机器学习经典算法之Apriori
一、 搞懂关联规则中的几个概念
关联规则这个概念,最早是由 Agrawal 等人在 1993 年提出的。在 1994 年 Agrawal 等人又提出了基于关联规则的 Apriori 算法,至今 Apriori 仍是关联规则挖掘的重要算法。
/*请尊重作者劳动成果,转载请标明原文链接:*/
/* https://www.cnblogs.com/jpcflyer/p/11146587.html * /
关联规则挖掘可以让我们从数据集中发现项与项(item 与 item)之间的关系,它在我们的生活中有很多应用场景,“购物篮分析”就是一个常见的场景,这个场景可以从消费者交易记录中发掘商品与商品之间的关联关系,进而通过商品捆绑销售或者相关推荐的方式带来更多的销售量。所以说,关联规则挖掘是个非常有用的技术。
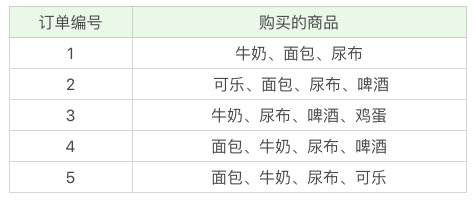
我举一个超市购物的例子,下面是几名客户购买的商品列表:

什么是支持度呢?
支持度是个百分比,它指的是某个商品组合出现的次数与总次数之间的比例。支持度越高,代表这个组合出现的频率越大。
在这个例子中,我们能看到“牛奶”出现了 4 次,那么这 5 笔订单中“牛奶”的支持度就是 4/5=0.8。
同样“牛奶 + 面包”出现了 3 次,那么这 5 笔订单中“牛奶 + 面包”的支持度就是 3/5=0.6。
什么是置信度呢?
它指的就是当你购买了商品 A,会有多大的概率购买商品 B,在上面这个例子中:
置信度(牛奶→啤酒)=2/4=0.5,代表如果你购买了牛奶,有多大的概率会购买啤酒?
置信度(啤酒→牛奶)=2/3=0.67,代表如果你购买了啤酒,有多大的概率会购买牛奶?
我们能看到,在 4 次购买了牛奶的情况下,有 2 次购买了啤酒,所以置信度 (牛奶→啤酒)=0.5,而在 3 次购买啤酒的情况下,有 2 次购买了牛奶,所以置信度(啤酒→牛奶)=0.67。
所以说置信度是个条件概念,就是说在 A 发生的情况下,B 发生的概率是多少。
什么是提升度呢?
我们在做商品推荐的时候,重点考虑的是提升度,因为提升度代表的是“商品 A 的出现,对商品 B 的出现概率提升的”程度。
还是看上面的例子,如果我们单纯看置信度 (可乐→尿布)=1,也就是说可乐出现的时候,用户都会购买尿布,那么当用户购买可乐的时候,我们就需要推荐尿布么?
实际上,就算用户不购买可乐,也会直接购买尿布的,所以用户是否购买可乐,对尿布的提升作用并不大。我们可以用下面的公式来计算商品 A 对商品 B 的提升度:
提升度 (A→B)= 置信度 (A→B)/ 支持度 (B)
