[Presto] Trino :开源的分布式SQL查询引擎
0 引言
Presto(Trino) 在 Facebook 的诞生最开始是为了填补当时 Facebook 内部实时查询和 ETL 处理之间的空白。
Presto的核心目标就是提供【交互式查询】,也就是我们常说的Ad-Hoc Query(即席查询),很多公司都使用它作为OLAP计算引擎。- 但是随着近年来业务场景越来越复杂,除了交互式查询场景,很多公司也需要批处理;但是 Presto 作为一个 MPP 计算引擎,将一个 MPP 体系结构的数据库 来处理海量数据集的批处理是一个非常困难的问题,所以一种比较常见的做法是前端写一个适配器,对 SQL 进行预先处理,如果是一个【即时查询】就走
Presto,否则走Spark,这么处理可以在一定程度解决我们的问题,但是两个【计算引擎】以及加上前面的一些SQL【预处理】大大加大我们系统的复杂度。为了解决这个问题,PrestoDB 启动了 Presto Unlimited 以及 Presto on Spark 等项目用于解决这种问题,这些我们可以到 Presto on Spark: 支持即时查询和批处理 和 Presto on Spark: 通过 Spark 来扩展 Presto 文章中了解详情。
1 概述: Trino

1.1 Trino 介绍
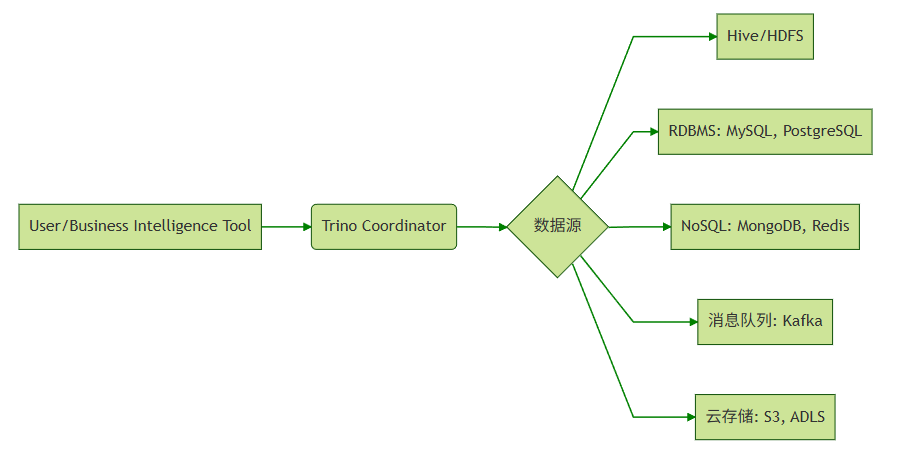
Trino(原名PrestoSQL)是一款开源的分布式 SQL 查询引擎,专为大数据的交互式分析(Ad-hoc)而设计。
- 它最核心的特点是快,能够处理从 GB 到 PB 级的数据,并且支持跨多种数据源(如
Kafka、Hive、MySQL、Oracle、PostgreSQL、SQLServer、Clickhouse、Elasticsearch、Inceptor、tdsql、MongoDB、Redis、S3(对象存储)、Iceberg等20+异构数据源)进行【联邦查询】(跨源查询)。
- 其核心特性包括高速查询、弹性扩展和低成本使用,适合交互式分析与BI场景。
Trino采用【无共享架构】,通过【列式内存格式】和【动态代码生成】优化性能,并提供丰富的连接器实现【计算存储分离(存算分离)】,最大化下推优化以提升效率。
1.2 核心特性 && 适用场景
- 分布式计算:Trino通过将查询任务分发到多个节点上并行执行,显著提升了查询性能。
- 内存计算:Trino采用内存计算模型,数据在查询过程中被加载到内存中进行处理,适合实时分析场景。
- 扩展性:Trino支持动态扩展集群规模,能够根据负载需求自动调整资源。
- 流水线:Trino是基于
PipeLine设计的,在进行大量设计处理过程中,终端不需要等待所有的数据计算完毕之后才能看到结果,计算一部分就可以看部分结果。
| 特性 | 传统数仓/引擎 | Trino | 优势场景 |
|---|---|---|---|
| 查询速度 | 分钟~小时级 | 秒~分钟级 | 交互式分析、BI报表 |
| 数据源支持 | 单一存储 | 联邦查询(跨20+连接器) | 统一访问异构数据源 |
| 架构扩展性 | 固定集群 | 弹性伸缩(无状态Worker) | 按需扩容降低成本 |
| 使用成本 | 高(商业授权/硬件) | 开源+云原生 | 避免厂商锁定,支持容器化 |
小结:适用于 数据仓库、日志分析、数据湖查询、BI 分析。

1.3 核心设计思想
- 无共享架构(Shared Nothing):Worker完全独立;无磁盘写依赖;线性扩展能力。
- 全内存流水线:各Operator间通过内存Page直接传递数据。
- 动态代码生成:运行时生成优化字节码;消除虚函数调用;特定数据类型特化。
- 异步I/O模型:网络与计算重叠;非阻塞数据获取;流水线气泡最小化。
2 工作原理与架构
要理解 Trino 的工作原理,我们可以从它的架构设计、查询执行流程以及核心优化技术这三个维度来拆解。
- 核心组件
- Coordinator(协调器):接收SQL请求,解析生成分布式执行计划;调度Task到Worker,监控查询状态。
- Worker(工作节点):执行Task(数据扫描、过滤、聚合等操作);通过Driver驱动多个Operator(最小执行单元)。
- Connector(连接器):解耦计算与存储,通过插件支持新数据源;关键接口:getSplits()(数据分片)、getPage()。
