[Java/SpringCloud] Feign(Http Client)、Hystrix(熔断器)、Ribbon(客户端式的负载均衡器) 概述
序
- 在微服务架构的应用中,
Feign、Hystrix,Ribbon三者都是必不可少的,可以说已经成为铁三角。
概述: Feign(Http Client)、Hystrix(熔断器)、Ribbon(客户端式的负载均衡器)
组件介绍
Feign : Http 客户端
Feign是一款Java语言编写的HttpClient绑定器,在Spring Cloud微服务中用于实现微服务之间的声明式调用。
Feign可以定义请求到其他服务的接口,用于微服务间的调用,不用自己再写http请求,在客户端实现,调用此接口就像远程调用其他服务一样,当请求出错时可以调用接口的实现类来返回
Feign是一个声明式的web service客户端,它使得编写web service客户端更为容易。
创建接口,为接口添加注解,即可使用Feign。
Feign可以使用Feign注解或者JAX-RS注解,还支持热插拔的编码器和解码器。
Spring Cloud为Feign添加了Spring MVC的注解支持,并整合了Ribbon和Eureka来为使用Feign时提供负载均衡。
- github
Hystrix : 流量控制/容错管理
-
Hystrix作为熔断流量控制,在客户端实现,在方法上注解,当请求出错时可以调用注解中的方法返回 -
Hystrix熔断器,容错管理工具,旨在通过熔断机制控制服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。
在Spring Cloud Hystrix中实现了线程隔离、断路器等一系列的服务保护功能。
它也是基于Netflix的开源框架 Hystrix实现的,该框架目标在于通过控制那些访问远程系统、服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。Hystrix具备了服务降级、服务熔断、线程隔离、请求缓存、请求合并以及服务监控等强大功能。
- github:
Ribbon : 负载均衡器
-
Ribbon作为负载均衡,在客户端实现,服务段可以启动两个端口不同但servername一样的服务 -
Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法,将Netflix的中间层服务连接在一起。
Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等。
简单的说,就是在配置文件中列出Load Balancer后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。我们也很容易使用Ribbon实现自定义的负载均衡算法。简单地说,Ribbon是一个客户端负载均衡器。
Ribbon工作时分为2步:
- 第1步, 先选择 Eureka Server, 它优先选择在同一个Zone且负载较少的Server;
- 第2步, 再根据用户指定的策略,在从Server取到的服务注册列表中选择一个地址。
其中Ribbon提供了多种策略,例如轮询、随机、根据响应时间加权等。
- github:
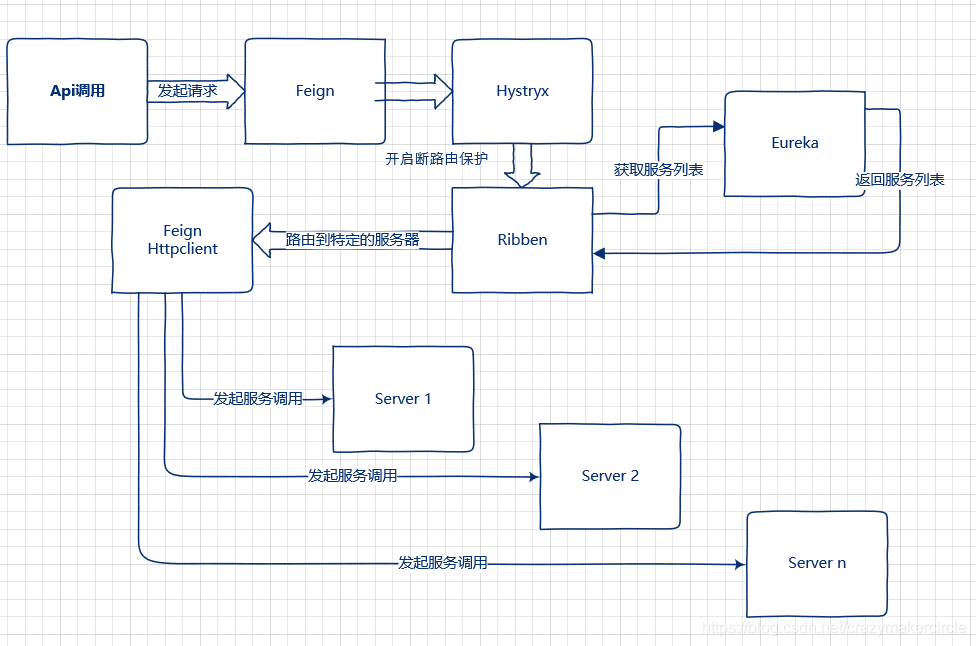
重点: 三者之间的关系图
-
如果微服务项目加上了
spring-cloud-starter-netflix-hystrix依赖,则:feign会通过代理模式, 自动将所有的方法用hystrix进行包装。 -
在
Spring Cloud微服务体系下,微服务之间的互相调用可以通过Feign进行声明式调用。
- 在这个服务调用过程中
Feign会通过Ribbon从服务注册中心获取目标微服务的服务器地址列表- 之后在网络请求的过程中
Ribbon就会将请求以负载均衡的方式打到微服务的不同实例上,从而实现Spring Cloud微服务架构中最为关键的功能即服务发现及客户端负载均衡调用。
- 另一方面微服务在互相调用的过程中,为了防止某个微服务的故障消耗掉整个系统所有微服务的连接资源
所以,在实施微服务调用的过程中,我们会要求在调用方实施针对被调用微服务的熔断逻辑。
而要实现这个逻辑场景在Spring Cloud微服务框架下我们是通过Hystrix这个框架来实现的。
-
调用方会针对被调用微服务设置调用超时时间,一旦超时就会进入熔断逻辑,而这个故障指标信息也会返回给
Hystrix组件 -
Hystrix组件会根据熔断情况判断被调微服务的故障情况从而打开熔断器,之后所有针对该微服务的请求就会直接进入熔断逻辑,直到被调微服务故障恢复,Hystrix断路器关闭为止。 -