这个公式是用来衡量 A 出现的情况下,是否会对 B 出现的概率有所提升。
所以提升度有三种可能:
提升度 (A→B)>1:代表有提升;
提升度 (A→B)=1:代表有没有提升,也没有下降;
提升度 (A→B)<1:代表有下降。
二、 Apriori 的工作原理
明白了关联规则中支持度、置信度和提升度这几个重要概念,我们来看下 Apriori 算法是如何工作的。
首先我们把上面案例中的商品用 ID 来代表,牛奶、面包、尿布、可乐、啤酒、鸡蛋的商品 ID 分别设置为 1-6,上面的数据表可以变为:

Apriori 算法其实就是查找频繁项集 (frequent itemset) 的过程,所以首先我们需要定义什么是频繁项集。
频繁项集就是支持度大于等于最小支持度 (Min Support) 阈值的项集,所以小于最小值支持度的项目就是非频繁项集,而大于等于最小支持度的项集就是频繁项集。
项集这个概念,英文叫做 itemset,它可以是单个的商品,也可以是商品的组合。我们再来看下这个例子,假设我随机指定最小支持度是 50%,也就是 0.5。
我们来看下 Apriori 算法是如何运算的。
首先,我们先计算单个商品的支持度,也就是得到 K=1 项的支持度:

因为最小支持度是 0.5,所以你能看到商品 4、6 是不符合最小支持度的,不属于频繁项集,于是经过筛选商品的频繁项集就变成:

在这个基础上,我们将商品两两组合,得到 k=2 项的支持度:

我们再筛掉小于最小值支持度的商品组合,可以得到:

我们再将商品进行 K=3 项的商品组合,可以得到:

再筛掉小于最小值支持度的商品组合,可以得到:

到这里,你已经和我模拟了一遍整个 Apriori 算法的流程,下面我来给你总结下 Apriori 算法的递归流程:
K=1,计算 K 项集的支持度;
筛选掉小于最小支持度的项集;
如果项集为空,则对应 K-1 项集的结果为最终结果。
否则 K=K+1,重复 1-3 步。
三、 Apriori 的改进算法:FP-Growth 算法
能看到 Apriori 在计算的过程中有以下几个缺点:
可能产生大量的候选集。因为采用排列组合的方式,把可能的项集都组合出来了;
每次计算都需要重新扫描数据集,来计算每个项集的支持度。
所以 Apriori 算法会浪费很多计算空间和计算时间,为此人们提出了 FP-Growth 算法,它的特点是:
创建了一棵 FP 树来存储频繁项集。在创建前对不满足最小支持度的项进行删除,减少了存储空间。我稍后会讲解如何构造一棵 FP 树;
整个生成过程只遍历数据集 2 次,大大减少了计算量。
