循环,如果出错,就多试几次,测试截图如下:

从上图可以看出,在下载过程中提示了好几次Http_recv_file,close in first send:Bad file descriptor。但是由于笔者更新了代码,加上了while循环,从截图看出,在失败了几次后终于成功了。但是之后笔者再次测试想要查明具体原因时,这个错误再也没有出现过。之前问题是出现在下载快车软件的时候,线程多到一定程度就会出现这个问题,与此同时,从华中科大下载hbase,同样的线程数目,却不会出现问题。这个只好留到以后,错误再次重现的时候再查明具体原因了。另外还有一个现象就是,如果出现了上述错误,然后笔者中断下载,再次通过断点续传的话,很快就能下载完毕。而如果一直等待不采用断点的方式重新下载,虽然可以成功,但却花费更长的时间。
七 一个有意思的现象
在分别从快车官网、华中科大镜像下载的时候,通过top命令,看到前者cpu占用率基本维持在0.9%左右,而后者基本维持在5%左右。这应该是后者网络通畅,使得JDownload大部分时间有事情做,而前者由于网络不是太通畅,导致大部分时间没有数据需要处理,从而不需要占用太多的cpu资源。有时候JDownload会从top命令里面消失,这应该是由于网络太不通畅了,导致send,或者recv调用被阻塞,从而程序被linux内核从调度队列里面暂时移除了。另外测试的时候最好用可执行文件的下载链接来测试,这样可以通过运行它来确定下载的是正确的文件,而有些压缩文件,即使最后少下载了一部分,但是也能解压看到其他文件,这个时候就不利于判断程序写的是否正确。
具体的代码实现,请读者移步笔者的github链接吧,链接在前言中。
八 结束语
至此本文就结束了,总结来说,就是在单线程断点续传的功能基础上,加上了多线程的功能。目前只支持从http站点下载,未来可能还会加入ftp的支持,如果您对此有兴趣的话,请继续关注笔者博客的动态。
联系方式:https://github.com/junhuster/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号