三者之间的关系图,大致如下:
典型配置
Feign
Feign自身可以支持多种Http Client工具包
例如:
OkHttp及Apache HttpClient
- 针对
Apache HttpClient的典型配置:
feign:
#替换掉JDK默认HttpURLConnection实现的 Http Client
httpclient:
enabled: true
hystrix:
enabled: true
client:
config:
default:
#连接超时时间
connectTimeout: 5000
#读取超时时间
readTimeout: 5000
Hystrix
- 在Spring Cloud微服务体系中Hystrix主要被用于实现实现微服务之间网络调用故障的熔断、过载保护及资源隔离等功能。
hystrix:
propagate:
request-attribute:
enabled: true
command:
#全局默认配置
default:
#线程隔离相关
execution:
timeout:
#是否给方法执行设置超时时间,默认为true。一般我们不要改。
enabled: true
isolation:
#配置请求隔离的方式,这里是默认的线程池方式。还有一种信号量的方式semaphore,使用比较少。
strategy: threadPool
thread:
#方式执行的超时时间,默认为1000毫秒,在实际场景中需要根据情况设置
timeoutInMilliseconds: 10000
#发生超时时是否中断方法的执行,默认值为true。不要改。
interruptOnTimeout: true
#是否在方法执行被取消时中断方法,默认值为false。没有实际意义,默认就好!
interruptOnCancel: false
circuitBreaker: #熔断器相关配置
enabled: true #是否启动熔断器,默认为true,false表示不要引入Hystrix。
requestVolumeThreshold: 20 #启用熔断器功能窗口时间内的最小请求数,假设我们设置的窗口时间为10秒,
sleepWindowInMilliseconds: 5000 #所以此配置的作用是指定熔断器打开后多长时间内允许一次请求尝试执行,官方默认配置为5秒。
errorThresholdPercentage: 50 #窗口时间内超过50%的请求失败后就会打开熔断器将后续请求快速失败掉,默认配置为50
Ribbon
-
Ribbon在Spring Cloud中对于支持微服之间的通信发挥着非常关键的作用,其主要功能包括客户端负载均衡器及用于中间层通信的客户端。 -
在基于
Feign的微服务通信中无论是否开启Hystrix,Ribbon都是必不可少的,Ribbon的配置参数主要如下:
ribbon:
eager-load:
enabled: true
#说明:同一台实例的最大自动重试次数,默认为1次,不包括首次
MaxAutoRetries: 1
#说明:要重试的下一个实例的最大数量,默认为1,不包括第一次被调用的实例
MaxAutoRetriesNextServer: 1
#说明:是否所有的操作都重试,默认为true
OkToRetryOnAllOperations: true
#说明:从注册中心刷新服务器列表信息的时间间隔,默认为2000毫秒,即2秒
ServerListRefreshInterval: 2000
#说明:使用Apache HttpClient连接超时时间,单位为毫秒
ConnectTimeout: 3000
#说明:使用Apache HttpClient读取的超时时间,单位为毫秒
ReadTimeout: 3000
- 如上图所示,在Spring Cloud中使用
Feign进行微服务调用分为两层:
- Hystrix的调用
- Ribbon的调用
即:Feign自身的配置会被覆盖。
- 而如果开启了
Hystrix,那么Ribbon的超时时间配置与Hystrix的超时时间配置则存在依赖关系
因为涉及到
Ribbon的重试机制,所以:一般情况下都是Ribbon的超时时间 <Hystrix的超时时间,否则会出现以下错误:
2019-10-12 21:56:20,208 111231 [http-nio-8084-exec-2] WARN o.s.c.n.z.f.r.s.AbstractRibbonCommand - The Hystrix timeout of 10000ms for the command xxxx-service is set lower than the combination of the Ribbon read and connect timeout, 24000ms.