所以在实际工作中,我们常用 FP-Growth 来做频繁项集的挖掘,下面我给你简述下 FP-Growth 的原理。
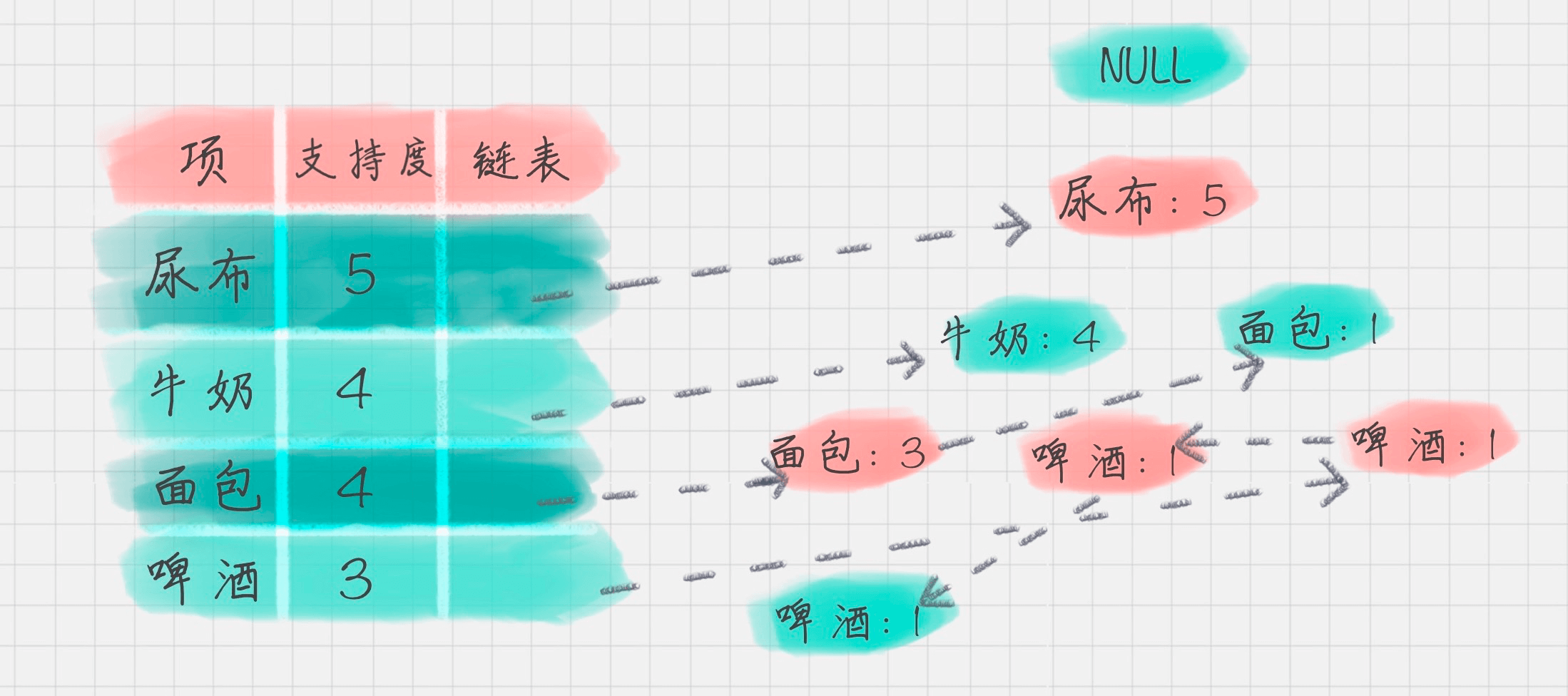
1. 创建项头表(item header table)
创建项头表的作用是为 FP 构建及频繁项集挖掘提供索引。
这一步的流程是先扫描一遍数据集,对于满足最小支持度的单个项(K=1 项集)按照支持度从高到低进行排序,这个过程中删除了不满足最小支持度的项。
项头表包括了项目、支持度,以及该项在 FP 树中的链表。初始的时候链表为空。

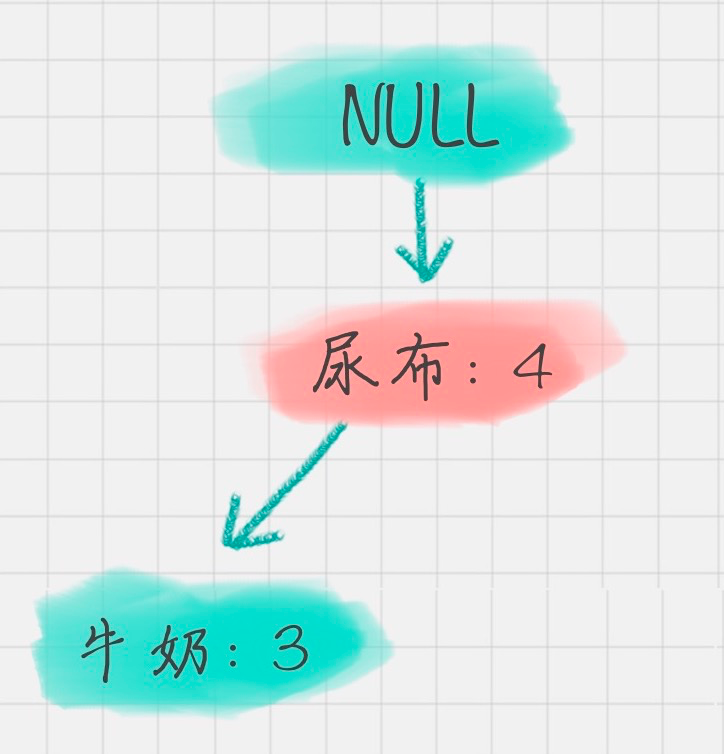
2. 构造 FP 树
FP 树的根节点记为 NULL 节点。
整个流程是需要再次扫描数据集,对于每一条数据,按照支持度从高到低的顺序进行创建节点(也就是第一步中项头表中的排序结果),节点如果存在就将计数 count+1,如果不存在就进行创建。同时在创建的过程中,需要更新项头表的链表。
3. 通过 FP 树挖掘频繁项集
到这里,我们就得到了一个存储频繁项集的 FP 树,以及一个项头表。我们可以通过项头表来挖掘出每个频繁项集。
具体的操作会用到一个概念,叫“条件模式基”,它指的是以要挖掘的节点为叶子节点,自底向上求出 FP 子树,然后将 FP 子树的祖先节点设置为叶子节点之和。
我以“啤酒”的节点为例,从 FP 树中可以得到一棵 FP 子树,将祖先节点的支持度记为叶子节点之和,得到:

你能看出来,相比于原来的 FP 树,尿布和牛奶的频繁项集数减少了。这是因为我们求得的是以“啤酒”为节点的 FP 子树,也就是说,在频繁项集中一定要含有“啤酒”这个项。你可以再看下原始的数据,其中订单 1{牛奶、面包、尿布}和订单 5{牛奶、面包、尿布、可乐}并不存在“啤酒”这个项,所以针对订单 1,尿布→牛奶→面包这个项集就会从 FP 树中去掉,针对订单 5 也包括了尿布→牛奶→面包这个项集也会从 FP 树中去掉,所以你能看到以“啤酒”为节点的 FP 子树,尿布、牛奶、面包项集上的计数比原来少了 2。
条件模式基不包括“啤酒”节点,而且祖先节点如果小于最小支持度就会被剪枝,所以“啤酒”的条件模式基为空。
同理,我们可以求得“面包”的条件模式基为:
所以可以求得面包的频繁项集为{尿布,面包},{尿布,牛奶,面包}。同样,我们还可以求得牛奶,尿布的频繁项集,这里就不再计算展示。
四、 如何使用 Apriori 工具包