Trino 查询执行流程:从 SQL 到分布式计算
当你提交一条 SQL 语句时,Trino 内部经历了一个复杂的“翻译”和“分发”过程:
- 解析与逻辑计划生成:
- SQL Parser:将 SQL 文本解析成抽象语法树(AST)。
- Logical Planner:结合元数据(如表结构、统计信息),将 AST 转换成逻辑执行计划。
- 物理计划与分布式调度:
- Distributed Planner:这是关键一步。它将逻辑计划拆分成多个Stage(阶段),构成一个树状依赖结构。
- Stage Scheduler:将 Stage 分发到各个 Worker 节点上执行。
- 任务执行与流水线处理:
- Task Executor:每个 Stage 在 Worker 上表现为一个或多个 Task。
- Operator Pipeline:Task 内部由多个 Operator(操作符,如 Scan、Filter、Join、Aggregation)组成。
数据在这些 Operator 之间以“流水线”的方式传递,中间结果通常不落盘,直接在内存中流转,这是 Trino 速度快的重要原因。
Trino数据模型
Trino就是通过Connector来访问不同的数据源的,相当于访问不同数据源的驱动程序,每种connector都实现了Trino的【标准SPI接口】。
因此,只要实现了【标准SPI接口】就可以制定特殊的Connector来访问数据源。
- Trino采取三层表结构:
- Catalog
Trino中Catalog类似于mysql中的一个数据库实例,Schema类似于mysql当中的一个database。如用Trino去连接一个hive中的一个库
- Schema
Trino中的schema就相当于mysql中的一个具体的database。
- Table
Trino中的table和mysql中table含义一样
- 访问数据源的示例
trino --server ip:port --catalog hive --schema xxx
这样就可以访问hive的中的xxx库。
核心架构:Master-Worker 模式
Trino 采用经典的 无共享(Shared-Nothing) 架构,这意味着各个节点之间没有数据共享,完全独立,这保证了极强的线性扩展能力。
- Coordinator(协调节点):
- 职责:它是集群的“大脑”。负责接收客户端的 SQL 查询请求,解析 SQL 生成执行计划,并将任务分发给 Worker 节点。
- 工作:它会维护元数据(MetaStore),监控 Worker 的心跳和状态,并最终将各个 Worker 返回的结果汇总,流式返回给客户端。
- Worker(工作节点):
- 职责:它是集群的“四肢”。负责执行 Coordinator 下发的具体任务。
- 工作:通过连接器(Connector)读取外部存储系统(如 HDFS、S3、MySQL)的数据,进行计算处理,并将中间结果发送给下一阶段的 Worker 或 Coordinator。
分层架构设计
- 协调层(Coordinator):集群大脑
- SQL解析器:语法树生成
- 优化器:基于成本的查询优化(CBO)
- 调度器:分布式任务分配
- 资源管理器:全局资源配额控制
- 计算层(Worker):并行执行引擎
- 任务执行器:Task处理单元
- 驱动池:多线程执行引擎
- 内存管理器:精细化内存控制
- 连接层(Connector):存储抽象
- 统一接口:getSplits(), getPage()
- 数据源适配器:Hive/S3/RDBMS等
Coordinator(协调器)深度解析
- SQL解析与优化
- 语法解析 → 语义验证 → 逻辑计划 → CBO优化
- 优化手段:谓词下推、Join重排序、Limit下推
- 资源管理:全局资源组配置;查询优先级队列;内存池监控。
Worker(工作节点)执行引擎
- Task:最小调度单元;包含多个Driver实例;状态机:PLANNED → RUNNING → FINISHED/FAILED。
- Driver:执行线程的基本单位;包含Operator管道;内存控制单元。
- Operator:原子操作实现,类型如下:
- 数据源:TableScanOperator
- 转换:FilterOperator, ProjectOperator
- 聚合:HashAggregationOperator