(命令 xxxx-service 的 Hystrix 超时 10000ms 被设置为低于Ribbon读取和连接超时(24000ms)的总和。)
Ribbon和Hystrix的超时时间配置的关系?
- 那么Ribbon和Hystrix的超时时间配置的关系具体是什么呢?
如下:
Hystrix的超时时间=Ribbon的重试次数(包含首次) * (ribbon.ReadTimeout + ribbon.ConnectTimeout)
- 而
Ribbon的重试次数的计算方式为:
Ribbon重试次数(包含首次)= 1 + ribbon.MaxAutoRetries + ribbon.MaxAutoRetriesNextServer + (ribbon.MaxAutoRetries * ribbon.MaxAutoRetriesNextServer)
以上图中的Ribbon配置为例子:
Ribbon的重试次数=1+(1+1+1)=4
所以,Hystrix 的超时配置应该 >= 4*(3000+3000)=24000 毫秒。
在Ribbon超时,但Hystrix没有超时的情况下,Ribbon便会采取重试机制;而重试期间如果时间超过了Hystrix的超时配置则会立即被熔断(fallback)。
- 如果不配置Ribbon的重试次数,则Ribbon默认会重试一次,加上第一次调用 Ribbon,总的的重试次数为2次,以上述配置参数为例,Hystrix超时时间配置为2*6000=12000
由于很多情况下,大家一般不会主动配置Ribbon的重试次数
所以,这里需要注意下!
强调下,以上超时配置的值只是示范,超时配置有点大不太合适实际的线上场景,大家根据实际情况设置即可!
说明下,如果不启用Hystrix,Feign的超时时间则是Ribbon的超时时间,Feign自身的配置也会被覆盖。
FAQ for Feign(Http Client)、Hystrix(熔断器)、Ribbon(客户端式的负载均衡器)
Q: 接口调用时报 failed and no fallback available(调用失败、且无可用的应变计划)
问题分析
- 对于
failed and no fallback available.这种异常信息,是因为应用程序开启了熔断:feign.hystrix.enabled: true
当调用服务时抛出了异常,却没有定义
fallback方法,就会抛出上述异常。
解决方法
解决方法1 : @FeignClient加上fallback方法,并获取异常信息
为@FeignClient修饰的接口加上
fallback方法有2种方式。
由于要获取异常信息,所以使用fallbackFactory的方式:
@FeignClient(name = "serviceId", fallbackFactory = TestServiceFallback.class)
public interface TestService {
@RequestMapping(value = "/get/{id}", method = RequestMethod.GET)
Result get(@PathVariable("id") Integer id);
}
在
@FeignClient注解中指定fallbackFactory,上面例子中是TestServiceFallback:
import feign.hystrix.FallbackFactory;
import org.apache.commons.lang3.StringUtils;
@Component
public class TestServiceFallback implements FallbackFactory<TestService> {
private static final Logger LOG = LoggerFactory.getLogger(TestServiceFallback.class);
public static final String ERR_MSG = "Test接口暂时不可用: ";
@Override
public TestService create(Throwable throwable) {
String msg = throwable == null ? "" : throwable.getMessage();
if (!StringUtils.isEmpty(msg)) {
LOG.error(msg);
}
return new TestService() {
@Override
public String get(Integer id) {
return ResultBuilder.unsuccess(ERR_MSG msg);
}
};
}
}
通过实现
FallbackFactory,可以在create方法中获取到服务抛出的异常。
但是请注意,这里的异常是被Feign封装过的异常,不能直接在异常信息中看出原始方法抛出的异常。
这时得到的异常信息,形如:
status 500 reading TestService#addRecord(ParamVO);
content: {“success”:false,“resultCode”:null,“message”:"/ by zero",“model”:null,“models”:[],“pageInfo”:null,“timelineInfo”:null,“extra”:null,“validationMessages”:null,“valid”:false}
说明一下,本例子中,服务提供者的接口返回信息会统一封装在自定义类Result中,内容就是上述的
content:{“success”:false,“resultCode”:null,“message”:"/ by zero",“model”:null,“models”:[],“pageInfo”:null,“timelineInfo”:null,“extra”:null,“validationMessages”:null,“valid”:false}
因此,异常信息我希望是
message的内容:/ by zero,这样打日志时能够方便识别异常。
解决方法2 保留原始异常信息
当调用服务时,如果服务返回的状态码不是200,就会进入到Feign的ErrorDecoder中,因此如果我们要解析异常信息,就要重写ErrorDecoder:
import feign.Response;
import feign.Util;
import feign.codec.ErrorDecoder;
/**
* @Author: CipherCui
* @Description: 保留 feign 服务异常信息
* @Date: Created in 1:29 2018/6/2
*/