Apriori 虽然是十大算法之一,不过在 sklearn 工具包中并没有它,也没有 FP-Growth 算法。这里教你个方法,来选择 Python 中可以使用的工具包,你可以通过 https://pypi.org/ 搜索工具包。
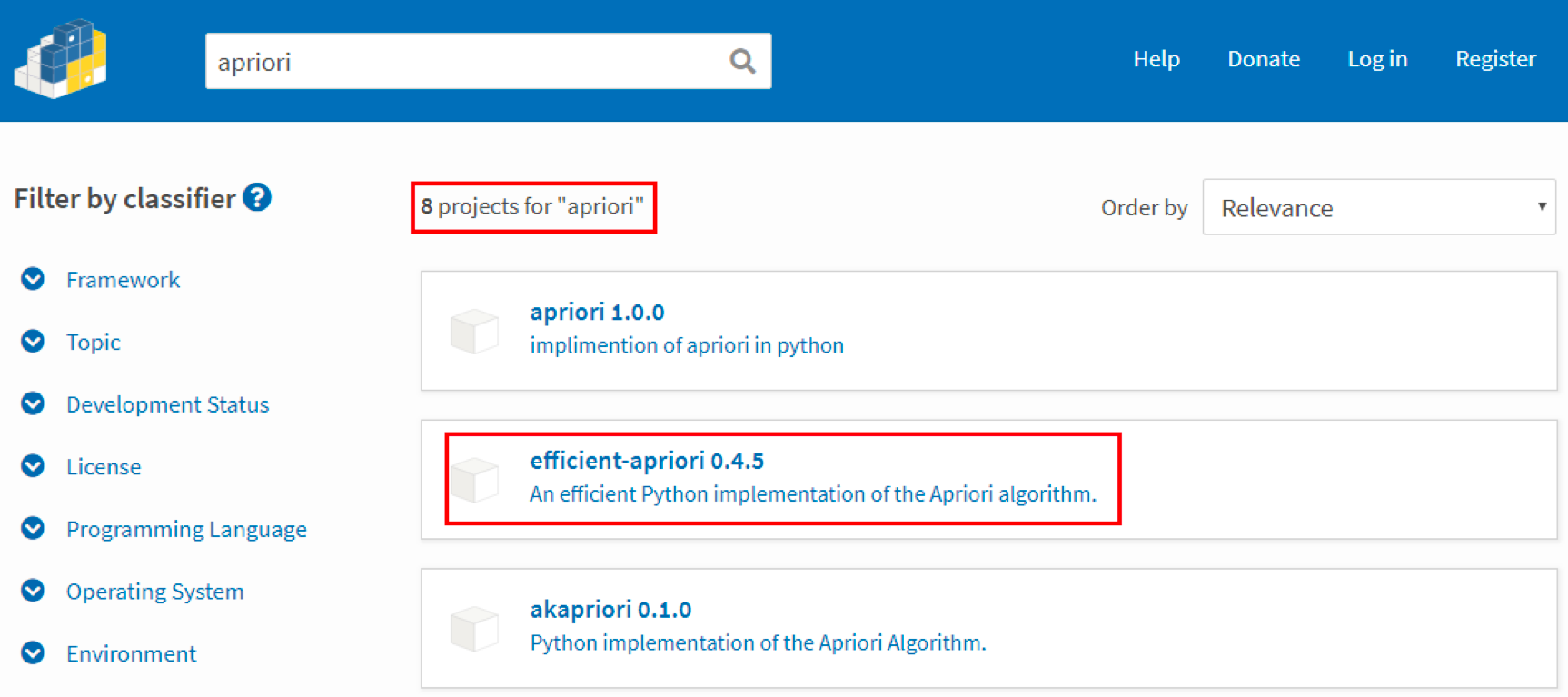
这个网站提供的工具包都是 Python 语言的,你能找到 8 个 Python 语言的 Apriori 工具包,具体选择哪个呢?建议你使用第二个工具包,即 efficient-apriori。后面我会讲到为什么推荐这个工具包。
首先你需要通过 pip install efficient-apriori 安装这个工具包。
然后看下如何使用它,核心的代码就是这一行:
1 itemsets, rules = apriori(data, min_support, min_confidence)
其中 data 是我们要提供的数据集,它是一个 list 数组类型。min_support 参数为最小支持度,在 efficient-apriori 工具包中用 0 到 1 的数值代表百分比,比如 0.5 代表最小支持度为 50%。min_confidence 是最小置信度,数值也代表百分比,比如 1 代表 100%。
接下来我们用这个工具包,跑一下前面讲到的超市购物的例子。下面是客户购买的商品列表:
具体实现的代码如下:
1 from efficient_apriori import apriori 2 # 设置数据集 3 data = [('牛奶','面包','尿布'), 4 ('可乐','面包', '尿布', '啤酒'), 5 ('牛奶','尿布', '啤酒', '鸡蛋'), 6 ('面包', '牛奶', '尿布', '啤酒'), 7 ('面包', '牛奶', '尿布', '可乐')] 8 # 挖掘频繁项集和频繁规则 9 itemsets, rules = apriori(data, min_support=0.5, min_confidence=1) 10 print(itemsets) 11 print(rules)
运行结果:
1 {1: {('啤酒',): 3, ('尿布',): 5, ('牛奶',): 4, ('面包',): 4}, 2: {('啤酒', '尿布'): 3, ('尿布', '牛奶'): 4, ('尿布', '面包'): 4, ('牛奶', '面包'): 3}, 3: {('尿布', '牛奶', '面包'): 3}} 2 [{啤酒} -> {尿布}, {牛奶} -> {尿布}, {面包} -> {尿布}, {牛奶, 面包} -> {尿布}]