- Join:HashBuilderOperator, LookupJoinOperator
Connector (连接器)
- 连接器设计精髓
- 元数据抽象:统一表/列/分区视图;跨源schema映射。
- 谓词下推优化:过滤条件下推到数据源。
- 分片并行处理:自动分裂大文件(>64MB);并行读取小文件合并;ORC/Parquet列式加速。
关键优化技术
- 数据局部性优化:Split调度亲和性;网络拓扑感知;动态过滤(Dynamic Filtering)。
- 资源隔离机制:多级配额控制(CPU/内存/并发)。
- 弹性内存管理:内存分级(执行/系统/预留);智能溢出(Spill to SSD);OOM防护机制。
Query Execution(查询执行) 原理剖析
四级执行抽象模型
为了更清晰地理解任务是如何被执行的,我们可以看下表这个层级结构:
| 层级 | 说明 | 并行度 |
|---|---|---|
| Query | 代表一次完整的 SQL 查询 | 全局唯一 |
| Stage | 执行计划的子图,各 Stage 间有依赖关系 | 多 Worker 并行 |
| Task | Stage 的具体分区实例,是调度的最小单元 | 每个 Worker 上可运行多个 Task |
| Operator | 原子计算操作(如读取、过滤、聚合) | 每个 Task 包含多个 Operator |
- Stage拓扑类型
- SOURCE Stage:直接对接数据源(HDFS/S3/RDBMS);并行度 = 数据分片数(Split);仅包含Scan类Operator。
- FIXED Stage:承担Shuffle数据交换;并行度由hash_partition_count配置;包含Join/Aggregate等复杂Operator。
- SINGLE Stage:最终结果汇聚;单点执行(Coordinator或指定Worker);负责Order By/Limit等全局操作。
- 数据交换模式
- Local Exchange:Worker内部Task间数据传输。
- Global Exchange:跨Worker数据重分布。
- Exchange Client:管理网络连接与数据缓冲。
关键执行流程
- 查询解析阶段:SQL → 抽象语法树 → 逻辑计划 → 优化计划。
- 分布式调度阶段:Stage间构成流水线(Pipeline);Task为最小调度单元;Split对应数据分片。
- 内存计算阶段:列式内存格式(Page);向量化处理(每个Page 1024行);操作符流水线(避免物化中间结果)。
内存计算引擎核心设计
- 列式内存结构(Page)
| 组件 | 描述 | 优化价值 |
|---|---|---|
| Block | 单列数据容器 | 列式处理加速聚合 |
| Page | 1024行Blocks的集合 | CPU缓存友好 |
| Position Count | 实际行数(可能<1024) | 处理尾部数据 |
| Dictionary Block | 字典编码块 | 高基数列内存压缩 |
- 操作符流水线
- 批处理:单次处理整Page而非单行。
- 延迟物化:保持编码数据直至必须解码。
- 短路执行:Limit条件下提前终止。
- 内存管理机制
- 执行内存:Operator计算过程占用。
- 系统内存:数据结构开销(Hash表等)。
- 预留内存:保障关键操作不被中断。
高级优化策略体系
分布式Join优化
| 策略 | 适用场景 | 数据移动代价 |
|---|---|---|
| Broadcast | 维度表(<1GB) | O(N) |
| Partitioned | 双大表 | O(N+M) |
| Colocated | 同分布键的事实-事实表Join | O(1) |
| Dynamic Filter | 星型模型Join | 下推减少源数据 |
动态运行时优化
- 自适应并行度:基于数据量动态调整Task数;小数据集自动降级到单Task处理;倾斜分区识别与特殊处理。
- 动态过滤工作流
连接器级加速(ORC/Parquet优化)
- 行组跳过:基于统计信息过滤数据块
- 布隆过滤:快速判断值是否存在
- 延迟加载:仅读取需要的列块
Connectors(连接器)
-
Trino 本身不存储数据,它通过 Connector 来对接各种外部数据源。Trino 定义了一套标准的 SPI(服务提供者接口),允许开发者通过实现接口来接入新的数据源。
-