public class KeepErrMsgConfiguration {
@Bean
public ErrorDecoder errorDecoder() {
return new UserErrorDecoder();
}
/**
* 自定义错误
*/
public class UserErrorDecoder implements ErrorDecoder {
private Logger logger = LoggerFactory.getLogger(getClass());
@Override
public Exception decode(String methodKey, Response response) {
Exception exception = null;
try {
// 获取原始的返回内容
String json = Util.toString(response.body().asReader());
exception = new RuntimeException(json);
// 将返回内容反序列化为Result,这里应根据自身项目作修改
Result result = JsonMapper.nonEmptyMapper().fromJson(json, Result.class);
// 业务异常抛出简单的 RuntimeException,保留原来错误信息
if (!result.isSuccess()) {
exception = new RuntimeException(result.getMessage());
}
} catch (IOException ex) {
logger.error(ex.getMessage(), ex);
}
return exception;
}
}
}
上面是一个例子,原理是根据
response.body()反序列化为自定义的Result类,提取出里面的message信息,然后抛出RuntimeException
这样当进入到熔断方法中时,获取到的异常就是我们处理过的RuntimeException。
注意:上面的例子并不是通用的,但原理是相通的,大家要结合自身的项目作相应的修改。
要使上面代码发挥作用,还需要在
@FeignClient注解中指定configuration:
@FeignClient(name = "serviceId", fallbackFactory = TestServiceFallback.class, configuration = {KeepErrMsgConfiguration.class})
public interface TestService {
@RequestMapping(value = "/get/{id}", method = RequestMethod.GET)
String get(@PathVariable("id") Integer id);
}
解决方法3 不进入熔断,直接抛出异常
- 有时我们并不希望方法进入熔断逻辑,只是把异常原样往外抛。这种情况我们只需要捉住两个点:不进入熔断、原样。
原样就是获取原始的异常,上面已经介绍过了,而不进入熔断,需要把异常封装成
HystrixBadRequestException,对于HystrixBadRequestException,Feign会直接抛出,不进入熔断方法。
因此,我们只需要在上述KeepErrMsgConfiguration的基础上作一点修改即可:
/**
* @Author: CipherCui
* @Description: feign 服务异常不进入熔断
* @Date: Created in 1:29 2018/6/2
*/
public class NotBreakerConfiguration {
@Bean
public ErrorDecoder errorDecoder() {
return new UserErrorDecoder();
}
/**
* 自定义错误
*/
public class UserErrorDecoder implements ErrorDecoder {
private Logger logger = LoggerFactory.getLogger(getClass());
@Override
public Exception decode(String methodKey, Response response) {
Exception exception = null;
try {
String json = Util.toString(response.body().asReader());
exception = new RuntimeException(json);
Result result = JsonMapper.nonEmptyMapper().fromJson(json, Result.class);
// 业务异常包装成 HystrixBadRequestException,不进入熔断逻辑
if (!result.isSuccess()) {
exception = new HystrixBadRequestException(result.getMessage());
}
} catch (IOException ex) {
logger.error(ex.getMessage(), ex);
}
return exception;
}
}
}
- 小结
为了更好的达到熔断效果,我们应该为每个接口指定fallback方法。而根据自身的业务特点,可以灵活的配置上述的KeepErrMsgConfiguration和NotBreakerConfiguration,或自己编写Configuration。
参考文献
Q: 接口调用时报错:timed-out and no fallback(调用超时,且没有应变计划)
- 问题分析
这个错误基本是出现在
Hystrix熔断器
熔断器的作用是判断该服务能不能通,如果通了就不管了,调用在指定时间内超时时,就会通过熔断器进行错误返回。
- 解决方法
一般设置如下配置的其中一个即可:
1、把时间设长
//这里设置5秒
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=5000
2、把超时发生异常属性关闭
hystrix.command.default.execution.timeout.enabled=false
3、禁用feign的熔断器hystrix
feign.hystrix.enabled: false
- 参考文献
X 参考文献
- Feign Ribbon Hystrix 三者关系 | 史上最全, 深度解析 - 博客园 2019.10.13

本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号