你能从代码中看出来,data 是个 List 数组类型,其中每个值都可以是一个集合。实际上你也可以把 data 数组中的每个值设置为 List 数组类型,比如:
1 data = [['牛奶','面包','尿布'], 2 ['可乐','面包', '尿布', '啤酒'], 3 ['牛奶','尿布', '啤酒', '鸡蛋'], 4 ['面包', '牛奶', '尿布', '啤酒'], 5 ['面包', '牛奶', '尿布', '可乐']]
两者的运行结果是一样的,efficient-apriori 工具包把每一条数据集里的项式都放到了一个集合中进行运算,并没有考虑它们之间的先后顺序。因为实际情况下,同一个购物篮中的物品也不需要考虑购买的先后顺序。
而其他的 Apriori 算法可能会因为考虑了先后顺序,出现计算频繁项集结果不对的情况。所以这里采用的是 efficient-apriori 这个工具包。
五、 挖掘导演是如何选择演员的
在实际工作中,数据集是需要自己来准备的,比如我们要挖掘导演是如何选择演员的数据情况,但是并没有公开的数据集可以直接使用。因此我们需要使用之前讲到的 Python 爬虫进行数据采集。
不同导演选择演员的规则是不同的,因此我们需要先指定导演。数据源我们选用豆瓣电影。
先来梳理下采集的工作流程。
首先我们先在 https://movie.douban.com 搜索框中输入导演姓名,比如“宁浩”。
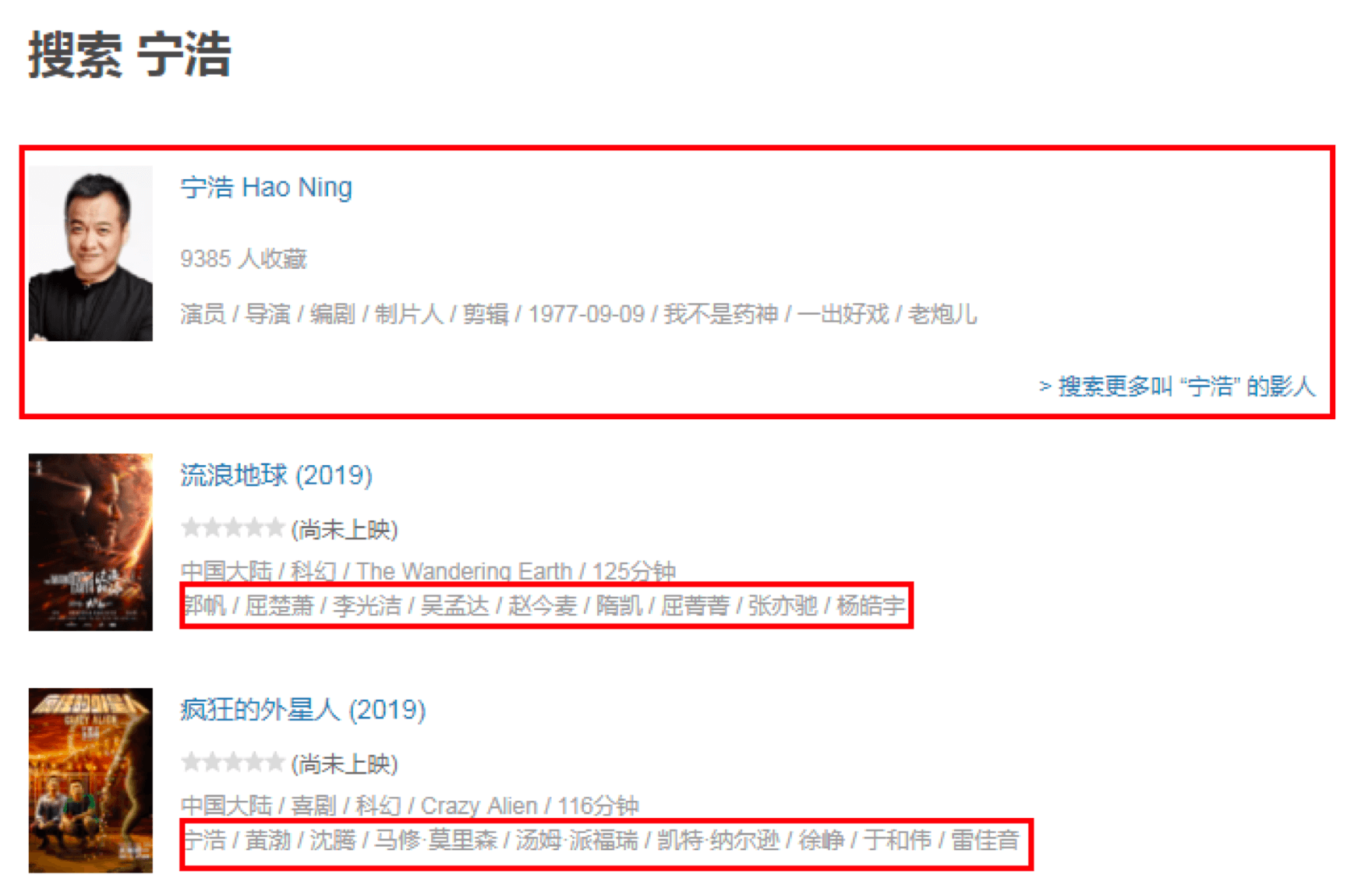
页面会呈现出来导演之前的所有电影,然后对页面进行观察,你能观察到以下几个现象:
页面默认是 15 条数据反馈,第一页会返回 16 条。因为第一条数据实际上这个导演的概览,你可以理解为是一条广告的插入,下面才是真正的返回结果。
每条数据的最后一行是电影的演出人员的信息,第一个人员是导演,其余为演员姓名。姓名之间用“/”分割。
有了这些观察之后,我们就可以编写抓取程序了。在代码讲解中你能看出这两点观察的作用。抓取程序的目的是为了生成宁浩导演(你也可以抓取其他导演)的数据集,结果会保存在 csv 文件中。完整的抓取代码如下:
1 # -*- coding: utf-8 -*- 2 # 下载某个导演的电影数据集 3 from efficient_apriori import apriori 4 from lxml import etree 5 import time 6 from selenium import webdriver 7 import csv 8 driver = webdriver.Chrome() 9 # 设置想要下载的导演 数据集 10 