联邦查询:你可以在一条 SQL 中同时查询 Hive 里的日志数据和 MySQL 里的业务数据,Trino 会自动协调这两个数据源的数据进行关联。
核心设计原则
- 计算存储分离:Trino不存储数据,只进行计算。
- 统一接口规范:所有数据源实现相同API。
- 元数据抽象:统一表/列/分区视图。
- 下推优化:最大化利用底层存储能力。
三大基础接口
| 接口 | 职责 | 关键方法 |
|---|---|---|
| ConnectorMetadata | 元数据管理 | listTables(), getTableHandle() |
| ConnectorSplitManager | 数据分片管理 | getSplits() |
| ConnectorRecordSetProvider | 数据读取 | getRecordSet() |
主流连接器特性
| 连接器 | 核心优势 | 适用场景 | 下推能力 |
|---|---|---|---|
| Hive | 成熟稳定,兼容Hive生态 | 数据湖查询 | 谓词/分区/列裁剪 |
| Iceberg | ACID事务,时间旅行 | 增量ETL,CDC场景 | 高级谓词下推,元数据过滤 |
| RDBMS | 实时数据访问 | 联邦查询,数据融合 | 完整SQL下推 |
| Kafka | 流式数据接入 | 实时监控,事件分析 | 时间范围过滤 |
| MongoDB | 文档模型支持 | JSON数据分析 | 字段投影,简单过滤 |
高可用架构设计
为了实现高可用性,Trino架构需要满足以下目标:
- 故障 tolerance:单点故障可能导致服务中断,因此需要设计容错机制。
- 负载均衡:确保查询任务在集群内均匀分布,避免某些节点过载。
- 数据冗余:通过数据副本机制保证数据的可靠性,防止数据丢失。
- 快速故障恢复:在节点故障时,能够快速切换到备用节点,减少服务中断时间。
总结
简单来说,Trino 的工作原理就是:
- Coordinator 接收 SQL,将其拆解成分布式执行计划(Stage/Task),分发给 Worker 集群;
- Worker 利用内存列式计算和向量化执行,在数据源上进行并行扫描和计算,并通过流水线方式快速返回结果。
这种架构使其成为大数据领域进行交互式分析查询的首选引擎,特别适合 ETL 数据清洗、海量数据报表分析等场景。
3 安装部署篇
安装部署 on Windows
- 在
Windows环境下搭建Trino(之前称为PrestoSQL)的开发环境需要一系列的组件和工具。
Trino是一个高性能的分布式SQL查询引擎,用于查询大型数据仓库。在本节文章中,我们将探讨在Windows上配置Trino开发环境所需的各种组件,并帮助您解决在搭建过程中可能遇到的问题。
Java开发工具包(JDK)
Trino需要Java运行环境(JRE)和开发工具包(JDK)才能正常运行。请确保您已安装最新版本的JDK,并配置好JAVA_HOME环境变量。
C:\Users\Johnny> java -version
java version "1.8.0_261"
Java(TM) SE Runtime Environment (build 1.8.0_261-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode)
Maven
- Trino项目使用Maven进行构建和依赖管理。请确保已安装Maven,并将其添加到系统
PATH中。您可以从Apache官网下载和安装Maven。
$ mvn --version
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: D:\Program Files(x86)\Maven\apache-maven-3.6.3-self
Java version: 1.8.0_261, vendor: Oracle Corporation, runtime: D:\Program_Files\Java\jdk1.8.0_261\jre
Default locale: zh_CN, platform encoding: GBK
OS name: "windows 10", version: "10.0", arch: "amd64", family: "windows"
$ ls "D:\Program Files(x86)\Maven\apache-maven-3.6.3-self\conf\settings.xml"
'D:\Program Files(x86)\Maven\apache-maven-3.6.3-self\conf\settings.xml'
Git
- 由于Trino的源代码托管在GitHub上,因此您需要使用Git来获取源代码。请确保已安装Git,并将其添加到系统PATH中。您可以从GitHub官网下载和安装Git。
Trino 源代码
- 您可以从Trino的GitHub仓库克隆或下载源代码。在命令行中运行以下命令:
# git clone --branch 479 https://github.com/trinodb/trino.git
git clone https://github.com/trinodb/trino.git
# 切换到指定分支 (332版本 是最后一个支持 JDK 8 的版本)
git checkout 332
cd trino

构建Trino
- 在获取源代码后,使用Maven构建Trino。在命令行中运行以下命令:
# mvn clean install -DskipTests
mvn clean install -DskipTests --settings "D:\Program Files(x86)\Maven\apache-maven-3.6.3-self\conf\settings.xml"
这将构建Trino并将其安装到您的本地仓库中。
注意,由于Trino需要运行一些测试,因此在某些Windows环境下可能无法完全跳过测试。
如果遇到问题,您可以尝试在能够运行这些测试的环境中执行上述命令。

配置数据源
Trino支持多种数据源,但配置新数据源需要在配置文件中进行添加,且Trino目前没有热加载机制。
因此,每次添加新数据源需要【重启节点】才能生效。
这对于需要频繁更换数据源的用户来说可能会造成不便。
如果需要添加新的数据源,您需要编辑Trino的配置文件(通常位于conf/目录下),并添加相应的配置项。
具体的配置方式可以参考Trino的官方文档或社区提供的指南。
编译和运行Trino
- 完成上述步骤后,您可以使用编译好的Trino二进制文件启动Trino服务器。在命令行中运行以下命令:
./bin/launcher.sh server conf/server.properties
这将启动Trino服务器并监听指定的端口(默认为8080)。您可以使用相应的客户端工具连接到服务器并执行SQL查询。
通过遵循上述步骤,您可以在Windows环境下成功搭建Trino的开发环境。请注意,由于Trino的开源性质和持续发展,本文中的信息可能已经过时或有所变更。建议您经常查看Trino的官方文档和社区论坛以获取最新的信息和技术支持。
FAQ for Trino
Q: 为什么 Trino 这么快?(核心优化技术)
Trino 能实现秒级甚至毫秒级响应,主要得益于以下几个关键技术:
- 全内存与向量化执行:
- Trino 尽量避免磁盘 I/O,数据在处理过程中以列式内存格式(Page)在内存中传递。
- 它采用向量化处理,每次处理一个 Page(通常包含 1024 行数据),而不是一行一行地处理,这非常契合现代 CPU 的缓存机制,极大地提升了 CPU 利用率。
- MPP 并行计算模型:
- 基于 Massively Parallel Processing (MPP) 模型,查询计划被拆解到所有可用的 Worker 节点上并行执行,充分利用集群资源。
- 智能 Join 优化:
- 广播 Join (Broadcast):如果一张表很小(维度表),Trino 会将其完整复制到所有包含大表(事实表)的节点上,避免昂贵的数据重分布(Shuffle)。
- 动态过滤 (Dynamic Filtering):在运行时根据小表的 Join Key 动态生成过滤条件,提前过滤掉大表中不相关的数据,减少 I/O。
- 谓词与列式下推:
- Trino 会将
WHERE条件(谓词)和只需要的列(列裁剪)直接“下推”到底层存储(如 Hive、MySQL),让数据源先过滤数据,只拉取必要的数据到 Trino 计算层。
- Trino 会将
- 异步 I/O 模型:
- 使用非阻塞的网络和数据获取方式,计算和网络传输可以重叠进行,减少了任务等待时间。
Y 推荐文献
- Trino
X 参考文献

本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号