director = u'宁浩' 11 # 写 CSV 文件 12 file_name = './' + director + '.csv' 13 base_url = 'https://movie.douban.com/subject_search?search_text='+director+'&cat=1002&start=' 14 out = open(file_name,'w', newline='', encoding='utf-8-sig') 15 csv_write = csv.writer(out, dialect='excel') 16 flags=[] 17 # 下载指定页面的数据 18 def download(request_url): 19 driver.get(request_url) 20 time.sleep(1) 21 html = driver.find_element_by_xpath("//*").get_attribute("outerHTML") 22 html = etree.HTML(html) 23 # 设置电影名称,导演演员 的 XPATH 24 movie_lists = html.xpath("/html/body/div[@id='wrapper']/div[@id='root']/div[1]//div[@class='item-root']/div[@class='detail']/div[@class='title']/a[@class='title-text']") 25 name_lists = html.xpath("/html/body/div[@id='wrapper']/div[@id='root']/div[1]//div[@class='item-root']/div[@class='detail']/div[@class='meta abstract_2']") 26 # 获取返回的数据个数 27 num = len(movie_lists) 28 if num > 15: # 第一页会有 16 条数据 29 # 默认第一个不是,所以需要去掉 30 movie_lists = movie_lists[1:] 31 name_lists = name_lists[1:] 32 for (movie, name_list) in zip(movie_lists, name_lists): 33 # 会存在数据为空的情况 34 if name_list.text is None: 35 continue 36 # 显示下演员名称 37 print(name_list.text) 38 names = name_list.text.split('/') 39 # 判断导演是否为指定的 director 40 if names[0].strip() == director and movie.text not in flags: 41 # 将第一个字段设置为电影名称 42 names[0] = movie.text 43 flags.append(movie.text) 44 csv_write.writerow(names) 45 print('OK') # 代表这页数据下载成功 46 print(num) 47 if num >= 14: # 有可能一页会有 14 个电影 48 # 继续下一页 49 return True 50 else: 51 # 没有下一页 52 return False 53 54 # 开始的 ID 为 0,每页增加 15 55 start = 0 56 while start<10000: # 最多抽取 1 万部电影 57 request_url = base_url + str(start) 58 # 下载数据,并返回是否有下一页 59 flag = download(request_url) 60 if flag: 61 start = start + 15 62 else: 63 break 64 out.close() 65 print('finished')
代码中涉及到了几个模块,我简单讲解下这几个模块。
在引用包这一段,我们使用 csv 工具包读写 CSV 文件,用 efficient_apriori 完成 Apriori 算法,用 lxml 进行 XPath 解析,time 工具包可以让我们在模拟后有个适当停留,代码中我设置为 1 秒钟,等 HTML 数据完全返回后再进行 HTML 内容的获取。使用 selenium 的 webdriver 来模拟浏览器的行为。
在读写文件这一块,我们需要事先告诉 python 的 open 函数,文件的编码是 utf-8-sig(对应代码:encoding=‘utf-8-sig’),这是因为我们会用到中文,为了避免编码混乱。
编写 download 函数,参数传入我们要采集的页面地址(request_url)。针对返回的 HTML,我们需要用到之前讲到的 Chrome 浏览器的 XPath Helper 工具,来获取电影名称以及演出人员的 XPath。我用页面返回的数据个数来判断当前所处的页面序号。如果数据个数 >15,也就是第一页,第一页的第一条数据是广告,我们需要忽略。如果数据个数 =15,代表是中间页,需要点击“下一页”,也就是翻页。如果数据个数 <15,代表最后一页,没有下一页。
在程序主体部分,我们设置 start 代表抓取的 ID,从 0 开始最多抓取 1 万部电影的数据(一个导演不会超过 1 万部电影),每次翻页 start 自动增加 15,直到 flag=False 为止,也就是不存在下一页的情况。
你可以模拟下抓取的流程,获得指定导演的数据,比如我上面抓取的宁浩的数据。这里需要注意的是,豆瓣的电影数据可能是不全的,但基本上够我们用。
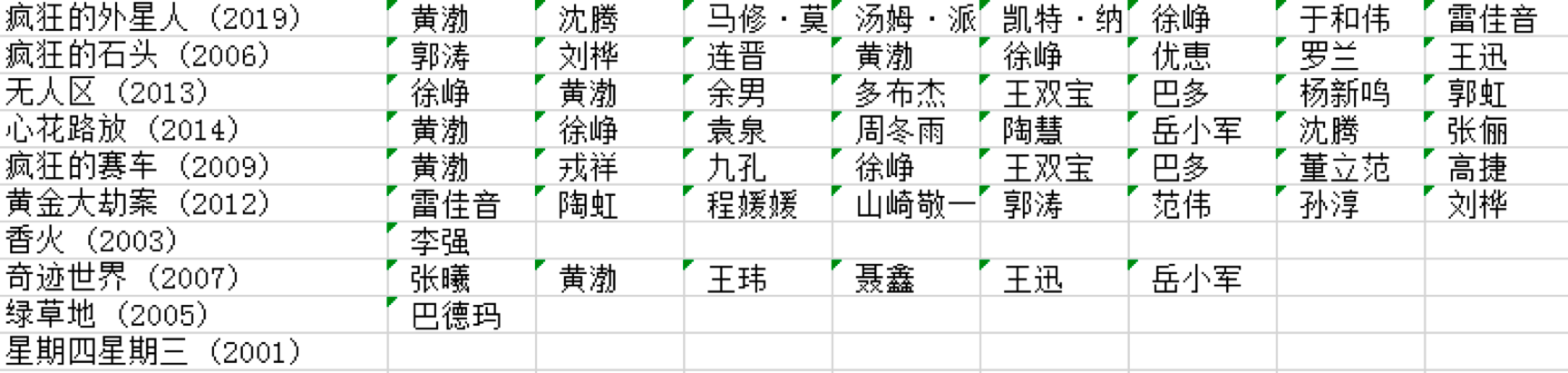
有了数据之后,我们就可以用 Apriori 算法来挖掘频繁项集和关联规则,代码如下:
1 # -*- coding: utf-8 -*- 2 from efficient_apriori import apriori 3 import csv 4 director = u'宁浩' 5 file_name = './'+director+'.csv' 6 lists = csv.reader(open(file_name, 'r', encoding='utf-8-sig')) 7 # 数据加载 8 data = [] 9 for names in lists: 10 name_new = [] 11 for name in names: 12 # 去掉演员数据中的空格 13 name_new.append(name.strip()) 14 data.append(name_new[1:]) 15 # 挖掘频繁项集和关联规则 16 itemsets, rules = apriori(data, min_support=0.5, min_confidence=1) 17 print(itemsets) 18 print(rules)
代码中使用的 apriori 方法和开头中用 Apriori 获取购物篮规律的方法类似,比如代码中都设定了最小支持度和最小置信系数,这样我们可以找到支持度大于 50%,置信系数为 1 的频繁项集和关联规则。
这是最后的运行结果:
1 {1: {('徐峥',): 5, ('黄渤',): 6}, 2: {('徐峥', '黄渤'): 5}} 2 [{徐峥} -> {黄渤}]
你能看出来,宁浩导演喜欢用徐峥和黄渤,并且有徐峥的情况下,一般都会用黄渤。你也可以用上面的代码来挖掘下其他导演选择演员的规律。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号